写在前面
最近在写论文过程中,研究了一些关于概率统计的算法,也从网上收集了不少资料,在此整理一下与各位朋友分享。
隐马尔可夫模型,简称HMM(Hidden Markov Model), 是一种基于概率的统计分析模型,用来描述一个系统隐性状态的转移和隐性状态的表现概率。
本文适用于对HMM感兴趣的入门读者,为了让文章更加通俗易懂,我会多阐述数学思想,尽可能的撇开公式,撇开推导。结合实际例子,争取做到雅俗共赏,童叟无欺。没有公式,就没有伤害。
建议看一下吴军博士的《数学之美》,里面有简单的说明。然后看下HMM的三个计算问题和对应的解答,你会发现基本就是动态规划的思想。
本文非完全原创,部分内容来自互联网,自己在此基础上加入了个人的理解,如有侵权还请告知!
从掷骰子说起
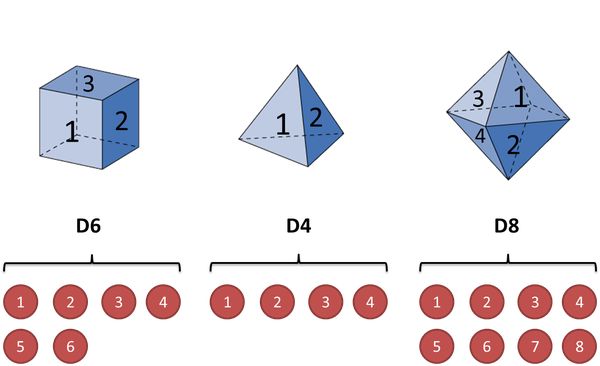
假设我手里有三个不同的骰子:
- 第一个骰子是我们平常见的骰子(称这个骰子为D6),6个面,每个面(1,2,3,4,5,6)出现的概率是1/6。
- 第二个骰子是个四面体(称这个骰子为D4),每个面(1,2,3,4)出现的概率是1/4。
- 第三个骰子有八个面(称这个骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是1/8。
现在开始掷骰子:
- 挑骰子:从三个骰子里挑一个(挑到每一个骰子的概率都是1/3)
- 掷骰子:将得到一个数字(1,2,3,4,5,6,7,8中的一个)
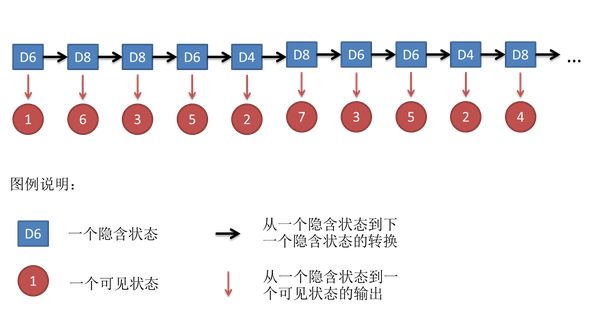
不停的重复上述过程,我们会得到一串数字,例如我们可能得到这么一串数字(掷骰子10次):
1 6 3 5 2 7 3 5 2 4
我们称这串数字叫做可见状态链。
在隐马尔可夫模型中,不仅仅有这么一串可见状态链,还有一串隐含状态链。在这个例子里,这串隐含状态链就是你用的骰子的序列。比如,隐含状态链有可能是:
D6 D8 D8 D6 D4 D8 D6 D6 D4 D8
一般来说,HMM中说到的马尔可夫链其实是指隐含状态链,因为隐含状态(骰子)之间存在转换概率(transition probability)。
在这个例子里,D6的下一个状态是D4,D6,D8的概率都是1/3。D4,D8的下一个状态是D4,D6,D8的转换概率也都一样是1/3。我们其实可以随意设定转换概率的。比如,我们可以这样定义:D6后面不能接D4,D6后面是D6的概率是0.9,是D8的概率是0.1。这样就是一个新的HMM。

同样的,尽管可见状态之间没有转换概率,但是隐含状态和可见状态之间有一个概率叫做输出概率(emission probability)。就我们的例子来说,六面骰(D6)产生1的输出概率是1/6。产生2,3,4,5,6的概率也都是1/6。我们同样可以对输出概率进行其他定义。比如,我有一个被赌场动过手脚的六面骰子,掷出来是1的概率更大,是1/2,掷出来是2,3,4,5,6的概率是1/10。
其实对于HMM来说,如果提前知道所有隐含状态之间的转换概率和所有隐含状态到所有可见状态之间的输出概率,做模拟是相当容易的。但在实际运用中,往往会缺失一部分信息:有时候你知道骰子有几种,每种骰子是什么,但是不知道掷出来的骰子序列;有时候你知道骰子序列,剩下的什么都不知道。如何应用算法去估计这些缺失的信息,就成了一个很有研究价值的问题。这些算法我会在下面详细讲。
和HMM模型相关的算法主要分为三类,分别解决三种问题:
知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道每次掷出来的都是哪种骰子(隐含状态链)。这个问题,在语音识别领域,叫做解码问题。这个问题其实有两种解法,会给出两个不同的答案。每个答案都对,只不过这些答案的意义不一样。第一种解法求最大似然状态路径,说通俗点,就是我求一串骰子序列,这串骰子序列产生观测结果的概率最大。第二种解法,就不是求骰子序列了,而是求每次掷出的骰子分别是某种骰子的概率。比如说我看到结果后,我可以求得第一次掷骰子是D4的概率是0.5,D6的概率是0.3,D8的概率是0.2。第一种解法我会在下面说到,但是第二种解法我就不写在这里了。
还是知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道掷出这个结果的概率。看似这个问题意义不大,因为你掷出来的结果很多时候都对应了一个比较大的概率。问这个问题的目的,其实是检测观察到的结果和已知的模型是否吻合。如果很多次结果都对应了比较小的概率,那么就说明我们已知的模型很有可能是错的,有人偷偷把我们的骰子给换了。
知道骰子有几种(隐含状态数量),不知道每种骰子是什么(转换概率),观测到很多次掷骰子的结果(可见状态链),我想反推出每种骰子是什么(转换概率)。这个问题很重要,因为这是最常见的情况。很多时候我们只有可见结果,不知道HMM模型里的参数,我们需要从可见结果估计出这些参数,这是建模的一个必要步骤。
问题阐述完了,下面就开始说解法。
一个简单问题
其实这个问题实用价值不高。由于对下面较难的问题有帮助,所以先在这里提一下。
知道骰子有几种,每种骰子是什么,每次掷的都是什么骰子,给出一串数字序列,求产生这个序列的概率。
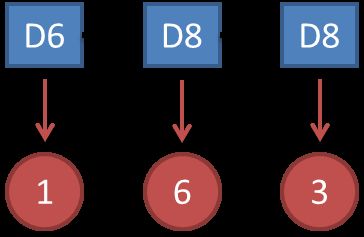
解法无非就是概率相乘:
破解骰子序列
这里我说的是第一种解法,解最大似然路径问题。
举例来说,我知道我有三个骰子,六面骰,四面骰,八面骰。我也知道我掷了十次的结果(1 6 3 5 2 7 3 5 2 4),我不知道每次用了哪种骰子,我想知道最有可能的骰子序列。
其实最简单而暴力的方法就是穷举所有可能的骰子序列,然后依照第零个问题的解法把每个序列对应的概率算出来。然后我们从里面把对应最大概率的序列挑出来就行了。如果马尔可夫链不长,当然可行。如果长的话,穷举的数量太大,就很难完成了。
另外一种很有名的算法叫做Viterbi algorithm. 要理解这个算法,我们先看几个简单的列子。
首先,如果我们只掷一次骰子:

看到结果为1,对应的最大概率骰子序列就是D4,因为D4产生1的概率是1/4,高于1/6和1/8.
把这个情况拓展,我们掷两次骰子:

结果为1,6,这时问题变得复杂起来,我们要计算三个值,分别是第二个骰子是D6,D4,D8的最大概率。显然,要取到最大概率,第一个骰子必须为D4。这时,第二个骰子取到D6的最大概率是
同上,我们可以计算第三个骰子是D6或D8时的最大概率。我们发现,第三个骰子取到D4的概率最大。而使这个概率最大时,第二个骰子为D6,第一个骰子为D4。所以最大概率骰子序列就是D4 D6 D4。
写到这里,大家应该看出点规律了,这其实就是概率DP问题(Dynamic Programming with Probability)。既然掷骰子一二三次可以算,掷多少次都可以以此类推。我们发现,我们要求最大概率骰子序列时要做这么几件事情:
- 首先,不管序列多长,要从序列长度为1算起,算序列长度为1时取到每个骰子的最大概率。
- 然后,逐渐增加长度,每增加一次长度,重新算一遍在这个长度下最后一个位置取到每个骰子的最大概率。因为上一个长度下的取到每个骰子的最大概率都算过了,重新计算的话其实不难。当我们算到最后一位时,就知道最后一位是哪个骰子的概率最大了。
- 最后,我们把对应这个最大概率的序列从后往前推出来。
谁动了我的骰子
如果你怀疑自己的六面骰被赌场动过手脚了,有可能被换成另一种六面骰,这种六面骰掷出来是1的概率更大,是1/2,掷出来是2,3,4,5,6的概率是1/10。怎么办?答案很简单,算一算正常的三个骰子掷出一段序列的概率,再算一算不正常的六面骰和另外两个正常骰子掷出这段序列的概率。如果前者比后者小,你就要小心了。比如说掷骰子的结果是:

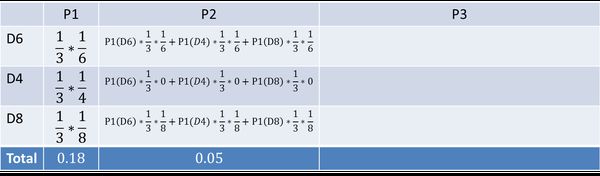
要算用正常的三个骰子掷出这个结果的概率,其实就是将所有可能情况的概率进行加和计算。同样,简单而暴力的方法就是把穷举所有的骰子序列,还是计算每个骰子序列对应的概率,但是这回,我们不挑最大值了,而是把所有算出来的概率相加,得到的总概率就是我们要求的结果。这个方法依然不能应用于太长的骰子序列(马尔可夫链)。我们会应用一个和前一个问题类似的解法,只不过前一个问题关心的是概率最大值,这个问题关心的是概率之和。解决这个问题的算法叫做前向算法( forward algorithm)。首先,如果我们只掷一次骰子:

看到结果为1.产生这个结果的总概率可以按照如下计算,总概率为0.18:

把这个情况拓展,我们掷两次骰子:

看到结果为1,6.产生这个结果的总概率可以按照如下计算,总概率为0.05:
继续拓展,我们掷三次骰子:

看到结果为1,6,3.产生这个结果的总概率可以按照如下计算,总概率为0.03:
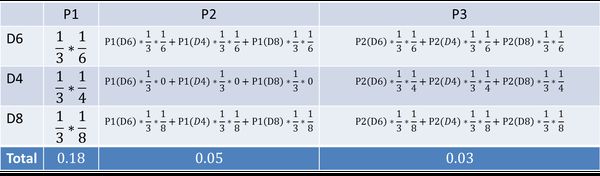
同样的,我们一步一步的算,有多长算多长,再长的马尔可夫链总能算出来的。用同样的方法,也可以算出不正常的六面骰和另外两个正常骰子掷出这段序列的概率,然后我们比较一下这两个概率大小,就能知道你的骰子是不是被人换了。
HMM 的应用
以上例子是用HMM对掷骰子进行建模与分析。当然还有很多HMM经典的应用,能根据不同的应用需求,对问题进行建模。
但是使用HMM进行建模的问题,必须满足以下条件:
- 隐性状态的转移必须满足马尔可夫性(状态转移的马尔可夫性:一个状态只与前一个状态有关)
- 隐性状态必须能够大概被估计
在满足条件的情况下,确定问题中的隐性状态是什么,隐性状态的表现可能又有哪些。
HMM适用的问题:真正的状态(隐态)难以被估计,而状态与状态之间又存在联系。
语音识别
语音识别问题就是将一段语音信号转换为文字序列的过程。
在个问题里面,隐性状态就是: 语音信号对应的文字序列。而显性状态就是: 语音信号。
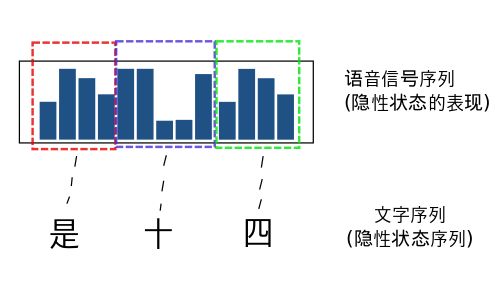
MM模型的学习(Learning): 语音识别的模型学习和上文中通过观察骰子序列建立起一个最有可能的模型不同。
语音识别的HMM模型学习有三个步骤:
- 统计文字的发音概率,建立隐性表现概率矩阵
- 统计字词之间的转换概率(不需要考虑语音,直接统计字词之间的转移概率即可)
- 语音模型的估计(Evaluation): 计算"是十四”,"四十四"等等的概率,比较得出最有可能出现的文字序列。
由此可见,其原理和上面的破解骰子序列是一样的。
手写识别
手写识别(HandWriting Recognition)是指将在手写设备上书写时产生的有序轨迹信息化转化为文字的过程。
原理和语音差不多,只不过手写识别的过程是将字的图像当成了显性序列。
中文分词
总所周知,在汉语中,词与词之间不存在分隔符,词本身也缺乏明显的形态标记(英文中,词与词之间用空格分隔,这是天然的分词标记)。因此,中文信息处理的特有问题就是如何将汉语的字串分割为合理的词语序。

例如,英文句子:you should go to kindergarten now. 天然的空格已然将词分好,只需去除其中的介词“to”即可;而“你现在应该去幼儿园了”这个句子表达同样的意思却没有明显的分隔符,中文分词的目的是得到“你/现在/应该/去/幼儿园/了”。那么如何进行分词呢?
主流的方法有三种:
- 第1类是基于语言学知识的规则方法,如:各种形态的最大匹配、最少切分方法。
- 第2类是基于大规模语料库的机器学习方法,这是目前应用比较广泛、效果较好的解决方案。用到的统计模型有N元语言模型、信道—噪声模型、最大期望、HMM等。
- 第3类也是实际的分词系统中用到的,即规则与统计等多类方法的综合。
拼音输入法
拼音输入法,是一个估测拼音字母对应想要输入的文字(隐性状态)的过程(比如, ‘pingyin’ -> 拼音)。
很明显,拼音输入法的观察序列就是用户的输入拼音,比如”wo shi zhong guo ren”,我们要推测出用户想要输入的是“我 是 中 国 人”,这是个很典型的隐马尔科夫模型。
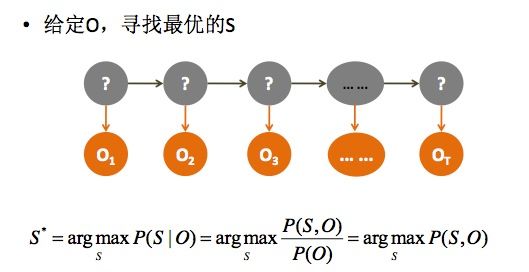
如上图所示,我们根据给定的观察对象O,获得一个概率最大的序列S*。我们所知道的数据有:
- 所有观察对象的值
- 隐藏序列的马尔科夫模型概率,这是通过统计获得的
- 隐藏状态到观察状态的概率,比如 “晴天”(隐藏状态) 到 “出去玩”(观察状态)的概率
我们要求的是S*各个状态的连续概率最大的那个序列,和上面同理。
结语
隐马尔可夫模型是可用于标注问题的统计学习的模型,描述由隐藏的马尔可夫链随机生成观测序列的过程,属于生成模型。
本文以一个例子为主线,用理论结合实际的方法讲解了HMM的基本原理和三个基本问题,以及三个问题的求解方法。最后,综述了一些HMM在人类的行为分析、网络安全和信息抽取中的最新应用。
参考文献
- 数学之美 - 吴军 - 隐马尔科夫模型
- 统计学习方法 - 李航 - 隐马尔科夫模型
- HMM学习最佳范例一:介绍 - 52nlp
- HMM学习最佳范例二:生成模式 - 52nlp
- POS - Stanford NLP
- 【整理】图解隐马尔可夫模型(HMM)