部署高可用kubernetes
kubernetes的基本概念
写在前面的话
整个安装过程中尽量不要出现写死的IP的情况出现,尽量全部使用域名代替IP。
环境是ubuntu18.04
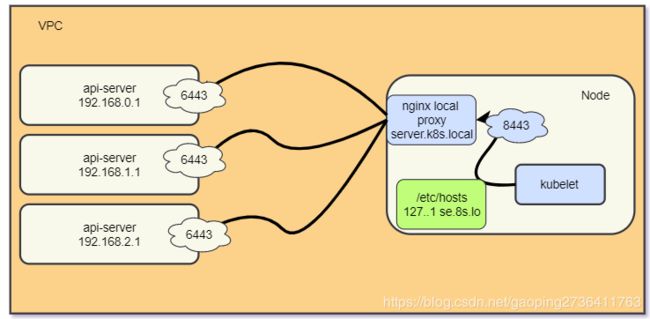
kubernetes 高可用架构图
ETCD高可用

API-Server 高可用
节点清单
制作一个base镜像
制作一个base镜像安装和修改通用组件,方便以后的节点部署。
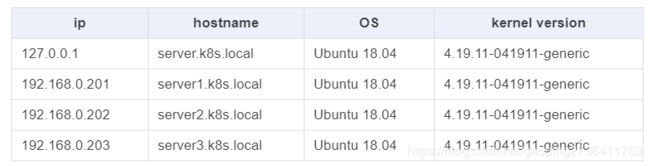
修改node的hosts文件
如果你使用自己的域名我建议将如下配置配到你的域名管理中。
注意:如你使用我这里的域名你需要将此信息写入到机器中的每一台node中(包括master和node)
cat >> /etc/hosts << EOF
127.0.0.1 server.k8s.local
192.168.0.1 server1.k8s.local
192.168.1.1 server2.k8s.local
192.168.2.1 server3.k8s.local
EOF
禁用
#https://linuxconfig.org/how-to-disable-ipv6-address-on-ubuntu-18-04-bionic-beaver-linux
# 编辑grub
➜ vim /etc/default/grub
FROM:
GRUB_CMDLINE_LINUX_DEFAULT=""
GRUB_CMDLINE_LINUX=""
TO:
GRUB_CMDLINE_LINUX_DEFAULT="ipv6.disable=1"
GRUB_CMDLINE_LINUX="ipv6.disable=1"
# 更新grub
➜ update-grub
时区问题
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
DNS问题
systemctl disable systemd-resolved
rm -rf /etc/resolv.conf
touch /etc/resolv.conf
echo 'nameserver 114.114.114.114' > /etc/resolv.conf
echo '100.100.2.148 mirrors.cloud.aliyuncs.com' >> /etc/hosts
为什么要升级内核
本文中所使用到的OS为Ubuntu 18.04,用户均为root用户。升级内核为必须条件。
在低版本的内核中会出现一下很让人恼火的BUG,时不时来一下,发作时候会导致整个OS Hang住无法执行任何命令。
现象如下:
kernel:unregister_netdevice: waiting for lo to become free. Usage count = 1
而根据我实际的实验(采坑)下来,这个问题我花费了差不多1个多月的时间先后尝试了内核版本3.10,4.4,4.9,4.12,4.14,4.15版本,均会不同程度的复现上述Bug,而一旦触发并无他法,只能重启(然后祈祷不要再次触发)。
实在是让人寝食难安,睡不踏实,直到我遇到了内核4.17,升级完毕之后,从6月到现在,没有复现过。似乎可以认为该BUG已经修复了,故而建议升级内核到4.17+。
机器环境
升级内核
你可以从Linux内核官网了解到最新发布的内核版本。
我们这里升级到当前最新的4.19.11版本的内核,以下为升级到该内核版本需要的文件。
linux-headers-4.19.11-041911_4.19.11-041911.201812191931_all.deb
linux-image-unsigned-4.19.11-041911-generic_4.19.11-041911.201812191931_amd64.deb
linux-modules-4.19.11-041911-generic_4.19.11-041911.201812191931_amd64.deb
以上三个内核相关文件下载到本地。如我这里存放在~目录下。执行以下命令完成内核的安装。
➜ dpkg -i ~/*.deb
正在选中未选择的软件包 linux-headers-4.19.11-041911。
(正在读取数据库 ... 系统当前共安装有 60576 个文件和目录。)
正准备解包 linux-headers-4.19.11-041911_4.19.11-041911.201812191931_all.deb ...
正在解包 linux-headers-4.19.11-041911 (4.19.11-041911.201812191931) ...
正在选中未选择的软件包 linux-image-unsigned-4.19.11-041911-generic。
正准备解包 linux-image-unsigned-4.19.11-041911-generic_4.19.11-041911.201812191931_amd64.deb ...
正在解包 linux-image-unsigned-4.19.11-041911-generic (4.19.11-041911.201812191931) ...
正在选中未选择的软件包 linux-modules-4.19.11-041911-generic。
正准备解包 linux-modules-4.19.11-041911-generic_4.19.11-041911.201812191931_amd64.deb ...
正在解包 linux-modules-4.19.11-041911-generic (4.19.11-041911.201812191931) ...
正在设置 linux-headers-4.19.11-041911 (4.19.11-041911.201812191931) ...
正在设置 linux-modules-4.19.11-041911-generic (4.19.11-041911.201812191931) ...
正在设置 linux-image-unsigned-4.19.11-041911-generic (4.19.11-041911.201812191931) ...
I: /vmlinuz.old is now a symlink to boot/vmlinuz-4.4.0-131-generic
I: /initrd.img.old is now a symlink to boot/initrd.img-4.4.0-131-generic
I: /vmlinuz is now a symlink to boot/vmlinuz-4.19.11-041911-generic
I: /initrd.img is now a symlink to boot/initrd.img-4.19.11-041911-generic
正在处理用于 linux-image-unsigned-4.19.11-041911-generic (4.19.11-041911.201812191931) 的触发器 ...
/etc/kernel/postinst.d/initramfs-tools:
update-initramfs: Generating /boot/initrd.img-4.19.11-041911-generic
W: mdadm: /etc/mdadm/mdadm.conf defines no arrays.
/etc/kernel/postinst.d/x-grub-legacy-ec2:
Searching for GRUB installation directory ... found: /boot/grub
Searching for default file ... found: /boot/grub/default
Testing for an existing GRUB menu.lst file ... found: /boot/grub/menu.lst
Searching for splash image ... none found, skipping ...
Found kernel: /boot/vmlinuz-4.4.0-131-generic
Found kernel: /boot/vmlinuz-4.19.11-041911-generic
Found kernel: /boot/vmlinuz-4.4.0-131-generic
Replacing config file /run/grub/menu.lst with new version
Updating /boot/grub/menu.lst ... done
/etc/kernel/postinst.d/zz-update-grub:
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-4.19.11-041911-generic
Found initrd image: /boot/initrd.img-4.19.11-041911-generic
Found linux image: /boot/vmlinuz-4.4.0-131-generic
Found initrd image: /boot/initrd.img-4.4.0-131-generic
done
完成安装后,reboot重启服务器。查看我们的最新内核版本。
uname -a
Linux k8s 4.19.11-041911-generic #201812191931 SMP Wed Dec 19 19:33:33 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
清理老的内核(可选)。
# 查看老的内核
➜ dpkg --list | grep linux
# 清理 老旧的4.4.0内核的相关
➜ apt purge linux*4.4.0* -y
启用IPVS相关内核module
echo > /etc/modules-load.d/ipvs.conf
➜ module=(ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
ip_vs_lc
br_netfilter
nf_conntrack)
for kernel_module in ${module[@]};do
/sbin/modinfo -F filename $kernel_module |& grep -qv ERROR && echo $kernel_module >> /etc/modules-load.d/ipvs.conf || :
done
# 如下输出表示加载成功
➜ lsmod | grep ip_vs
ip_vs_sh 16384 0
ip_vs_wrr 16384 0
ip_vs_rr 16384 0
ip_vs 147456 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr
nf_conntrack 143360 6 xt_conntrack,nf_nat,ipt_MASQUERADE,nf_nat_ipv4,nf_conntrack_netlink,ip_vs
libcrc32c 16384 5 nf_conntrack,nf_nat,btrfs,raid456,ip_vs
内核参数调整
cat > /etc/sysctl.conf << EOF
# https://github.com/moby/moby/issues/31208
# ipvsadm -l --timout
# 修复ipvs模式下长连接timeout问题 小于900即可
net.ipv4.tcp_keepalive_time = 800
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_probes = 10
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
net.ipv4.neigh.default.gc_stale_time = 120
net.ipv4.conf.all.rp_filter = 0
net.ipv4.conf.default.rp_filter = 0
net.ipv4.conf.default.arp_announce = 2
net.ipv4.conf.lo.arp_announce = 2
net.ipv4.conf.all.arp_announce = 2
net.ipv4.ip_forward = 1
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 1024
net.ipv4.tcp_synack_retries = 2
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
fs.inotify.max_user_watches=89100
fs.file-max=52706963
fs.nr_open=52706963
net.bridge.bridge-nf-call-arptables = 1
vm.swappiness = 0
vm.max_map_count=262144
net.core.somaxconn = 2048
EOF
禁用swap并关闭防火墙
swapoff -a
sysctl -w vm.swappiness=0
sed -ri '/^[^#]*swap/s@^@#@' /etc/fstab
systemctl disable --now ufw
安装必须软件
配置镜像
配置ubuntu18.04
➜ cat > /etc/apt/sources.list << EOF
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
EOF
更新apt镜像源并升级相关软件
apt update && apt upgrade
apt -y install ipvsadm ipset apt-transport-https
apt -y install ca-certificates curl software-properties-common apt-transport-https
安装docker-ce
# step 1: 安装GPG证书
curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
# Step 2: 写入软件源信息
add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
# Step 3: 更新并安装 Docker-CE
apt-get -y update
apt-get -y install docker-ce
配置docker加速
这里推荐使用cgroupdriver 使用cgroupfs 不推荐使用systemd
touch /etc/docker/daemon.json
cat > /etc/docker/daemon.json <<EOF
{
"log-driver": "json-file",
"exec-opts": ["native.cgroupdriver=cgroupfs"],
"log-opts": {
"max-size": "100m",
"max-file": "3"
},
"live-restore": true,
"max-concurrent-downloads": 10,
"max-concurrent-uploads": 10,
"registry-mirrors": ["https://hccwwfjl.mirror.aliyuncs.com"],
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
]
}
EOF
systemctl daemon-reload
systemctl restart docker
部署Nginx local Proxy
nginx.conf
本地nginx代理的主要主要是代理访问所有的master节点。nginx.conf 配置如下:
mkdir -p /etc/nginx
cat > /etc/nginx/nginx.conf << EOF
worker_processes auto;
user root;
events {
worker_connections 20240;
use epoll;
}
error_log /var/log/nginx_error.log info;
stream {
upstream kube-servers {
hash $remote_addr consistent;
server server1.k8s.local:6443 weight=5 max_fails=1 fail_timeout=3s;
server server2.k8s.local:6443 weight=5 max_fails=1 fail_timeout=3s;
server server3.k8s.local:6443 weight=5 max_fails=1 fail_timeout=3s;
}
server {
listen 8443 reuseport;
proxy_connect_timeout 3s;
# 加大timeout
proxy_timeout 3000s;
proxy_pass kube-servers;
}
}
EOF
启动nginx
docker run --restart=always \
-v /etc/apt/sources.list:/etc/apt/sources.list \
-v /etc/nginx/nginx.conf:/etc/nginx/nginx.conf \
--name kps \
--net host \
-it \
-d \
nginx
注意:请确保每一台kubernetes机器中的机器都运行着此代理
部署ETCD集群
关于ETCD要不要使用TLS?
首先TLS的目的是为了鉴权为了防止别人任意的连接上你的etcd集群。其实意思就是说如果你要放到公网上的ETCD集群,并开放端口,我建议你一定要用TLS。
如果你的ETCD集群跑在一个内网环境比如(VPC环境),而且你也不会开放ETCD端口,你的ETCD跑在防火墙之后,一个安全的局域网中,那么你用不用TLS,都行。
注意事项
–auto-compaction-retention
由于ETCD数据存储多版本数据,随着写入的主键增加历史版本需要定时清理,默认的历史数据是不会清理的,数据达到2G就不能写入,必须要清理压缩历史数据才能继续写入;所以根据业务需求,在上生产环境之前就提前确定,历史数据多长时间压缩一次;推荐一小时压缩一次数据这样可以极大的保证集群稳定,减少内存和磁盘占用
–max-request-bytes
etcd Raft消息最大字节数,ETCD默认该值为1.5M; 但是很多业务场景发现同步数据的时候1.5M完全没法满足要求,所以提前确定初始值很重要;由于1.5M导致我们线上的业务无法写入元数据的问题,我们紧急升级之后把该值修改为默认32M,但是官方推荐的是10M,大家可以根据业务情况自己调整
–quota-backend-bytes
ETCD db数据大小,默认是2G,当数据达到2G的时候就不允许写入,必须对历史数据进行压缩才能继续写入;参加1里面说的,我们启动的时候就应该提前确定大小,官方推荐是8G,这里我们也使用8G的配置
–auto-compaction-retention=1 –max-request-bytes=’33554432’ –quota-backend-bytes=’8589934592’ \
docker安装ETCD
请依次在你规划好的etcd机器上运行即可。
etcd1
mkdir -p /var/etcd
docker rm etcd1 -f
rm -rf /var/etcd/*
docker run --restart=always --net host -it --name etcd1 -d \
-v /var/etcd:/var/etcd \
-v /etc/localtime:/etc/localtime \
quay.io/coreos/etcd:v3.3.13 \
etcd --name etcd-s1 \
--auto-compaction-retention "1h" --max-request-bytes "33554432" --quota-backend-bytes "8589934592" \
--data-dir=/var/etcd/etcd-data \
--listen-client-urls http://0.0.0.0:2379 \
--listen-peer-urls http://0.0.0.0:2380 \
--initial-advertise-peer-urls http://server1.k8s.local:2380 \
--advertise-client-urls http://server1.k8s.local:2379,http://server1.k8s.local:2380 \
-initial-cluster-token etcd-cluster \
-initial-cluster "etcd-s1=http://server1.k8s.local:2380,etcd-s2=http://server2.k8s.local:2380,etcd-s3=http://server3.k8s.local:2380" \
-initial-cluster-state new
etcd2
mkdir -p /var/etcd
docker rm etcd2 -f
rm -rf /var/etcd/*
docker run --restart=always --net host -it --name etcd2 -d \
-v /var/etcd:/var/etcd \
-v /etc/localtime:/etc/localtime \
quay.io/coreos/etcd:v3.3.13 \
etcd --name etcd-s2 \
--auto-compaction-retention "1h" --max-request-bytes "33554432" --quota-backend-bytes "8589934592" \
--data-dir=/var/etcd/etcd-data \
--listen-client-urls http://0.0.0.0:2379 \
--listen-peer-urls http://0.0.0.0:2380 \
--initial-advertise-peer-urls http://server2.k8s.local:2380 \
--advertise-client-urls http://server2.k8s.local:2379,http://server2.k8s.local:2380 \
-initial-cluster-token etcd-cluster \
-initial-cluster "etcd-s1=http://server1.k8s.local:2380,etcd-s2=http://server2.k8s.local:2380,etcd-s3=http://server3.k8s.local:2380" \
-initial-cluster-state new
etcd3
mkdir -p /var/etcd
docker rm etcd3 -f
rm -rf /var/etcd/*
docker run --restart=always --net host -it --name etcd3 -d \
-v /var/etcd:/var/etcd \
-v /etc/localtime:/etc/localtime \
quay.io/coreos/etcd:v3.3.13 \
etcd --name etcd-s3 \
--auto-compaction-retention "1h" --max-request-bytes "33554432" --quota-backend-bytes "8589934592" \
--data-dir=/var/etcd/etcd-data \
--listen-client-urls http://0.0.0.0:2379 \
--listen-peer-urls http://0.0.0.0:2380 \
--initial-advertise-peer-urls http://server3.k8s.local:2380 \
--advertise-client-urls http://server3.k8s.local:2379,http://server3.k8s.local:2380 \
-initial-cluster-token etcd-cluster \
-initial-cluster "etcd-s1=http://server1.k8s.local:2380,etcd-s2=http://server2.k8s.local:2380,etcd-s3=http://server3.k8s.local:2380" \
-initial-cluster-state new
# 如何修复故障的ETCD节点
https://www.centos.bz/2018/06/etcd%E9%9B%86%E7%BE%A4%E6%95%85%E9%9A%9C%E5%A4%84%E7%90%86/
ETCDCTL_API=3 etcdctl –endpoints=http://server1.k8s.local:2379,http://server2.k8s.local:2379,http://server3.k8s.local:2379 endpoint health
ETCDCTL_API=3 etcdctl –endpoints=http://server1.k8s.local:2379,http://server2.k8s.local:2379,http://server3.k8s.local:2379 member list
ETCDCTL_API=3 etcdctl –endpoints=http://server1.k8s.local:2379,http://server2.k8s.local:2379,http://server3.k8s.local:2379 endpoint status –write-out=table
首先从集群删除节点
etcdctl –endpoints=http://server1.k8s.local:2379,http://192.168.0.202:2379,http://192.168.0.203:2379 member remove nodeid
添加节点
etcdctl –endpoints=http://server1.k8s.local:2379,http://192.168.0.202:2379 member add etcd-s3 –peer-urls=”http://server3.k8s.local:2380"
将new修改为existing
-initial-cluster-state existing
检查
➜ ETCDCTL_API=3 etcdctl member list
410feb26f4fa3c7f: name=etcd-s1 peerURLs=http://server1.k8s.local:2380 clientURLs=http://server1.k8s.local:2379,http://server1.k8s.local:2380
56fa117fc503543c: name=etcd-s3 peerURLs=http://server3.k8s.local:2380 clientURLs=http://server3.k8s.local:2379,http://server3.k8s.local:2380
bc4d900274366497: name=etcd-s2 peerURLs=http://server2.k8s.local:2380 clientURLs=http://server2.k8s.local:2379,http://server2.k8s.local:2380
➜ ETCDCTL_API=3 etcdctl cluster-health
http://server1.k8s.local:2379 is healthy: successfully committed proposal: took = 3.755356ms
http://server3.k8s.local:2379 is healthy: successfully committed proposal: took = 3.415338ms
http://server2.k8s.local:2379 is healthy: successfully committed proposal: took = 5.179934ms
部署Master
安装kubernetes基础组件
关于kubeadm自动签发的证书一年过期的问题
请参考修改kubeam生成证书有效期为100年
设置镜像源
同样使用国内的阿里云提供的kubernetes镜像源,加速基础组件的安装。
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
cat > /etc/apt/sources.list.d/kubernetes.list << EOF
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
安装kubeadm kubelet kubectl
如果你是自己手动编译的kubeadm的话记得替换下。
apt-get update
apt-get install kubeadm kubelet kubectl
设置kubelet的pause镜像
在Ubuntu中的kublet配置文件在/etc/systemd/system/kubelet.service.d/10-kubeadm.conf
关于为什么不使用kubeadm推荐的system做为cgroup-driver 这里有详细的讨论,我在使用systemd作为驱动时,遇到了同样的问题,以及kubelet极高的CPU使用。
cat > /etc/default/kubelet << EOF
KUBELET_EXTRA_ARGS="--cgroup-driver=cgroupfs --serialize-image-pulls=false --image-pull-progress-deadline=30m --max-pods=300 --allow-privileged=true --pod-infra-container-image=freemanliu/pause:3.1"
EOF
systemctl daemon-reload
systemctl enable kubelet && systemctl restart kubelet
Kubeadm-config.yaml
自1.13.0之后的kubeadm的文件格式发生了比较大的变化
你可以使用一下命令查看到默认的yaml格式
查看 ClusterConfiguration 的默认配置
# kubeadm config print-default --api-objects ClusterConfiguration
查看 KubeProxyConfiguration 的默认配置
# kubeadm config print-default --api-objects KubeProxyConfiguration
查看 KubeletConfiguration 的默认配置
# kubeadm config print-default --api-objects KubeletConfiguration
# https://godoc.org/k8s.io/kubernetes/cmd/kubeadm/app/apis/kubeadm/v1beta1
kubeadm-config.yaml
# enable-admission-plugins: "NamespaceLifecycle,LimitRanger,ServiceAccount,PersistentVolumeClaimResize,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota,Priority"
# kubeadm init --config=kubeadm-config.yaml --experimental-upload-certs
apiVersion: kubeadm.k8s.io/v1beta1
kind: ClusterConfiguration
kubernetesVersion: v1.14.4
#useHyperKubeImage: true
#imageRepository: gcr.azk8s.cn/google_containers
imageRepository: gcr.azk8s.cn/google_containers
apiServer:
extraArgs:
storage-backend: etcd3
extraVolumes:
- hostPath: /etc/localtime
mountPath: /etc/localtime
name: localtime
certSANs:
- "prod-server.k8s.local"
- "server1.k8s.local"
- "server2.k8s.local"
- "server3.k8s.local"
- "server4.k8s.local"
- "server5.k8s.local"
- "127.0.0.1"
- "192.168.0.1"
- "192.168.1.1"
- "192.168.2.1"
- "192.168.3.1"
- "192.168.4.1"
- "kubernetes"
- "kubernetes.default"
- "kubernetes.default.svc"
- "kubernetes.default.svc.cluster"
- "kubernetes.default.svc.cluster.local"
controllerManager:
extraArgs:
experimental-cluster-signing-duration: 867000h
extraVolumes:
- hostPath: /etc/localtime
mountPath: /etc/localtime
name: localtime
scheduler:
extraVolumes:
- hostPath: /etc/localtime
mountPath: /etc/localtime
name: localtime
networking:
# pod 网段
podSubnet: 172.224.0.0/12
# SVC 网络
serviceSubnet: 10.96.0.0/12
controlPlaneEndpoint: server.k8s.local:8443
etcd:
external:
endpoints:
- http://server1.k8s.local:2379
- http://server2.k8s.local:2379
- http://server3.k8s.local:2379
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
ipvs:
scheduler: lc
minSyncPeriod: 5s
syncPeriod: 15s
预拉取镜像
➜ kubeadm config images pull --config kubeadm-config.yaml
[config/images] Pulled gcr.azk8s.cn/google_containers/kube-apiserver:v1.14.4
[config/images] Pulled gcr.azk8s.cn/google_containers/kube-controller-manager:v1.14.4
[config/images] Pulled gcr.azk8s.cn/google_containers/kube-scheduler:v1.14.4
[config/images] Pulled gcr.azk8s.cn/google_containers/kube-proxy:v1.14.4
[config/images] Pulled gcr.azk8s.cn/google_containers/pause:3.1
[config/images] Pulled gcr.azk8s.cn/google_containers/coredns:1.2.6
初始化Master
预拉取镜像之后我们这步骤会十分的快很顺利。
# 初始化Master
# --experimental-upload-certs 参数的意思为将相关的证书直接上传到etcd中保存,这样省去我们手动分发证书的过程
# 注意在v1.15+版本中,已经变成正式参数,不再是实验性质 请使用 --upload-certs
➜ kubeadm init --config=kubeadm-config.yaml --experimental-upload-certs
启动完成之后你可以在/etc/kubernetes/pki/找到kubeadm生成的证书,使用一下命令可以查看到证书的信息以及过期时间。
可以清楚的看到过期时间99年了。
➜ openssl x509 -in /etc/kubernetes/pki/ca.crt -noout -text
Certificate:
............
Validity
Not Before: Dec 25 15:55:21 2018 GMT
Not After : Dec 1 15:55:21 2117 GMT
Subject: CN=kubernetes
Subject Public Key Info:
............
cd /etc/kubernetes/pki
openssl x509 -in ca.crt -noout -dates
openssl x509 -in apiserver-kubelet-client.crt -noout -dates
openssl x509 -in apiserver.crt -noout -dates
openssl x509 -in front-proxy-ca.crt -noout -dates
openssl x509 -in front-proxy-client.crt -noout -dates
openssl x509 -noout -dates -in apiserver-kubelet-client.crt
部署高可用Master
本章节的内容主要来自官方文档
- 加入Master节点
在1.13中kubeadm提供了一个新的试验性标志--experimental-control-plane
我们只需要在kubeadm join token --experimental-control-plane即可完成Master的添加。
注意:在v1.15+ 请使用--control-plane
分别在Master2,3执行如下命令,成功如下正确输出
➜ kubeadm join server.k8s.local:8443 --token qiqcg7.8kg2v7txawdf6ojh --discovery-token-ca-cert-hash sha256:039b3de841b63309983911c890c967fa167c5be5a713fe0f9b6f5f4eda74b70a --experimental-control-plane
kubeadm都干了什么
简单说下kubeadm都干了什么
1.生成各个组件所需要的证书。存放路径在/etc/kubernetes/pki
# ls /etc/kubernetes/pki
apiserver.crt apiserver-kubelet-client.crt ca.crt front-proxy-ca.crt front-proxy-client.crt sa.key
apiserver.key apiserver-kubelet-client.key ca.key front-proxy-ca.key front-proxy-client.key sa.pub
2 生成组件kube-apiserver,kube-controller-manager,kube-scheduler static pod yaml描述文件。
# ls /etc/kubernetes/manifests
kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml
3.生成组件kube-apiserver,kube-controller-manager,kube-scheduler,kubelet,kubectl的配置文件。
# ls /etc/kubernetes | grep conf
admin.conf
bootstrap-kubelet.conf
controller-manager.conf
kubelet.conf
scheduler.conf
4.kubelet 会自动检测(20s间隔)static pod的路径(/etc/kubernetes/manifests)是否存在yaml格式的pod描述文件,由于上面的步骤已经生成好了yaml文件,这时候kubelet会按照描述yaml启动pause容器,进而启动起来整个kubernetes的组件容器。
5.生成默认插件生成configmap配置文件。
#查看生成的configmap
# kubectl get configmap -nkube-system
NAME DATA AGE
coredns 1 3d22h
extension-apiserver-authentication 6 3d23h
kube-flannel-cfg 2 3d22h
kube-proxy 2 3d23h
kubeadm-config 2 3d23h
kubelet-config-1.14 1 3d23h
6.当全部容器启动成功,并通过kubeadm的检查,kubeadm将会自动的部署kube-proxy插件,coredns插件。并给出添加master和workload的cmd。
#查看kube-proxy的yaml描述文件
# kubectl get ds -nkube-system kube-proxy -oyaml
# 查看kube-proxy插件的配置信息
# kubectl get configmap -nkube-system -oyaml kube-proxy
# coredns 查看和以上一直。
查看集群状态
设置kubeconfig
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
查看node,你可以发现我们的master节点已经启动好了3台了,status是NotReady,这不用管,这是因为我们还没安装网络插件导致的。我们在下一章专门讲解。
➜ kubectl get node
NAME STATUS ROLES AGE VERSION
server1.k8s.local NotReady master 17m v1.14.2
server2.k8s.local NotReady master 3m10s v1.14.2
server3.k8s.local NotReady master 2m56s v1.14.2
查看static Pods coredns 状态是ContainerCreating,原因依然是网络插件的问题。我们在下一章专门讲解。
➜ kubectl get pods -nkube-system
NAME READY STATUS RESTARTS AGE
coredns-89cc84847-2s5xq 0/1 ContainerCreating 0 16m
coredns-89cc84847-4cbqf 0/1 ContainerCreating 0 16m
kube-apiserver-server1.k8s.local 1/1 Running 0 16m
kube-apiserver-server2.k8s.local 1/1 Running 0 2m29s
kube-apiserver-server3.k8s.local 1/1 Running 0 2m14s
kube-controller-manager-server1.k8s.local 1/1 Running 0 16m
kube-controller-manager-server2.k8s.local 1/1 Running 0 2m29s
kube-controller-manager-server3.k8s.local 1/1 Running 0 2m14s
kube-proxy-5mgrq 1/1 Running 0 16m
kube-proxy-b6wpc 1/1 Running 0 2m29s
kube-proxy-j7gnq 1/1 Running 0 2m15s
kube-scheduler-server1.k8s.local 1/1 Running 0 16m
kube-scheduler-server2.k8s.local 1/1 Running 0 2m29s
kube-scheduler-server3.k8s.local 1/1 Running 0 2m14s
清理
rm -rf $HOME/.kube
kubeadm reset && rm -rf ~/.kube && ipvsadm --clear
kubectl drain <node name> --delete-local-data --force --ignore-daemonsets
kubectl delete node <node name>
添加新的节点集群中
默认生成的token有效期只有24小时,当超过24小时之后tokne会失效,我们可以使用一下方式来添加新的node节点。
# 创建一个新的token
kubeadm token create
# 查看token列表
kubeadm token list
# 获取ca证书sha256编码hash值
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
# 最终生成的cmd
kubeadm join server.k8s.local:8443 --token ${TOKEN} --discovery-token-ca-cert-hash sha256:${CaSHA256}