FPN(特征金字塔网络)解读
注:md文件,Typora书写,md兼容程度github=CSDN>知乎,若有不兼容处麻烦移步其他平台,github文档供下载。
上传在github:https://github.com/FermHan/Learning-Notes
发表在CSDN:https://blog.csdn.net/hancoder/article/
发表在知乎专栏:https://zhuanlan.zhihu.com/c_1088438808227254272
预备知识:
Faster R-CNN,RPN可见本人博客https://blog.csdn.net/hancoder/article/details/87917174
Feature Pyramid Networks for Object Detection (简称FPN)
作者Tusing-Yi Lin,Ross Girshich,Kaiming He
文章目录
- Feature Pyramid Networks for Object Detection (简称FPN)
- 1、常见卷积与FPN模型
- FPN的框架
- 2、框架三部分Details
- Bottom-up pathway
- Top-down pathway and lateral connections
- 3、应用
- FPN for RPN
- FPN for Fast R-CNN
- FPN for Mask R-CNN
- 4、实验
- 表1 FPN对RPN的影响:关心的是召回率AR[外链图片转存失败(img-AgIyp8Xi-1567168956144)(https://raw.githubusercontent.com/FermHan/tuchuang/master/20190407150341.png)]
- 表2 FPN对Fast R-CNN的影响:关心的是准确率AP
- 表3FPN对整个Faster R-CNN的影响
- 表4 对比其他单模型
- 表5 共享特征
- 表6 在实例分割上的表现
- 5、CVPR现场:
- 后续
- 6、代码实现
- 参考:
1、常见卷积与FPN模型
首先看几种卷积分类方式
(a) Featurized image pyramid 计算与内存开销太大
[外链图片转存失败(img-uE2eulyW-1567168956127)(https://raw.githubusercontent.com/FermHan/tuchuang/master/20190404152455.png)]
刚开始你可能会不熟悉这4个命名方式,你只需记住第一个里是图像image金字塔,而FPN是特征feature金字塔。因为需要缩放原图然后进行卷积,这种卷积方式肯定是耗内存的,最不科学的。
(b) Single feature map 框不出小物体
[外链图片转存失败(img-jh82O2UQ-1567168956127)(https://raw.githubusercontent.com/FermHan/tuchuang/master/20190404152529.png)]
b所讲的就是简单的分类网络,如AlexNet等。使用Single feature map的包括R-CNN、SPPNet、Fast R-CNN、Faster R-CNN、YOLOv1以及R-FCN系列。
© Pyramidal feature hierarchy 底层大scale的feature map语义信息少,虽然框出了小物体,但小物体容易被错分:
[外链图片转存失败(img-1XtGoEJE-1567168956128)(https://raw.githubusercontent.com/FermHan/tuchuang/master/20190404152600.png)]
使用Pyramidal feature hierarchy的包括SSD。SSD没有上采样过程,因为是在原有特征图上预测的,所以也不会增加额外的计算开销,但作者认为SSD没有用到足够底层的特征,而越底层的特征对检测小物体越有利。SSD用的最底层的特征是conv4_3。SSD也可以去我的CSDN等地观看。
Note:
- YOLOv2是个特例,其在 26×26 层设置了通道层接至 13×13 层。本质上即为single-scale上处理two-scale的feature map信息。
总结:上面abc这三种卷积方式都不是特征理想,那么怎么才能兼顾准确率(检测小物体)和速度(开销)呢?
FPN的框架
(d) Feature Pyramid Network
[外链图片转存失败(img-rFtytJx5-1567168956128)(https://raw.githubusercontent.com/FermHan/tuchuang/master/20190404152622.png)]
参照d图及下图。特征金字塔网络相当于先进行传统的bottom-up自上而下的特征卷积(d图左侧),然后FPN试图融合左侧特征图的相邻的特征图。左侧模型叫bottom-up,右侧模型叫top-down,横向的箭头叫横向连接lateral connections。这么做的目的是因为高层的特征语义多,低层的特征语义少但位置信息多。
左侧模型特征图大小相差1倍,但像AlexNet一样,其实是每在同样大小的feature上卷积几次才进行一次池化操作,我们把在同样大小feature上的卷积称之为一个stage。
d图这里画的图是每个stage的最后一个卷积层,因为每个stage的最后一层feature语义信息最多
具体做法是两个特征层的较高层特征2倍上采样(上采样方法很多,上采样几乎都是采用内插值方法,即在原有图像像素的基础上在像素点之间采用合适的插值算法插入新的元素,总之是把feature大小扩大了一倍)。较低层特征通过1×1卷积改变一下低层特征的通道数,然后简单地把将P的上采样和1×1卷积后的结果对应元素相加。为什么横向连接要使用1×1卷积呢,为什么不能原地不动地拿过来呢?原来在于作者想用1×1改变通道数,以达到各个level处理结果的channel都为256-d,便于后面对加起来的特征进行分类。这段文字表述的即是下图。
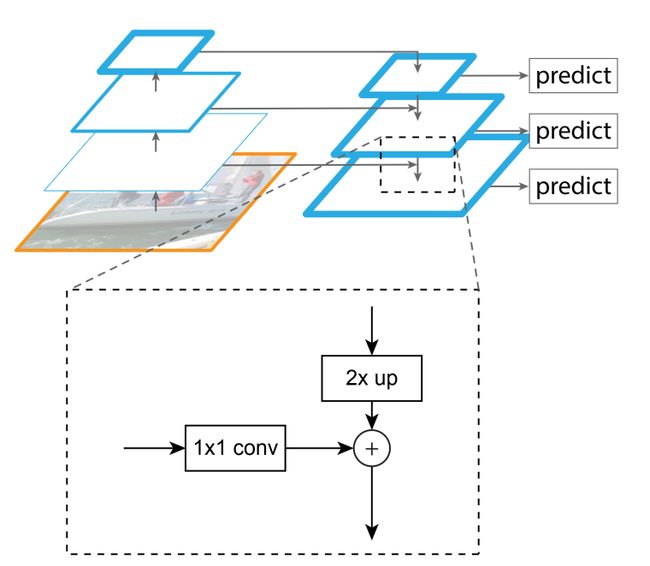
FPN只是提取特征的一种方法而已,这篇论文作者的应用于实验主要是在Faster R-CNN上进行的。
虽然d图只画了3个stage,但我们以论文描述的为主,其实最起码有5个stage。左侧模型从低到高的卷积结果记为C2,C3,C4,C5,C6(有C1,但是论文里是抛弃了这层,为了不造成混淆,所以这里自动忽略了),同理右侧模型从低到高记为P2,P3,P4,P5,P6。
接下来的内容最好联系下图Faster R-CNN网络进行学习。

[外链图片转存失败(img-L6bC01gd-1567168956130)(https://raw.githubusercontent.com/FermHan/tuchuang/master/20190404152622.png)]
先在图像上进行完像图d一样的操作后,得到FPN的结果,结果即d图右侧模型 P i P_i Pi。而d图左侧是普通的主干网络 C i C_i Ci。然后我们在FPN的结果(d图右侧)上进行操作:像Faster R-CNN中的RPN一样,先在 P i P_i Pi上进行3×3的卷积操作,然后在此结果上,两支并行的1×1卷积核分别卷积出来分类(前背景)与框位置信息(xywh)。
然后我们把RPN的结果拿出来进行RoIpooling后进行分类。
至此FPN的框架介绍结束,简言之把FPN结合到普通网络中后,有三条路线:Bottom-up pathway + Top-down pathway + lateral connections。
2、框架三部分Details
Bottom-up pathway
Bottom-up的画的是每个stage的最后一层feature,这个我们已经前文说过,因为该层有最strong的特征。
此文用的是ResNet,所以 C i = { C 2 , C 3 , C 4 , C 5 } C_i=\{C_2,C_3,C_4,C_5\} Ci={C2,C3,C4,C5},分别对应conv2,conv3,conv4,conv5的输出,与原图相比的步长分别是{4,8,16,32}。不要conv1的原因是its large memory footprint(能体会但是不会翻译)。
Top-down pathway and lateral connections
上采样操作降低了特征的分辨率(hallucinate higher resolution features,这句可能没理解好,望纠正)。但是这些上采样的结果通过与横向连接结合,相加更好enhance了。相加的两者中,bottom-up的特征 C i C_i Ci虽然语义信息较少,但他的位置信息较多,因为他的下采样次数更少。The bottom-up feature map is of lower-level semantics,but its activations are more accurately localized as it was subsampled fewer times
在ResNet中,先在 C 5 C_5 C5上进行1×1卷积降维通道数,得到P5。P5上采样结果与C4的1×1卷积结果对应元素相加,得到P4,然后用3×3卷积处理,以减小上采样带来的混淆现象(附原文We append a 3×3 convolution on each merged map to generate the final feature map,which is to reduce the aliasing effect of upsampling)。相加的结果称为 { P 2 , P 3 , P 4 , P 5 } \{P_2,P_3,P_4,P_5\} {P2,P3,P4,P5},与同样大小的 C i C_i Ci对应。
因为金字塔所有级level使用相同的分类/回归器(这句应该指的是RPN),所以固定了特征图上的通道数d都为256,即每个stage或每个level的特征图 P i P_i Pi的通道数都是d=256。
[外链图片转存失败(img-c56KdcmF-1567168956138)(https://raw.githubusercontent.com/FermHan/tuchuang/master/20190408105937.jpg)]
由上图可以看出(上图在P5P6处有些错误),我们的C2-C5是Bottom-up
pathway卷积出来的,P5是1×1卷积改变通道数256后的结果,其余P4,P3,P2是1×1卷积和上采样加和的融合。然后P2-P5经过3×3卷积后仍然叫P2-P5(Pi处理后赋值给Pi)。P6是从C5上用3×3卷积、步长为2极大值池化后直接得到的
3、应用
FPN for RPN
RPN即一个用于目标检测的一系列滑动窗口。具体地,RPN是先进行3×3,然后跟着两条并行的1×1卷积,分布产生前背景分类和框位置回归,我们把这个组合叫做网络头部network head。
但是前背景分类与框位置回归是在anchor的基础上进行的,简言之即我们先人为定义一些框,然后RPN基于这些框进行调整即可。在SSD中anchor叫prior,更形象一些。为了回归更容易,anchor在Faster R-CNN中预测了3种大小scale,宽高3种比率ratio{1:1,1:2,2:1},共9种anchor框。
在FPN中我们同样用了一个3×3和两个并行的1×1,但是是在每个级上都进行了RPN这种操作。既然FPN已经有不同大小的特征scale了,那么我们就没必要像Faster R-CNN一样采用3种scale大小的anchor了,我们只要采用3种比率的框就行了。所以每个级level的anchor都是相同的scale。所以我们在 { P 2 , P 3 , P 4 , P 5 , P 6 } \{P_2,P_3,P_4,P_5,P_6\} {P2,P3,P4,P5,P6}上分别定义anchor的scale为 { 3 2 2 , 6 4 2 , 12 8 2 , 25 6 2 , 52 1 2 } \{32^2,64^2,128^2,256^2,521^2\} {322,642,1282,2562,5212},在每级level的 P i P_i Pi上有{1:1,1:2,2:1}三种宽高比率ratio的框。所以我们在特征金字塔上总共有15个anchor。
需要特别说明的是虽然在 { P 2 , P 3 , P 4 , P 5 , P 6 } \{P_2,P_3,P_4,P_5,P_6\} {P2,P3,P4,P5,P6}上训练RPN,但只有 { P 2 , P 3 , P 4 , P 5 , P 6 } \{P_2,P_3,P_4,P_5,P_6\} {P2,P3,P4,P5,P6}用于fast rcnn的第二阶段。
RPN训练时需要有anchor的前背景类标。对anchor进行label的原理和Faster R-CNN里一模一样,详情可以去本人博客https://blog.csdn.net/hancoder/article/details/87917174 的RPNlabel部分查看。反正就是与gt的IoU>0.7就是正类label=1,IoU<0.3是负类背景label=0,其余介于0.3和0.7直接的都扔掉不参与训练label=-1。在faster rcnn中拿256个anchors训练后得到W×H×9个roi。
此外,每个级level的头部的参数是共享的,共享的原因是实验验证出来的。实验证明,虽然每级的feature大小不一样,但是共享与不共享头部参数的准确率是相似的。这个结果也说明了其实金字塔的每级level都有差不多相似的语义信息,而不是普通网络那样语义信息区别很大。
FPN for Fast R-CNN
把 { P 2 , P 3 , P 4 , P 5 , P 6 } \{P_2,P_3,P_4,P_5,P_6\} {P2,P3,P4,P5,P6}都经过RPN后,在每级都得到了一些ROI,而ROI的xywh千奇百怪。RPN给了我们ROI的xywh,那么我们要在哪级的特征图上切取xywh区域(切取后送到Align Pool)送到后面第二阶段的fast rcnn网络呢?
作者给出的建议是:
不同尺度的ROI,使用不同特征层作为ROI pooling层的输入。大尺度ROI就用后面一些的金字塔层,比如P5;小尺度ROI就用前面一点的特征层,比如P4。计算公式如下:
k = ⌊ k 0 + l o g 2 ( w h / 224 ) ⌋ k=\left \lfloor k_0+log_2(\sqrt{wh}/224) \right \rfloor k=⌊k0+log2(wh/224)⌋
224是ImageNet预训练图的大小,k0是基准值(面积为224×224的roi所在的层级),设置为5或4,代表P5层的输出(原图大小就用P5层),
w和h是ROI区域的长和宽,
假设ROI是112 * 112的大小,那么k = k0-1 = 5-1 = 4,意味着该ROI应该使用P4的特征层。k值做取整处理。这意味着如果RoI的尺度变小(比如224的1/2),那么它应该被映射到一个精细的分辨率水平。
k的计算结果只会是2345,即不要第6级特征图进行第二阶段的训练和测试了。
利用这个公式的意义是大尺度的ROI在低分辨率的特征图上切有利于大目标,小尺度的ROI从高分辨率特征图上切,有利于检测小目标。
FPN for Mask R-CNN
如faster rcnn一样,只利用align pool后的特征图,因此FPN的工作在此前已经做完了,FPN与mask rcnn的mask分支没有关系。
4、实验
使用80类的COCO数据集,训练集80k,验证集35k+5k(mini),在ImageNet1k上预训练。使用ResNet-50和Resnet-101模型。
表1 FPN对RPN的影响:关心的是召回率AR[外链图片转存失败(img-AgIyp8Xi-1567168956144)(https://raw.githubusercontent.com/FermHan/tuchuang/master/20190407150341.png)]
下标sml指的是gt框的大小small,medium,large
- (a,b)只使用conv4或conv5的R-CNN在召回率上提升10%(a,b),尤其在小物体上提升明显。(使用相同的超参数anchors)
- (d)去掉了top-down,只保留横向连接 。即去掉了上采样。相当于论文图1的c。性能仅与原 RPN 差不多,原因可能是不同层的语义信息差别较大。原因在于不同层之间的语义特征差距较大。还测试了共享/不共享头部参数的区别,都很差。
- (e)去掉了横向链接。相当于只上采样。语义多,但位置不准确。
- (f)只用P2特征层,不使用金字塔模型。对应论文图1的(b)。结果当然不是很好。
表2 FPN对Fast R-CNN的影响:关心的是准确率AP
[外链图片转存失败(img-SxXJMN7D-1567168956144)(https://raw.githubusercontent.com/FermHan/tuchuang/master/20190407150416.png)]
类似于RPN的实验,改变FPN的结构,以验证FPN对Fast R-CNN重要性。
表3FPN对整个Faster R-CNN的影响
[外链图片转存失败(img-8Nv9IOcB-1567168956145)(https://raw.githubusercontent.com/FermHan/tuchuang/master/20190407150436.png)]
表4 对比其他单模型
[外链图片转存失败(img-UeoWzFha-1567168956146)(https://raw.githubusercontent.com/FermHan/tuchuang/master/20190407150501.png)]
表5 共享特征
在FPN基础上,将RPN和Fast R-CNN的特征共享,与原Faster R-CNN一样,精度得到了小幅提升。
[外链图片转存失败(img-0zKVgmGc-1567168956147)(https://raw.githubusercontent.com/FermHan/tuchuang/master/20190407150523.png)]
表6 在实例分割上的表现
[外链图片转存失败(img-Q4UaQXWC-1567168956147)(https://raw.githubusercontent.com/FermHan/tuchuang/master/20190407150549.png)]
5、CVPR现场:
海报:https://vision.cornell.edu/se3/wp-content/uploads/2017/07/fpn-poster.pdf
[外链图片转存失败(img-S34cM3Ss-1567168956147)(https://raw.githubusercontent.com/FermHan/tuchuang/master/20190407220106.png)]
上图是FPN的海报,Fast R-CNN+FPN与单纯的Fast R-CNN没什么差别。通道数从1024减小到256减少了计算量,训练和前向运算都快了。
我们利用2个MLP层取代了Conv5,作为我们的头分类器;
CVPR 现场 QA:
Q1. 不同深度的 feature map 为什么可以经过 upsample 后直接相加?
A:作者解释说这个原因在于我们做了 end-to-end 的 training,因为不同层的参数不是固定的,不同层同时给监督做 end-to-end training,所以相加训练出来的东西能够更有效地融合浅层和深层的信息。
Q2. 为什么 FPN 相比去掉深层特征 upsample(bottom-up pyramid) 对于小物体检测提升明显?(RPN 步骤 AR 从 30.5 到 44.9,Fast RCNN 步骤 AP 从 24.9 到 33.9)
A:作者在 poster 里给出了这个问题的答案
[外链图片转存失败(img-qFoZWYb8-1567168956148)(https://raw.githubusercontent.com/FermHan/tuchuang/master/20190407220545.png)]
对于小物体,一方面我们需要高分辨率的 feature map 更多关注小区域信息,另一方面,如图中的挎包一样,需要更全局的信息更准确判断挎包的存在及位置。
Q3. 如果不考虑时间情况下,image pyramid 是否可能会比 feature pyramid 的性能更高?
A:作者觉得经过精细调整训练是可能的,但是 image pyramid 主要的问题在于时间和空间占用太大,而 feature pyramid 可以在几乎不增加额外计算量情况下解决多尺度检测问题。
后续
-
FPN如今已成为Detecton算法的标准组件,不管是one-stage(RetinaNet、DSSD)、two-stage(Faster R-CNN、Mask R-CNN)还是four-stage(Cascade R-CNN)都可用;
-
何恺明大神的论文Mask R-CNN 获得ICCV最佳论文,其中也应用了FPN网络
-
R-FCN系由于其自身设计的缘故,无法使用FPN;
-
后来者PAN在FPN的基础上再加了一个bottom-up方向的增强,使得顶层feature map也可以享受到底层带来的丰富的位置信息,从而把大物体的检测效果也提上去了:
6、代码实现
# 在此贴出Pi卷积层的代码,帮助理解
# Build the shared convolutional layers.
# Bottom-up Layers
# Returns a list of the last layers of each stage, 5 in total.
# 扔掉了C1
_, C2, C3, C4, C5 = resnet_graph(input_image, "resnet101", stage5=True)
# Top-down Layers
# TODO: add assert to varify feature map sizes match what's in config
P5 = KL.Conv2D(256, (1, 1), name='fpn_c5p5')(C5) # C5卷积一下就当做P5
P4 = KL.Add(name="fpn_p4add")([ # P4 开始有了对应元素add操作
KL.UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5),
KL.Conv2D(256, (1, 1), name='fpn_c4p4')(C4)])
P3 = KL.Add(name="fpn_p3add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4),
KL.Conv2D(256, (1, 1), name='fpn_c3p3')(C3)])
P2 = KL.Add(name="fpn_p2add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p3upsampled")(P3),
KL.Conv2D(256, (1, 1), name='fpn_c2p2')(C2)])
# Attach 3x3 conv to all P layers to get the final feature maps.
P2 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p2")(P2)
P3 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p3")(P3)
P4 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p4")(P4)
P5 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p5")(P5)
# P6 is used for the 5th anchor scale in RPN. Generated by
# subsampling from P5 with stride of 2.
# P6是P5的极大值池化
P6 = KL.MaxPooling2D(pool_size=(1, 1), strides=2, name="fpn_p6")(P5)
# Note that P6 is used in RPN, but not in the classifier heads.
rpn_feature_maps = [P2, P3, P4, P5, P6]
mrcnn_feature_maps = [P2, P3, P4, P5]
参考:
https://blog.csdn.net/jningwei/article/details/80661954
https://vision.cornell.edu/se3/wp-content/uploads/2017/07/fpn-poster.pdf FPN的海报
机器之心
https://blog.csdn.net/weixin_40683960/article/details/79055537