CVPR 2018 Saliency Detection 论文
1. Deep Unsupervised Saliency Detection: A Multiple Noisy Labeling Perspective
Jing Zhang1,2, Tong Zhang2,3, Yuchao Dai†1, Mehrtash Harandi2,3, and Richard Hartley2
1 中国西北工业大学,戴玉超教授; 2 澳大利亚国立大学 ;

大概思路:
(1)一方面,当前的深度显著性检测模型的成功,依赖于监督的方式,这种方式是带来了数据标注的费时费力,且泛化能力差;另一方面,传统的基于无监督方法手工提取特征,虽然性能不及有监督深度学习方法,但她独立于数据集,且泛化能力较强。
(2)所以该论文提出了一个端对端的无监督显著性检测模型,该模型包含两个模块,一个模块是潜在的显著性检测模块,一个模块是噪声建模模块。第一个模块强力的FCN网络负责性能,第二个模块使用传统的无监督方法生成噪声显著图,通过使用该噪声显著图,解决数据标注费时费力的问题。
(3)该模型有三个关键因素:
1)噪声显著图(noise saliency map)由传统的无监督手工提特征得到的噪声显著图;
2)潜在显著图(latent saliency map),由FCN神经网络生成;
3)噪声图,符合零均值高斯分布图。
噪声显著图,视为是潜在显著图与噪声图之和,并建模如下:假如给定FCN的参数,给定噪声图,输入一个图像,则有:
$$ \hat {y}_i^j = f(x_i; \theta) + n_i^j = \overline {y}_i + n_i^j $$
其中FCN的参数,和噪声图并不是给定的,所以需要定义损失函数去拟合,损失函数分为两部分:
$$ L(\theta, \sum) = L_{pred} (\theta, \sum) + \lambda L_{noise} (\theta, \sum) $$
左边部分使用交叉熵损失函数,右边部分使用KL距离为损失函数。优化参数,使得总的损失值最小。
想法:该方法贡献在于方法是一种深度学习模型,但能做到无监督。
2. A Bi-directional Message Passing Model for Salient Object Detection
Lu Zhang1, Ju Dai1, Huchuan Lu1, You He2, Gang Wang3
1 中国大连理工大学,卢湖川;2 海军航空大学;3 阿里巴巴 AILabs

思路:最近显著性目标检测因为使用FCN网络取得了较好的性能。包含在多级别卷积特征中的显著线索(saliency cues)对检测显著目标有一定的帮助。但是如何整合这些多级别特征,是显著性检测领域的一个公开问题。
所以,改论文提出一个新的双向消息传递模型,来整合这些多级别特征。模型的具体描述:
(1)输入彩色图像到修改后的VGG16网络中,依次生成多级别特征图,这些特征图可以捕获显著目标的不同信息,该VGG16去掉了全连接层,去掉最后一个池化层,使其如上图,由5部分组成;
(2)使用MCFEM模块,依次作用于不同的多级别特征图,提取多级别情景特征;
(3)使用GBMPM模块,整合上面生成的多级别情景特征图,生成多个融合的多级别特征图;
(4)使用这些融合的多级别特征图,依次生成不同分辨率的显著图;
(5)融合多级别预测结果,生成最终显著图。
总结:这篇论文利用了每一个卷积得到的特征,作为不用视野下的特征表示,不是简单的平均,而是自适应的融合不同级别的特征图。
3. Cube Padding forWeakly-Supervised Saliency Prediction in 360◦ Videos
Hsien-Tzu Cheng1, Chun-Hung Chao1, Jin-Dong Dong1, Hao-Kai Wen2, Tyng-Luh Liu3, Min Sun1
1国立清华大学;2Taiwan AI Labs;3中国研究院
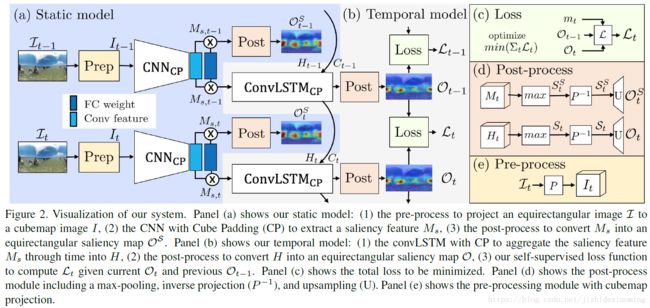
思路:
(1)360度视频显著性检测技术是360度视频的视点引导应用的关键技术,360视频捕获了场景中所有角度的视觉内容。将360度视频进行equirectangular projection,映射成equirectangular图像,将会产生形变和带来图像边界(360视频是没有图像边界的),两者都会网络学习变难。而将360度视频分成多个分开的透视图,虽然可以避免形变,但带来了更多的图像边界。
(2)作者将360度视频分成许多个重叠的透视图,然而太多的透视图会明显降低预测处理速度,所以该论文对现存的CNN网络做了简单的修改,来克服这个挑战。
(3)具体解决办法:将360度视频帧映射为立方体的六个面,然后利用立方体各个面之间的连接性,把六个面拼接起来,喂到网络中。
注:常用的显著性检测论文及代码汇总