tflite 源码解读
以下为鄙人读源码时做的一些粗略记录,如有不当望请多多指教(抱拳)
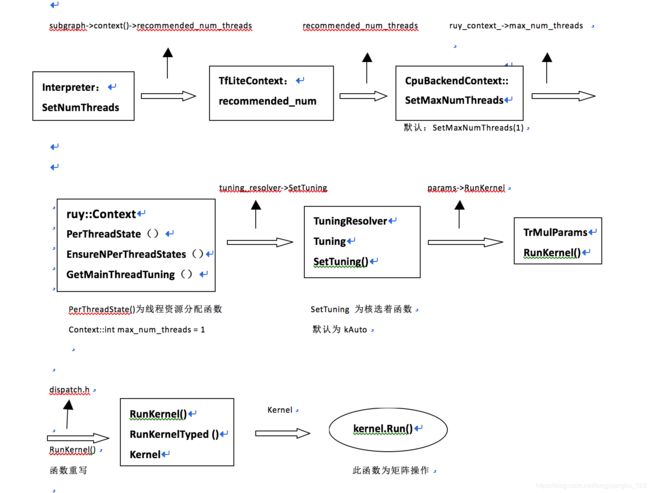
一、源码解读(主要为多线程执行过程)。从C++ 模型声明tflite::Interpreter类型做入口
1、tensorflow\lite\interpreter.cc
void Interpreter::SetNumThreads(int num_threads) {
for (auto& subgraph : subgraphs_) {
subgraph->context()->recommended_num_threads = num_threads;
}
for (int i = 0; i < kTfLiteMaxExternalContexts; ++i) {
auto* c = external_contexts_[i];
if (c && c->Refresh) {
c->Refresh(context_);
}
}
}
(a)、void SetNumThreads(int num_threads) ; 线程数设置 最新github上改了函数名字,改成void cpus(int num_threads);
(b)、顺着函数里面subgraph找到, tensorflow\lite\core\subgraph.h 里面的class Subgraph{} 以及里面的成员TfLiteContext* context()。
(c)、TfLiteContext 在tensorflow\lite\c\c_api_internal.h 里面定义typedef struct TfLiteContext {} 以及成员变量recommended_num_threads 。
2、根据recommended_num_threads 找到tensorflow\lite\kernels\cpu_backend_context.cc
CpuBackendContext* CpuBackendContext::GetFromContext(TfLiteContext* context) {
auto* external_context = static_cast(
context->GetExternalContext(context, kTfLiteCpuBackendContext));
if (external_context == nullptr) {
TF_LITE_FATAL(
"ExternalCpuBackendContext isn't properly initialized during TFLite "
"interpreter initialization.");
}
auto* cpu_backend_context = static_cast(
external_context->internal_backend_context());
if (cpu_backend_context == nullptr) {
// We do the lazy initialization here for the TfLiteInternalBackendContext
// that's wrapped inside ExternalCpuBackendContext.
cpu_backend_context = new CpuBackendContext();
if (context->recommended_num_threads != -1) {
cpu_backend_context->SetMaxNumThreads(context->recommended_num_threads);
}
external_context->set_internal_backend_context(
std::unique_ptr(cpu_backend_context));
}
return cpu_backend_context;
}
(a)、函数里面重要的代码。CPU设置的最大线程数,cpu_backend_context->SetMaxNumThreads(context->recommended_num_threads) 。
(b)、cpu_backend_context.cc 文件里面还有另外一个函数,CpuBackendContext::CpuBackendContext() 里面设置SetMaxNumThreads(1); 说明,lite里面默认线程数为1.
(c)、此文件里面还有最后一个设置函数线程的函数,void CpuBackendContext::SetMaxNumThreads(int max_num_threads) {….},里面有个ruy_context_->max_num_threads = max_num_threads,顺着这个找下去,能找到ruy::Context
3、根据2的ruy:Context 定位到tensorflow\lite\experimental\ruy\context.h。此文件较多注释,可详细看注释。
/ The state private to each Ruy thread.
struct PerThreadState {
// Each thread may be running on a different microarchitecture. For example,
// some threads may be on big cores, while others are on little cores. Thus,
// it's best for the tuning to be per-thread.
TuningResolver tuning_resolver;
// Each thread has its own local allocator.
Allocator allocator;
};
……….
……….
……….
void EnsureNPerThreadStates(int thread_count) {
while (per_thread_states.size() < static_cast(thread_count)) {
per_thread_states.emplace_back(new PerThreadState);
}
}
Tuning GetMainThreadTuning() {
EnsureNPerThreadStates(1);
TuningResolver* tuning_resolver = &per_thread_states[0]->tuning_resolver;
tuning_resolver->SetTuning(explicit_tuning);
return tuning_resolver->Resolve();
}
(a)、里面定义了关于线程的两个重要函数void EnsureNPerThreadStates(int thread_count) {…}和 Tuning GetMainThreadTuning() { …} 。
(b)、EnsureNPerThreadStates () 函数里面有个PerThreadState 结构体,(通过注释可明显知道,此处为线程分配的地方)
(c)、Struct Context final{…}里面有个 int max_num_threads = 1; 再次确定CPU线程分配默认为1。
4、查找3里面的线程分配结构体里面的TuningResolver ,找到定义处: tensorflow\lite\experimental\ruy\tune.h
enum class Tuning {
// kAuto means please use auto-detection. It's the default in the
// user-visible parts (see Context). It's meant to be resolved to an
// actual tuning at some point by means of TuningResolver.
kAuto,
// Target an out-order CPU. Example: ARM Cortex-A75.
kOutOfOrder,
// Target an in-order CPU. Example: ARM Cortex-A55.
kInOrder
};
// Why a TuningResolver class?
//
// Ideally, this Library would offer a single function,
// Tuning GetCurrentCPUTuning();
//
// However, determining information about the current CPU is not necessarily,
// cheap, so we currently cache that and only invalidate/reevaluate after
// a fixed amount of time. This need to store state is why this library
// has to expose a class, TuningResolver, not just a function.
class TuningResolver {
public:
TuningResolver();
// Allows the user to specify an explicit Tuning value, bypassing auto
// detection; or to specify Tuning::kAuto, reverting to auto detection.
void SetTuning(Tuning tuning) { unresolved_tuning_ = tuning; }
(a)、此文件有较多注释,可详细看注释,从注释里面可知道SetTuning 是设置CPU类型的地方,默认为KAuto,自动识别硬件类型。
5、根据SetTuning 函数调用情况,定位到tensorflow\lite\experimental\ruy\trmul.cc 文件
a) SetTuning所在函数存在一个 params->RunKernel(tuning, origin, rounded_dims); params 被TrMulParams定义。
6、找到TrMulParams定义文件, tensorflow\lite\experimental\ruy\trmul_params.h
a) 此文件定义了一个TrMulParams结构体,结构体里面定义了一个RunKernel()函数
7、根据RunKernel()函数,找到tensorflow\lite\experimental\ruy\kernel_common.h。
void RunKernelTyped(Tuning tuning, const PackedMatrix& lhs,
const PackedMatrix& rhs, const Spec& spec,
int start_row, int start_col, int end_row, int end_col,
Matrix* dst) {
using Kernel = Kernel;
Kernel kernel(tuning);
using LhsLayout = typename Kernel::LhsLayout;
using RhsLayout = typename Kernel::RhsLayout;
// end_row and end_col may be larger than dst dimensions.
// that is because kernels write directly to the destination matrix, whose
// dimensions may not be a multiple of the kernel dimensions, and we try to
// keep this annoyance localized as an implementation detail in kernels,
// by allowing to pass rounded-up values down as far as possible.
// These assertions encode the contract.
RUY_DCHECK_LE(0, start_row);
RUY_DCHECK_LE(start_row, end_row);
RUY_DCHECK_LT(end_row, dst->layout.rows + LhsLayout::kCols);
RUY_DCHECK_EQ((end_row - start_row) % LhsLayout::kCols, 0);
RUY_DCHECK_LE(0, start_col);
RUY_DCHECK_LE(start_col, end_col);
RUY_DCHECK_LT(end_col, dst->layout.cols + RhsLayout::kCols);
RUY_DCHECK_EQ((end_col - start_col) % RhsLayout::kCols, 0);
#if RUY_OPT_ENABLED(RUY_OPT_FAT_KERNEL)
kernel.Run(lhs, rhs, spec, start_row, start_col, end_row, end_col, dst);
#else
for (int col = start_col; col < end_col; col += RhsLayout::kCols) {
int block_end_col = std::min(col + RhsLayout::kCols, end_col);
for (int row = start_row; row < end_row; row += LhsLayout::kCols) {
int block_end_row = std::min(row + LhsLayout::kCols, end_row);
kernel.Run(lhs, rhs, spec, row, col, block_end_row, block_end_col, dst);
}
}
#endif
}
(a)、此文件里面有个RunKernel()重写函数,与6里面的TrMulParams里面的RunKernel()函数关系在tensorflow\lite\experimental\ruy\dispatch.h文件里面有说明。
(b)、RunKernel()函数里面有个RunKernelTyped ()函数,此函数里面执行了最终的kernel.Run()函数,但此函数里面并为提及相关CPU信息,是一些矩阵操作。唯一涉及到的就是Turnning tuning。但默认tuning是KAuto即自动检测核类型。
二、多线程执行示意图
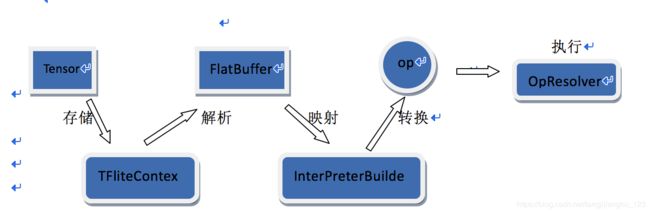
三、模型执行过程