一种SDN路由转发流表实现方法
1. 背景与需求
1.1 背景
传统上,路由器采用Radix树进行IP路由存储,但是到了SDN中,流表的key不一定是IP地址,所以就需要对路由表的存储更换一种算法,可以达到快速增、删、改、查的效果。由于KEY的类型不确定,设置无法比较大小,所以Hash表是一种不错的选择。
一般的HASH表都是通过数组(哈希桶)和链表的组合而成,如下图所示。数据元素的key通过给定的hash算法计算出所在数组的索引号,然后再将数据元素插入对应的链中。这种HASH表的特点是结构简单,便于管理,但是由于链表是顺序访问且节点是临时分配,无法达到路由表的使用性能,所以就需要一种增强型路由表来用于路由器的流表管理。同时,软路由类型的路由器一般都是基于多核进行开发的,所以路由表需要在多核间进行共享,并且同时需要保证路由表在多核间的一致性。这种增强型的HASH表叫做EHASH(Enhanced Hash Table)
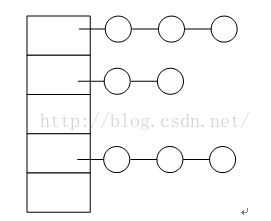
图 1 传统HASH表
1.2需求
EHASH路由流表需求如下:
a. 可以快速分配出路由元素
b. 在冲突链上快速查找
c. 可以对HASH进行统计计数
d. 多个转发核间共享路由流表数据
e. 多个转发核间以最高速度进行互斥访问
1.3设计思路
目前SDN路由器采用虚拟化的方案,会有多台负责数据转发的虚拟机,每个虚拟机中都会有一个或多个转发核。为了在所有的转发核间共享路由转发流表,需要在Hypervisor层上管理一个很大的内存,这块内存可以在各个虚拟机中访问到。具体Hypervisor的内存管理方式不是本文描述的重点,只要知道路由转发流表所用的内存都是从这块共享内存中分配出来的即可。
为了满足快速查找需求,采用HASH作为主体算法,通过HASH来进行快速查找;为了满足快速分配和快速访问的需求,这里采用利用数组预分配表项资源,通过数组索引来快速的访问内存,因为是预分配所以需要提前消耗比较大的共享内存,是一种典型的空间换时间的算法。
EHASH的算法结构如下图所示:
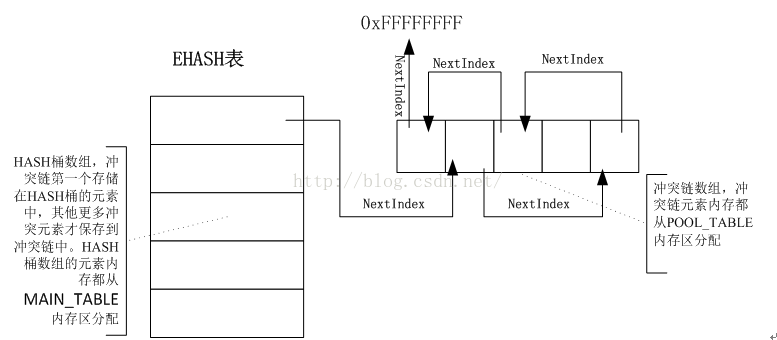
图 2 EHASH算法结构
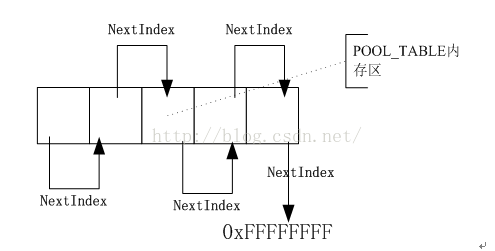
图 3 Pool区域初始化为数组链表
HASH桶数组用来完成HASH,经过HASH函数计算后的key就是HASH桶数组的索引。HASH桶数组元素就是冲突链的表头。通过NextIndex指向该HASH值的冲突链。如果NextIndex为全F,那么就表示该HASH值对应的HASH元素上没有冲突链。HASH桶数组叫做主表,即MainTable,其中的数组元素都从MAIN_TABLE内存区分配出来。
如上面图所示,Pool内存区会整个初始化为一个大数组,通过NextIndex会将这个大数组连接为一个大的链表。NextIndex存储的内容是一个元素在POOL_TABLE内存区数组中的索引下标。所有的冲突链上的元素都是从POOL_TABLE内存区上分配出来,当冲突节点被释放收,会修改释放节点的NextIndex,使其连接到Pool内存数组的下一个空闲元素上。
当多个插入的数据对应了同一个HASH KEY的时候,就会在同一个HASH KEY上形成冲突链。冲突链叫做PoolTable,所有的冲突链上的元素都是从POOL_TABLE内存区上分配出来。冲突链的第一个数据存储在HASH桶数组元素中,然后通过NextIndex指向冲突链的下一个元素;同理,下一个元素通过NextIndex指向再下一个冲突链元素,如此类推,直到最后一个冲突链元素,最后一个冲突链元素的NextIndex为0xFFFFFFFF,表示链表没有更多的元素了。通过NextIndex指向下一个元素在Pool内存数组中的索引下标,将预分配好的离散的数组元素组合成为一个链表。
为了满足多转发核间对路由表的互斥访问,所以需要通过锁来进行保护。同时因为路由流表的读操作多余写操作,所以通过读写锁对内存进行保护。如前文所述,目前采用虚拟化方案,会存取多个OS,所以锁使用内存也是在Hypervisor维护的共享内存上。这样所有的虚拟机都可以正常访问到所,以便互斥地访问路由流表资源。
同时对EHASH增加了统计表,如下图所示。统计表同HASH桶的元素一一对应,也就是说和HASH桶的大小相同。统计表中的每个元素记录了冲突链上冲突元素的数量,以及历史上该HASH KEY冲突的最大数量。通过观察统计数量,可以发现冲突最多的HASH KEY,从而调整HASH KEY的算法,使其对数据散列的更加平衡。
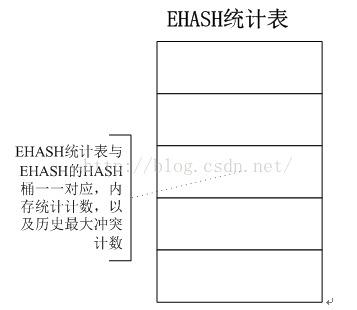
图 4 EHASH统计表
2. 主要数据结构
2.1共享内存布局
如前文所述,目前采用虚拟化方案,会存取多个负责转发的虚拟机,为了让多个虚拟机之间共享路由转发流表等信息,需要在Hypervisor层上管理一块内存,这块内存可以在各个虚拟机中访问到。共享内存布局如下所示

图 5 共享内存布局
- MAIN_TABLE 内存区:EHASH的HASH桶的元素的内存。Addr为内存区其实地址,Len为内存区长度。
- POOL_TABLE 内存区:EHASH的冲突链元素的内存。Addr为内存区其实地址,Len为内存区长度。
- STATISTICS_TABLE 内存区:EHASH统计表元素的内存。Addr为内存区其实地址,Len为内存区长度。
- SPINLOCK_TABLE 内存区:EHASH表自旋锁内存。Addr为内存区其实地址,Len为内存区长度。
- WRLOCK_TABLE 内存区: EHASH表读写锁内存。Addr为内存区其实地址,Len为内存区长度。
每个内存区都被视为是数组,而且内存区是相邻的,所以通过数组元素的地址,可以元素下标索引值,也可以通过元素下标索引值计算出元素对应的地址。数组元素索引和元素地址转换通过如下两个宏可以完成:
- EHASH_NODE_ENTRY:通过内存区基地址和元素索引,计算得到元素的地址;
- EHASH_NODE_INDEX: 通过内存区基地址和元素地址,计算得到元素在数组中的索引下标
相关代码如下:
#define EHASH_NODE_ENTRY(base,index,entrysize,type) \
(((index) == EHASH_INDEX_INVALID) ? NULL :((type *)((u32)(base) + (index) * (entrysize))))
/*得到指定为值off处元素的Index值*/
#define EHASH_NODE_INDEX(base,off,entrysize) \
(((u32)(off) -(u32)(base))/(entrysize))
2.2EHASH管理结构
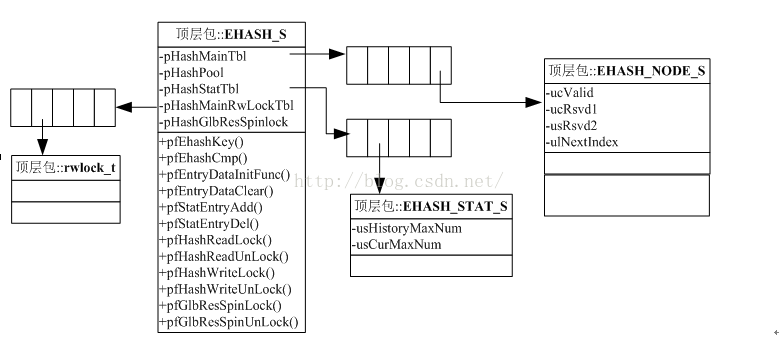
图 6 EHASH关键管理结构
EHASH_S结构是EHASH表的表管理结构,主要成员如下:
- pHashMainTbl:指向MAIN_TABLE内存区,将该内存区视为数组,每个数组元素为HASH表的节点数据。
- pHashPool: 指向POOL_TABLE内存区,将该内存区视为数组,每个数组元素为HASH表的节点数据。当有HASH节点从POOL_TABLE内存区中分配出去,该指针指向POOL_TABLE内存区中下一个空闲的数组元素。
- pHashStatTbl:指向STATISTICS_TABLE内存区,将该内存区视为数组,每个数组元素为HASH表统计数据结构。
- pHashMainRwLockTbl:指向WRLOCK_TABLE内存区,将该内存区视为数组,每个数组元素为HASH表的读写锁结构。
- pHashGlbResSpinlock:指向SPINLOCK_TABLE内存区,将该内存区视为数组,每个数组元素为HASH表的自旋锁结构。
- pfEntryDataInitFunc(): HASH表节点数据初始化接口,把外部拷贝的数据填充到HASH表的节点中。
- pfEntryDataClear():HASH表节点数据清除接口
- pfStatEntryAdd(): HASH统计表中统计节点计数增加接口。
- pfStatEntryDel(): HASH统计表中统计节点计数减少接口。
- pfHashWriteLock():对HASH表上读锁。
- pfHashWriteUnLock():对HASH表解除读锁。
EHASH_NODE_S结构是HASH节点的管理结构,在EHASH_NODE_S结构后紧接着的是具体的业务数据,HASH节点的KEY来自于具体的业务数据。EHASH_NODE_S结构和其后跟着的业务数据一起构成了HASH表的节点数据。主要成员如下:
- ucValid:标明该节点的数据是否有效,当冲POOL_TABLE内存区分配出来的时候,ucValid会被标记为1,释放到POOL_TABLE中的时候,ucValid被设定为0。修改节点数据前ucValid设为0,然后修改数据,修改后再将ucValid设定为1.
- ulNextIndex:下一个元素在POOL_TABLE内存数组中的数组下标。POOL_TABLE内存数组通过ulNextIndex将一个个离散或相邻的数组元素串联成为一个链表。链表最后一个元素的ulNextIndex为0xFFFFFFFF
EHASH_STAT_S结构是EHASH统计表的元素,EHASH统计表的每个元素对应一个EHASH表的HASH KEY,统计表同HASH桶的元素一一对应。统计表中的每个元素记录了冲突链上冲突元素的数量,以及历史上该HASH KEY冲突的最大数量。主要成员有:
- usHistoryMaxNum:历史上该HASH KEY冲突的最大数量
- usCurMaxNum:该HASH KEY上当前冲突元素的数量
相关核心代码如下:
typedef struct tagEHASH_NODE
{
volatile u8 ucValid;
u8 ucRsvd1;
u16 usRsvd2;
volatile u32 ulNextIndex;
} EHASH_NODE_S;
typedef struct tagEHASH_STAT
{
u16 usHistoryMaxNum;
u16 usCurMaxNum;
} EHASH_STAT_S;
typedef EHASH_NODE_S EHASH_BACKET_S;
typedef struct tagEHASH
{
EHASH_BACKET_S *pHashMainTbl;
EHASH_NODE_S *pHashPool;
EHASH_STAT_S *pHashStatTbl;
u32 ulSize;
u32 ulPoolSize;
u32 ulStatSize;
u32 ulEntrySize;
u32 ulStatEntrySize;
u32(*pfEhashKey)();
s32(*pfEhashCmp)();
void (*pfEntryDataInitFunc)(void *, void *);
void (*pfEntryDataClear)(void *, u32);
void (*pfStatEntryAdd)(void *, u32);
void (*pfStatEntryDel)(void *, u32);
u32 ulCount;
void *pHashMainRwLockTbl; /*读写锁基地址*/
u32 ulRwLockEntrySize; /*一个读写锁占用的内存大小*/
void *pHashGlbResSpinlock; /*全局资源锁*/
/*hash锁操作*/
void (*pfHashReadLock)(void *, u32);
void (*pfHashReadUnLock)(void *, u32);
void (*pfHashWriteLock)(void *, u32);
void (*pfHashWriteUnLock)(void *, u32);
void (*pfGlbResSpinLock)();
void (*pfGlbResSpinUnLock)();
} EHASH_S;
3. EHASH关键流程
3.1冲突节点分配流程
HASH表冲突节点的从POOL_TABLE内存区中分配得到的,分配流程如下
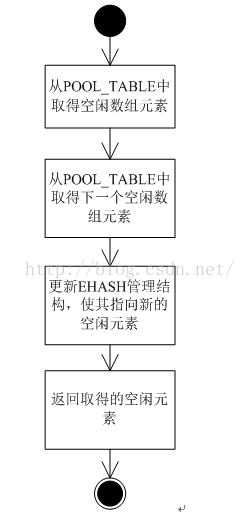
图 7 冲突节点分配流程
核心代码如下:
/*从哈希资源表中分配一个新节点(EHASH模块的内部函数)*/
EHASH_NODE_S *hashEntryAlloc(EHASH_S *pstEhcb)
{
EHASH_NODE_S *pstNewNode = NULL;
EHASH_NODE_S *pstHashPool = NULL;
u32 ulEntrySize = pstEhcb->ulEntrySize;
(*pstEhcb->pfGlbResSpinLock)(pstEhcb); /*锁一把*/
pstHashPool = pstHashPool = pstEhcb->pHashPool;
if (pstHashPool != NULL)
{
pstNewNode = pstHashPool;
pstHashPool = EHASH_NODE_ENTRY(pstEhcb->pHashMainTbl, pstNewNode->ulNextIndex, ulEntrySize, EHASH_NODE_S);
pstNewNode->ulNextIndex = EHASH_INDEX_INVALID;
pstEhcb->pHashPool = pstHashPool;
/*添加成功,记录添加个数*/
pstEhcb->ulCount++;
(*pstEhcb->pfGlbResSpinUnLock)(pstEhcb); /*解锁*/
return pstNewNode;
}
else
{
(*pstEhcb->pfGlbResSpinUnLock)(pstEhcb); /*解锁*/
return NULL;
}
}
3.2冲突节点释放流程
HASH表冲突节点的需要释放到POOL_TABLE内存区中,释放流程如下:

图 8 冲突节点释放流程
核心代码如下:
/*向哈希资源表中释放一个节点(EHASH模块的内部函数)*/
void hashEntryFree(EHASH_S *pstEhcb, EHASH_NODE_S *pstNode)
{
EHASH_NODE_S *pstHashPool = NULL;
if (pstEhcb == NULL || pstNode == NULL)
{
return;
}
(*pstEhcb->pfGlbResSpinLock)(pstEhcb); /*锁一把*/
pstHashPool = pstEhcb->pHashPool;
/*冲突表用光的情况下,要判断pstHashPool == NULL的情况*/
if (NULL != pstHashPool)
{
pstNode->ulNextIndex = EHASH_NODE_INDEX(pstEhcb->pHashMainTbl, pstHashPool, pstEhcb->ulEntrySize);
pstEhcb->pHashPool = pstNode;
}
else
{
pstNode->ulNextIndex = EHASH_INDEX_INVALID;
pstEhcb->pHashPool = pstNode;
}
pstEhcb->ulCount--;
(*pstEhcb->pfGlbResSpinUnLock)(pstEhcb); /*解锁*/
return;
}3.3哈希表资源初始化流程
初始化HASH表所用的所有资源,包括回调函数,共享内存区等,流程如下:

图 9 哈希表资源初始化流程
核心代码如下:
/*
*创建哈希表
*该函数实际上只创建了哈希控制块,这是因为使用EHASH模块所创建的哈希表用于多核
*共享,所以只需要在主核上初始化哈希表项资源,从核只需初始化好哈希控制块即可。
*基于上述原因,EHASH模块将哈希控制块的初始化与哈希表项初始化分割开。在主核上
*需要依次调用EHASH_HashNew()和EHASH_HashTblInit()来完成初始化动作;而在从核
*上只需调用EHASH_HashNew()函数创建哈希控制块即可操纵哈希表了。
*/
EHASH_S * EHASH_HashNew(u32(*pfEhashKey)(), s32(*pfEhashCmp)(),
void (*pfEntryDataInitFunc)(void *, void *),
void*(*pfMallocFunc)(u32), void (*pfEntryDataClear)(void *, u32),
void (*pfStatEntryAdd)(void *, u32), void (*pfStatEntryDel)(void *, u32))
{
EHASH_S *pstEhcb = NULL;
if (pfMallocFunc == NULL || pfEhashKey == NULL || pfEhashCmp == NULL
|| pfEntryDataInitFunc == NULL || pfEntryDataClear == NULL)
{
return NULL;
}
pstEhcb = (EHASH_S *)pfMallocFunc(sizeof(EHASH_S));
if (pstEhcb == NULL)
{
return NULL;
}
pstEhcb->pfEhashKey = pfEhashKey;
pstEhcb->pfEhashCmp = pfEhashCmp;
pstEhcb->pfEntryDataInitFunc = pfEntryDataInitFunc;
pstEhcb->pfEntryDataClear = pfEntryDataClear;
/*初始化统计函数*/
if (pfStatEntryAdd == NULL)
{
pstEhcb->pfStatEntryAdd = EHASH_HashCommonStatAdd;
}
else
{
pstEhcb->pfStatEntryAdd = pfStatEntryAdd;
}
if (pfStatEntryDel == NULL)
{
pstEhcb->pfStatEntryDel = EHASH_HashCommonStatDel;
}
else
{
pstEhcb->pfStatEntryDel = pfStatEntryDel;
}
/*初始化读写锁和spinlock的接口函数*/
pstEhcb->pfHashReadLock = EHASH_HashReadLock;
pstEhcb->pfHashReadUnLock = EHASH_HashReadUnLock;
pstEhcb->pfHashWriteLock = EHASH_HashWriteLock;
pstEhcb->pfHashWriteUnLock = EHASH_HashWriteUnLock;
pstEhcb->pfGlbResSpinLock = EHASH_GlbResSpinLock;
pstEhcb->pfGlbResSpinUnLock = EHASH_GlbResSpinUnLock;
return pstEhcb;
}
/*
*初始化哈希主表和哈希资源表
*pEhashMainTblAddr指向待初始化的哈希主表的首地址
*ulSize为哈希主表的大小,即通常我们所说的哈希表大小
*pEhashPoolAddr指向待初始化的哈希资源表的首地址,哈希资源表其实就是一个由哈
*希空闲节点所组成的大链表
*ulPoolSize为哈希资源表的大小
*ulEntrySize为当前初始化的哈希表中每一个哈希节点的实际大小
*/
s32 EHASH_HashTblInit(EHASH_S *pstEhcb,
void *pEhashMainTblAddr, u32 ulSize,
void *pEhashPoolAddr, u32 ulPoolSize,
u32 ulEntrySize, void *pEhashStatTblAddr,
u32 ulStatSize, u32 ulStatEntrySize,
void *pMainRwLockTblAddr, u32 ulRwLockEntrySize,
void *pEhashResSpinlock)
{
if (pstEhcb == NULL || pEhashMainTblAddr == NULL || pEhashPoolAddr == NULL
|| pEhashStatTblAddr == NULL)
{
return ERROR;
}
if (pMainRwLockTblAddr == NULL || pEhashResSpinlock == NULL)
{
return ERROR;
}
pstEhcb->pHashMainTbl = pEhashMainTblAddr;
pstEhcb->pHashPool = pEhashPoolAddr;
pstEhcb->pHashStatTbl = pEhashStatTblAddr;
pstEhcb->ulSize = ulSize;
pstEhcb->ulPoolSize = ulPoolSize;
pstEhcb->ulStatSize = ulStatSize;
pstEhcb->ulEntrySize = ulEntrySize;
pstEhcb->ulStatEntrySize = ulStatEntrySize;
/*add by dengjunjun_107 on 2012-4-10 支持ehash的锁机制,资源链用spinlock,ehash链用rwlock begin*/
pstEhcb->pHashMainRwLockTbl = pMainRwLockTblAddr;
pstEhcb->ulRwLockEntrySize = ulRwLockEntrySize;
pstEhcb->pHashGlbResSpinlock = pEhashResSpinlock;
return OK;
}
s32 EHASH_HashTblResInit(EHASH_S *pstEhcb)
{
u32 ulSize = pstEhcb->ulSize;
u32 ulPoolSize = pstEhcb->ulPoolSize;
u32 ulStatSize = pstEhcb->ulStatSize;
u32 ulEntrySize = pstEhcb->ulEntrySize;
u32 ulStatEntrySize = pstEhcb->ulStatEntrySize;
EHASH_NODE_S *pstEhashNode = NULL;
s32 i = 0;
cvmx_rwlock_wp_lock_t *pstMainRwLockTbl = NULL;
cvmx_spinlock_t * pstGlbResSpinlock = NULL;
if (pstEhcb == NULL || pstEhcb->pHashMainTbl == NULL || pstEhcb->pHashPool == NULL
|| pstEhcb->pHashStatTbl == NULL)
{
return ERROR;
}
if (pstEhcb->pHashMainRwLockTbl == NULL || pstEhcb->pHashMainRwLockTbl == NULL)
{
return ERROR;
}
bzero(pstEhcb->pHashMainTbl, (ulSize * ulEntrySize));
for (i = 0, pstEhashNode = pstEhcb->pHashMainTbl; i < ulSize; i++)
{
pstEhashNode = EHASH_NODE_ENTRY(pstEhcb->pHashMainTbl, i, ulEntrySize, EHASH_NODE_S);
pstEhashNode->ulNextIndex = EHASH_INDEX_INVALID;
}
bzero(pstEhcb->pHashPool, (ulPoolSize * ulEntrySize));
for (i = 0, pstEhashNode = pstEhcb->pHashPool; i < (ulPoolSize - 1); i++)
{
pstEhashNode->ulNextIndex = ulSize + i + 1;
pstEhashNode = EHASH_NODE_ENTRY(pstEhcb->pHashMainTbl, pstEhashNode->ulNextIndex, ulEntrySize, EHASH_NODE_S);
}
pstEhashNode->ulNextIndex = EHASH_INDEX_INVALID;
/*清零 统计表信息,统计*/
bzero(pstEhcb->pHashStatTbl, (ulStatSize * ulStatEntrySize));
UOS_ASSERT(sizeof(cvmx_rwlock_wp_lock_t) <= pstEhcb->ulRwLockEntrySize);
/*初始化hash主表的读写锁*/
pstMainRwLockTbl = (cvmx_rwlock_wp_lock_t *) pstEhcb->pHashMainRwLockTbl;
for (i = 0; i < ulSize; i++)
{
cvmx_rwlock_wp_init(&pstMainRwLockTbl[i]);
}
/*初始化资源表的全局spinlock*/
pstGlbResSpinlock = (cvmx_spinlock_t *)pstEhcb->pHashGlbResSpinlock;
cvmx_spinlock_init(pstGlbResSpinlock);
return OK;
}
3.4哈希查找流程
输入为指定要查找的内容,该内容中含所有关键字KEY,通过KEY可以计算得到散列值HASH KEY,在EHASH中进行查找,如果找到那么返回找到的元素,流程如下:
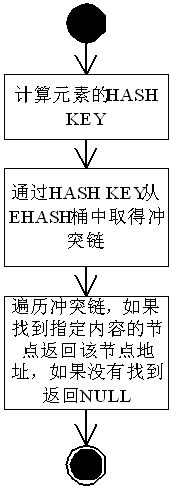
图 10哈希查找流程
核心代码如下:
/*
*哈希查找函数,pstEhcb指向哈希表控制块,pEhashEntryData指向待查找的数据
*哈希查找函数通常会被控制面和数据面的代码一起使用,旨在实现无阻塞的哈希
*查找。
*/
void * EHASH_HashSearch(EHASH_S *pstEhcb, void *pEhashEntryData)
{
u32 ulKey;
EHASH_BACKET_S *pstHashBacket = NULL;
EHASH_NODE_S *mp = NULL;
u32 ulEntrySize = pstEhcb->ulEntrySize;
u8 ucFlag = 0;
ulKey = (*pstEhcb->pfEhashKey)(pEhashEntryData);
(*pstEhcb->pfHashReadLock)(pstEhcb, ulKey);
pstHashBacket = (EHASH_BACKET_S *)((void *)pstEhcb->pHashMainTbl + ulEntrySize * ulKey);
for (mp = pstHashBacket;
(mp != NULL && mp->ucValid == 1);
mp = EHASH_NODE_ENTRY(pstEhcb->pHashMainTbl, mp->ulNextIndex, ulEntrySize, EHASH_NODE_S))
{
if ((*pstEhcb->pfEhashCmp)(mp, pEhashEntryData) == 0)
{
ucFlag = 1;
break;
}
}
(*pstEhcb->pfHashReadUnLock)(pstEhcb, ulKey);
if (ucFlag)
{
return mp;
}
else
{
return NULL;
}
}5.5向哈希表中插入一个新节点
输入为要插入的内容,该内容中含所有关键字KEY,通过KEY可以计算得到散列值HASH KEY。最终函数将带插入的内容插入到HASH表中。流程如下

图 11 向哈希表中插入一个新节点
核心代码如下:
/*
*向哈希表中压入一个新节点,pstEhcb指向哈希表控制块,pfInitFunc函数指针用于
*为不同数据类型的哈希节点进行初始化,pEhashEntryData用于为新创建的节点提供
*数据。
*/
s32 EHASH_HashPush(EHASH_S *pstEhcb, void *pEhashEntryData)
{
u32 ulKey;
u8 ucFlag = 0;
EHASH_BACKET_S *pstHashBacket = NULL;
EHASH_STAT_S *pstHashStatBacket = NULL;
EHASH_NODE_S *mp, *pstNewNode = NULL;
u32 ulEntrySize = pstEhcb->ulEntrySize;
u32 ulStatEntrySize = pstEhcb->ulStatEntrySize;
ulKey = (*pstEhcb->pfEhashKey)(pEhashEntryData);
(*pstEhcb->pfHashWriteLock)(pstEhcb, ulKey);
pstHashStatBacket = EHASH_NODE_ENTRY(pstEhcb->pHashStatTbl, ulKey, ulStatEntrySize, EHASH_STAT_S);
pstHashBacket = EHASH_NODE_ENTRY(pstEhcb->pHashMainTbl, ulKey, ulEntrySize, EHASH_BACKET_S);
for (mp = pstHashBacket;
(mp != NULL && mp->ucValid == 1);
mp = EHASH_NODE_ENTRY(pstEhcb->pHashMainTbl, mp->ulNextIndex, ulEntrySize, EHASH_NODE_S))
{
if ((*pstEhcb->pfEhashCmp)(mp, pEhashEntryData) == 0)
{
ucFlag = 1;
break;
}
}
if (ucFlag == 1)
{
/*既然是push操作,且找到了相同的节点,那么直接用新的数据覆盖旧的数据,
*在内层实现覆盖更新操作,是否需要覆盖更新则可在外部进行判断,这样可以
*更新时如果发现节点存在,不需要将原有节点删除,只需要将原有节点中需要
*保存的部分内容以及需要更新的内容push入即可,也保证了更新操作在锁的保护
*下*/
bcopy((void *)(pEhashEntryData + sizeof(EHASH_NODE_S)), (void *)(mp + 1),
(ulEntrySize - sizeof(EHASH_NODE_S)));
(*pstEhcb->pfHashWriteUnLock)(pstEhcb, ulKey);
return OK;
}
if (pstHashBacket->ucValid == 0) /*在空表中添加节点*/
{
(*pstEhcb->pfEntryDataInitFunc)(pstHashBacket, pEhashEntryData);
pstHashBacket->ucValid = 1;
}
else /*在冲突表中添加节点*/
{
pstNewNode = hashEntryAlloc(pstEhcb);
if (pstNewNode == NULL)
{
UOS_ASSERT(0);
(*pstEhcb->pfHashWriteUnLock)(pstEhcb, ulKey);
return ERROR;
}
(*pstEhcb->pfEntryDataInitFunc)(pstNewNode, pEhashEntryData);
pstNewNode->ucValid = 1;
for (mp = pstHashBacket;
(mp->ucValid == 1 && mp->ulNextIndex != EHASH_INDEX_INVALID);
mp = EHASH_NODE_ENTRY(pstEhcb->pHashMainTbl, mp->ulNextIndex, ulEntrySize, EHASH_NODE_S));
pstHashBacket->ucValid = 0;
mp->ucValid = 0;
mp->ulNextIndex = EHASH_NODE_INDEX(pstEhcb->pHashMainTbl, pstNewNode, ulEntrySize);
mp->ucValid = 1;
pstHashBacket->ucValid = 1;
}
/*增加节点,回调统计信息*/
(*pstEhcb->pfStatEntryAdd)(pstHashStatBacket, ulStatEntrySize);
(*pstEhcb->pfHashWriteUnLock)(pstEhcb, ulKey);
return OK;
}
3.6从哈希表中弹出(删除)指定节点
输入为要删除的内容,该内容中含所有关键字KEY,通过KEY可以计算得到散列值HASH KEY。最终函数将从HASH表中删除指定内容的节点。流程如下
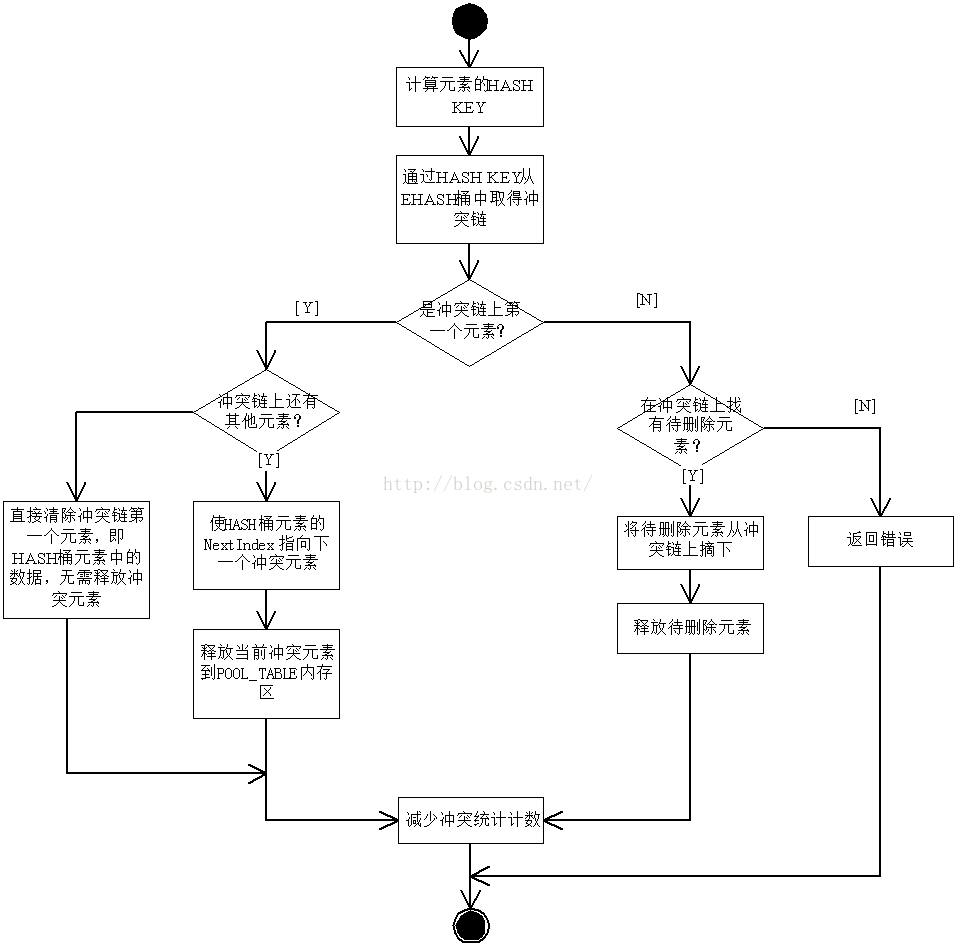
图 12 从哈希表中弹出(删除)指定节点
核心代码如下:
/*
*从哈希表中弹出(删除)待查找的节点,pstEhcb指向哈希表控制块,pEhashEntryData
*指向待查找的数据。
*/
s32 EHASH_HashPull(EHASH_S *pstEhcb, void *pEhashEntryData)
{
u32 ulKey;
EHASH_BACKET_S *pstHashBacket = NULL;
EHASH_STAT_S *pstHashStatBacket = NULL;
EHASH_NODE_S *mp, *pstPrevNode = NULL;
u32 ulEntrySize = pstEhcb->ulEntrySize;
u32 ulStatEntrySize = pstEhcb->ulStatEntrySize;
ulKey = (*pstEhcb->pfEhashKey)(pEhashEntryData);
(*pstEhcb->pfHashWriteLock)(pstEhcb, ulKey);
pstHashStatBacket = (EHASH_STAT_S *)((void *)pstEhcb->pHashStatTbl + ulStatEntrySize * ulKey);
pstHashBacket = (EHASH_BACKET_S *)((void *)pstEhcb->pHashMainTbl + ulEntrySize * ulKey);
if ((*pstEhcb->pfEhashCmp)(pstHashBacket, pEhashEntryData) == 0)
{
if (pstHashBacket->ulNextIndex == EHASH_INDEX_INVALID) /*Cond.1 无冲突链的情况下删除首节点*/
{
pstHashBacket->ucValid = 0;
/*bzero((void *)pstHashBacket, ulEntrySize);*/
pstHashBacket->ulNextIndex = EHASH_INDEX_INVALID;
(*pstEhcb->pfEntryDataClear)((void*)pstHashBacket, pstEhcb->ulEntrySize);
}
else /*Cond.2 存在冲突链的情况下删除首节点*/
{
mp = EHASH_NODE_ENTRY(pstEhcb->pHashMainTbl, pstHashBacket->ulNextIndex, ulEntrySize, EHASH_NODE_S);
pstHashBacket->ucValid = 0;
/*在删除主表节点时将数据块初始化一下,将冲突节点内容拷入到主节点中,*/
(*pstEhcb->pfEntryDataInitFunc)(pstHashBacket, mp);
pstHashBacket->ulNextIndex = mp->ulNextIndex;
pstHashBacket->ucValid = 1;
mp->ucValid = 0;
(*pstEhcb->pfEntryDataClear)((void*)mp, pstEhcb->ulEntrySize);
hashEntryFree(pstEhcb, mp);
}
}
else
{
u8 ucFlag = 0;
for (mp = pstHashBacket, pstPrevNode = NULL;
(mp != NULL && mp->ucValid == 1);
mp = EHASH_NODE_ENTRY(pstEhcb->pHashMainTbl, mp->ulNextIndex, ulEntrySize, EHASH_NODE_S))
{
if ((*pstEhcb->pfEhashCmp)(mp, pEhashEntryData) == 0)
{
ucFlag = 1;
break;
}
pstPrevNode = mp;
}
if (ucFlag == 0)
{
(*pstEhcb->pfHashWriteUnLock)(pstEhcb, ulKey);
return ERROR;
}
/*查找到待弹出的节点*/
if (mp->ulNextIndex == EHASH_INDEX_INVALID) /*Cond.3 冲突链存在的情况下删除尾节点*/
{
pstHashBacket->ucValid = 0;
mp->ucValid = 0;
pstPrevNode->ucValid = 0;
pstPrevNode->ulNextIndex = EHASH_INDEX_INVALID;
pstPrevNode->ucValid = 1;
pstHashBacket->ucValid = 1;
(*pstEhcb->pfEntryDataClear)((void*)mp, pstEhcb->ulEntrySize);
hashEntryFree(pstEhcb, mp);
}
else /*Cond.4 冲突链存在的情况下删除中间节点*/
{
pstHashBacket->ucValid = 0;
mp->ucValid = 0;
pstPrevNode->ucValid = 0;
pstPrevNode->ulNextIndex = mp->ulNextIndex;
pstPrevNode->ucValid = 1;
pstHashBacket->ucValid = 1;
(*pstEhcb->pfEntryDataClear)((void*)mp, pstEhcb->ulEntrySize);
hashEntryFree(pstEhcb, mp);
}
}
(*pstEhcb->pfHashWriteUnLock)(pstEhcb, ulKey);
/*删除节点,回调统计信息*/
(*pstEhcb->pfStatEntryDel)(pstHashStatBacket, ulStatEntrySize);
return OK;
}