树莓派wukong-robot智能音箱(三)-- 手动安装实现智能语音聊天
1. 克隆本仓库:
git clone https://github.com/wzpan/wukong-robot.git
2. 安装 sox ,ffmpeg 和 PyAudio:
sudo apt-get install portaudio19-dev python-pyaudio python3-pyaudio sox pulseaudio libsox-fmt-all ffmpeg

pip3 install pyaudio

如果遇到 pip3 安装慢的问题,可以考虑使用 Pypi 镜像。例如 清华大学 Pypi 镜像 。
3. 安装依赖的库:
cd wukong-robot
pip3 install -r requirements.txt

4. 编译 _snowboydetect.so
手动编译 snowboy ,得到 _snowboydetect.so ,以支持更多的平台。
安装 swig
首先确保你的系统已经装有 swig 。
对于 Linux 系统:
wget http://hahack-1253537070.file.myqcloud.com/misc/swig-3.0.10.tar.gz
tar xvf swig-3.0.10.tar.gz
cd swig-3.0.10
sudo apt-get -y update
sudo apt-get install -y libpcre3 libpcre3-dev
./configure --prefix=/usr --without-clisp --without-maximum-compile-warnings
make
sudo make install
sudo install -v -m755 -d /usr/share/doc/swig-3.0.10
sudo cp -v -R Doc/* /usr/share/doc/swig-3.0.10
sudo apt-get install -y libatlas-base-dev如果提示找不到 python3-config 命令,你还需要安装 python3-dev:
sudo apt-get install python3-dev # 注意 Ubuntu 18.04 可能叫 python3-all-dev
构建 snowboy
wget http://hahack-1253537070.file.myqcloud.com/misc/snowboy.tar.bz2 # 使用我fork出来的版本以确保接口兼容
tar -xvjf snowboy.tar.bz2
cd snowboy/swig/Python3
make
cp _snowboydetect.so 
如果 make 阶段遇到问题,尝试在 snowboy 项目 issue 中找到解决方案 。
使用 Mac 、Ubuntu 16.04 、Deepin 和 Raspberry Pi 系统的用户也可以试试预编译好的版本:
- Mac
- Ubuntu
- Deepin
- Raspberry Pi
5. 安装第三方技能插件库 wukong-contrib
mkdir $HOME/.wukong
cd $HOME/.wukong
git clone https://github.com/wzpan/wukong-contrib.git contrib
pip3 install -r contrib/requirements.txt 

6. 更新唤醒词(可选,树莓派必须)
默认自带的唤醒词是在 Macbook 上录制的,用的是作者的声音模型。但由于不同的人发声不同,所以不保证对于其他人都能很好的适用。
而树莓派上或者其他板子上接的麦克风可能和 PC 上的麦克风的声音畸变差异非常大,所以现有的模型更加不能直接在树莓派上工作,否则效果会非常糟糕。
如果你是第一次使用,需要先创建一个配置文件方便配置唤醒词。这个工作可以交给 wukong-robot 帮你完成。在 wukong-robot 的根目录下执行:
python3 wukong.py第一次启动将提示你是否要到用户目录下创建一个配置文件,输入 y 即可。配置文件将会保存在 ~/.wukong/config.yml 。

打开对应树莓派的IP地址端口5000,我这里的是172.30.1.88:5000,根据自己的设备IP设置
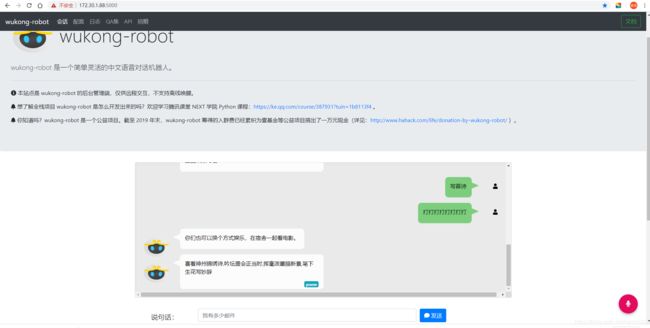
接下来我们来训练和更新唤醒词。比较建议到 snowboy 官网 上训练自己的模型,然后把模型放在 ~/.wukong 中,并修改 ~/.wukong/config.yml 里的几个 hotword 指向的文件名(如果文件名没改,则不用变)。一共有三个唤醒词需要修改:
hotword:全局唤醒词。默认为 “孙悟空” (wukong.pmdl)/do_not_bother/on_hotword:让 wukong-robot 进入勿扰模式的唤醒词。默认为 “悟空别吵” (悟空别吵.pmdl)/do_not_bother/off_hotword:让 wukong-robot 结束勿扰模式的唤醒词。默认为 “悟空醒醒” (悟空醒醒.pmdl)
对于树莓派用户,如果不想自己训练模型,wukong-robot 也提供了几个针对树莓派训练的模型,直接修改配置即可:
# snowboy 离线唤醒
# https://snowboy.kitt.ai/dashboard
# 建议到 https://snowboy.kitt.ai/hotword/32768
# 使用相同环境录入你的语音,以提升唤醒成功率和准确率
hotword: 'wukong_pi.pmdl' # 唤醒词模型,如要自定义请放到 $HOME/.wukong 目录中
sensitivity: 0.4 # 灵敏度
# 勿扰模式,该时间段内自动进入睡眠,避免监听
do_not_bother:
enable: false # 开启勿扰模式
since: 23 # 开始时间
till: 9 # 结束时间,如果比 since 小表示第二天
on_hotword: '悟空别吵_pi.pmdl' # 通过这个唤醒词可切换勿扰模式。默认是“悟空别吵”
off_hotword: '悟空醒醒_pi.pmdl' # 通过这个唤醒词可切换勿扰模式。默认是“悟空醒醒”但是同样建议到 snowboy 官网 自己训练。snowboy 官方建议在树莓派上先用 rec t.wav 这样的命令录制唤醒词,然后在训练的时候通过上传按钮上传到服务器中进行训练:

也可以使用 wukong.py 提供的 train 命令来进行训练。
- 首先使用
rec或者arecord来录制唤醒词的三段语音。例如:
cd $HOME
arecord a.wav
arecord b.wav
arecord c.wav- 然后,如果你还没有在 config.yml 配置文件中填写
snowboy_token的配置,可以先访问 https://snowboy.kitt.ai ,在 “Profile settings” 中找到你的 token :
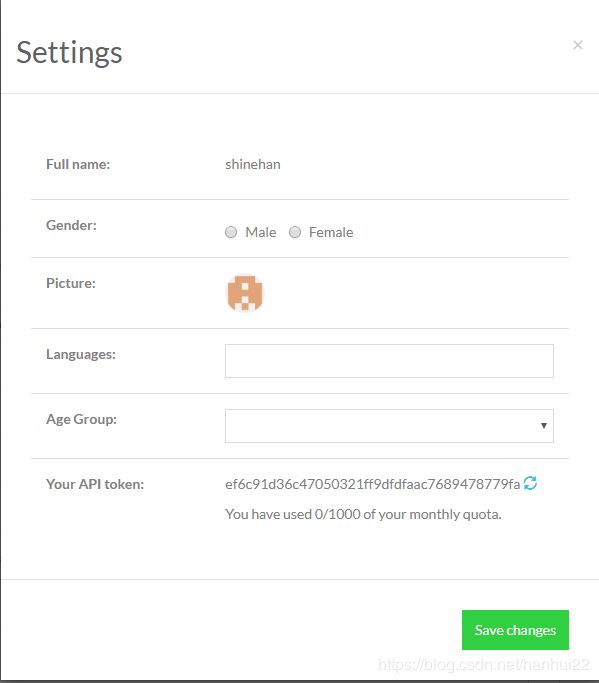
然后把它填进 config.yml 中。
- 之后,使用如下命令训练成唤醒词:
python3 wukong.py train $HOME/a.wav $HOME/b.wav $HOME/c.wav $HOME/.wukong/mywords.pmdl其中 mywords.pmdl 即是要生成的 pmdl 的名字。你也可以换成你喜欢的名字(但尽量不要用中文)。
- 完成后修改下 config.yml 把唤醒词改成刚刚训练的唤醒词即可。
CentOS 没声音问题解决
有用户在 CentOS 系统中遇到播放没声音的问题。解决方法是:
mknod /dev/dsp c 14 3
chmod 666 /dev/dsp