Hadoop中distcp命令
Hadoop中distcp命令
1.什么是distcp命令?
Hadoop comes with a useful program called distcp for copying data to and from Hadoop filesystems in parallel.
2.distcp 是如何实现的?
distcp is implemented as a MapReduce job where the work of copying is done by the maps that run in parallel across the cluster.There are no reducers.
Each file is copied by a single map, and distcp tries to give each map approximately the same amount of data by bucketing files into roughly equal allocations
By default, up to 20 maps are used, but this can be changed by specifying the -m argument to distcp.
3.如何使用distcp命令?
hadoop distcp dir1 dir2
- If dir2 does not exist, it will be created, and the contents of the dir1 directory will be copied there.
- If dir2 already exists, then dir1 will be copied under it, creating the directory structure dir2/dir1. If this isn’t what you want, you can supply the -overwrite option to keep the same directory structure and force files to be overwritten.
4.distcip 的用途
A very common use case for distcp is for transferring data between two HDFS clusters.
5.示例
- 执行命令前
查看HDFS的存储内容
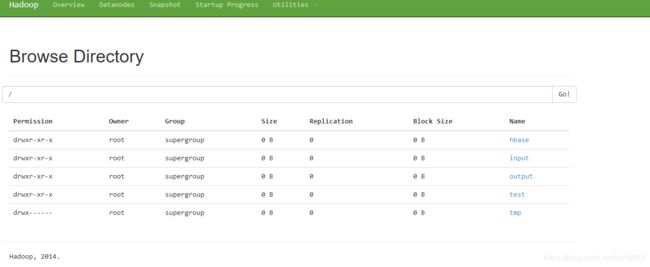
- 执行命令
hadoop distcp /test /lawson
这个命令的意思是:将/test目录下的内容 copy 一份放到/lawson文件夹下。
[root@server4 hadoop]# hadoop distcp /test /lawson
19/01/14 18:08:17 INFO tools.DistCp: Input Options: DistCpOptions{atomicCommit=false, syncFolder=false, deleteMissing=false, ignoreFailures=false, maxMaps=20, sslConfigurationFile='null', copyStrategy='uniformsize', sourceFileListing=null, sourcePaths=[/test], targetPath=/lawson, targetPathExists=false, preserveRawXattrs=false}
19/01/14 18:08:17 INFO client.RMProxy: Connecting to ResourceManager at server4/192.168.211.4:8032
19/01/14 18:08:17 INFO Configuration.deprecation: io.sort.mb is deprecated. Instead, use mapreduce.task.io.sort.mb
19/01/14 18:08:17 INFO Configuration.deprecation: io.sort.factor is deprecated. Instead, use mapreduce.task.io.sort.factor
19/01/14 18:08:17 INFO client.RMProxy: Connecting to ResourceManager at server4/192.168.211.4:8032
19/01/14 18:08:18 INFO mapreduce.JobSubmitter: number of splits:2
19/01/14 18:08:19 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1547460247783_0001
19/01/14 18:08:19 INFO impl.YarnClientImpl: Submitted application application_1547460247783_0001
19/01/14 18:08:19 INFO mapreduce.Job: The url to track the job: http://server4:8088/proxy/application_1547460247783_0001/
19/01/14 18:08:19 INFO tools.DistCp: DistCp job-id: job_1547460247783_0001
19/01/14 18:08:19 INFO mapreduce.Job: Running job: job_1547460247783_0001
19/01/14 18:08:31 INFO mapreduce.Job: Job job_1547460247783_0001 running in uber mode : false
19/01/14 18:08:31 INFO mapreduce.Job: map 0% reduce 0%
19/01/14 18:08:42 INFO mapreduce.Job: map 50% reduce 0%
19/01/14 18:08:43 INFO mapreduce.Job: map 100% reduce 0%
19/01/14 18:08:44 INFO mapreduce.Job: Job job_1547460247783_0001 completed successfully
19/01/14 18:08:44 INFO mapreduce.Job: Counters: 33
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=218172
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=889
HDFS: Number of bytes written=30
HDFS: Number of read operations=28
HDFS: Number of large read operations=0
HDFS: Number of write operations=7
Job Counters
Launched map tasks=2
Other local map tasks=2
Total time spent by all maps in occupied slots (ms)=15439
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=15439
Total vcore-milliseconds taken by all map tasks=15439
Total megabyte-milliseconds taken by all map tasks=15809536
Map-Reduce Framework
Map input records=2
Map output records=0
Input split bytes=268
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=293
CPU time spent (ms)=740
Physical memory (bytes) snapshot=201781248
Virtual memory (bytes) snapshot=4150059008
Total committed heap usage (bytes)=93454336
File Input Format Counters
Bytes Read=591
File Output Format Counters
Bytes Written=0
org.apache.hadoop.tools.mapred.CopyMapper$Counter
BYTESCOPIED=30
BYTESEXPECTED=30
COPY=2
-
执行命令后
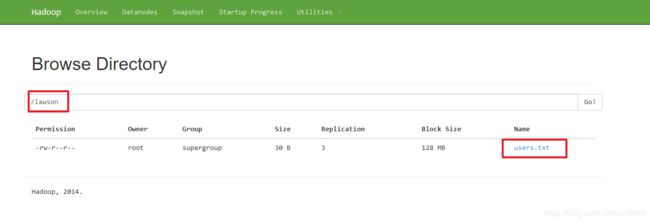
可以看到已经生成了一个/lawson的文件,而且下面有一个users.txt文件 -
接着我们将
/test文件夹下的文件重命名为distcp.txt,再次执行如下命令
[root@server4 hadoop]# hadoop distcp /test /lawson
19/01/14 18:14:17 INFO tools.DistCp: Input Options: DistCpOptions{atomicCommit=false, syncFolder=false, deleteMissing=false, ignoreFailures=false, maxMaps=20, sslConfigurationFile='null', copyStrategy='uniformsize', sourceFileListing=null, sourcePaths=[/test], targetPath=/lawson, targetPathExists=true, preserveRawXattrs=false}
19/01/14 18:14:17 INFO client.RMProxy: Connecting to ResourceManager at server4/192.168.211.4:8032
19/01/14 18:14:18 INFO Configuration.deprecation: io.sort.mb is deprecated. Instead, use mapreduce.task.io.sort.mb
19/01/14 18:14:18 INFO Configuration.deprecation: io.sort.factor is deprecated. Instead, use mapreduce.task.io.sort.factor
19/01/14 18:14:18 INFO client.RMProxy: Connecting to ResourceManager at server4/192.168.211.4:8032
19/01/14 18:14:19 INFO mapreduce.JobSubmitter: number of splits:2
19/01/14 18:14:19 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1547460247783_0002
19/01/14 18:14:19 INFO impl.YarnClientImpl: Submitted application application_1547460247783_0002
19/01/14 18:14:19 INFO mapreduce.Job: The url to track the job: http://server4:8088/proxy/application_1547460247783_0002/
19/01/14 18:14:19 INFO tools.DistCp: DistCp job-id: job_1547460247783_0002
19/01/14 18:14:19 INFO mapreduce.Job: Running job: job_1547460247783_0002
19/01/14 18:14:26 INFO mapreduce.Job: Job job_1547460247783_0002 running in uber mode : false
19/01/14 18:14:26 INFO mapreduce.Job: map 0% reduce 0%
19/01/14 18:14:33 INFO mapreduce.Job: map 50% reduce 0%
19/01/14 18:14:35 INFO mapreduce.Job: map 100% reduce 0%
19/01/14 18:14:35 INFO mapreduce.Job: Job job_1547460247783_0002 completed successfully
19/01/14 18:14:35 INFO mapreduce.Job: Counters: 33
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=218164
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=906
HDFS: Number of bytes written=30
HDFS: Number of read operations=29
HDFS: Number of large read operations=0
HDFS: Number of write operations=7
Job Counters
Launched map tasks=2
Other local map tasks=2
Total time spent by all maps in occupied slots (ms)=11509
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=11509
Total vcore-milliseconds taken by all map tasks=11509
Total megabyte-milliseconds taken by all map tasks=11785216
Map-Reduce Framework
Map input records=2
Map output records=0
Input split bytes=266
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=100
CPU time spent (ms)=520
Physical memory (bytes) snapshot=203853824
Virtual memory (bytes) snapshot=4150059008
Total committed heap usage (bytes)=93454336
File Input Format Counters
Bytes Read=610
File Output Format Counters
Bytes Written=0
org.apache.hadoop.tools.mapred.CopyMapper$Counter
BYTESCOPIED=30
BYTESEXPECTED=30
COPY=2
查看/lawson文件夹下的内容:
[root@server4 hadoop]# hadoop fs -ls /lawson
Found 2 items
drwxr-xr-x - root supergroup 0 2019-01-14 18:14 /lawson/test
-rw-r--r-- 3 root supergroup 30 2019-01-14 18:08 /lawson/users.txt
[root@server4 hadoop]# hadoop fs -ls /lawson/test
Found 1 items
-rw-r--r-- 3 root supergroup 30 2019-01-14 18:14 /lawson/test/distcp.txt
可以看到在/lawson文件夹下生成了一个/test文件夹,而该文件夹下有一个distcp.txt文件。