oracle 5种b*树索引扫描方式
Index scan(索引扫描index lookup):
我们通常说的一般索引都是B树索引(平衡树),有以下特性
1 叶子节点关键字为数据库值和ROWID,兄弟节点间链指针相连(字节点满了,则向父节点申请空间,一直叠加)
2 根/分支节点关键字存储键值范围(数据库值范围),分支节点兄弟节点间链指针相连,父子节点链指针相连
根据索引类型与where限制条件的不同,有5种类型的索引扫描:
3.1 Index unique scan(索引唯一扫描):
存在unique或者primary key的情况下,返回单个rowid数据内容。
验证:
step1
create table t_index1 as
select rownum as rn1,rownum as rn2,trunc(dbms_random.value*1000000) as rn3 from dual connect by rownum<1000000;
alter table t_index1 add constraint c_pk1 primary key(rn1);
create index indx_t_1 on t_index1(rn2);
step2
主键执行
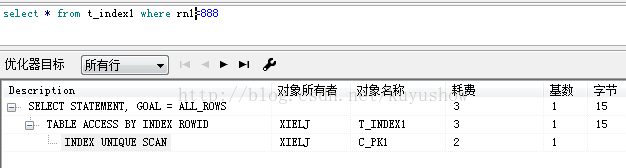
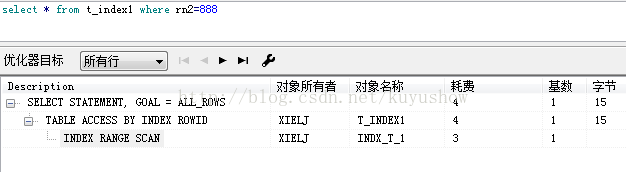
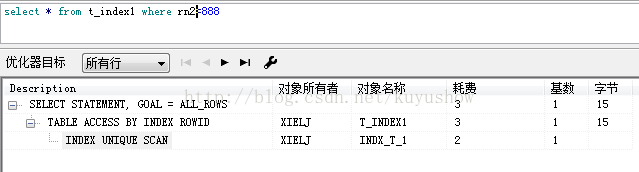
添加唯一约束
drop index indx_t_1
create unique index indx_t_1 on t_index1(rn2);
3.2 Index range scan(索引范围扫描):
1,在唯一索引上使用了range操作符(>,<,<>,>=,<=,between);

2,在组合索引上,只使用部分列进行查询(部分即不唯一);
create index indx_t_2 on t_index1(rn1,rn2);
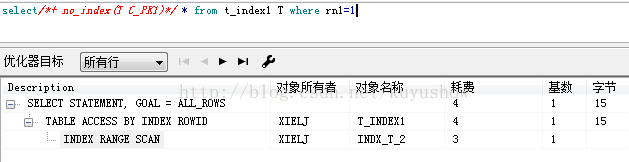
3,对非唯一索引上的列进行的查询。
如上的一般索引执行
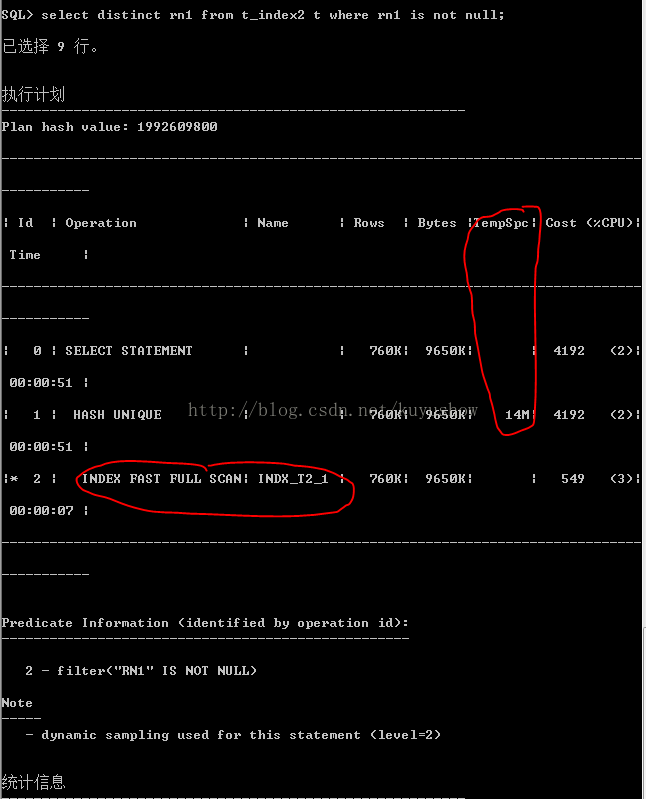
3.3 Index full scan(索引全扫描)(相对于INDEX_FFS,INDEX_FS会消除排序,但是为了保证顺序,所以一次只能读取索引块,其会消除排序,但是会增加单块读的开销)
需要查询的数据从索引中可以全部得到,且需要排序的数据
create table t_index2 as
select mod(rownum,9) as rn1,rownum as rn2,trunc(dbms_random.value*1000000) as rn3 from dual connect by rownum<1000000;
create index indx_t2_1 on t_index2(rn1);
set autotrace traceonly;
未消除排序(单块读的成本大于排序导致的成本,CBO选择INDEX_FFS)
消除排序
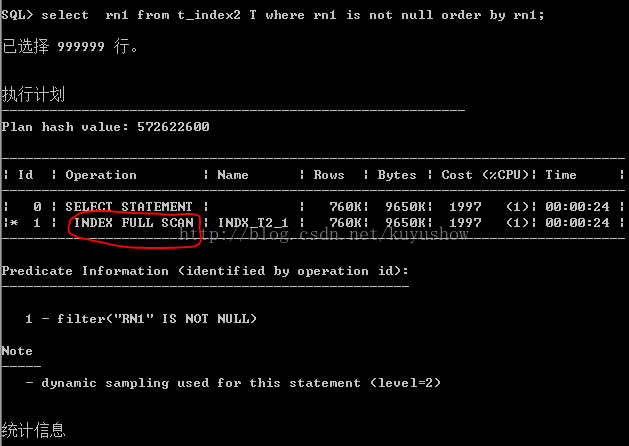
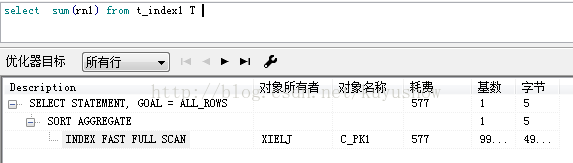
3.4 Index fast full scan(索引快速扫描):(能够按照物理块顺序来读取索引段,并使用多块读取)
与index full scan类似,但是这种方式下不对结果进行排序。
3.5 index skip scan
1.索引跳跃式扫描适合于组合索引,比如(gender,age)
2.当根据组合索引的第一个列gender(leading 列)做查询时,通常是可以用的到索引的
3.当你想使用第二个列age作为筛选条件时,oracle可以使用索引跳跃式扫描
4.跳跃式扫描适合于第一个列值重复比较多,第二个列唯一值比较多的情况
5.当组合索引多列时,一般要有2列或者多列非组合索引列联合查找才会用到index_ss,并且每个单独列的cost一样多。(实验如此,不敢打包票)
--捣鼓的sql
create table t_index1 as
select rownum as rn1,rownum as rn2,trunc(dbms_random.value*1000000) as rn3 from dual connect by rownum<1000000;
alter table t_index1 add constraint c_pk1 primary key(rn1);
drop index indx_t_1
create unique index indx_t_1 on t_index1(rn2);
--alter table t_index1 add constraint c_check check(rn2 <1000000);
--alter table t_index1 drop constraint c_uniq
alter table t_index1 add constraint c_uniq unique (rn2);
drop index indx_t_1
alter table t_index1 modify rn2 not null;