偏差与方差
当讨论线性回归时,我们提到过欠拟合和过拟合的问题。如下图所示,左图用的是y=θ0+θ1x的线性模型进行拟合,而右图用了更为复杂的多项式模型y=θ0+θ1x+...+θ5x5进行拟合。
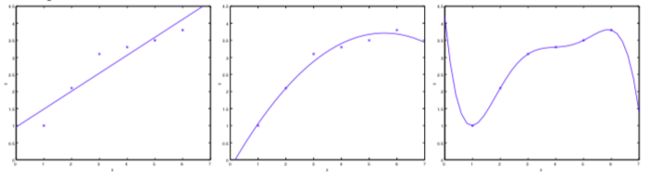
使用五阶多项式模型进行拟合并不会得到一个很好的模型,因为即使在训练集上表现很好,我们不能保证在新的数据集上也能做出很好的预测。换句话说,从已知的训练集中学习的经验并不能推广到新数据集上,由此产生的误差就叫做这个假设函数的泛化误差(generalization error)。稍后我们会给出泛化误差更正式的定义。
上图最左边和最右边的两个图形都有很大的泛化误差,但这两种误差不太相同。左图的模型过于简单,无法准确描述训练集的数据,这种误差我们称为偏差(bias),我们称这个模型是欠拟合(underfit)的。右图的模型过于复杂,对训练集的数据过于敏感,这种误差我们称为方差(variance),我们称这个模型是过拟合(overfit)的。
通常我们需要在偏差和方差中进行权衡。如果我们的模型过于简单,并且参数较少,那么这个模型通常会有较大的偏差,但是方差较小。相反如果我们的模型过于复杂,并且参数较多,那么这个模型通常会有较大的方差,但是偏差较小。在上面这个例子里,使用二阶函数进行拟合效果最好,在偏差和方差中获得了较好的权衡。
经验风险最小化
这一节我们正式给出泛化误差的定义以及如何在偏差和方差中进行权衡。在此之前,我们先介绍两个简单但很有用的引理。
联合边界(The union bound)引理:令A1, A2, ..., Ak为k个不同的随机事件,那么:
在概率论里,联合边界通常被作为一个公理,因此也无需被证明,我们可以在直观上理解:k个随机事件中任何一个事件发生的概率至多是k个随机事件出现的概率总和。
Hoeffding不等式(Hoeffding inequality)引理:令Z1, Z2, ..., Zm为m个服从伯努利分布B(φ)的独立同分布事件,即P(Zi = 1) = φ,P(Zi = 0) = 1 - φ,令φ^=(1/m)Σi∈[1,m]Zi为这些随机变量的平均值,对于任意的γ > 0,有:
这个引理告诉我们,如果用m次随机变量的平均值φ^作为对φ的估计,那么m越大,两者的误差就越小。这个引理和我们在概率论中学习的大数定理是符合的。
基于上面两个引理,我们可以推导出学习理论中最重要的一些结论。
为了方便讨论,我们将问题限制在二元分类问题上,推导出的结论同样也适用于其他分类问题。
假设我们有一个个数为m的训练集S = {(x(i), y(i)); i = 1, ..., m},训练集的每个数据(x(i), y(i))都是服从概率分布为D的独立同分布。对于某个假设函数h,定义其训练误差(training error),或者说经验风险(empirical risk)为:
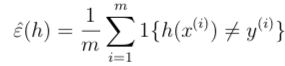
训练误差描述的是假设函数h误判结果的比例。
另外,我们定义泛化误差(generalization error)为:
泛化误差描述的是假设函数h误判结果的概率。
考虑线性回归的例子,令假设函数hθ(x) = 1{θTx >= 0},那么我们如何选取参数θ使得假设函数最优呢?一个方法就是使经验风险最小,即选取:
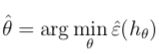
我们把这个方法称为经验风险最小化(empirical risk minimization(ERM)),并把通过ERM产生的最优假设函数记为h^。
为了便于讨论,我们抛弃掉假设函数的参数化过程。定义假设函数类(hypothesis class)H是所有可能的假设函数的集合。比如对于线性分类,H就是:
现在ERM可以表示成如下的最优化问题:
有限假设空间
首先我们考虑假设空间有限的情况,即H = {h1, ..., hk},H里包含k个假设函数,我们需要从k个假设函数中挑选出经验风险最小的那个函数。
我们的证明分两部分。首先证明可以用泛化误差来近似替代训练误差,其次证明泛化误差是有上边界的。
对于某个假设函数hi ∈ H,考虑一个概率分布为D的伯努利分布随机事件Z = 1{hi(x) != y},Z的泛化误差是其分布的期望值,而Z的训练误差是所有事件的平均值,即:

根据Hoeffding不等式,可以得到:
这就证明了对于某个假设函数hi,只要m越大,泛化误差就越接近训练误差。接下来我们还要证明,对所有的假设函数h ∈ H,上述特性都成立。令事件Ai为|ε(hi) - ε(h^i)| > γ,我们已经证明了P(Ai) <= 2exp(-2γ2m)。根据联合边界引理,我们可以得到:

如果我们把两边同时减去1,可以得到:

也就是说,对所有的h ∈ H,泛化误差与训练误差相差γ的概率至少是1 - 2kexp(-2γ2m),这个结论也被称为一致收敛(uniform convergence)。因此当m足够大时,我们可以用泛化误差来估计训练误差。
在刚才的讨论中,我们固定参数m和γ,给出P(|ε(hi) - ε(h^i)| > γ)的边界。这里我们感兴趣的是三个变量,m,γ以及一个误差的概率(后面用δ表示)。我们可以固定其中两个变量来求解另一个变量的边界。
如果给定γ和δ > 0,m需要取多大来保证上式成立?用δ = 2kexp(-2γ2m)代入求解,可得:

这个式子告诉我们为了满足误差的概率成立,m需要达到的最小值,此时m也被称为样本的复杂度(sample complexity)。这个式子也告诉我们,为了满足条件,m只和k成对数相关(logarithmic)。
类似的,固定m和δ来求解γ,我们可得:

下面我们来证明泛化误差是有上边界的。定义h* = arg minh∈Hε(h)是假设空间H里的最优假设函数。对于H里的任意假设函数h^,我们有:
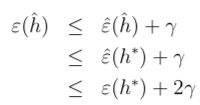
上式中的第一步和第三步都是利用了一致收敛的结论,因此我们证明了某个假设函数h的泛化误差比最优假设函数的泛化函数最多相差2γ。
将前面几个结论整合到一起可以形成如下定理:
令|H| = k,对于任意的固定参数m和δ,如果泛化误差与训练误差一致收敛的概率至少为1 - δ,那么有:
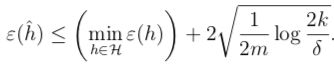
这个式子可以用来量化我们之前讨论的偏差方差权衡问题。当我们选择一个更大的假设空间时,等式右边第一项将会变小(因为有可能寻找到更优的假设函数),而等式右边第二项将会变大(因为k增大了),因而我们可以将第一项看成偏差,第二项看成方差。
这个定理还有一个推论:
令|H| = k,对于任意的固定参数γ和δ,为了使ε(h^) <= arg minh∈Hε(h) + 2γ的概率至少为1 - δ,那么m需满足:

无限假设空间
我们已经在有限假设空间的情况下证明了一些有用的定理了,那么在无限假设空间中是否有相似的定理呢?
在给出结论前,我们需要先介绍VC维的知识。
给定一个数据集S = {x(1), ... x(d)},数据集的每个点x(i) ∈ X,如果H可以对S进行任意标记(H can realize any labeling on S),那么我们称H可以打散(shatter)S。也就是说,对任意标记 {y(1), ... y(d)},都存在h ∈ H使得h(x(i)) = y(i), i = 1, ..., d。
给定一个假设空间类H,我们定义H的VC维(Vapnik-Chervonenkis dimension),记为VC(H),是H可以打散的最大样本集合个数。如果H可以打散任意大的样本集合,那么VC(H) = ∞。
举例来说,考虑如下三个点的样本集合:

如果H为二维线性分类器的集合,即h(x) = 1{θ0 + θ1x1 + θ2x2 >= 0},那么H是可以打散这个集合的。具体来说对于如下八种可能的情况,都可以找到一个“零训练误差”的线性分类器,如下图所示:
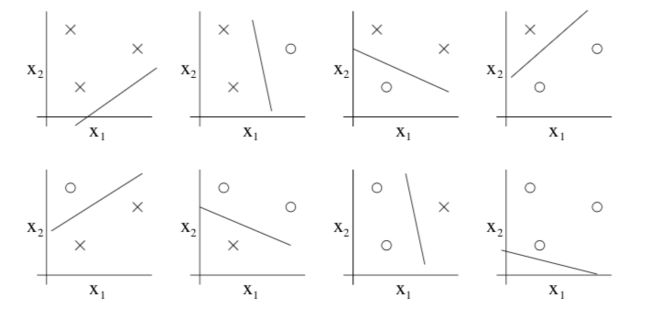
可以证明上述假设空间类H不能打散包含4个点的样本集合,因此H最多能打散的集合大小是3,即VC(H) = 3。
需要说明的是,如果这些点的排列方式在一条直线上,那么H是无法打散S的。这种情况如下图所示:
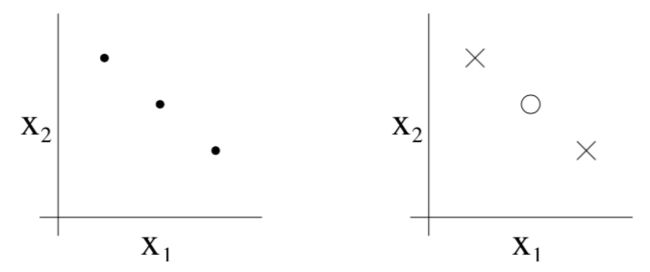
因此我们说VC(H) = d,只需证明H可以打散大小为d的某一个集合S即可。
介绍完VC维后,我们可以给出如下定理:
给定一个假设空间类H,令d = VC(H),如果一致收敛的概率至少为1 - δ,那么对任意的h ∈ H,有:
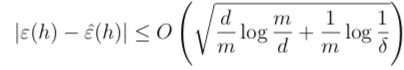
也就有:
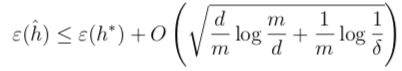
这就证明了,如果H的VC维是有限的,那么一致收敛就是有效的,只要m越大,泛化误差与训练误差越接近。
这个定理同样还有一个推论:
对所有的h∈H,为了使ε(h^) <= arg minh∈Hε(h) + 2γ的概率至少为1 - δ,那么m需满足:m = Oγ,δ(d)
这个推论告诉我们,训练集的数据大小与H的VC维成正比。而对大多数假设函数类,VC维的大小近似与参数的个数成正比。将上述两个结论结合起来,我们可以得出:训练集的数据大小通常近似与参数的个数成正比。
总结
- 如果模型比较简单并且参数比较少,那么这个模型通常会有较大的偏差和较小的方差;如果模型比较复杂并且参数比较多,那么这个模型通常会有较大的方差和较小的偏差
- 训练误差描述了假设函数误判结果的比例,泛化误差描述了假设函数误判结果的概率;当数据集足够大时,可以用泛化误差来估计训练误差
- 在假设空间里选择一个使训练误差最小的假设函数,这个过程叫做经验风险最小化(ERM)
- 如果假设空间有限,样本复杂度与假设空间大小的对数成正比(m = Oγ,δ(log k));如果假设空间无限,样本复杂度与假设空间的VC维成正比(m = Oγ,δ(d))
参考资料
- 斯坦福大学机器学习课CS229讲义 pdf
- 网易公开课:机器学习课程 双语字幕视频