在本次案例中,我所需要做的便是通过已有的信息进行预测员工未来的动向,即判断该员工未来是否会离职。
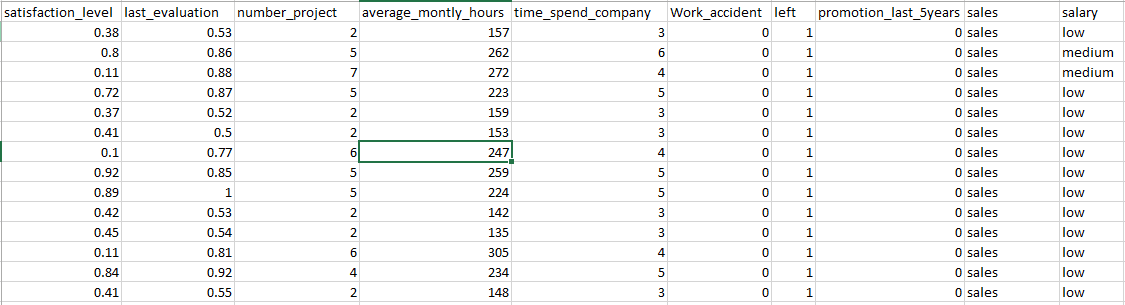
satisfaction_level:表示该员工对公司的满意度。
last_evaluation:该员工的对于公司的价值(取值为0-1,越高价值越大)
number_project:该员工总共完成的项目数
average_monthly_hours:平均每月工作时间
work_accident:是否出现过工作事故
left:是否已经离职(0表示未离职,1表示已经离职)
promotion_last_5years:在过去的5年中是否得到过升职
sales:工作岗位
salary:薪资水平(共三档。)PS(不要问我划分标准是什么。。。我表示我也很好奇)
以上便是数据集的全部介绍。同时如果大家想看到原始数据集和完整代码可以访问我的GitHub。接下来便是进行自己对这些数据集的一些思考。我所采用的工具是Pycharm,当然语言主要用到的就是Python喽。
首先导入数据集,代码如下所示:
# -*- coding: UTF-8 -*-
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
在本次库的运用中,我主要使用了pandas库(非常有名的一个machine learning的库)和绘图的库:matplotlib,以及基于其上的另外一种绘图的工具seaborn。当然还有驰名中外的numpy。
首先通过导入文件进行查看是否和原数据集是否一致。
filename = 'D:/kaggle/HR_comma_sep.csv'
data = pd.read_csv(filename)
print(data.head())
以上便把数据存储在我们声明的data变量之中了。PS(蛋疼的是pycharm中的console在输出过程中貌似默认自动换行,导致我console后面还有很大空间也自动换行,不知哪位高手可以解决这个问题)
现在我们拥有9个变量。初拿到数据或许我们对其一无所知,但是或许大家都有这样这些好奇点,譬如,员工的价值和其他8个变量中的哪一个更有联系?也就是说员工价值更主要的是由哪个因素所决定?
data_connection=data.corr()
plt.figure(figsize=(10,10))
sns.heatmap(data_connection,vmax=1.0,annot=True,square=True,cmap="YlGnBu")
plt.show()
显示结果如下所示:

通过上图我们可以得知,1.员工的满意度和该员工的公司价值关系更加明显。2.如果我们得到升职后,我们将更加情愿的进行工作(因为我们可以很明显的发现每月工作时间与其更有联系)。这张图可以更加明显的告诉我们这9个变量之间的相关度。
正如我在开文所提到的一样:薪水的三档是如何划分的?这个我肯定不知道。但是我可以知道这里的薪水是和哪些变量更有联系。。。。废话不说,直接上代码。
#因为共有十个变量,所以要/10
salary_low=data[data['salary']=='low']
salary_medium=data[data['salary']=='medium']
salary_high=data[data['salary']=='high']
print('the number of salary_low:',salary_low.size/10)
print('the number of salary_medium:',salary_medium.size/10)
print('the number of salary_high:',salary_high.size/10)
salary_low_mean=salary_low.mean()
salary_low_std=salary_low.std()
print(salary_low_mean.values.T)
print(salary_low_std.values.T)
salary_medium_mean=salary_medium.mean()
salary_medium_std=salary_medium.std()
print(salary_medium_mean)
print(salary_medium_std)
salary_high_mean=salary_high.mean()
salary_high_std=salary_high.std()
print(salary_high_mean)
print(salary_high_std)
最终得出的结果,我简单的用Excel表整理一下如图所示:
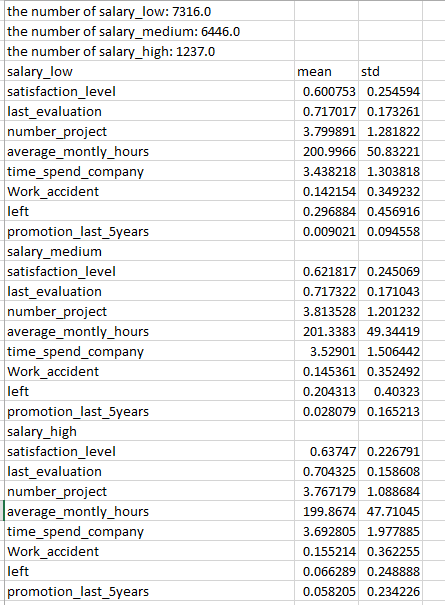
通过该图我们可以发现一些极其有意思的现象:
1.工资越低的人跳槽的可能性越大。。。因为(0.296884>0.204313>0.066289)
2.薪水越高的人,其在前五年得到晋升的可能性更大。并且其待在公司的时间更长。。。
3.同时薪水比较低的人,,反而每月工作时间更长(额。。。万恶的资本主义。。。。我要当老板。。。。)
接下来我需要看到一些薪水高的人都分布在哪个阶层,换言之我想知道哪个行业赚钱多,怎么实现呢?代码呗。
plt.figure(figsize=(10,10))
sns.factorplot(x='sales',kind='count',data=data,col='salary',col_wrap=3)
plt.show()
然后我们就得到这样一张图:
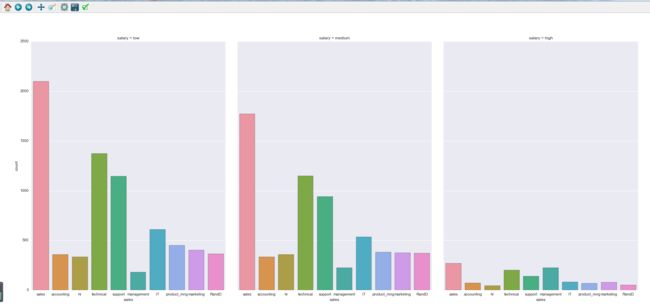
通过本图可以发现薪水阶层为low和medium时。职位为sales(销售)的人数比较多。。。很符合我们的认知,,,换句话说销售的工资比较低而且从事人数比较多。 我们伟大的IT职业薪水呢?,我果断直接观察当薪水为high的图表。(不要问我问什么?哥就是这么装逼。)然后看到之后就苦逼了。。。管理者明显占多数,同时可以知道销售和技术职位的待遇也不错。。然后轮到IT了。然后我就潜意识认为我所从事的行业是技术职位。。。对。。就是这样的。这就充分说明一个真理:万恶的资本主义,赚钱的永远都是管理层。。。
如果想更加清晰观察到其具体所占百分比,这也是可能的。上代码:
sales_categaries = ['sales', 'accounting', 'hr', 'technical', 'support', 'management', 'IT', 'product_mng', 'marketing',
'RandD']
sales_low_count = []
sales_medium_count = []
sales_high_count = []
salary_low=data[data['salary']=='low']
salary_medium=data[data['salary']=='medium']
salary_high=data[data['salary']=='high']
color=['c','m','r','b','yellow','green','gray','k','w']
for i in sales_categaries:
sales_low_count.append(salary_low[salary_low['sales']==i].shape[0])
for i in sales_categaries:
sales_medium_count.append(salary_medium[salary_medium['sales']==i].shape[0])
for i in sales_categaries:
sales_high_count.append(salary_high[salary_high['sales']==i].shape[0])
plt.subplot(131)
plt.title('salary_low')
plt.pie(sales_low_count,
labels=sales_categaries,
colors=color,
startangle=90,
shadow=True,
explode=(0.1,0,0,0,0,0,0,0,0,0),
autopct='%1.1f%%'
)
plt.subplot(132)
plt.title('salary_medium')
plt.pie(sales_medium_count,
labels=sales_categaries,
colors=color,
startangle=90,
shadow=True,
explode=(0.1,0,0,0,0,0,0,0,0,0),
autopct='%1.1f%%'
)
plt.subplot(133)
plt.title('salary_high')
plt.pie(sales_high_count,
labels=sales_categaries,
colors=color,
startangle=90,
shadow=True,
explode=(0.1,0,0,0,0,0,0,0,0,0),
autopct='%1.1f%%'
)
plt.show()
上述代码我们就可以得到不同档次salary的饼状图;
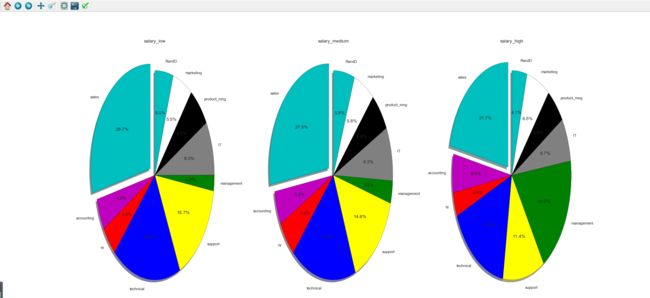
其实效果和上图是一样的,只不过是更加清晰地观察其所占百分比。
以上分析只是为了让我们更加清楚地观察到这些数据的用途。并没有进行具体的分析,接下来我们将运用数学模型进行预测。从而预测出未来哪些员工可能离职。
数学模型
在本次预测时,我主要采用了三个数学模型,分别是逻辑回归,SVM,随机森林三种模型。通过训练模型从而得到一种最好的模型进行预测。
在进行数学模型预测之前,我们首先应该对数据进行处理,首先就是将sales和salary中的文字部分转换成数值类型。转换方式可以采用pandas中的get_dummies()实现。
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn import svm
from sklearn.linear_model import LogisticRegression
data_copy = pd.get_dummies(data)
data_copy_information = data_copy.drop(['left'], axis=1).values
data_copy_left = data_copy['left'].values
X_train, X_test, y_train, y_test = train_test_split(data_copy_information, data_copy_left, test_size=0.5)
# LR测试
LR=LogisticRegression()
LR.fit(X_train,y_train)
print('LR\'s accuracy rate:',LR.score(X_test,y_test))
#随机森林测试
rmf=RandomForestClassifier()
rmf.fit(X_train,y_train)
print('rmf\'s accuracy rate:',rmf.score(X_test,y_test))
# SVM测试
svm_model=svm.SVC()
svm_model.fit(X_train,y_train)
print('svm\'s accuracy rate:',svm_model.score(X_test,y_test))
实验结果如下所示:
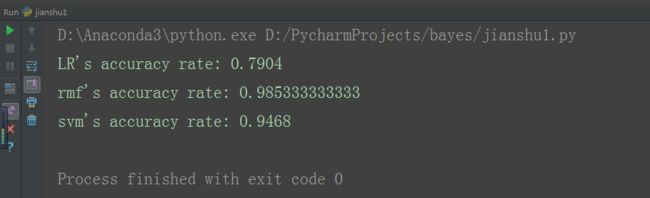
从图可知,随机森林的准确率最高。高达98%,其次是svm。其实LR的准确率较低是很容易理解的。svm就是一个万金油。。。。分类神器。我接下来将会学习随机森林的algorithm。现在对其为什么会如此之高的原理不做介绍。当然欢迎大家一起讨论。既然随机森林的准确率如此之高,那么在这里我就采用随机森林进行预测和分析。
首先将其特征的重要性进行排序:
# 将特征重要性从小到大排序
indices=np.argsort(rmf.feature_importances_)[::-1]
print(indices)
这里输出结果共有20个。

可能有人不理解为什么会有20个特征值,明明在原始数据集中只有9个特征(‘left’已经作为标签了,所以首先将其排除掉)20个特征值主要是由于我们进行get_dummies()操作,将sales中的各种属性数值化得到10个特征值,相应的salary的各种属性数值化得到3个特征值。接下来就是简单的加法运算:9-2+10+3=20。所以共有20个特征值。不懂的小伙伴可以查阅pandas中的get_dummies()函数。
既然已经得到特征值的排名。那么我们将以图的形式观察其具体分数。
for i in range(data_copy_information.shape[1]):
print('%d.feature %d %s(%f)'%(i+1,indices[i],data_copy.columns[indices[i]],rmf.feature_importances_[indices[i]]))
&semp;&semp;输出结果如下所示:
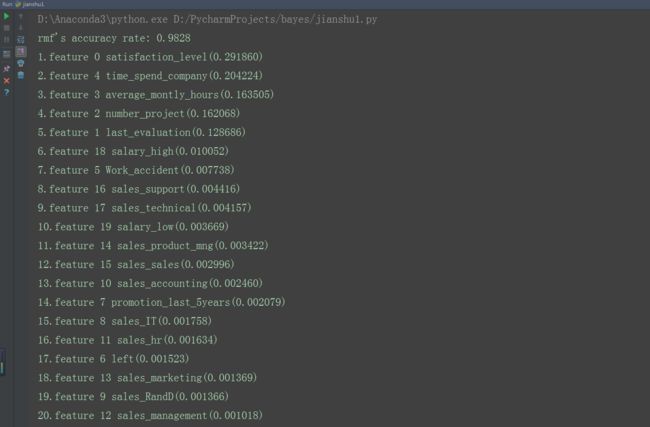
通过该图可知是否跳槽与对公司满意度,在公司工作时间长度,以及每月工作时间有很大的关系。联系实际生活也确实如此。(表示图表强迫症,所以我制作了图标显示)
data_feature_names=[]
data_feature_probability=[]
for i in range(data_copy_information.shape[1]):
# print('%d.feature %d %s(%f)'%(i+1,indices[i],data_copy.columns[indices[i]],rmf.feature_importances_[indices[i]]))
data_feature_names.append(data_copy.columns[indices[i]])
data_feature_probability.append(rmf.feature_importances_[indices[i]])
plt.figure(figsize=(20,20))
sns.set_style("whitegrid")
sns.barplot(data_feature_names,data_feature_probability)
plt.xlabel('feature')
plt.ylabel('probability')
plt.show()

接下来我们就可以很happy的进行员工预测了,原理很简单。就是将原始数据集中left=0的人全部扔进已经训练好的数学模型中。得到其在未来可能离开的概率。这样就可以实现预测。
now_stay = data[data['left'] == 0]
now_stay = pd.get_dummies(now_stay)
now_stay_information = now_stay.drop(['left'], axis=1).values
now_stay_label = now_stay['left'].values
predict = rmf.predict_proba(now_stay_information)
print(sum(predict[:, 1] == 1))
now_stay['maybe leave company']=predict[:,1]
print(now_stay[now_stay['maybe leave company']>=0.5].sort_values('maybe leave company',ascending=False))
outputfile='D:/kaggle/.output.csv'
now_stay[now_stay['maybe leave company']>=0.5].sort_values('maybe leave company',ascending=False).to_csv(outputfile)
最终输出结果如下所示:
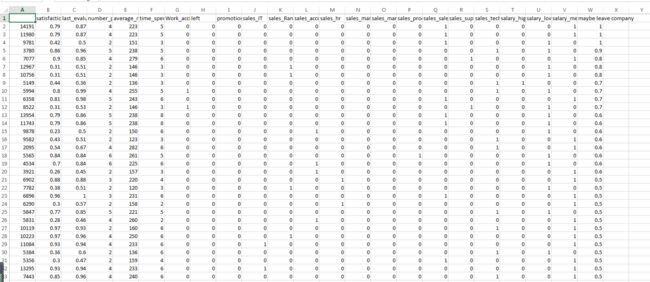
通过分析,我们可以发现可能有32个员工将会跳槽。。。其中员工编号为14191是重点关注对象。。。希望HR可以找他(她)谈谈心,聊一聊人生。。。。。。顺便提前谈一下解约事项。。。。没错,,就是这么先发制人。
以上便是整个分析预测流程。自己感觉很好玩,所以与大家分享一下。如果大家想要源代码以及数据集的话可以查看我的 Github。很愉快能和大家交流。