Python与爬虫入门实践——简易搜狐新闻爬虫02
Python与爬虫入门实践——简易搜狐新闻爬虫02
爬虫的基础内容参考:
Python与爬虫入门实践——简易搜狐新闻爬虫01:https://blog.csdn.net/gcn_Raymond/article/details/86741843
首先新项目中建立如下的内容,db是数据库相关操作,spider是爬虫内容,view是一个操作主界面的程序
spider.py
from urllib.request import Request
from urllib import request
from bs4 import BeautifulSoup
from bs4.element import NavigableString
# 爬取新闻列表
def spider_new_list():
# 伪装请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/17.17134"
}
url = 'http://news.sohu.com/?spm=smpc.content.nav.2.1547783966163584maPh'
req = Request(url, headers=headers)
response = request.urlopen(req)
soup = BeautifulSoup(response.read(), 'html.parser')
# div = soup.find_all('div', attrs={"class":"focus-news"})
# news_as = div[0].find_all('a')
news_as = soup.find_all('a')
news_url_list = []
for news_a in news_as:
# print(news_a.string)
# print("抓取新闻内容:" + news_a.attrs.get('title'))
news_t = news_a.attrs.get('title')
if news_t:
# print("抓取新闻内容:" + news_t)
href = news_a.attrs.get('href')
if href == 'javascript:void(0)':
# print('这是一个视频')
continue
# 字典 key - value 变量名['href'], 变量名.get('href')
if href.startswith('//'):
href = 'http:' + href
news_url_list.append(href)
return news_url_list
def spider_one_news(url):
# 伪装请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/17.17134"
}
# url = 'http://httpbin.org/get'
# url = 'http://www.sohu.com/a/289791626_428290?g=0?code=499a2b65ff7c5bfe01010550a1994c73&spm=smpc.home.top-news1.1.15477740598813ZibCcj&_f=index_cpc_0'
# url = 'http://www.sohu.com/a/289854995_267106?code=1b67e25ec7dedcf5e1bbabdcb07c80c0&_f=index_chan08cpc_0'
req = Request(url, headers=headers)
response = request.urlopen(req)
# print(response.read().decode('utf-8'))
soup = BeautifulSoup(response.read(), 'html.parser')
# print(soup)
# 选择元素的方法
# 元素选择器 soup.HTML标签的名字
# print(soup.h1)
# 信息的获取
# print(soup.h1.name) # 标签的名字
# print(soup.title.string) # 标签内的字符串
# 找页面中的h1标签
h1 = soup.h1
if not h1:
# print('这不是一条有效的新闻')
return
# 获取h1标签下的所有子元素, 过滤掉没用的
news_title = h1.contents[0]
if not isinstance(news_title, NavigableString):
return
# 去掉标题中的空格
# print(news_title)
news_title = news_title.replace(' ', '')
# 去掉换行
news_title = news_title.replace('\n', '')
# 得到最终的标题
# print(news_title)
# 标签选择器
article = soup.article
if not article:
# print('这不是一条有效的新闻')
return
# 获取子节点
ps = article.contents
# 遍历子节点, 筛选文字信息
news_content = ""
for p in ps:
if p.string:
news_content += p.string
news_content = news_content.replace('\n\n', '\n')
# print(news_content)
# for tag in soup.find_all('div', class_='title-info-title'):
# newstitle = tag.find('span', class_='title-info-title').get_text()
return news_title, news_content
db.py
# 使用sqlite数据库保存爬取数据
# news
# 0. id
# 1. url
# 2. 标题 title
# 3. 内容 content
import sqlite3
db_file = 'new.db'
def create_table():
conn = sqlite3.connect(db_file)
cor = conn.cursor()
cor.execute('''
create table news(
id INTEGER PRIMARY KEY AUTOINCREMENT,
url TEXT,
title TEXT,
content TEXT
)
''')
conn.commit()
conn.close()
# 保存爬取数据
def save(url, title, content):
conn = sqlite3.connect(db_file)
cor = conn.cursor()
sql = "insert into news (url, title, content) " \
"values (?,?,?)"
cor.execute(sql,(url,title,content))
conn.commit()
conn.close()
#查询是否已存在
def query_url(url):
conn = sqlite3.connect(db_file)
cor = conn.cursor()
result=cor.execute('''
select * from news
where url = ?
''',(url,))
exist=False
for row in result:
exist=True
break
conn.commit()
conn.close()
if exist:
return True
else:
return False
#根据标题查询数据
def query_by_title(title):
conn = sqlite3.connect(db_file)
cor = conn.cursor()
result = cor.execute('''
select * from news
where title like ?
''',("%"+title+"%",))#通配符%
ls=[]
for row in result:
ls.append(row)
conn.commit()#查询也可以不提交,有关修改数据库内容的操作需要提交
conn.close()
return ls
#根据内容查询
def query_by_content(content):
conn = sqlite3.connect(db_file)
cor = conn.cursor()
result = cor.execute('''
select * from news
where content like ?
''',("%"+content+"%",))#通配符%
ls=[]
for row in result:
ls.append(row)
conn.commit()#查询也可以不提交,有关修改数据库内容的操作需要提交
conn.close()
return ls
#根据关键字
def query_by_key(key):
conn = sqlite3.connect(db_file)
cor = conn.cursor()
result = cor.execute('''
select * from news
where title like ? or content like ?
''',("%"+key+"%",)*2)#通配符%
ls=[]
for row in result:
ls.append(row)
conn.commit()#查询也可以不提交,有关修改数据库内容的操作需要提交
conn.close()
return lsmain.py
from spider import spider
from db import db
import os
def spider_news():
# 爬取所有的新闻列表
news_list = spider.spider_new_list()
# 遍历新闻列表
for url in news_list:
#检测是否已经被爬过
if db.query_url(url):
print("这个url已经爬取过:"+url)
continue
news = spider.spider_one_news(url)
if news:
# 把抓取到的新闻保存到数据库中
db.save(url, news[0], news[1])
print("保存一条新闻: " + news[0])
def query_by_title():
title=input('请输入要查询的标题')
result=db.query_by_title(title)
for row in result:
print(row)
def query_by_content():
content = input('请输入要查询的内容')
result = db.query_by_content(content)
for row in result:
print(row)
def query_by_key():
key = input('请输入要查询的关键字')
result = db.query_by_title(key)
for row in result:
print(row)
def search_news():
#按标题查询 title筛选
while True:
print('''
1.按标题查询
2.按内容查询
3.按关键字查询
4.返回上一层
''')
cmd=input("请输入功能编号:")
if cmd=='1':
query_by_title()
elif cmd=='2':
query_by_content()
elif cmd=='3':
query_by_key()
elif cmd=='4':
break
else:
print("输入有误")
#按内容查询
#按关键字查询
# 程序入口
if __name__ == '__main__':
# 启动程序时, 先检查数据库是否存在, 如果不存在, 执行创建数据库的操作
if not os.path.exists(db.db_file):
db.create_table()
# 1. 开启爬虫
# 2. 查询
while True:
print("*****搜狐新闻爬虫*****")
print("1. 提取新闻数据")
print("2. 搜索新闻")
print("3. 退出")
cmd = input("请输入功能选择编号: ")
# 根据用户输入的命令, 执行相应的操作
if cmd == '1':
spider_news()
elif cmd == '2':
search_news()
elif cmd == '3':
break
else :
print("输入有误, 请重新选择")
运行界面:


![]()
这样的情况是因为标题左边有一个原创的标记,爬取得时候会被卡住,暂时没有设置这样的判断,但也会保存内容在数据库中

重复的新闻不会再爬取
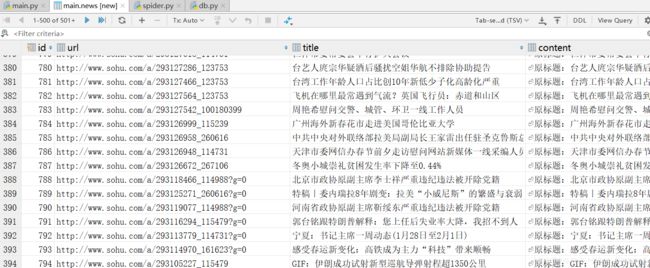
可以看到爬取的内容放在了数据库中,可以进行查询

查询结果

这样一个简易的搜狐新闻页新闻爬虫就完成了!