对《ToonSynth: Example-Based Synthesis of Hand-Colored Cartoon Animations》一文的理解(上)
本文发表于SIGGRAPH2018,作者是MAREK DVOROŽŇÁK, Czech Technical University in Prague, Faculty of Electrical Engineering WILMOT LI, Adobe Research VLADIMIR G. KIM, Adobe Research DANIEL SÝKORA, Czech Technical University in Prague, Faculty of Electrical Engineering
该博客是上文,重在翻译。
ToonSynth:基于实例的手工彩色卡通动画合成
我们提出了一种新的基于实例的方法来合成手工彩色卡通动画。 我们的方法产生的结果保留了手动创作的动画的特定视觉外观和风格化动作,而无需艺术家从头开始绘制每一帧。在我们的框架中,艺术家首先风格化一组有限的已知源骨骼动画,我们从中提取样式 - 感知木偶,编码艺术品的外观和运动特征(In our framewok, the artist first stylizes a limited set of known source skeletal animations from which we extract a style-aware puppet that encodes the appearance and motion characteristics of the artwork)。 给定新的目标骨架运动,我们的方法自动从源示例传输样式以创建手动颜色的目标动画(Given a new target skeletal motion, our method automatically transfers the style from the source examples to create a hand-colored target animation)。 与之前的工作相比,我们的技术是首次能够保留原始手绘内容的详细视觉外观和风格化运动的技术。 我们的方法有许多实际应用,包括传统动画制作和游戏内容创作。
CCS 内容:计算方法--->运动处理;图像处理
关键词:风格转移(style transfer),骨骼动画
1、INTRODUCTION
虽然计算机图形学的进步促成3D动画演变成为一种富有表现力的成熟媒体,但2D动画仍然是一种非常受欢迎且引人入胜的讲故事方式。创建2D动画的一个常见工作流程是将角色,物体和背景分解为单独的层,这些层随着时间的推移(刚性或非刚性地运动)变换以产生期望的运动(One common workflow for creating 2D animations is to decompose characters, objects and the background into separate layers that are transformed over time to produce the desired motion)。这种基于图层的方法的一个关键优势是可以在许多动画帧中重复使用单件艺术品(即图层)。只要图层的外观没有显着变化(例如,角色的躯干从前视图转向侧视图),艺术家就不需要从头开始重绘。与每一帧都用手绘制和着色相比,用图层动画大大减少了制作的耗费,这是为什么许多现代漫画系列(例如,Archer,BoJack Horseman,Star vs the Forces of Evil)都是以这种方式创建的原因之一。


![]()
(妈妈,这个男人好帅!!!!!!泪流满面)
不幸的是,这种效率的提高需要付出一定的代价。虽然手工制作的动画可以让艺术家完全自由地指定每个画面的外观,但是使用典型的基于图层的工作流程很难制作出很多风格的艺术作品(many styles of artwork are hard to animate using a typical layer-based workflow)。由于层可以在多帧中进行重复使用和转换,因此纹理区域在压缩和拉伸时可能会看起来很笨拙(Since layers are reused and transformed across several frames, painterly artwork can look awkward as textured regions are compressed and stretched.)。此外,当线条的样式在帧之间保持的不变的话,被笔刷线条渲染出来的作品会显得“死气沉沉”,莫得灵魂(In addition, rendering styles with visible brush strokes often appear somewhat "dead" when the pattern of strokes remains fixed from frame to frame.)。除了艺术作品的外观之外,层的运动也受到限制,因为商业工具通常能够实现有限的一组变换,这些变换不直接支持许多二次特效或者运动部件的过度弯曲和凸出(since commercial tools typically enable a limited set of transformations that do not directly support many secondary effects or exaggerated blending and bulging of moving parts. )。因此,大多数基于图层的动画都会被渲染出来简单,平面阴影样式,表现出相对僵硬或不平稳的动作(As a result, most layer-based animations are rendered in simple, flat-shaded styles and exhibit relatively stiff or jerky motion)。
在这项工作中,我们提出了一个基于实例的分层动画工作流程,允许艺术家通过为一个或多个特定的源动作指定一小组手工彩色示例帧来自定义角色的外观和动作(allows artists to customize the appearance and motion of characters by specifying a small set of hand-colored example frames for one or more specific source motions.)。我们的系统自动捕捉并将示例的样式应用于新的目标运动。我们的方法和标准分层动画之间的主要区别在于,目标动画帧是通过基于示例帧集合每个层而不是变换单个绘制层来生成的。由于合成过程在手动着色动画源的外观和动作中保留了风格方面,因此我们的方法支持更广泛的动画风格。与传统的逐帧绘图相比,我们的方法允许艺术家更多地使用他们的艺术作品,因为相对较小的一组绘图就可以发挥杠杆作用以产生各种相关运动的动画效果(例如,绘制的步行周期可用于生成快速的生气行走,慢速偷偷摸摸的行走等)。
用于2D动画的现有基于示例的技术主要关注于诸如2D形状插值(2D shape interpolation),运动(motion)或外观转移(appearance transfer)的各个子问题。然而,单独关注各个步骤会导致真正的手绘艺术作品与计算机生成的输出之间存在显着差异:运动特征或视觉外观缺乏质量。例如,在某些情况下,使用适当的运动特征对形状进行插值,但外观包括由于纹理的扭曲或混合引起的伪影[Arora et al .2017; Baxter 2009年;Sýkora2009年]。或者,外观传递得恰到好处,但潜在的运动感觉太过人为[Fišer等人2017年,2014年])。因此,一个关键的剩余挑战是将运动和外观风格化结合到一个整体框架中,该框架产生具有手绘动画的所有特征的综合结果。据我们所知,我们的方法是第一个提供这种联合解决方案的方法,并且能够从少量动画样本中自动合成令人信服的手工彩色卡通动画。
我们定制我们的方法来处理具有遮挡的平面内运动(we tailor our method to handle in-plane motions with occlusions),这对于卡通动画和游戏场景来说是典型的。专注于此类运动使我们能够应用相对简单的算法,该算法仍能产生支持一系列实际应用的有效结果。对于涉及更复杂的深度顺序变化以及拓扑变化的平面外运动(out-of-plane),需要额外的手动干预。
我们的论文做出了以下具体贡献。 我们定义了分层风格感知木偶的概念,该木偶足够灵活,可以对艺术家的手工彩色动画帧所体现的外观和动作风格化属性进行编码(We define the concept of a layered style-aware puppet that is flexible enough to encode both the appearance and motion stylization properties exemplified by the artist's hand-colored animation frames.)。 我们还提出了一种机制,将这个木偶捕获的信息结合起来,将运动和外观风格转移到骨骼运动规定的目标动画上(We also present a mechanism to combine the information captured by this puppet to transfer motion and appearance style to target animations prescribed by skeletal motion)。 与以前的工作相比,我们的技术的一个主要好处是我们专门设计了我们的管道,以保留原始艺术媒体的视觉特征,包括用户可控制的时间不连贯性(we specifically designed our pipeline to preserve the visual characteristics of the original artistic media, including a user-controllable amount of temporal incoherence)。
2、RELATED WORK
由Catmull [1978]开创,在过去的几十年里,人们一直在努力模拟或简化使用计算机制作传统手绘动画的过程。
计算机辅助的中间功能[Kort 2002] - 即,从一组手绘关键帧生成平滑内插动画 - 是受到极大关注的问题之一(Computer-assisted inbetweening -i.e.,generating smoothly interpolated animation from a set of hand-drawn keyframes-is one of the problems that has received significant attention)。已经提出了各种技术来解决它,无论是在矢量领域还是光栅领域都实现了令人印象深刻的结果[BaxterandAnjyo2006; Whited etal2010; Yang 2017][Arora et al 2017; Baxter等2009年;Sýkora等2009年]。这些技术中的一些提出了在所有可用帧之间的N路变形以扩展可用的姿势空间(Some of these techniques propose N-way morphing between all available frames to widen the available pose space.)。然而,inbetweening旨在仅在关键帧之间提供看似合理的过渡。要为新的目标运动制作动画,艺术家必须手动创建其他关键帧。
另一大批研究重点是模拟传统动画中的基本运动原理,包括压缩和拉伸(squash-and-stretch),预期(anticipation)和后续(follow-through)[Lasseter 1987]。现有工作提出了定制化的程序技术[Kazi et al .2016;李等人2012;施密特等人2010; Wang et al.2006]以及可控物理模拟[Bai et al2016年琼斯等人2015; Willett等2017年;朱等人2017年](Existing work proposes customized procedural techniques as well as controllable physical simulation)。虽然这些方法能够实现传统动画的外观和感觉,但它们通常不会保留特定动作细节----能够特色化一个艺术家给定的风格的动作细节。这些技术也没有考虑如何忠实地保留运动中手绘艺术作品的详细视觉外观。在大多数情况下,纹理只是拉伸和变形,这会导致视觉伪影。
为了保留更多的手绘外观,一些技术直接重用或操纵现有的手绘内容。他们要么使用动画序列不变[Buck et al 2000; van Haevre等 2005; de Juan和Bodenheimer 2004,2006]并且只对动画帧重新排序,在中间添加更多内容,或者直接操作像素级别的外观[Sýkora等人2011年,2009年;张等人2012]增强视觉内容或改变运动特征。虽然这些方法更好地保留了手工彩色动画的概念,但它们对动作进行实质性改变的可能性相当有限。当需要从现有素材中生成不同的动画时,通常需要大量的手动工作。
图像类比[Hertzmann et al2001]提供了一个基于示例艺术作品合成新内容的强大框架,可以不用直接重复使用手绘帧。在该方法中,提供引导图像及其程式化版本以定义样式转移类比(In this approach, a guiding image and its stylized version are provided to define the style transfer analogy)。这种方法已经扩展到动画风格化[Bénard2013]等人随后的工作增加了用户对时间闪烁量的控制[Fišeretal 2017年,2014年]为了更好地保留每个动画框架都是手工独立创建的印象(This approach has been extended to stylize animations with later work adding user control over the amount of temporal flickering to better preserve the impression that every animation frame was created by hand independently.)。但是,这些基于类比的方法仅支持外观样式转换,不考虑如何表示和应用运动样式。
最近,Dvorožňák等人 [2017]提出了一个动作风格的类比框架,它和我们的管道有类似的动机。在他们的工作流程中,艺术家准备一组手绘动画,这些动画将风格化物理模拟计算的刚体运动(圆形或正方形)(In their workflow,an artist prepares a set of hand-drawn animations that stylize input rigid body motion(of circles or squares) computed using physical simulation)。然后,他们通过记录二次变形模型以及残余变形来分析样式。最后,对于给定的目标刚体动画,它们通过混合来自相似示例轨迹段的变形参数来合成手绘动画。我们工作的一个关键区别是我们不仅关注运动风格化,还关注全彩色图纸的外观合成(we focus not only on motion stylization but also appearance synthesis for fully colored drawings)。虽然Dvorožňák等人的方法确实合成了简单的轮廓图,但我们的方法旨在支持各种手工颜色的渲染方式。此外,先前的技术仅处理简单的刚体场景,其中场景中的每个对象可由单个图稿层和一组变形参数表示。相比之下,我们描述了一个类比框架,适用于复杂的,多层次的,清晰的角色。
骨骼动画[Burtnyk和Wein 1976]已被证明是一种有效的2D形状变形工具[Hornungetal2007; Vanaken等2008]。它已被用于控制卡通动画背景下的变形[Sýkora等2005;王等人2013年以及从一系列图纸中转移运动[Bregler et al.2002;戴维斯等人2003; Jain等 2009年]或单一姿势[Bessmeltsev等2016]到3D模型。在我们的框架中,我们证明了骨骼动画也可以在手绘样本和目标动画之间执行样式转换的过程中做有效的指导。
3、OUR APPROACH
我们工作的主要目标是帮助艺术家创建手工彩色的人物动画,而无需从头开始绘制每一帧。由于姿势估计的最新进展[Mehta et al .2017],专业的MoCap系统(Vicon,OptiTrack,The Captury)和现有的运动数据库(CMU,HumanEva,HDM05),我们假设有丰富的可用运动捕捉数据。骨骼动画很容易访问,可以作为传达运动特征的基本工具。此外,MotionBuilder等工具允许用户组合和扩展现有的MoCap数据使用正向/反向运动学来创建适合我们方法的骨骼运动。
因此,我们专注于生成匹配给定目标骨骼运动的彩色动画的挑战,同时遵循艺术家创造的类比-----其中一些手工彩色的帧作为艺术家风格化特定的骨骼动画的示例------的视觉外观和运动风格。受以前类比技术的启发[Dvorožňák等2017年;赫兹曼等人2001]我们称我们的方法动画类比。
在我们的框架中,艺术家首先选择一个短的源骨骼动画![]() ,并通过创作表示源骨骼动画风格化的手工彩色帧来创建源风格化动画
,并通过创作表示源骨骼动画风格化的手工彩色帧来创建源风格化动画 。我们将这对称为源实例
。我们将这对称为源实例![]() 。在源示例中,我们假设的帧大致遵循
。在源示例中,我们假设的帧大致遵循![]() 中的运动,但是由于样式化效应,运动的细节可能不同。例如,如果
中的运动,但是由于样式化效应,运动的细节可能不同。例如,如果![]() 是步行循环,我们假设中的脚步是同步的,但是腿本身可能以夸张的方式弯曲和伸展。我们还假设每个风格化的帧
是步行循环,我们假设中的脚步是同步的,但是腿本身可能以夸张的方式弯曲和伸展。我们还假设每个风格化的帧![]() 可以被分成与
可以被分成与![]() 中的骨架骨骼相关联的一致的一组层,并且层的深度顺序与相应的骨骼的深度顺序匹配(We also assume that each stylized frame
中的骨架骨骼相关联的一致的一组层,并且层的深度顺序与相应的骨骼的深度顺序匹配(We also assume that each stylized frame ![]() can be separated into a consistent set of layers that are associated with the skeleton bones in
can be separated into a consistent set of layers that are associated with the skeleton bones in ![]() and that the depth order of the layers matches that of the corresponding bones.)。这些层中被遮挡部分的形状可以自动重建[Sýkora等2014; Yeh等人2017]或手动修复。艺术家还可以指定那些被遮挡部分的详细外观风格。但是,此步骤是可选的,因为我们的外观转移技术可用于自动填充缺失区域。然后,我们分析源示例
and that the depth order of the layers matches that of the corresponding bones.)。这些层中被遮挡部分的形状可以自动重建[Sýkora等2014; Yeh等人2017]或手动修复。艺术家还可以指定那些被遮挡部分的详细外观风格。但是,此步骤是可选的,因为我们的外观转移技术可用于自动填充缺失区域。然后,我们分析源示例![]() 给出的外观和动作样式,并让艺术家或其他用户提供多个新颖的目标骨架动画
给出的外观和动作样式,并让艺术家或其他用户提供多个新颖的目标骨架动画![]() ,其表示最终动画的角色的期望动作。最后,我们的方法使用类比
,其表示最终动画的角色的期望动作。最后,我们的方法使用类比![]() 自动生成相应的手绘上色输出帧
自动生成相应的手绘上色输出帧![]() (见Fig2)。
(见Fig2)。

虽然目标骨骼运动![]() 可能与源
可能与源![]() 有很大不同,但我们希望基于类比的框架有一些相似之处。例如,艺术家可以对标准步行循环进行风格化,并将风格化转移到偷偷摸摸的步行,醉酒步行或跑步循环。但是,跳跃动作可能与源运动不太相似,无法成功地进行样式化,在这种情况下,可以创建不同的样式示例。
有很大不同,但我们希望基于类比的框架有一些相似之处。例如,艺术家可以对标准步行循环进行风格化,并将风格化转移到偷偷摸摸的步行,醉酒步行或跑步循环。但是,跳跃动作可能与源运动不太相似,无法成功地进行样式化,在这种情况下,可以创建不同的样式示例。
为了实现这种基于类比的工作流程,我们提出了一种引导合成技术(a guided synthesis technique),该技术使用样式示例 来为目标骨骼运动
来为目标骨骼运动![]() 生成风格化帧
生成风格化帧 。我们的方法有两个主要阶段:首先,我们分析源动画以确定骨架动画
。我们的方法有两个主要阶段:首先,我们分析源动画以确定骨架动画![]() 和相应的手工彩色数据
和相应的手工彩色数据![]() 之间的关系。具体来说,我们构造了一个样式感知木偶
之间的关系。具体来说,我们构造了一个样式感知木偶![]() ,它对来自
,它对来自![]() 的每一帧的姿势,形状和外观样式
的每一帧的姿势,形状和外观样式![]() 进行编码。一旦我们进行了这种编码,我们就可以自动将样式应用到
进行编码。一旦我们进行了这种编码,我们就可以自动将样式应用到![]() 中的帧并生成一个新的手动彩色动画
中的帧并生成一个新的手动彩色动画![]() 。以下部分详细描述了这两个阶段。
。以下部分详细描述了这两个阶段。
3.1 Representing Source Stylization
给定源骨架![]() 和风格化
和风格化![]() 动画,我们构造了一个样式感知木偶
动画,我们构造了一个样式感知木偶![]() ,其描述了关于分层模板木偶
,其描述了关于分层模板木偶![]() 的样本的姿势,形状和外观属性(Given the source skeletal So and stylized Ss animations, we construct a style-aware puppet Ps that describes the pose, shape and appearance properties of the exemplars with respect to a layerd template puppet P)。模板木偶
的样本的姿势,形状和外观属性(Given the source skeletal So and stylized Ss animations, we construct a style-aware puppet Ps that describes the pose, shape and appearance properties of the exemplars with respect to a layerd template puppet P)。模板木偶![]() 代表“中性”姿势的角色;它与源图稿具有相同的分层部分集,其中每个部分与源骨架的相应部分相关联(参见Fig4)。如果在原始艺术品中某些部分被遮挡,我们要求艺术家完成其形状并指定需要保留的重要语义细节(例如,面部特征或布料垂直)。然后,我们通过将模板木偶P登记到每个手工着色的源帧
代表“中性”姿势的角色;它与源图稿具有相同的分层部分集,其中每个部分与源骨架的相应部分相关联(参见Fig4)。如果在原始艺术品中某些部分被遮挡,我们要求艺术家完成其形状并指定需要保留的重要语义细节(例如,面部特征或布料垂直)。然后,我们通过将模板木偶P登记到每个手工着色的源帧![]() 来对样式化进行编码。这允许我们提取变形的骨架姿势以及角色相对于P的中性姿势的详细形状变形。我们还以纹理的形式编码角色的外观。更正式地,风格感知木偶
来对样式化进行编码。这允许我们提取变形的骨架姿势以及角色相对于P的中性姿势的详细形状变形。我们还以纹理的形式编码角色的外观。更正式地,风格感知木偶![]() 由分层模板木偶
由分层模板木偶![]() 和每个风格化帧i的元组
和每个风格化帧i的元组![]() 组成(参见Fig3):
组成(参见Fig3):![]() 捕获各个木偶形状的粗糙变形,
捕获各个木偶形状的粗糙变形,![]() 它们的残余弹性变形,
它们的残余弹性变形,![]() 是源骨架姿态
是源骨架姿态![]() 和风格化骨架姿势
和风格化骨架姿势![]() 之间的差异。
之间的差异。![]() 是角色的风格化纹理。我们使用这些元组来设计新颖的骨骼动画
是角色的风格化纹理。我们使用这些元组来设计新颖的骨骼动画![]()
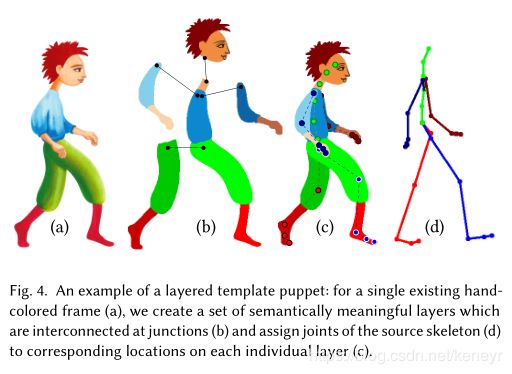

Layerd Template Puppet Creation。即一层又一层(分层)的模板木偶的创建。为了创建分层模板木偶P,我们可以在由艺术家创建的休息姿势中使用特殊的未风格化帧,或者从输入的手绘动画![]() 中获取一个帧(we can either use a special unstylized frame in a rest pose created by the artist or one of the frames taken from the input hand-drawn animation Ss)。 它由一组语义上有意义的层(例如,头部,身体,手和腿)组成,它们在它们的位置自然连接手动缝合在一起(It consists of a set of semantically meaningful layers(e.g.,head,body,hands,and legs) manually stitched together at locations where they naturally connect.)。 每个图层必须在一个或多个用户指定的关节处附加到底层骨架。 这些附件定义了骨骼和层之间的对应关系(见Fig4)(Each layer must be attached to the underlying skeleton at one or more user-specified joints.These attachments define the correspondence between bones and layers.)
中获取一个帧(we can either use a special unstylized frame in a rest pose created by the artist or one of the frames taken from the input hand-drawn animation Ss)。 它由一组语义上有意义的层(例如,头部,身体,手和腿)组成,它们在它们的位置自然连接手动缝合在一起(It consists of a set of semantically meaningful layers(e.g.,head,body,hands,and legs) manually stitched together at locations where they naturally connect.)。 每个图层必须在一个或多个用户指定的关节处附加到底层骨架。 这些附件定义了骨骼和层之间的对应关系(见Fig4)(Each layer must be attached to the underlying skeleton at one or more user-specified joints.These attachments define the correspondence between bones and layers.)
Registration。为了将模板木偶P"注册"到这些带有手工着色的动画 的每个帧i,我们使用与Dvorožňák等人类似的方法。 其中首先估计粗糙变形(coarse deformation),然后提取剩余的残余动态(residual motion)。粗到精策略提高了配准算法(registration algorithm)的鲁棒性,同时仍允许我们编码非常精确的变形。 而Dvorožňák等人使用单个as-rigid-as-possible(ARAP)网格,我们的方法的一个关键改进是我们使用分层ARAP模型,其中多个分段连接网格由我们的分层模板木偶P定义(While Dvorožňák use a single as-rigid-as-possible mesh, a key improvement of our approach is that we use a layerd ARAP model with multiple peicewise connected meshes defined by our layered template puppet P.)
的每个帧i,我们使用与Dvorožňák等人类似的方法。 其中首先估计粗糙变形(coarse deformation),然后提取剩余的残余动态(residual motion)。粗到精策略提高了配准算法(registration algorithm)的鲁棒性,同时仍允许我们编码非常精确的变形。 而Dvorožňák等人使用单个as-rigid-as-possible(ARAP)网格,我们的方法的一个关键改进是我们使用分层ARAP模型,其中多个分段连接网格由我们的分层模板木偶P定义(While Dvorožňák use a single as-rigid-as-possible mesh, a key improvement of our approach is that we use a layerd ARAP model with multiple peicewise connected meshes defined by our layered template puppet P.)
我们使用ARAP图像配准算法计算粗糙变形[Sýkora等2009]。迭代地应用两个步骤:推动相位使用块匹配算法将ARAP网格上的每个点移向目标图像中的更好匹配位置;正则化相位使ARAP网格保持一致(the pushing phase shifts every point on the ARAP mesh towards a better matching location in the target image using a block-matching algorithm; and the regularization phase keeps the ARAP mesh consistent.)。为了将这种方法与我们的多网格ARAP模型一起使用,我们调整推动相位,以便块匹配仅使用相应层的内容来移动每个网格(参见Fig5,左)。这个概念类似于[Sýkora等人使用的基于深度的分离2010],避免了由遮挡引起的混乱,提高了最终注册的整体准确性。所描述的注册过程是自动的。然而,可能存在具有挑战性的配置(例如,当变形与模板相比较大时),其中手动干预(将控制点拖动到期望位置)可以有助于加速配准过程或纠正可能的未对准。
一旦我们获得了我们的分层模板木偶![]() 的粗糙变形,我们通过去除计算的粗糙变形来纠正每个手工着色的部分,并使用Glocker et的方法在模板和整合帧之间执行更准确的弹性配准。该步骤的结果是多层残余运动场
的粗糙变形,我们通过去除计算的粗糙变形来纠正每个手工着色的部分,并使用Glocker et的方法在模板和整合帧之间执行更准确的弹性配准。该步骤的结果是多层残余运动场![]() ,其编码各个身体部位的细微形状变化(Fig5,右)。
,其编码各个身体部位的细微形状变化(Fig5,右)。
为了计算![]() ,我们需要从登记的木偶层的配置推断出风格化的骨架姿势
,我们需要从登记的木偶层的配置推断出风格化的骨架姿势![]() 。我们的目标是仅获得风格化姿势的2D投影。为此,我们使用骨架的拓扑等效2D表示,该表示由根关节位置,骨骼骨骼的长度及其在祖先骨骼的参考系中的旋转指定。由于每个层在特定关节处附接到模板骨架,因此可以从变形网格上的相应附接点的位置直接获得这些关节的风格化位置。然后将
。我们的目标是仅获得风格化姿势的2D投影。为此,我们使用骨架的拓扑等效2D表示,该表示由根关节位置,骨骼骨骼的长度及其在祖先骨骼的参考系中的旋转指定。由于每个层在特定关节处附接到模板骨架,因此可以从变形网格上的相应附接点的位置直接获得这些关节的风格化位置。然后将![]() 计算为根关节位置,骨长度和它们的旋转之间的差
计算为根关节位置,骨长度和它们的旋转之间的差![]() 。
。
最后,通过存储来自手工彩色艺术品的像素来获得![]() 。
。
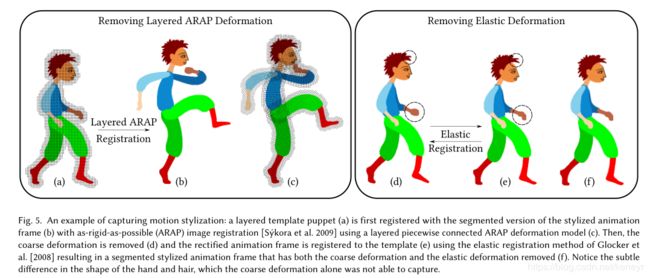
(图5.捕获运动风格化的示例:分层模板木偶(a)首先向风格化动画帧的分段版本(b)注册,具有尽可能刚性(ARAP)图像注册[Sýkora等人2009]使用分层分段连接的ARAP变形模型(c)。 然后,去除粗糙变形(d),并使用Glocker等人的弹性配准方法将校正的动画帧登记到模板(e) [2008]导致分割的风格化动画帧,其去除了粗糙变形和弹性变形(f)。 注意手和头发形状的细微差别,单独的粗糙变形无法捕捉。)
3.2 Style Transfer of Motion and Appearance to Target Skeletal Animation
Synthesis of Motion。我们使用由木偶模板P和每帧元组![]() 表示的提取的样式感知木偶来风格化新的骨架动画的样式。我们假设目标骨架具有与源骨架相同的拓扑,这对于大多数MoCap系统通常是正确的。
表示的提取的样式感知木偶来风格化新的骨架动画的样式。我们假设目标骨架具有与源骨架相同的拓扑,这对于大多数MoCap系统通常是正确的。
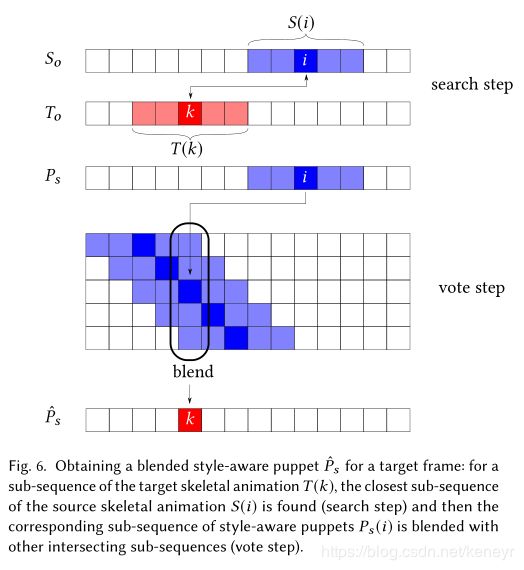
运动风格的转移类似于基于补丁的纹理合成(patch-based texture synthesis)[Kwatra et al2005; Wexler等2007年]涉及两个交替的步骤:搜索和投票。在我们的上下文中,这些步骤不是纹理补丁,而是对源和目标动画中每帧周围2 N + 1个连续骨架姿势的小子序列进行操作。搜索步骤在目标中的每个帧的源示例中找到最接近的匹配子序列,然后投票步骤平均所有相交子序列上的内容以获得最终帧姿势(参见Fig6)。
更正式地,在搜索步骤中,我们对于每个目标子序列![]() 找到最接近的源子序列
找到最接近的源子序列![]() ------使用Kovar等人的姿势相似性度量[2002](pose similarity metric),
------使用Kovar等人的姿势相似性度量[2002](pose similarity metric),其利用在去除全局平移之后由每个子序列中的相应骨架关节的轨迹形成的点云之间的距离之和(which exploits the sum of distances between point clouds formed by the trajectories of corresponding skeleton joints in each sub-sequence after removing global translation)
一旦我们找到了每个目标帧的最佳匹配源子序列,我们就会得到一组重叠的源子序列(见Fig6)。 此时,我们执行投票步骤以混合对应于每个输出目标帧的所有源帧(using the information encoded in the associated style-aware typles 使用在关联的样式感知元组中编码的信息)。 该步骤导致每个目标帧的混合样式感知元组![]() ,其使用N路ARAP插值获得[Baxter等人2009]粗糙部分变形
,其使用N路ARAP插值获得[Baxter等人2009]粗糙部分变形![]() 和残余形状变形
和残余形状变形![]() 的线性混合[Lee et al1998]和骨骼姿势差异
的线性混合[Lee et al1998]和骨骼姿势差异![]() 。 通过首先校正纹理
。 通过首先校正纹理![]() (即,去除
(即,去除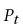 以及
以及![]() )然后线性地混合像素颜色来获得混合纹理
)然后线性地混合像素颜色来获得混合纹理![]() 。 最后,我们将得到的混合骨架姿势差
。 最后,我们将得到的混合骨架姿势差![]() 应用于目标骨架
应用于目标骨架![]() 以获得其风格化姿势(参见Fig7)。
以获得其风格化姿势(参见Fig7)。

Synthesis of Appearance. 一旦目标框架的风格化变形已知,转移风格化外观的直接方式将是使用![]() 上的新骨架关节位置使混合形状变形并相应地扭曲混合纹理信息( Once the stylized deformation of the target frame is known,a straight forward way to transfer the stylized appearance would be to deform the blended shapes using the new skeleton joint locations on T o (k) and warp the blended textural information accordingly)。然而,这种简单的解决方案会产生大量的伪影。线性混合通常会使原始手工彩色帧中的视觉细节平滑,这对于艺术品的风格至关重要(参见Fig8和补充视频进行比较)。这主要是由于各个混合帧的高频细节未完全对齐简单的平均化抑制了这些细节的表现。此外,在艺术家仅指定 样式样本帧中的遮挡层的形状 的情况下,风格化目标可以包括不包含纹理信息的区域,其也需要填充(in the case where the artist specifies only the shape of the occluded layers in the style exemplar frames, the stylized target may include regions that do not contain textural information, which need to be filled as well.)。最后,混合和弯曲通常不会产生表征许多手工彩色动画的相同类型的时间变化(即“沸腾”)。理想情况下,我们希望支持可控的时间闪烁,如[Fišer2014](Finally, blending and warping typically does not produce the same type of temporal variation(i.e.,"boiling") that characterizes many hand-colored animations. Indeally, we would like to support controllable temporal flickering as in [])。
上的新骨架关节位置使混合形状变形并相应地扭曲混合纹理信息( Once the stylized deformation of the target frame is known,a straight forward way to transfer the stylized appearance would be to deform the blended shapes using the new skeleton joint locations on T o (k) and warp the blended textural information accordingly)。然而,这种简单的解决方案会产生大量的伪影。线性混合通常会使原始手工彩色帧中的视觉细节平滑,这对于艺术品的风格至关重要(参见Fig8和补充视频进行比较)。这主要是由于各个混合帧的高频细节未完全对齐简单的平均化抑制了这些细节的表现。此外,在艺术家仅指定 样式样本帧中的遮挡层的形状 的情况下,风格化目标可以包括不包含纹理信息的区域,其也需要填充(in the case where the artist specifies only the shape of the occluded layers in the style exemplar frames, the stylized target may include regions that do not contain textural information, which need to be filled as well.)。最后,混合和弯曲通常不会产生表征许多手工彩色动画的相同类型的时间变化(即“沸腾”)。理想情况下,我们希望支持可控的时间闪烁,如[Fišer2014](Finally, blending and warping typically does not produce the same type of temporal variation(i.e.,"boiling") that characterizes many hand-colored animations. Indeally, we would like to support controllable temporal flickering as in [])。
为了缓解所有这些问题,我们用引导纹理合成代替图像变形[Fišer等人2017],它可以创建连贯,细致的纹理内容,并且可以灵活地填充新的可见区域。为了使这种技术正常工作,我们需要准备一组引导通道,这些引导通道定义来自源风格化框架的纹理应如何转移到变形的目标框架。

由于角色的各个部分的纹理通常是不同的,我们希望避免跨不同部分的纹理转移。为此,我们引入了基于分段的引导通道![]() ,其使用单独的颜色标签表示每个分段部分(参见Fig9)。既然分割也包含重要的语义细节,如眼睛,鼻子和嘴巴,
,其使用单独的颜色标签表示每个分段部分(参见Fig9)。既然分割也包含重要的语义细节,如眼睛,鼻子和嘴巴,![]() 确保这些细节将保留在适当的位置。
确保这些细节将保留在适当的位置。
此外,我们希望以可控的方式保持合成目标纹理中的时间连贯性。为此,我们引入了一个时间外观指南![]() ,它影响从一帧到下一帧合成纹理的一致性。我们将
,它影响从一帧到下一帧合成纹理的一致性。我们将![]() 定义为源帧的原始纹理
定义为源帧的原始纹理![]() ,以及目标帧的混合纹理
,以及目标帧的混合纹理![]() 。这些引导纹理中的细节通过限制一组匹配的示例性补丁来促进帧到帧的一致性(The details in these guiding textures encourage frame-to-frame consistency by restricting a set of matching exemplar patches.)。为了控制一致性,我们使用与[Fišer等人2017年,2014年]的方法类似的策略,我们平滑
。这些引导纹理中的细节通过限制一组匹配的示例性补丁来促进帧到帧的一致性(The details in these guiding textures encourage frame-to-frame consistency by restricting a set of matching exemplar patches.)。为了控制一致性,我们使用与[Fišer等人2017年,2014年]的方法类似的策略,我们平滑![]() 和
和 。然而,与Fišer等人相反。如果使用简单的高斯模糊,我们使用联合双边滤波器(joint bilateral filter)[Eisemann和Durand 2004]和联合域(joint domain)
。然而,与Fišer等人相反。如果使用简单的高斯模糊,我们使用联合双边滤波器(joint bilateral filter)[Eisemann和Durand 2004]和联合域(joint domain) ,即我们避免模糊部分边界,这样可以更好地保持各个部分的一致性。增加
,即我们避免模糊部分边界,这样可以更好地保持各个部分的一致性。增加![]() 中的模糊量减少了对合成的限制,从而增加了合成目标动画中的时间闪烁量(temporal flickering)。
中的模糊量减少了对合成的限制,从而增加了合成目标动画中的时间闪烁量(temporal flickering)。
为了生成源动画的指南,我们只需对于每个风格化的帧 渲染分割标签和纹理(具有指定的平滑量)。对于目标帧,我们将变形
渲染分割标签和纹理(具有指定的平滑量)。对于目标帧,我们将变形![]() 和
和![]() 应用于模板木偶
应用于模板木偶![]() ,并使用在运动风格化步骤中获得的骨架将木偶扭曲成风格化的姿势。然后,我们渲染
,并使用在运动风格化步骤中获得的骨架将木偶扭曲成风格化的姿势。然后,我们渲染![]() 的分割标签和
的分割标签和![]() 的平滑纹理
的平滑纹理 。最后,我们使用StyLit进行合成[Fišer等人 2016]生成最终的风格化目标框架(见Fig9)。
。最后,我们使用StyLit进行合成[Fišer等人 2016]生成最终的风格化目标框架(见Fig9)。

4、Result
我们使用C ++和CUDA的组合实现了我们的方法。我们在所有实验中设置N = 4。为了使用关节双边滤波器(joint bilateral filter)为外观指南![]() 平滑纹理,我们设置
平滑纹理,我们设置![]() 。对于外观转移,分割指南
。对于外观转移,分割指南![]() 具有权重2并且
具有权重2并且![]() 设置为1。我们之前发布的方法在我们的管道中使用,我们根据相应论文中的建议设置参数。
设置为1。我们之前发布的方法在我们的管道中使用,我们根据相应论文中的建议设置参数。
在四核CPU(Core i7,2.7 GHz,16 GB RAM)上,分析阶段(即注册)每帧平均需要15秒(ARAP注册为6秒,弹性注册为9秒)。合成新的目标动画帧每帧大约需要9秒(运动合成为1秒,外观传输为8秒)。外观传输使用CUDA在GPU(GeForce GTX 750 Ti)上并行化。而且,每个动画帧可以独立地合成,即,合成处理可以在簇上并行执行。
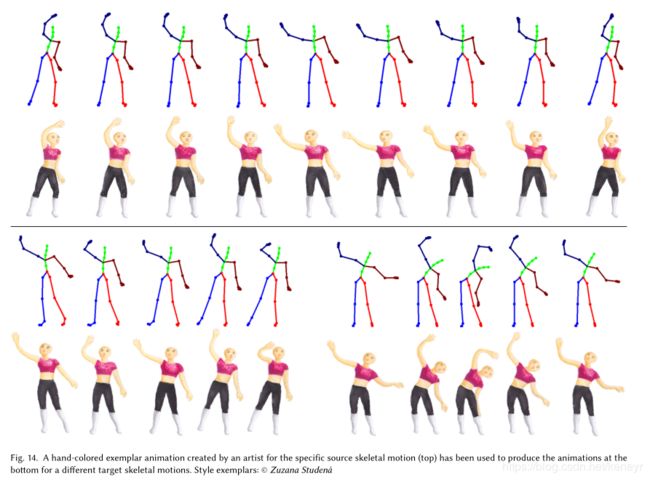
为了评估我们的方法的有效性,我们要求艺术家使用不同的艺术媒体(水彩画,水彩,水彩)从CMU动作捕捉数据库(步行,跑步,跳跃和窗户清洁)中选择不同的骨骼动作准备一套手绘样本。铅笔和粉笔,见Fig10和Fig14)。然后,我们从同一动作捕捉数据库中选择了一组目标序列,这些目标序列具有与源动画类似的整体运动类型,但具有不同的运动特色。例如,我们包括更慢,更快和“偷偷摸摸”的步行运动,以及结合跑步和跳跃运动的序列。我们还测试了源骨骼动画的慢动作版本,以证明我们的技术也可以用于中间。Fig1,11,13和14显示了我们某些结果的静态帧,可以在补充视频中找到更多的合成动画。
总的来说,结果表明我们的方法成功地从不同的源示例中捕获了外观和运动样式的重要方面。例如,外观合成保留了所使用的艺术媒体的重要特征,包括水彩风格的颜色变化,粉笔渲染中的高频纹理以及铅笔画中的精细阴影。这些特征在整个目标动画中持续存在,即使姿势与任何示例帧明显不同。
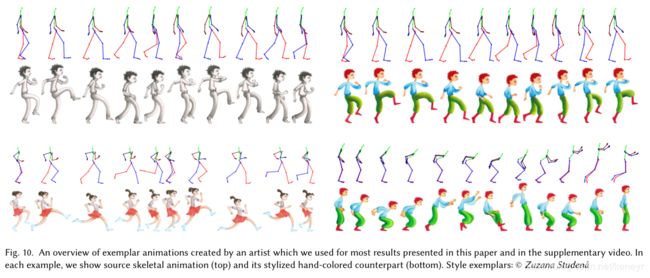


总的来说,结果表明我们的方法成功地从不同的源示例中捕获了外观和运动样式的重要方面。例如,外观合成保留了所使用的艺术媒体的重要特征,包括水彩风格的颜色变化,粉笔渲染中的高频纹理以及铅笔画中的精细阴影。这些特征在整个目标动画中持续存在,即使姿势与任何示例帧明显不同。艺术家还添加了几个动作风格,例如在行走动作中夸张的手臂摆动和膝盖提升,以及在跳跃和跑步动画中的次要效果(例如,挤压和拉伸)。我们的技术将这些特征转移到新的目标运动,例如,如Fig1所示。
我们的方法有几个组件,它们共同有助于最终合成动画的质量。为了演示这些组件的影响,我们生成了比较,我们在管道中添加关键步骤(ARAP变形,残余变形,用混合纹理替换静态纹理和外观合成),从一个简单的基于骨架的开始源木偶变形为基线。我们还通过修改指导纹理中的联合双边模糊的强度来生成具有不同时间相干量的结果。请参阅我们的补充视频以查看这些比较。
5、LIMITATIONS AND FUTURE WORK
我们的结果表明,所提出的方法可以有效地将一系列样式转换为新的目标运动。但是,现有技术确实存在一些局限性。
Motion constraints。我们方法的当前版本不对风格化的目标动作强制显式约束。结果,诸如脚滑或过度弯曲的关节之类的伪像是可能的(参见Fig12,左)。在应用每帧姿势变形 之后,通过调整风格化的目标骨架姿势来保持这种约束将是相对简单的扩展。
之后,通过调整风格化的目标骨架姿势来保持这种约束将是相对简单的扩展。
Sub-skeleton matching。当找到与给定目标子序列最接近的匹配源子序列时,我们当前将所有骨架关节合并到相似性度量中。未来工作的可能扩展将仅考虑部分匹配,例如,找到单独的子序列匹配骨架的上部和下部。这可以提供更大的灵活性,使现有的动画范例适应更多种类的目标运动。
Out-of-plane motions。使用我们的方法处理平面外运动存在两个挑战。首先,由于我们将3D骨架姿势投影到2D表示,因此平面外运动可能会在运动合成步骤的搜索阶段引入歧义(见Fig12,右)。例如,朝向相机旋转臂可以具有与远离相机旋转相似的2D投影,这使得难以自动选择用于合成的适当源子序列。为了解决这个问题,我们可以扩展我们的方法,在源序列和目标序列中使用3D骨架信息。第二个挑战涉及平面外运动,这些运动不能在分层部分(例如,旋转部分)上保持一致的深度顺序。处理此类动作是未来工作的一个有趣方向。
Reducing input requirements。我们的方法使艺术家能够利用相对较小的手工彩色框架来合成许多新的目标动作。但是,有机会进一步降低投入要求。例如,艺术家可以选择一些关键帧来提供手工彩色的例子,而不是对源骨骼运动的每一帧进行风格化。为了支持这种减少的输入,我们框架的分析阶段可能使用类似于我们当前用于生成风格化目标帧的引导合成方法来插入中间帧。此外,我们可以尝试增加现有的木偶注册方法,以避免需要每个风格化源框架的分段版本。
Inconsistent motion or skeletal structure。理论上,艺术家可以为输入序列提供任何姿势风格化(例如,将跳跃动作映射到步行序列或使用具有与原始骨架明显不同的结构的艺术品)。然而,在这种情况下,最接近的匹配通常是非常不同的,因此算法可以产生远离目标骨架姿势规定的预期形状的N路变形(例如,过度夸大的拉伸)。在这种情况下,艺术家可能需要提供捕捉所需姿势的附加风格化框架。

6、CONCLUSION
在本文中,我们介绍了ToonSynth,一种用于合成目标骨骼运动的手绘卡通动画的新方法。 我们的方法利用艺术家创建的关于源骨骼运动的示例。 我们创造了一种风格感知的木偶,将艺术家特有的风格编码为骨架姿势,尽可能粗糙的扭曲,精细的弹性变形和纹理。 使用这种表示,我们可以通过生成捕获基本运动属性的引导通道以及提供对时间动态量的控制来将样式转移到许多新运动,并且使用基于引导补丁的合成来产生最终外观。 这种方法使我们能够提供手工彩色动画的外观和感觉,每个帧都是从头开始绘制的。
-------------------------------------------------------------------End-------------------------------------------------