数据库中的无损连接分解和是否保持函数依赖的判定
首先了解一下几个概念:
1)把一个关系模式分解成若干个关系模式的过程,称为关系模式的分解。
2)把低一级的关系模式分解为若干个高一级的关系模式的方法不是唯一的。
3)只有能够保证分解后的关系模式与原关系模式等价,分解方法才有意义。
对于第一句话,为什么需要分解关系模式?因为原来的关系模式可能造成数据冗余或
给数据库带来潜在的不一致性。对于第二句话,根据不同语义,分解的原则也不尽相
同,所以方法肯定是不唯一的,譬如U={A,B,C},根据不同原则(随便你自己定),
可能分成(A,B)(A,C)也可能分成(B,C)(A,C)。对于第三句话,则是本文所要
讲的内容。
为了保证分解后的关系模式与原关系模式等价,我们要判定 1)分解后形成的行的关
系模式中是否为无损连接 2)是否保持函数依赖
一、无损连接的判定:
1)如果分解后的的关系模式是形如{U1,U2}这,里面只有两个,那很好做,就判断
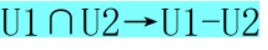 或
或 ![]() 是否成立,成立的话肯定是
是否成立,成立的话肯定是
无损连接。
2)如果是两个以上{U1,U2,U3....}这种,那就比较麻烦了,比如,有属性集,
ABCDEF,存在这样的函数依赖集{A->BC , CD->E , B->D , BE->F , EF->A},然后有
这样的分解{ABC , BD , BEF}。
例如:
设U1=ABC,U2=BD,U3=BEF,根据提供的函数依赖集,我们可得U1存在这样的
函数依赖A->BC,U2上的函数依赖是 B->D, U3的函数依赖是BE->F。
1)于是可构造这样的表格。
| G | A | B | C | D | E | F |
| A->BC | ||||||
| B->D | ||||||
| BE->F |
2)各自判断A,B,C,D,E,F是否有在G列的函数依赖中,如果有记为ai,i表示第几列,否
则记为bji,表示第j行第i列
如:
| G | A | B | C | D | E | F |
| A->BC | a1(A有在函数依赖中,此行为第一行) | |||||
| B->D | ||||||
| BE->F | b31(A没有,此列为第一列) |
这样我们可得到图:
| G | A | B | C | D | E | F |
| A->BC | a1 | a2 | a3 | b14 | b15 | b16 |
| B->D | b21 | a2 | b23 | a4 | b25 | b26 |
| BE->F | b31 | a2 | b33 | b34 | a5 | a6 |
3)接下来是关键的,如果我们经过一系列变换得到有一行是这样的排序
{a1,a2,a3,a4,a5,a6...},即不存在bji,那我们就认为,该分解是无损连接。
4)变换过程:为了方便,我们可以按A->BC, B->D,BE->F这个顺序来(随你喜
欢)。
第一遍,根据A->BC,我们知道主健是能唯一标识一个元组的,也就是说如果
A中存在着两个属性值是相同的,毫无疑问,他们推出的BC的值肯定也是相同的。从
表格中我们遍历A列,没有发现有相同的属性组,那就跳过。
第二遍, 根据B->D,因为B列属性值相同,那我们修改D列。修改时遵照这样的一个
规则,如果D中有ai这样的值,那么宣布修改为ai,如果没有,修改成该列的第一行的
第一个值。从表格中我们可以发现D中有a4,那么修改后变成:
| G | A | B | C | D | E | F |
| A->BC | a1 | a2 | a3 | a4 | b15 | b16 |
| B->D | b21 | a2 | b23 | a4 | b25 | b26 |
| BE->F | b31 | a2 | b33 | a4 | a5 | a6 |
第三遍,根据BE->F,找一组BE相同的值,发现不存在,即不存在类似
{a1,a2,a3,a4,a5,a6}这样的序列,即该分解不是无损连接分解。
二、是否保持函数依赖?
这个的判断方法就比较简单了,还是这道题,有属性集,ABCDEF,存在这样
的函数依赖集{A->BC , CD->E , B->D , BE->F , EF->A},然后有这样的分解
{ABC , BD , BEF}。
设U1=ABC,A->BC,U2=BD,B->D ,U3=BEF,BE->F ,即我们不能推出 CD->E
,EF->A,所以也不具有保持函数依赖的特性。