Windows远程桌面实现之五(FFMPEG实现桌面屏幕RTSP,RTMP推流及本地保存)
by fanxiushu 2018-07-10 转载或引用请注明原始作者。
前面文章分别阐述了,如何抓取电脑屏幕数据,如何采集电脑声音,
如何实现在现代浏览器中通过HTML5和WebSocket直接进行远程控制。
这章阐述如何把采集到的电脑屏幕和电脑声音,通过一些通用协议,
比如RTSP,RTMP把电脑桌面屏幕推送到更广泛的直播服务器上,达到电脑屏幕直播的效果。
或者把电脑屏幕保存成本地的MP4或MKV视频文件。
其实 https://github.com/fanxiushu/xdisp_virt 或 https://download.csdn.net/download/fanxiushu/10168823 提供的程序,
其中xdisp_server.exe中转服务器,本身就是个直播服务器的效果。
只不过xdisp_server.exe不但能直播屏幕和声音,还能远程控制,实时性要求也更高。
还能直接在网页中播放,只是使用的是自己定义的私有通讯协议。
为了把我们的电脑屏幕无私的共享出去,而且让别人更好的中转,加速,就得使用一些比较广泛使用的协议,
比如RTSP, 这个一般在视频监控领域用得比较多,实时性要求也比较高,不过我在内网测试下来,总有几秒的延迟。
播放器使用VLC, RTSP是在linux上架设的 easydarwin 测试服务器,当然也就是随便架设,没做什么优化。
也可能播放的屏幕尺寸太大,是 2560X1600 的视频尺寸。
另一个RTMP协议在当前互联网直播推流中用得很多,linux我使用的是nginx+rtmp_module,这个的延时就更加糟糕,
最差能达到十几秒的延迟。而且是越播放越往后延迟。当然都是属于测试性质的架设这些服务器,主要是为了测试开发
RTSP,RTMP推流客户端。
RTSP,RTMP这类协议的开源库不少,这里并不打算介绍通讯协议细节。也没仔细去研究过这些通讯协议。
无非就是在TCP或UDP链接中,以一个一个的数据包分界的方式,传递视频帧或者音频帧。
这在我们自己定义的私有通讯协议中也是这么做的,比起研究这些通用协议格式,
更愿意自己来实现,因为更加灵活,就比如xdisp_virt.exe远程控制程序里,在一条TCP链接里,不单传输音视频帧,
还传输鼠标键盘数据包,还传输各种控制信息数据包,以及其他需要的数据包,想想都挺热闹的。
一开始使用的是librtmp开源库,因为当时只局限于实现RTMP推流,没考虑其他的,
只是等使用librtmp实现了之后,发现使用VLC播放,总是只找到音频流,没有视频,试了多次都是这样。
当时找不到原因(其实后来找到原因是因为设置的关键帧间隔太大,
足有800这么大,这在我的私有通讯协议中没问题,因为发现缺少SPS,PPS。都会通知被控制端重新刷出关键帧。),
也就打算放弃使用librtmp库,另外使用其他开源库,后来发现ffmpeg也能实现rtmp推流,
再仔细查看ffmpeg,发现不但能rtmp推流,还能rtsp推流,http推流,还能保存到本地mp4,mkv等多种格式的视频文件。
既然有这么多这么强大的功能,干嘛死抱着librtmp不放。
而且把桌面屏幕保存到本地视频文件,一直都是我想做的事,苦于自己对这些MP4封装格式不大了解。
使用的是ffmpeg的3.4的版本,在这个版本中的 doc/example 目录中的 muxing.c 源代码,就是实现如何推流的例子。
之所以取名 muxing.c, 在ffmpeg开发团队看来,rtmp,rtsp这些推流,其实也是把音频和视频混合成一定格式”保存“。
跟本地MP4等文件一样的概念。正是这样的做法,我们可以在muxing.c中,
使用的ffmpeg统一的API函数,既可以把音视频保存到本地多种格式的文件,
也可以实时的以rtmp,http,rtsp等多种方式推送到流媒体服务器端,非常的方便。
muxing.c例子代码中,输入原始YUV图像数据或原始声音数据,然后编码,然后混合写入文件或者推流,一气呵成。
但是我们这里需要的功能是只需要把已经编码好的音视频(H264和AAC)数据帧,直接写入混合器。
而且要实现可以同时朝多个混合器写数据。也就是我们可以同时保存到本地MP4文件,
也同时可以朝多个RTSP或RTMP服务器做推流。
如下图的配置界面,就是最新版本xdisp_virt程序做的推流的网页方式的配置界面:
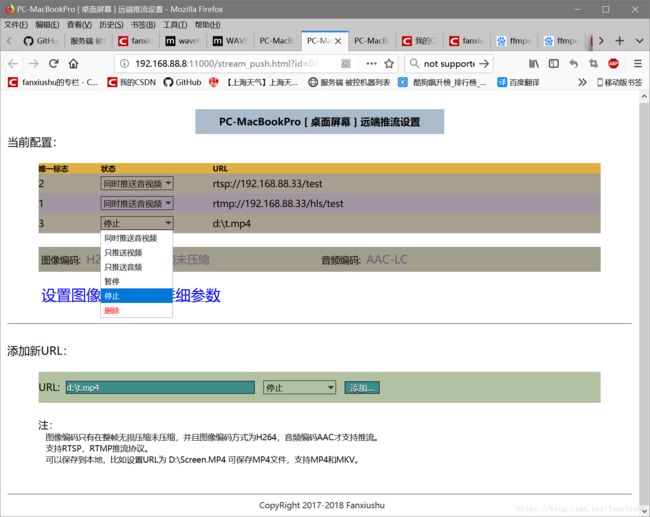
图中设置了三个推流地址,分别朝RTSP, RTMP服务器推送音视频,同时保存到d盘的t.mp4视频文件中。
在我们的xidsp_virt远程桌面控制程序中,编码好的桌面图像数据和声音数据,
一边要发送给多个WebSocket通讯的网页客户端,一边要发送给多个原生客户端(当然还包括发送给中转服务端),
现在还要发送给RTMP,RTSP,同时保存到本地文件等,
如果朝每个终端发送音视频流都做一次编码,是不现实的。这就是为何要把muxing.c例子代码里边的编码部分剥离出去,
只保留把编码好的音视频帧直接写入混合器的功能。
我们先来看看调用ffmpeg的API的流程,其实是挺简单,函数也不多:
首先调用avformat_alloc_output_context2 创建AVFormatContext变量,最后一个参数就是推流地址,或者保存本地的完整路径,
比如:
AVFormatContext* ctx;
avformat_alloc_output_context2(&ctx, NULL, "flv", "rtmp://192.168.88.1/hls/test"); // 以RTMP协议推送
avformat_alloc_output_context2(&ctx, NULL, "rtsp", "rtsp://192.168.88.1/test"); // 以RTSP协议推送
avformat_alloc_output_context2(&ctx, NULL,NULL, "d:\\Screen.mp4") ; //保存到本地 Screen.mp4视频文件中。
之后调用 avformat_new_stream 函数创建视频流和音频流,并且添加到ctx变量中。
比如如下代码就是创建编码类型为H264和AAC的视频和音频流:
AVOutputFormat *fmt = ctx->oformat;
////固定 H264 + AAC 编码
fmt->video_codec = AV_CODEC_ID_H264;
fmt->audio_codec = AV_CODEC_ID_AAC;
codec = avcodec_find_encoder(AV_CODEC_H264);
AVStream* st = avformat_new_stream( ctx, codec);
...... //其他初始化
codec = avcodec_find_encoder(AV_CODEC_AAC);
AVStream* st = avformat_new_stream( ctx , codec);
...... //其他初始化
因为RTSP,RTMP都是网络通讯,网络环境复杂多变就必须面临一个通讯超时问题,写到本地磁盘倒不必关心这个。
AVFormatContext结构提供了一个 interrupt_callback 变量,用来设置回调函数,我们可以设置这个回调函数,用来检测超时。
如下设置:
ctx->interrupt_callback.callback = interrupt_cb; // 这个是我们的回调函数,在此函数中用于检测写操作是否超时。
ctx->interrupt_callback.opaque = this; //
如果不是写到本地磁盘,而是网络通讯,我们还必须调用avio_open2来初始化网络。如下所示:
if (!(fmt->flags & AVFMT_NOFILE)) {
////以AVIO_FLAG_WRITE写方式打开,因为我们是推流,只写不读,stream_url 就是RTSP,RTMP的URL地址。
ret = avio_open2(&ctx->pb, stream_url.c_str(), AVIO_FLAG_WRITE, &ctx->interrupt_callback, NULL );
}
初始化就这样完成了。接下来,需要把头信息写入,这时候调用 avformat_write_header 函数来写头部信息。
写完头部信息,我们就可以不断调用av_interleaved_write_frame 或者 av_write_frame, 把已经编码好的视频帧和音频帧写入。
ffmpeg底层框架会根据不同协议,做不同的推送处理。
等推流结束了,调用av_write_trailer写入尾部信息,
如果是写到本地视频文件,一定需要调用av_write_trailer,否则视频文件无法正常使用。
以上流程应该是非常简洁明了的。
在这里我们只需要ffmpeg的混合器功能,不需要打开编码器,因此与muxing.c例子不同的是,在avformat_new_stream创建流之后,
不必调用avcodec_open2来打开具体的编码设备。
既然不打开具体的编码设备,在调用avformat_write_header 写头部信息的时候,ffmpeg框架是不清楚要写哪些头部信息的,
因此,我们在调用 avformat_write_header 前,必须还做些额外的工作:
那就是填写 每个ffmpeg编码器的 extradata 字段,告诉ffmpeg,头部应该写些什么进去。
比如对于H264编码的视频,我们应该填写 H264 AVCC 格式的extradata头,用来存储 SPS,PPS 。
这个几乎是固定的填写方法,如下:
假设SPS,PPS的buffer和长度分别是:sps_buffer,pps_buffer 和 sps_len,pps_len。
AVCodecContext* c = video_stream->codec; // video_stream 是avformat_new_stream创建视频流返回的AVStream对象。
int extradata_len = 8 + sps_len + pps_len + 2 + 1;
c->extradata_size = extradata_len;
c->extradata = (byte*)av_mallocz(extradata_len);
int i = 0;
byte* body = (byte*)c->extradata;
//H264 AVCC 格式的extradata头,用来存储 SPS,PPS
body[i++] = 0x01;
body[i++] = sps_buffer[1];
body[i++] = sps_buffer[2];
body[i++] = sps_buffer[3];
body[i++] = 0xff;
//// SPS
body[i++] = 0xe1;
body[i++] = (sps_len >> 8) & 0xff;
body[i++] = sps_len & 0xff;
memcpy(&body[i], sps_buffer, sps_len);
i += sps_len;
/// PPS
body[i++] = 0x01;
body[i++] = (pps_len >> 8) & 0xff;
body[i++] = (pps_len) & 0xff;
memcpy(&body[i], pps_buffer, pps_len);
i += pps_len;
对于AAC音频编码的extradata字段,则按照如下方式:
假设声道数是audio_channel, 采样率序号是audio_sample_index,
AAC编码方式(比如是LC,HEv1,HEv2等)是audio_aot, 这些参数都可以从 带有ADTS头的AAC编码数据里边解析出来。
至于如何解析,可稍后查看我发布到CSDN或GITHUB上的源代码。
////// audio, ADTS头转换为MPEG-4 AudioSpecficConfig
c = audio_stream->codec; ///audio_stream是创建的音频流
c->extradata_size = 2;
c->extradata = (byte*)av_malloc(2);
byte dsi[2];
dsi[0] = ((audio_aot+1) << 3) | (audio_sample_rate_index >> 1);
dsi[1] = ((audio_sample_rate_index & 1) << 7) | (audio_channel << 3);
memcpy(c->extradata, dsi, 2);
正确填写 音频和视频对应的extradata字段之后,就可以放心的调用 avformat_write_header函数写入头部信息。
这个时候ffmpeg框架判断如果是rtsp,rtmp之类的则开始建立链接,发送各种初始化信息,和头部信息。
如果是写本地视频文件,则写入视频头信息到文件。
然后,我们就开始调用 av_interleaved_write_frame 函数真正的写已经编码好的H264视频帧和AAC音频帧了。
再开始H264帧前,先了解一些基本概念。
H264视频码流目前有两种打包模式:一种是Annex-B的打包格式,另一种是AVCC打包格式。
Annex-B是传统的打包格式,绝大部分H264编码器和解码器都支持这种格式。在实时传输上用得很多,
我们使用x264,openh264默认都是编码出这种打包格式。
AVCC这种打包格式主要用在文件存储上,比如存储成MP4,MKV等文件,
而在RTSP,RTMP这类通讯协议上,也必须采用AVCC格式。
两者的主要区别:
我们知道,H264是以NALU包来存储每个slice分片,每个H264帧,可能存储多个slice,
也就是可能每帧H264编码的视频数据,可以包括一个NALU或者多个NALU。
Annex-B打包格式是以00 00 01(三个字节)或者00 00 00 01(四个字节)开始码来分隔NALU,
而且把SPS,PPS也打包在一起,也是以开始码分隔。
在AVCC格式中,每个NALU前面是4个字节来表示这个NALU的长度,
而SPS,PPS是分开来存储,存储格式就是上面填写ffmpeg的extradata字段采用的存储格式。
同理,AAC音频也是差不多的,我们在实时传输时候,一般都会编码出带ADTS头部的AAC数据,
而在存储文件或者推送 RTMP,RTSP协议的时候,使用的是 MPEG-4 AudioSpecficConfig 格式,因此一样需要做转换。
这里需要提示一下,ffmpeg有个自带的AAC编码器,它编码的AAC数据默认是不带 ADTS头部的,
我们一般采用的是fdk-aac库,这个库编码AAC是可以带ADTS头部的。
在这里,输入的实时H264码流都是Annex-B标准格式,而且是每个IDR帧(关键帧)前都会有SPS,PPS。
输入的实时AAC码流,都是带ADTS头部的。
我们都会在内部处理的时候对这种格式转换到RTSP, RTMP推流和本地文件识别的格式,
具体解析处理办法,可查看稍后发布到CSDN或GITHUB上的代码。
似乎一切都妥当了,拿到已经编码好的数据,直接调用 av_interleaved_write_frame 写入就可以了,
其实还有一个大麻烦,就是PTS的问题,音频和视频同步的问题。
这是很讨厌的问题。
PTS我们必须手动计算, 计算这个倒也不难,
我们在开始推流的时候,就是调用avformat_write_header 函数之后,记录开始时间 start_time=av_gettime(); //单位是微妙
然后每个实时音频或视频包到达时间 curr = av_gettime(); 这样计算PTS:(下面是视频PTS)
pts = (curr - start_time )*1.0/1000000.0/av_q2d(video_stream->time_base);//video_stream是创建的视频流
接下来的就是同步的问题了。
我们推流的是桌面屏幕和是电脑内部声音,这跟一般的一直在动的视频不大一样。
有可能长时间,电脑屏幕都没任何变化;很长时间,电脑都不发一声响声。
一般采用同步方法基本如下三种:
1,以视频为准,就是让视频以恒定的速度,比如30帧每秒,音频根据视频速度来定位。
2,以音频为准,让音频以恒定速度,比如每秒48000的采样率,视频根据音频来定位。
3,以外部的某个时钟为准来同步。
除第三个办法不知道该怎么操作外,1, 2都比较好理解。
如果按照1 的办法,显然不大现实,因此只好采用第2种办法,让音频以恒定速度传输。
既然是让音频以恒定速度传输,也就是时时刻刻都有数据帧,而电脑内部可能很长时间都没有发声。
也就是没声音数据。这个时候,我们就得造假了,在这段时间内,我们就得连续不断的制造静音帧。
以AAC编码为例,AAC编码的每个sample的大小是固定为1024,
比如是双声道,16位采样,则每次都需要输入固定 1024*2*2=4096字节大小的数据,才能编码出一帧AAC的数据。
也就是我们造假,每次都输入4096大小的空白数据(就是全是0)让它编码出一帧静音AAC帧。
我们再来计算每一帧AAC数据播放的持续时间。
假设还是双声道,16位采样。
假设每秒48000的采样率,则每秒可以制造2*2*48000字节 = 192000字节 的PCM原始声音数据。每帧AAC是4096字节,我们做除法。
4096/192000 = 0.0213秒=21.3毫秒。
在48000采样率的情况下,每帧AAC数据的播放持续时间大约是21毫秒。
也就是我们每隔21毫秒就要制造一个静音AAC帧推送出去,这样在没有外部声音的情况下,才能保证声音的持续不断。
在windows平台,可以使用timeSetEvent 函数来达到精确定时。
如下伪代码:
////
timeSetEvent( 30 , 10, audioTimer, (DWORD_PTR)this,
TIME_PERIODIC | TIME_KILL_SYNCHRONOUS | TIME_CALLBACK_FUNCTION);
///////
void CALLBACK audioTimer(UINT uID, UINT uMsg, DWORD_PTR dwUser, DWORD_PTR dw1, DWORD_PTR dw2){
int64_t cur = av_gettime(); ///
////
int max_cnt = 4;
Lock();
int64_t step = (int64_t)1024 * 1000 * 1000 / audio_sample_rate; // us,每个AAC压缩帧播放的时间
int64_t last = max( cur - max_cnt*step, last_audio_timestamp + step );
///
strm_pkt_t pkt; memset(&pkt, 0, sizeof(pkt));
pkt.type = AUDIO_STREAM;
pkt.data = audio_mute_data; ///已经编码好的AAC静音帧
pkt.length = audio_mute_size;
pkt.rawptr = NULL;
/////
while (last <= cur -step ) { ////
///
pkt.timestamp = last;
last_audio_timestamp = last;
////
post_strm_pkt(&pkt); ////投递AAC帧
/////
last += step;
}
Unlock();
}
具体可查询稍后发布到CSDN或GITHUB代码工程。
前面文章分别阐述了,如何抓取电脑屏幕数据,如何采集电脑声音,
如何实现在现代浏览器中通过HTML5和WebSocket直接进行远程控制。
这章阐述如何把采集到的电脑屏幕和电脑声音,通过一些通用协议,
比如RTSP,RTMP把电脑桌面屏幕推送到更广泛的直播服务器上,达到电脑屏幕直播的效果。
或者把电脑屏幕保存成本地的MP4或MKV视频文件。
其实 https://github.com/fanxiushu/xdisp_virt 或 https://download.csdn.net/download/fanxiushu/10168823 提供的程序,
其中xdisp_server.exe中转服务器,本身就是个直播服务器的效果。
只不过xdisp_server.exe不但能直播屏幕和声音,还能远程控制,实时性要求也更高。
还能直接在网页中播放,只是使用的是自己定义的私有通讯协议。
为了把我们的电脑屏幕无私的共享出去,而且让别人更好的中转,加速,就得使用一些比较广泛使用的协议,
比如RTSP, 这个一般在视频监控领域用得比较多,实时性要求也比较高,不过我在内网测试下来,总有几秒的延迟。
播放器使用VLC, RTSP是在linux上架设的 easydarwin 测试服务器,当然也就是随便架设,没做什么优化。
也可能播放的屏幕尺寸太大,是 2560X1600 的视频尺寸。
另一个RTMP协议在当前互联网直播推流中用得很多,linux我使用的是nginx+rtmp_module,这个的延时就更加糟糕,
最差能达到十几秒的延迟。而且是越播放越往后延迟。当然都是属于测试性质的架设这些服务器,主要是为了测试开发
RTSP,RTMP推流客户端。
RTSP,RTMP这类协议的开源库不少,这里并不打算介绍通讯协议细节。也没仔细去研究过这些通讯协议。
无非就是在TCP或UDP链接中,以一个一个的数据包分界的方式,传递视频帧或者音频帧。
这在我们自己定义的私有通讯协议中也是这么做的,比起研究这些通用协议格式,
更愿意自己来实现,因为更加灵活,就比如xdisp_virt.exe远程控制程序里,在一条TCP链接里,不单传输音视频帧,
还传输鼠标键盘数据包,还传输各种控制信息数据包,以及其他需要的数据包,想想都挺热闹的。
一开始使用的是librtmp开源库,因为当时只局限于实现RTMP推流,没考虑其他的,
只是等使用librtmp实现了之后,发现使用VLC播放,总是只找到音频流,没有视频,试了多次都是这样。
当时找不到原因(其实后来找到原因是因为设置的关键帧间隔太大,
足有800这么大,这在我的私有通讯协议中没问题,因为发现缺少SPS,PPS。都会通知被控制端重新刷出关键帧。),
也就打算放弃使用librtmp库,另外使用其他开源库,后来发现ffmpeg也能实现rtmp推流,
再仔细查看ffmpeg,发现不但能rtmp推流,还能rtsp推流,http推流,还能保存到本地mp4,mkv等多种格式的视频文件。
既然有这么多这么强大的功能,干嘛死抱着librtmp不放。
而且把桌面屏幕保存到本地视频文件,一直都是我想做的事,苦于自己对这些MP4封装格式不大了解。
使用的是ffmpeg的3.4的版本,在这个版本中的 doc/example 目录中的 muxing.c 源代码,就是实现如何推流的例子。
之所以取名 muxing.c, 在ffmpeg开发团队看来,rtmp,rtsp这些推流,其实也是把音频和视频混合成一定格式”保存“。
跟本地MP4等文件一样的概念。正是这样的做法,我们可以在muxing.c中,
使用的ffmpeg统一的API函数,既可以把音视频保存到本地多种格式的文件,
也可以实时的以rtmp,http,rtsp等多种方式推送到流媒体服务器端,非常的方便。
muxing.c例子代码中,输入原始YUV图像数据或原始声音数据,然后编码,然后混合写入文件或者推流,一气呵成。
但是我们这里需要的功能是只需要把已经编码好的音视频(H264和AAC)数据帧,直接写入混合器。
而且要实现可以同时朝多个混合器写数据。也就是我们可以同时保存到本地MP4文件,
也同时可以朝多个RTSP或RTMP服务器做推流。
如下图的配置界面,就是最新版本xdisp_virt程序做的推流的网页方式的配置界面:
图中设置了三个推流地址,分别朝RTSP, RTMP服务器推送音视频,同时保存到d盘的t.mp4视频文件中。
在我们的xidsp_virt远程桌面控制程序中,编码好的桌面图像数据和声音数据,
一边要发送给多个WebSocket通讯的网页客户端,一边要发送给多个原生客户端(当然还包括发送给中转服务端),
现在还要发送给RTMP,RTSP,同时保存到本地文件等,
如果朝每个终端发送音视频流都做一次编码,是不现实的。这就是为何要把muxing.c例子代码里边的编码部分剥离出去,
只保留把编码好的音视频帧直接写入混合器的功能。
我们先来看看调用ffmpeg的API的流程,其实是挺简单,函数也不多:
首先调用avformat_alloc_output_context2 创建AVFormatContext变量,最后一个参数就是推流地址,或者保存本地的完整路径,
比如:
AVFormatContext* ctx;
avformat_alloc_output_context2(&ctx, NULL, "flv", "rtmp://192.168.88.1/hls/test"); // 以RTMP协议推送
avformat_alloc_output_context2(&ctx, NULL, "rtsp", "rtsp://192.168.88.1/test"); // 以RTSP协议推送
avformat_alloc_output_context2(&ctx, NULL,NULL, "d:\\Screen.mp4") ; //保存到本地 Screen.mp4视频文件中。
之后调用 avformat_new_stream 函数创建视频流和音频流,并且添加到ctx变量中。
比如如下代码就是创建编码类型为H264和AAC的视频和音频流:
AVOutputFormat *fmt = ctx->oformat;
////固定 H264 + AAC 编码
fmt->video_codec = AV_CODEC_ID_H264;
fmt->audio_codec = AV_CODEC_ID_AAC;
codec = avcodec_find_encoder(AV_CODEC_H264);
AVStream* st = avformat_new_stream( ctx, codec);
...... //其他初始化
codec = avcodec_find_encoder(AV_CODEC_AAC);
AVStream* st = avformat_new_stream( ctx , codec);
...... //其他初始化
因为RTSP,RTMP都是网络通讯,网络环境复杂多变就必须面临一个通讯超时问题,写到本地磁盘倒不必关心这个。
AVFormatContext结构提供了一个 interrupt_callback 变量,用来设置回调函数,我们可以设置这个回调函数,用来检测超时。
如下设置:
ctx->interrupt_callback.callback = interrupt_cb; // 这个是我们的回调函数,在此函数中用于检测写操作是否超时。
ctx->interrupt_callback.opaque = this; //
如果不是写到本地磁盘,而是网络通讯,我们还必须调用avio_open2来初始化网络。如下所示:
if (!(fmt->flags & AVFMT_NOFILE)) {
////以AVIO_FLAG_WRITE写方式打开,因为我们是推流,只写不读,stream_url 就是RTSP,RTMP的URL地址。
ret = avio_open2(&ctx->pb, stream_url.c_str(), AVIO_FLAG_WRITE, &ctx->interrupt_callback, NULL );
}
初始化就这样完成了。接下来,需要把头信息写入,这时候调用 avformat_write_header 函数来写头部信息。
写完头部信息,我们就可以不断调用av_interleaved_write_frame 或者 av_write_frame, 把已经编码好的视频帧和音频帧写入。
ffmpeg底层框架会根据不同协议,做不同的推送处理。
等推流结束了,调用av_write_trailer写入尾部信息,
如果是写到本地视频文件,一定需要调用av_write_trailer,否则视频文件无法正常使用。
以上流程应该是非常简洁明了的。
在这里我们只需要ffmpeg的混合器功能,不需要打开编码器,因此与muxing.c例子不同的是,在avformat_new_stream创建流之后,
不必调用avcodec_open2来打开具体的编码设备。
既然不打开具体的编码设备,在调用avformat_write_header 写头部信息的时候,ffmpeg框架是不清楚要写哪些头部信息的,
因此,我们在调用 avformat_write_header 前,必须还做些额外的工作:
那就是填写 每个ffmpeg编码器的 extradata 字段,告诉ffmpeg,头部应该写些什么进去。
比如对于H264编码的视频,我们应该填写 H264 AVCC 格式的extradata头,用来存储 SPS,PPS 。
这个几乎是固定的填写方法,如下:
假设SPS,PPS的buffer和长度分别是:sps_buffer,pps_buffer 和 sps_len,pps_len。
AVCodecContext* c = video_stream->codec; // video_stream 是avformat_new_stream创建视频流返回的AVStream对象。
int extradata_len = 8 + sps_len + pps_len + 2 + 1;
c->extradata_size = extradata_len;
c->extradata = (byte*)av_mallocz(extradata_len);
int i = 0;
byte* body = (byte*)c->extradata;
//H264 AVCC 格式的extradata头,用来存储 SPS,PPS
body[i++] = 0x01;
body[i++] = sps_buffer[1];
body[i++] = sps_buffer[2];
body[i++] = sps_buffer[3];
body[i++] = 0xff;
//// SPS
body[i++] = 0xe1;
body[i++] = (sps_len >> 8) & 0xff;
body[i++] = sps_len & 0xff;
memcpy(&body[i], sps_buffer, sps_len);
i += sps_len;
/// PPS
body[i++] = 0x01;
body[i++] = (pps_len >> 8) & 0xff;
body[i++] = (pps_len) & 0xff;
memcpy(&body[i], pps_buffer, pps_len);
i += pps_len;
对于AAC音频编码的extradata字段,则按照如下方式:
假设声道数是audio_channel, 采样率序号是audio_sample_index,
AAC编码方式(比如是LC,HEv1,HEv2等)是audio_aot, 这些参数都可以从 带有ADTS头的AAC编码数据里边解析出来。
至于如何解析,可稍后查看我发布到CSDN或GITHUB上的源代码。
////// audio, ADTS头转换为MPEG-4 AudioSpecficConfig
c = audio_stream->codec; ///audio_stream是创建的音频流
c->extradata_size = 2;
c->extradata = (byte*)av_malloc(2);
byte dsi[2];
dsi[0] = ((audio_aot+1) << 3) | (audio_sample_rate_index >> 1);
dsi[1] = ((audio_sample_rate_index & 1) << 7) | (audio_channel << 3);
memcpy(c->extradata, dsi, 2);
正确填写 音频和视频对应的extradata字段之后,就可以放心的调用 avformat_write_header函数写入头部信息。
这个时候ffmpeg框架判断如果是rtsp,rtmp之类的则开始建立链接,发送各种初始化信息,和头部信息。
如果是写本地视频文件,则写入视频头信息到文件。
然后,我们就开始调用 av_interleaved_write_frame 函数真正的写已经编码好的H264视频帧和AAC音频帧了。
再开始H264帧前,先了解一些基本概念。
H264视频码流目前有两种打包模式:一种是Annex-B的打包格式,另一种是AVCC打包格式。
Annex-B是传统的打包格式,绝大部分H264编码器和解码器都支持这种格式。在实时传输上用得很多,
我们使用x264,openh264默认都是编码出这种打包格式。
AVCC这种打包格式主要用在文件存储上,比如存储成MP4,MKV等文件,
而在RTSP,RTMP这类通讯协议上,也必须采用AVCC格式。
两者的主要区别:
我们知道,H264是以NALU包来存储每个slice分片,每个H264帧,可能存储多个slice,
也就是可能每帧H264编码的视频数据,可以包括一个NALU或者多个NALU。
Annex-B打包格式是以00 00 01(三个字节)或者00 00 00 01(四个字节)开始码来分隔NALU,
而且把SPS,PPS也打包在一起,也是以开始码分隔。
在AVCC格式中,每个NALU前面是4个字节来表示这个NALU的长度,
而SPS,PPS是分开来存储,存储格式就是上面填写ffmpeg的extradata字段采用的存储格式。
同理,AAC音频也是差不多的,我们在实时传输时候,一般都会编码出带ADTS头部的AAC数据,
而在存储文件或者推送 RTMP,RTSP协议的时候,使用的是 MPEG-4 AudioSpecficConfig 格式,因此一样需要做转换。
这里需要提示一下,ffmpeg有个自带的AAC编码器,它编码的AAC数据默认是不带 ADTS头部的,
我们一般采用的是fdk-aac库,这个库编码AAC是可以带ADTS头部的。
在这里,输入的实时H264码流都是Annex-B标准格式,而且是每个IDR帧(关键帧)前都会有SPS,PPS。
输入的实时AAC码流,都是带ADTS头部的。
我们都会在内部处理的时候对这种格式转换到RTSP, RTMP推流和本地文件识别的格式,
具体解析处理办法,可查看稍后发布到CSDN或GITHUB上的代码。
似乎一切都妥当了,拿到已经编码好的数据,直接调用 av_interleaved_write_frame 写入就可以了,
其实还有一个大麻烦,就是PTS的问题,音频和视频同步的问题。
这是很讨厌的问题。
PTS我们必须手动计算, 计算这个倒也不难,
我们在开始推流的时候,就是调用avformat_write_header 函数之后,记录开始时间 start_time=av_gettime(); //单位是微妙
然后每个实时音频或视频包到达时间 curr = av_gettime(); 这样计算PTS:(下面是视频PTS)
pts = (curr - start_time )*1.0/1000000.0/av_q2d(video_stream->time_base);//video_stream是创建的视频流
接下来的就是同步的问题了。
我们推流的是桌面屏幕和是电脑内部声音,这跟一般的一直在动的视频不大一样。
有可能长时间,电脑屏幕都没任何变化;很长时间,电脑都不发一声响声。
一般采用同步方法基本如下三种:
1,以视频为准,就是让视频以恒定的速度,比如30帧每秒,音频根据视频速度来定位。
2,以音频为准,让音频以恒定速度,比如每秒48000的采样率,视频根据音频来定位。
3,以外部的某个时钟为准来同步。
除第三个办法不知道该怎么操作外,1, 2都比较好理解。
如果按照1 的办法,显然不大现实,因此只好采用第2种办法,让音频以恒定速度传输。
既然是让音频以恒定速度传输,也就是时时刻刻都有数据帧,而电脑内部可能很长时间都没有发声。
也就是没声音数据。这个时候,我们就得造假了,在这段时间内,我们就得连续不断的制造静音帧。
以AAC编码为例,AAC编码的每个sample的大小是固定为1024,
比如是双声道,16位采样,则每次都需要输入固定 1024*2*2=4096字节大小的数据,才能编码出一帧AAC的数据。
也就是我们造假,每次都输入4096大小的空白数据(就是全是0)让它编码出一帧静音AAC帧。
我们再来计算每一帧AAC数据播放的持续时间。
假设还是双声道,16位采样。
假设每秒48000的采样率,则每秒可以制造2*2*48000字节 = 192000字节 的PCM原始声音数据。每帧AAC是4096字节,我们做除法。
4096/192000 = 0.0213秒=21.3毫秒。
在48000采样率的情况下,每帧AAC数据的播放持续时间大约是21毫秒。
也就是我们每隔21毫秒就要制造一个静音AAC帧推送出去,这样在没有外部声音的情况下,才能保证声音的持续不断。
在windows平台,可以使用timeSetEvent 函数来达到精确定时。
如下伪代码:
////
timeSetEvent( 30 , 10, audioTimer, (DWORD_PTR)this,
TIME_PERIODIC | TIME_KILL_SYNCHRONOUS | TIME_CALLBACK_FUNCTION);
///////
void CALLBACK audioTimer(UINT uID, UINT uMsg, DWORD_PTR dwUser, DWORD_PTR dw1, DWORD_PTR dw2){
int64_t cur = av_gettime(); ///
////
int max_cnt = 4;
Lock();
int64_t step = (int64_t)1024 * 1000 * 1000 / audio_sample_rate; // us,每个AAC压缩帧播放的时间
int64_t last = max( cur - max_cnt*step, last_audio_timestamp + step );
///
strm_pkt_t pkt; memset(&pkt, 0, sizeof(pkt));
pkt.type = AUDIO_STREAM;
pkt.data = audio_mute_data; ///已经编码好的AAC静音帧
pkt.length = audio_mute_size;
pkt.rawptr = NULL;
/////
while (last <= cur -step ) { ////
///
pkt.timestamp = last;
last_audio_timestamp = last;
////
post_strm_pkt(&pkt); ////投递AAC帧
/////
last += step;
}
Unlock();
}
具体可查询稍后发布到CSDN或GITHUB代码工程。
至此,我们利用ffmpeg实现了RTSP, RTMP推流,以及保存到本地MP4或MKV视频文件。
源代码下载:
GITHUB下载地址:
https://github.com/fanxiushu/stream_push
CSDN下载地址:
https://download.csdn.net/download/fanxiushu/10536116