前言:
本篇中,将使用Scrapy爬取Jobbole中文章的各个字段,并存放到MySQL或存储为Json文件。
代码思路:
1、首先进行准备工作,例如,安装Scrapy、安装所需要的各种库等。
2、安装及配置所需的MySQL服务器。
3、分析要爬取的网站结构以及目标字段。
4、根据目标字段,设计Item的存储结构。
5、获取导航页面中的关键字段(文章URL)并交由Scrapy解析(Request)。
6、使用XPath解析文章页面的所需字段。
7、设计ImagePipeline,用于处理并保存图片。
8.1、通过JSON库,将数据存储为Json文件。
8.2、通过Scrapy自带的Json库,将数据存储为Json文件。
9、通过twisted,将数据异步存储至MySQL中。
代码执行步骤(一):
在使用Scrapy之前,首先要对其进行安装,并进行初始化,再安装后续代码中所需的库。以下操作都是在CMD中进行的,详见下述代码:
1、首先创建一个用于Scrapy的虚拟环境。
C:\Users\Administrator>mkvirtualenv Scrapy # 其中mkvirtualenv用于创建虚拟环境,Scrapy为虚拟环境的名称。
输出结果如下:
Using base prefix 'c:\\users\\administrator\\appdata\\local\\programs\\python\\python35'
New python executable in D:\Python\Evns\Scrapy\Scripts\python.exe
Installing setuptools, pip, wheel...done.
2、安装Scrapy框架及其他所需库:
(Scrapy) C:\Users\Administrator>pip install -i https://pypi.douban.com/simple/ pypiwin32 #安装Scrapy所需的库。
(Scrapy) C:\Users\Administrator>pip install -i https://pypi.douban.com/simple/ pillow #安装PIL库(用于处理图片)
(Scrapy) C:\Users\Administrator>pip install -i https://pypi.douban.com/simple/ scrapy #安装Scrapy。
3、创建Scrapy模板:
创建Scrapy项目:
(Scrapy) C:\Users\Administrator>d: # 将当前目录切换至虚拟环境所在的分区。
(Scrapy) D:\Python\Evns>cd Scrapy # 将当前目录切换至Scrapy所在的目录。
(Scrapy) D:\Python\Evns\Scrapy>scrapy startproject JobboleScrapy # 创建名为JobboleScrapy的Scrapy项目。
在创建Scrapy项目中,scrapy表示调用scrapy的命令(要在Scrapy的虚拟环境中)。startproject表示新建一个项目。JobboleScrapy表示新建项目的名称。
输出结果如下:
New Scrapy project 'JobboleScrapy', using template directory 'c:\\users\\administrator\\appdata\\local\\programs\\python\\python35\\lib\\site-packages\\scrapy\\templates\\project', created in:
C:\Users\Administrator\Envs\Scrapy\JobboleScrapy
You can start your first spider with:
cd JobboleScrapy
scrapy genspider example example.com
4、创建Spiders:
通过模板创建Spiders(创建并初始化Scrapy所需的各个模块):
(Scrapy) D:\Python\Evns\Scrapy>cd JobboleScrapy # 将目录切换至Scrapy项目中。
(Scrapy) D:\Python\Evns\Scrapy\JobboleScrapy>scrapy genspider Jobbole blog.jobbole.com # 创建Spiders。
在一个Scrapy项目中,可以同时爬取多个网站,而通常一个Spiders表示爬取的一个网站
其中scrapy同样表示调用scrapy的命令。
genspider表示创建一个spiders。
Jobbole表示所创建的spiders的名称。
blog.jobbole.com表示这个spiders所爬取的网站的种子URL。
代码执行步骤(二):
本次数据库采用MySQL,系统环境为CentOS7,同时,在安装系统前,已配置IP;IP地址为192.168.35.161。
针对CentOS7,需以下配置:
1、用于远程的SSH。
2、安装MySQL。
3、初始化MySQL。
4、配置Firewall防火墙。
1、安装SSH:
[root@localhost ~]# yum install openssh-server
2、安装MySQL:
[root@localhost ~]# yum install wget # 安装wget包。用于下载mysql的repo源文件。
[root@localhost ~]# wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm # 下载mysql的repo源文件。
[root@localhost ~]# rpm -ivh mysql-community-release-el7-5.noarch.rpm # 通过rpm来安装MySQL的repo源(下载地址)。
[root@localhost ~]# yum install mysql-server # 安装MySQL。
[root@localhost ~]# mysql -u root # 通过默认的root来登录mysql。
3、初始化MySQL。
mysql> set password for root@localhost = password('123'); # 初始化root账户的密码。
由于MySQL默认只能在本机登录,但当前环境下,我们需要通过Python来设置插入数据至MySQL中,所以要允许MySQL可以远程登录:
mysql> use mysql; # 首先选择默认的MySQL库。表示后续的操作都将在此库中进行。
mysql> SELECT User, Password, Host FROM user; # 首先查看默认的mysql用户表。
+------+-------------------------------------------+-----------------------+
| User | Password | Host |
+------+-------------------------------------------+-----------------------+
| root | *23AE809DDACAF96AF0FD78ED04B6A265E05AA257 | localhost |
| root | | localhost.localdomain |
| root | | 127.0.0.1 |
| root | | ::1 |
| | | localhost |
| | | localhost.localdomain |
+------+-------------------------------------------+-----------------------+
7 rows in set (0.00 sec)
在以上输出结果中,可以看到允许登录的地址为localhost(表示本机),用户名以及密码,密码是被md5加密的。
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'192.168.10.99'IDENTIFIED BY 'mima1' WITH GRANT OPTION; # 配置允许远程登录的IP地址,以及对应的密码。
根据自己的情况,分别设置允许远程的账户、IP、密码。
mysql> FLUSH PRIVILEGES; # 刷新表
mysql> create database Jobbole; # 创建稍等会用到的库、表以及各个字段。
mysql> use Jobbole; # 选择新建的库,表示后续的操作都围绕此库进行。
mysql> create table JobboleArticle (
-> post_title varchar(100) not null,
-> post_date date,
-> post_tag varchar(100),
-> post_like int,
-> post_image_url varchar(500) not null,
-> post_image_path varchar(500),
-> post_url varchar(500) not null,
-> post_object_id varchar(100) not null,
-> primary key (post_object_id))
-> charset=utf8;
Query OK, 0 rows affected (0.27 sec)
创建表,以及确定每个字段的名称、类型。
mysql> desc JobboleArticle;
+-----------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+--------------+------+-----+---------+-------+
| post_title | varchar(100) | NO | | NULL | |
| post_date | date | YES | | NULL | |
| post_tag | varchar(100) | YES | | NULL | |
| post_like | int(11) | YES | | NULL | |
| post_image_url | varchar(500) | NO | | NULL | |
| post_image_path | varchar(500) | YES | | NULL | |
| post_url | varchar(500) | NO | | NULL | |
| post_object_id | varchar(100) | NO | PRI | NULL | |
+-----------------+--------------+------+-----+---------+-------+
8 rows in set (0.01 sec)
查看当前表结构。
4、配置Firewall防火墙:
[root@localhost ~]# firewall-cmd --zone=public --permanent --add-port=3306/tcp # 开启MySQL的远程端口号,允许远程访问MySQL。
[root@localhost ~]# firewall-cmd --zone=public --permanent --add-port=22/tcp # 开启用于远程CentOS的SSH的22号端口。
[root@localhost ~]# systemctl stop firewalld # 重启防火墙以生效。
[root@localhost ~]# systemctl start firewalld
[root@localhost ~]# firewall-cmd --zone=public --permanent --list-ports # 查看当前开启的端口列表。
22/tcp 3306/tcp
代码执行步骤(三):
1、首先确定,我们希望爬取的网站的首页网址为:http://www.jobbole.com/
2、如果希望爬取网站中所有的文章,其URL为:http://blog.jobbole.com/
3、而Jobbole网站中的最新文章URL提供了一个列表,通过下一页的方式可以看到所有的文章URL。其URL为:http://blog.jobbole.com/all-posts/
4、当打开一篇文章,假设我们需要:标题内容、发布时间、文章类型、点赞数。
5、另外,我们需要在文章列表中爬取文章URL、封面图片URL。
6、在第3/4/5步骤中所有的字段,可以使用CSS和Xpath两种方式选定,根据选择的方式,使用其语法选择出相应的字段。
7、当爬取到封面图片URL后,将图片下载到本地,并修改图片的命名,再将图片的存放地址存储起来。
代码执行步骤(四):
1、新建一个Item类,用作Scrapy爬取、存储等各个阶段所使用的数据类型。
2、Scrapy自带了一种存储类型,类似于字典的形式。
3、定义Item之后,根据需要爬取的各个字段,设置不同的对象,并使用scrapy.Field()进行赋值(定义对象类型)。
具体代码如下:
import scrapy
class JobboleArticleItem(scrapy.Item):
post_title = scrapy.Field() # 文章标题。
post_date = scrapy.Field() # 文章发布时间。
post_tag = scrapy.Field() # 文章的标签。
post_image_url = scrapy.Field() # 文章封面图片的URL。
post_image_path = scrapy.Field() # 文章封面存储本地的地址。
post_url = scrapy.Field() # 文章的URL。
post_object_id = scrapy.Field() # 存储到数据库中后,文章的ID(MD5)
其中,我们创建的Item类所继承的Item类,是Scrapy中专门用于数据类型,基于字典,再由内部进行重写,实现其他字典无法实现的功能。
代码执行步骤(五):
1、首先使用Xpath语法,在网页中寻找到文章URL和封面图的节点。
2、然后将两个节点通过for迭代分别取出、复制。
3.1、然后将文章URL通过yield传递给Request函数,使其对文章页进行下载。
3.2、而Request()函数的第二个参数是一个函数,定义了获取文章具体内容的逻辑。
3.3、meta参数是一个字典,其中存储了文章封面URL和文章URL,一同传递给了parse_detail函数。
3.4、当在for循环中将本页中所有的文章URL抓取后,将抓取"下一页"的URL。
4.1、同样使用Xpath获取下一页的URL,(注意.extract_first()函数的应用)。
4.2、接着通过if判断,如果next_page的值不为空,则再将next_page(下一页的URL)通过Request()交给本函数(parse())再解析。
以下代码在Jobbole代码如下:
import scrapy
from scrapy.http import Request
class JobboleSpider(scrapy.Spider):
name = 'Jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/']
def parse(self, response):
post_node = response.xpath("//div[@class='post-thumb']/a") # 获取文章URL和封面图的节点。
for node in post_node:
post_url = node.xpath("@href").extract_first("") # 获取文章及图片的URL。
post_cover = {"post_image_url": node.xpath("img/@src").extract_first(""),
"post_url": post_url} # 创建一个字典,第一值为图片的URL,第二个值为文章的URL。
# meta参数接收一个字典,可以将字典传递到parse_detail中,用于处理封面图片。
yield Request(url=post_url, callback=self.parse_detail, meta=post_cover)
# 获取下一页URL。
# extract_first()函数会自动获取第一个元素,并返回string类型,如果没有元素,则抛出异常。
next_page = response.xpath("//a[@class='next page-numbers']/@href").extract_first()
if next_page:
yield Request(url=next_page, callback=self.parse)
上述代码解析:
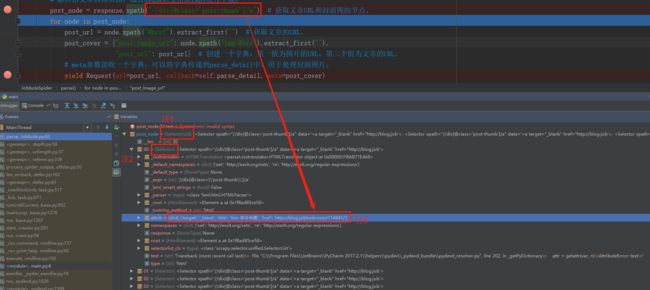
注1:可以在DeBug中看到,当通过xpath语法定位到正确的内容后,其返回的对象类型是SelectorList,即是一种可以迭代的选择器。
注2:当通过for循环迭代post_node后,赋值给node的类型是Selector,从而可以继续使用xpath等方式对定位的内容继续解析。
注3:而通过Xpath语法定位出的节点中,包含了文章标题的名字和文章的URL,但由于图片的URL是当前节点的子节点,所以没有显示出。
2、关于获取文章URL:
解析下述代码:
post_url = node.xpath("@href").extract_first("")
由于node是Selector,所以我们可以xpath对其继续解析,而在上述注3中,可以看到其现有的属性包含了href,这个属性是文章页的URL,所以直接使用.xpath("@href")即可获取到。
但这时的返回值仍然是Selector,并不能直接使用,所以调用.extract_first("")函数,表示只获取返回的列表中的第一个元素(str类型),如果列表是空的,则返回赋予的默认值。
当然也有其他类似.extract_first("")的函数,例如:
.extract() 表示返回所有符合Xpath语法且获取到的内容(list类型)。
.extract_first("") 表示返回符合Xpath语法且获取到的第一个list中的内容。
.re() 表示返回所有符合Xpath语法且获取到的内容(list类型),但list中的内容可以通过正则表达式进行解析。
.re_first() 同理。
也可以继续使用xpath()或css()继续进行解析。
3、关于继续解析Selector类型:
post_cover = {"post_image_url": node.xpath("img/@src").extract_first(""),"post_url": post_url}
值得注意的是,node对象本身是可以继续进行解析的,而通过node解析并使用extract_first("")解析出的结果并赋值给post_url是无法解析的,因为他的类型是str。
代码执行步骤(六):
1、在定义parse_detail()函数时,需要接收一个函数,这个函数是Scrapy爬取网页内容后的返回值。
2、然后初始化一个Item的对象,当通过Xpath获取到具体的节点内容后,需要赋值给Item。
3、接着通过Xpath获取节点内容。
4.1、在获取时间时,由于字段内容存在无效字符,所以需要删除。
4.2、但此时的post_date是str类型,所以需要转换为date类型。
4.3、另外,通过try(抛出异常),如果没有正确的获取到date或格式,则将当天的时间赋值给post_date。
5、和字典的使用方法类似,将获取到的值赋值给Item。
以下代码在Jobbole代码如下:
from JobboleScrapy.utils.ToMd5 import get_md5
import datetime
def parse_detail(self, response):
article_item = JobboleArticleItem() # 初始化Item,定义存储数据的数据类型。
post_title = response.xpath("//div[@class='entry-header']/h1/text()").extract_first()
post_date = response.xpath("//p[@class='entry-meta-hide-on-mobile']/text()[1]").extract_first()
# str类型的.strip()函数,默认将删除前后两端所有的空白字符,也可以输入一个str字符串来删除前后位置指定的字符串。
# 而如果指定的字符如果没有在首尾位置,则不会删除。即使参数字符分别存在首尾位置,也可以删除。
# 但由于.strip()只能删除首尾,并不能删除字符串中间位置的内容,所以还需要使用.translate()和.maketrans()。
# maketrans()函数用于创建一个"字符映射关系转换表",这个表用于将源字符转换成目标字符。
# maketrans()函数接收两个参数:第一个参数是一段字符串,表示需要转换的字符,即源字符。
# 第二个参数也是一段字符串,表示需要转换成何种字符,即目标字符。而两个字符串的长度必须相等,用于保证对应关系。
# 而如果希望删除任意字符,则需要在第三个参数中定义。而如果不希望替换其他元素,则将前两个参数定义为空字符串。
#
# 而.translate()函数是用于删除由.maketrans()函数所创建的"字符映射关系转换表"中的字符。
#
# 值得注意的是,在这种操作中,translate()函数不会区分你定义的需删除字符串是一个“单词”还是“字母”。
# 它会将你输入的所有字符同字符串中的所以字符进行相匹配,如果相同,则直接删除。
post_date = post_date.strip("\r\n· ").translate(str.maketrans("", "", "-/")) # 处理时间字符串,将无用的字符删除。
post_tag = response.xpath("//p[@class='entry-meta-hide-on-mobile']/a/text()").extract_first()
try:
post_date = datetime.datetime.strptime(post_date, "%Y%m%d").date()
except Exception as e:
post_date = datetime.datetime.now().date()
article_item["post_title"] = post_title
article_item["post_date"] = post_date
article_item["post_tag"] = post_tag
article_item["post_image_url"] = [response.meta["post_image_url"]]
article_item["post_url"] = response.meta["post_url"]
article_item["post_object_id"] = get_md5(response.url)
yield article_item # 传递到pipelines中,用于优化、处理、保存数据(默认需要在settings中启动pipelines)。
当然,在删除字符串"-/"时,也可以使用str..replace(),此处当有手动狗头。
另外,用于创建文件md5的代码如下:
import hashlib
def get_md5(url):
if isinstance(url, str):
url = url.encode("utf-8")
md5 = hashlib.md5()
md5.update(url)
return md5.hexdigest()
代码执行步骤(七):
1、首先重写get_media_requests()函数,此函数在ImagesPipeline中的from_settings()和init()执行结束后就立刻执行。
2、我们希望使用文章的名称作为图片名称,而不是默认的MD5。
3、get_media_requests(item,info)用于在每个Pipeline刚开始执行时,向里面加入meta字段。
4、接着执行file_path()函数,用于设置图片保存本地的位置,以及其名称。而名称是image_name。
5、最后Pipeline执行完成后,在item_completed()函数中,将results中的两个值取出,ok为图片是否获取成功,value是图片保存路径。
6、然后将图片保存路径存放到item中。
以下代码在pipelines中:
from scrapy.pipelines.images import ImagesPipeline
from scrapy import Request
from scrapy.exporters import JsonItemExporter
from twisted.enterprise import adbapi
import re
import codecs
import json
import MySQLdb
import MySQLdb.cursors
from datetime import datetime, date
class ArticleImagePipeline(ImagesPipeline):
def item_completed(self, results, item, info):
# 最后将执行item_completed()函数。
# 在结果中将value的path字段取出,也就是当前图片存储的路径及名称,然后放到item中。
# 最后将item返回,交给后续、其他的pipeline使用。
for ok, value in results:
image_file_path = value["path"]
item["post_image_path"] = image_file_path
return item
def get_media_requests(self, item, info):
post_name = item["post_title"] # 获取文章的标题,用作图片名称。
# item_url = self.images_urls_field # 测试获取图片URL字段名称。
# item_urls = item.get("post_image_url") # 测试获取图片URL。
# item_title = item.get("post_title") # 测试获取文章标题。
# self.images_urls_field表示当前图片的URL,他返回一个str类型的字符串,其值是item中存储图片URL的字段名。
# item.get()表示获取item中当前的数据,例如,上面代码中,根据不同的字段名可以获取不同的Item内容。
# 由于在一篇文章中可能获取多个图片,所以其返回一个List类型。
# 所以使用推导式将图片URL过滤出,赋值为X。
# 然后返回一个新的请求,第一个值是URL,也就是图片的URL,第二个值是放到请求中的字典。
return [Request(x, meta={"image_name": post_name}) for x in item.get(self.images_urls_field)]
def file_path(self, request, response=None, info=None):
# 当get_media_requests()中的新请求执行结束后,将返回一个request(结果).
# 首先在request()中将文章名称取出,然后通过正则表达式将文章名称中的奇怪字符删除。
# 最后返回一个存储图片的路径,以及该图片的名称。
image_name = request.meta["image_name"]
image_name = re.sub(r'[?\\*|“<>:/]', '', image_name)
return 'full/%s.jpg' % image_name
关于使用pipeline时,需要在settings中的设置:
1、启用pipeline:
当设计好一个pipeline后,需要在settings.py中启用这个pipeline,默认在settings.py中已经有了实例,我们可以根据自己的需要来进行修改。
ITEM_PIPELINES = {
# 'JobboleScrapy.pipelines.JsonWithEncodingPipeline': 200,
'JobboleScrapy.pipelines.ArticleImagePipeline': 50,
# 'JobboleScrapy.pipelines.MysqlTwistedPipline': 100,
}
即,首先确定pipeline的路径,接着定义一个0-1000的数值,这定义了每个pipeline的执行顺序,数值越小的,执行优先级越高。
2、神奇的IMAGES_URLS_FIELD:
在get_media_requests()中,我们使用self.images_urls_field就可以获取到在Item中,图片URL的字段名称,这也是因为IMAGES_URLS_FIELD常量已经在settings.py中进行了设置:
IMAGES_URLS_FIELD = "post_image_url"
3、图片具体的存储位置:
如果我们希望将图片存储到一个位置,将需要实现定义,这就需要在settings.py中设置IMAGES_STORE常量。
# IMAGES_STORE 表示下载图片所存储的位置。
# os.path.dirname() 表示获取一个文件的绝对路径。__file__返回本文件的路径。所以获取到settings.py的绝对路径(不含本文件)。
# 所以当前image_project的路径是JobboleScrapy这个目录。接着使用join(),用来路径拼接。
# 最终的路径为JobboleScrapy/images。当前也可以根据需求,设置到其他的目录中。
image_project = os.path.dirname(__file__)
IMAGES_STORE = os.path.join(image_project, "images")
代码执行步骤(八):
1、JSON通常用于数据在网络中的传输,有着类型XML的格式(自定义)。
2、可以分别Python的Json库和Scrapy的Json库来对数据进行封装。
3.1、而使用Python自带Json库时,如果格式化的内容中,包含了datetime或date类型时,默认无法对数据进行格式化。
3.2、所以需要json对数据进行解码。其内容在MyJsonDatetime类中。
4.1、首先在init函数中初始化,创建一个名为article.json的文件。
4.2、接着具体对数据的操作是在process_item()中进行的。
4.3、最后,每当写入一次数据,最后都会在spider_closed()中对文件进行关闭(否则会开启很多个)。
5.1、与Json库不同的是,使用JsonItemExporter需要将文件使用二进制的方式打开。
5.2、并且存储方式被封装了起来,分别成为启动exporting、具体添加和关闭。
5.3、相同的是都需要创建和关闭文件。
下列代码在pipelines.py中写入:
# (第四步)使用JSON库来将数据输出为Json文件。
class JsonWithEncodingPipeline(object):
def __init__(self):
# 在Python3中,codecs.open是对文件进行操作的函数。
# 第一个参数为创建或打开的文件名称,w表示写模式,如果文件不存在则创建。
# encoding="utf-8"表示该文件的格式为utf-8。
# 另外其他的操作类型如下:
# r 表示读取模式;
# w 表示写模式,如果文件不存在则创建,如果创建则重写其中的内容;
# x 表示在文件不存在的情况下创建并写入文件;
# a 表示如果文件存在,则在文件末尾追加内容。
# 也可以添加第二个操作类型:
# t(或省略)代表文本类型;
# b代表二进制文件(用于打开图片、视频等)。
self.file = codecs.open("article.json", "w", encoding="utf-8")
def process_item(self, item, spider):
# json.dumps()是用于将数据格式转换为Json格式,即字符串。它可以接受一个字典,字典中的类型不做限制(例如嵌套字典)。
# 首先,将item转换为一个字典格式。接着确定格式不为Ascii类型。
# 最后由于数据类型中包含了date,所以需要使用一个独立的类对数据进行重写转换确定编码。
lines = json.dumps(dict(item), ensure_ascii=False, cls=MyJsonDatetime) + "\n"
# 进行的写入操作。
self.file.write(lines)
# 返回item,以其他Pipeline使用。
return item
def spider_closed(self, spider):
# 当这个Pipeline即将结束后,执行此函数,用于关闭当前打开的文件。
self.file.close()
# 使用Python自带Json库时,如果格式化的内容中,包含了datetime或date类型时,默认无法对数据进行格式化。
# 所以需要json对数据进行解码。
# 如果不对数据进行格式化,将报错:TypeError: datetime.date(2018, 6, 4) is not JSON serializable
class MyJsonDatetime(json.JSONEncoder):
def default(self, o):
if isinstance(o, datetime):
return o.strftime('%Y-%m-%d %H:%M:%S')
elif isinstance(o, date):
return o.strftime('%Y-%m-%d')
else:
return json.JSONEncoder.default(self, o)
# (第五步)使用Scrapy自带的Json库将数据输出为Json文件。
class JsonExporterPipeline(object):
def __init__(self):
self.file = open("articleExport.json", "wb")
self.exporter = JsonItemExporter(self.file, encoding="utf-8", ensure_ascii=False)
# Scrapy已经将Json具体的操作进行封装,只需要在此Pipeline开始时,启动导出操作。
self.exporter.start_exporting()
def process_item(self, item, spider):
# 不需要进行转换,只有将item作为参数传输为exporter即可。
self.exporter.export_item(item)
return item # 仍需要将item返回出去。
def close_spider(self, spider):
# 当此Pipeline执行结束后,关闭exporting操作,并关闭文件即可。
self.exporter.finish_exporting()
self.file.close()
当需要测试或启用这两个pipeline时,需要在settings.py中启用。
代码执行步骤(九):
1、首先在from_settings()中,初始化MySQL的连接内容,并使用异步的方式对数据库进行操作。
2、接着在init()中初始化数据库连接池。
3、在Scrapy默认调用的process_item()函数中,调用do_insert(),对数据库进行数据填充。
class MysqlTwistedPipline(object):
def __init__(self, db_pool):
# 创建db_pool对象。
self.db_pool = db_pool
@classmethod
def from_settings(cls, settings):
# 数据库相关的内容,已经在settings.py中提前定义。
# cursorclass表示游标(cursor)类型,设置为DictCursor,表示当前执行查询操作时,返回的结果为字典。
# use_unicode表示返回的数据类型,如果为True,返回值则是Unicode,如果为False,返回值则为字符串。
# 另外,在dbparms中的字段名称,需要和MySQLDB中的connection设置的名称相同。
dbparms = dict(
host=settings["MYSQL_HOST"],
db=settings["MYSQL_DBNAME"],
user=settings["MYSQL_USER"],
passwd=settings["MYSQL_PASSWORD"],
charset="utf8",
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True
)
# 在Twisted中提供了以异步多线程访问数据库的模块abdapi。
# 其中ConnectionPool()可以创建一个数据库连接池对象,包括多个连接对象,每个连接对象在独立的线程中工作。
# 当然,abdapi只是封装了异步访问数据库的框架,其内部仍然是使用mysqldb来访问数据库。
db_pool = adbapi.ConnectionPool("MySQLdb", **dbparms)
# 将创建的数据库连接池返回为__init__()。
return cls(db_pool)
# 使用twisted将MySQL的插入变成异步执行。
def process_item(self, item, spider):
# runInteraction()可以以异步的方式调用insert_db()(mysqlDB执行插入的函数)。
# do_pool会在连接池中选择一个连接对象在独立的线程中调用insert_db()。
self.db_pool.runInteraction(self.do_insert, item)
# 执行具体的插入数据逻辑。
def do_insert(self, cursor, item):
post_image_url = item["post_image_url"][0]
insert_sql = """
insert into JobboleArticle
(post_title,post_date,post_tag,post_image_url,post_image_path,post_url,post_object_id)
VALUES
(%s,%s,%s,%s,%s,%s,%s)
"""
params = (item["post_title"], item["post_date"], item["post_tag"], post_image_url,
item["post_image_path"], item["post_url"], item["post_object_id"])
cursor.execute(insert_sql, params)
在settings.py中的设置内容:
MYSQL_HOST = "192.168.35.161"
MYSQL_DBNAME = "Jobbole"
MYSQL_USER = "root"
MYSQL_PASSWORD = "Qwer111,"
至此,本篇结束。