Hadoop进阶
地址:Hadoop进阶
源码地址:github
1 第一章 概述
hadoop的体系架构
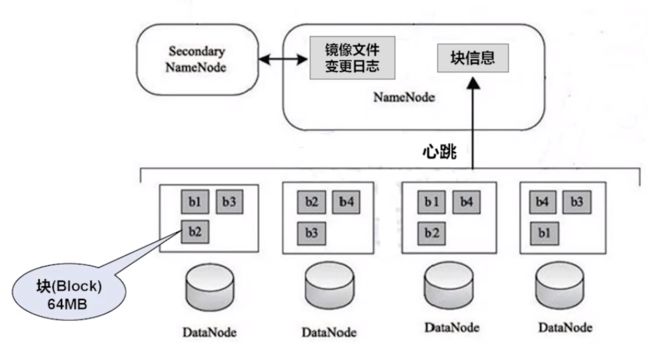
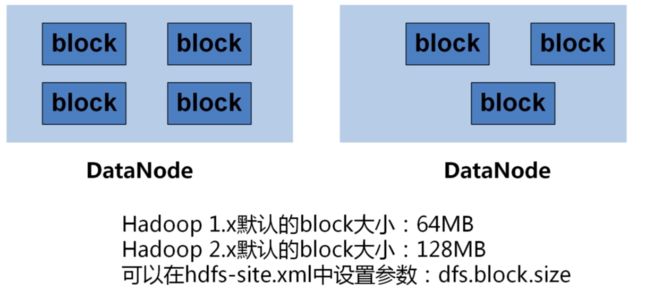
块:
DataNode:
NameNode:
Secondary NameNode:
Hadoop1.X架构图
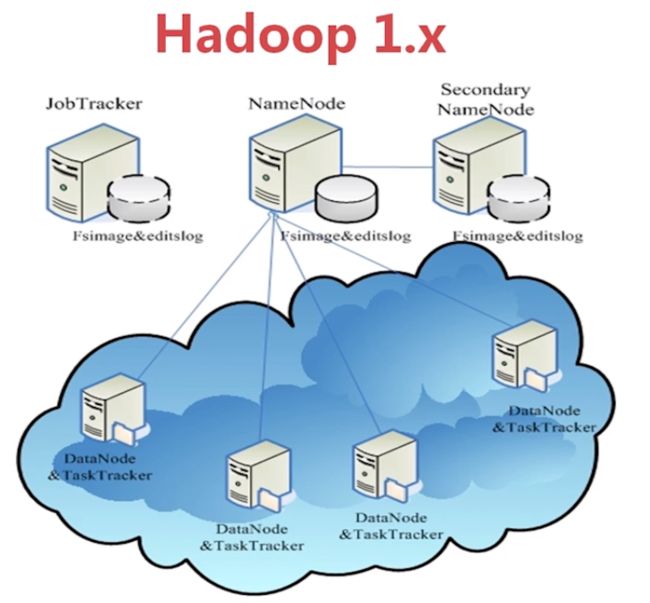
Hadoop 2.X
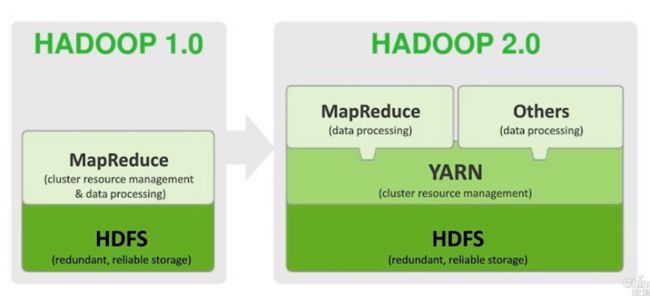
hadoop2.0以后版本移除了jobtracker tasktracker,改由Yarn平台的resourcemanager负责统一调配。

Yarn设计减少了jobtracker对系统资源的消耗,也减少了hadoop1.0单点故障问题。

2 第二章 深入探索MapReduce过程
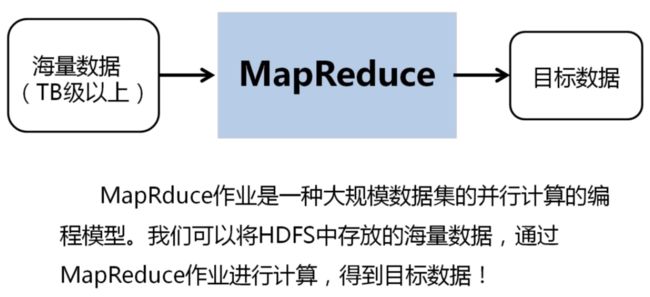
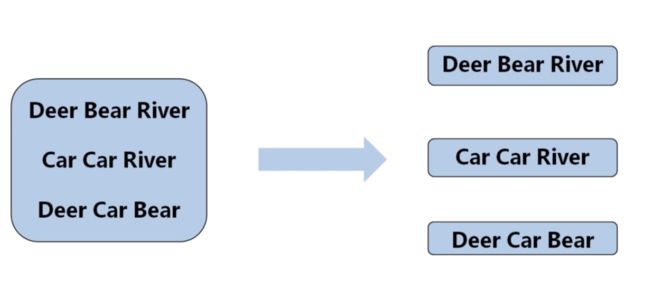
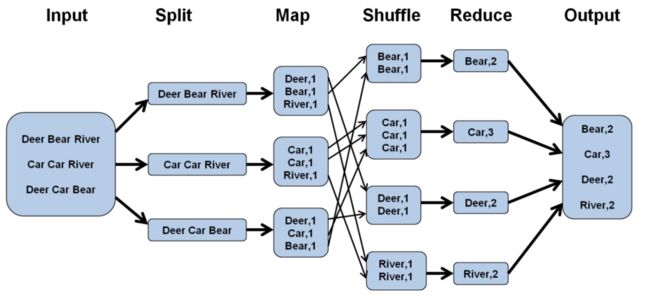
2.1 WordCount实例回顾
1Split 2 Map 3 Shuffle 4 Reduce
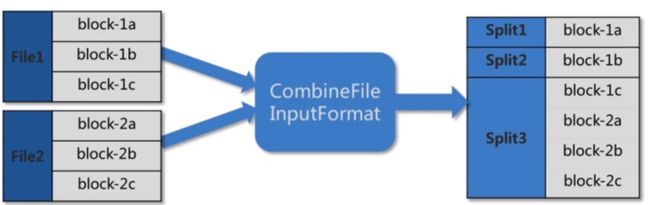
1 Split阶段

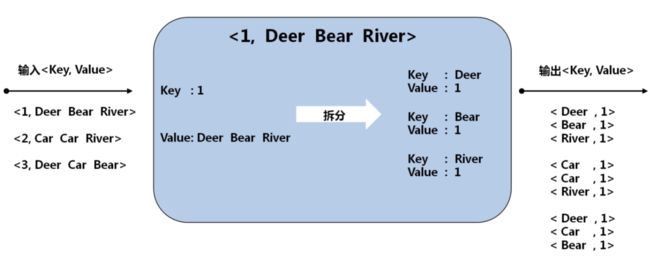
2 Map阶段
输入:key 行号 value 一行值
输出:key 单词 value 1
3 Shuffle阶段
比较复杂,可以理解为map端的输出作为reduce端的输入过程,而且涉及到网络传输;
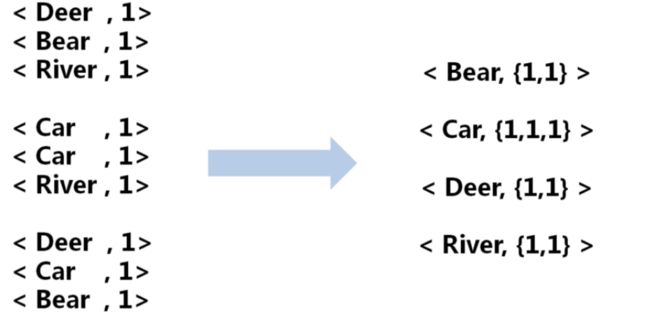
4 Reduce阶段
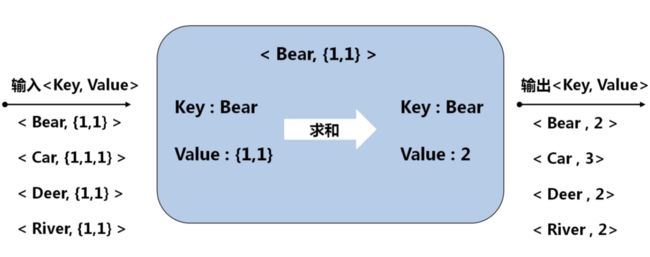
总结
2.2 从分片输入到Map
输入文件:
分片输入:
分片输入问题:
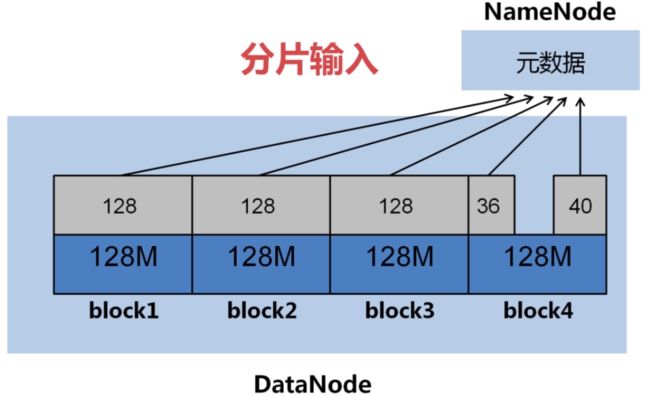
理想的输入文件:
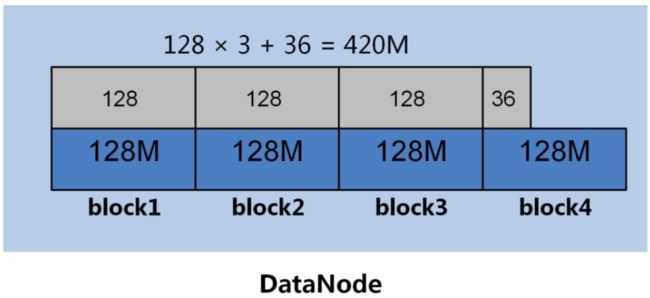
由于NameNode内存有限,大量的小文件会给Hdfs带来性能上的问题;故Hdfs适合存放大文件,对于大量的小文件,可以采取 **压缩、合并小文件 **的优化策略。例如,设置文件输入类型为CombineFileInputFormat格式。
如何调整节点Map的任务的个数?
四个分片对应四个map任务
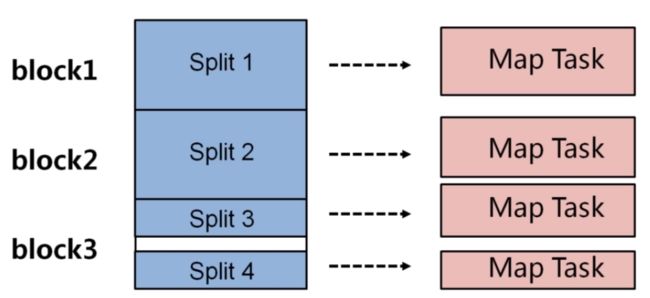
在实际情况下,map任务的个数是受多个条件的制约,一般一个DataNode的map任务数量控制在10到100比较合适。
一般操作如下:
- 增加map个数,可增大mapred.map.tasks;
- 减少map个数,可增大mapred.min.split.size;
- 如果要减少map个数,但有很多小文件,可将小文件合并成大文件,再使用准则2
2.3 Map---Shuffle---Reduce
1 本地优化-Combine

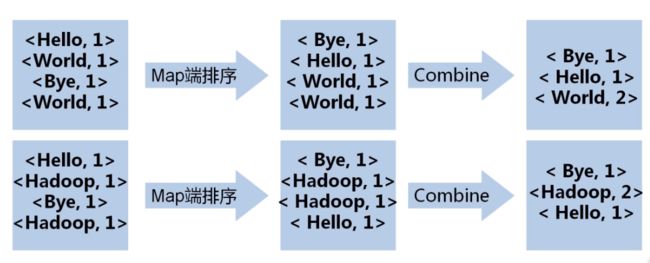

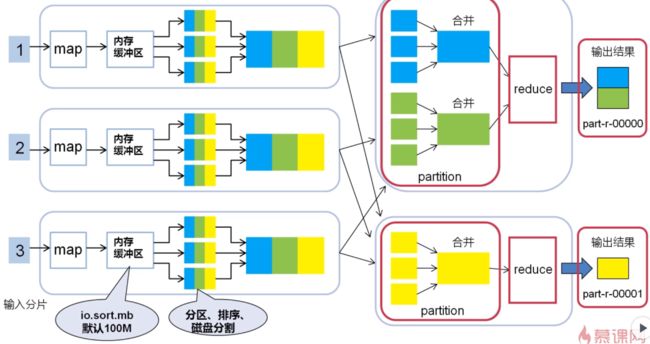
2 M-S-R
一、Combine的逻辑和reduce逻辑一致。故可以认为combine是对本地数据的reduce操作。
二、一个mapreduce作业中,一下三者的数量是相等的。
1)partitioner的数量
2)reduce任务的数量
3)最终输出文件的数量
三、一个reducer中,所有数据都会被按照key值升序排序,故如果part输出文件包含key值,则这个文件一定是有序的;
四、reducer任务数量

调整方式有二:
1)mapred.reduce.tasks
2)Java代码中job.setNumReduceTasks(int n)
2.4 总结
分片输入---split

本地合并---Combiner

Map---Shuffle---Reduce

3 第三章 Hadoop的分布式缓存
3.1 分布式缓存---DistributedCache
在执行MapReduce时,可能Mapper之间需要共享一些信息,如果信息量不大,可以将其从HDFS加载到内存中,这就是Hadoop分布式缓存机制。
例子:统计全量的单词文本中存在的单词,那么在Hadoop一开始就把全量的单词加载到内存中 ,然后对于输入的行单词,去在内存中查找,如果全局缓存中存在该单词,就输出;
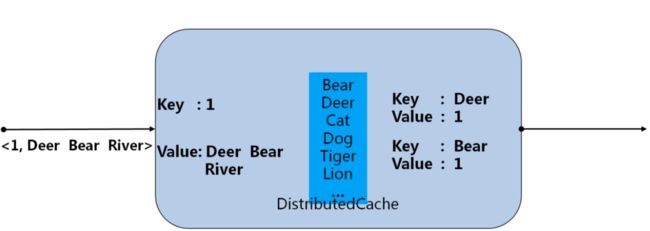
如何使用DistributedCached呢?
第一步:设置路径和别名
在main方法中加载共享文件的HDFS路径,路径可以是目录也可以是文件。可以在路径末尾追加 “ #” +别名,在map阶段可以使用该别名;

第二步:
在Mapper类或Reducer的setup方法中,用输入流获取分布式缓存中的文件;

加载到内存发生在Job执行之前,每个从节点各自都缓存一份相同的共享数据。如果共享数据太大,可以把共享数据分批缓存,重复执行作业。
3.2 MapReduce实现矩阵相乘
1 矩阵相乘例子

2 矩阵相乘编码
矩阵在文件中的表示
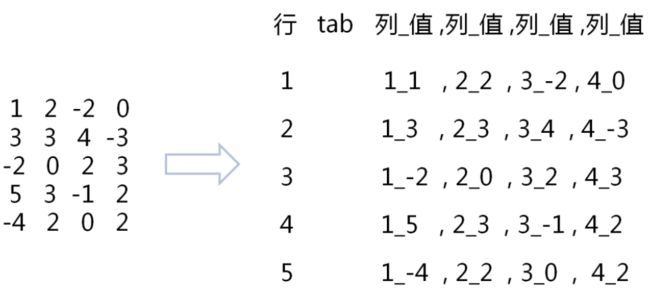
思路:
1: 将右侧矩阵转置,即行转换成列,列转化为行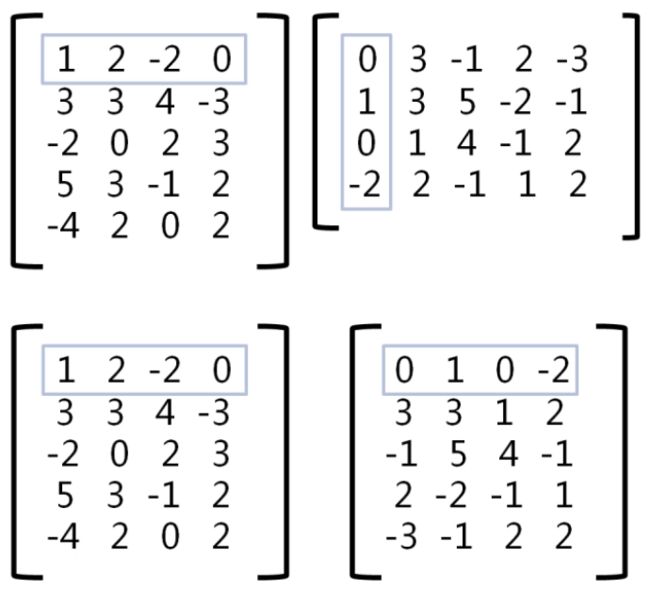
2:矩阵相乘
1、将右矩阵载入分布式缓存;
2、将左矩阵的行作为map输入;
3、在map执行之前:将缓存的右矩阵以行为单位放入list;
4、在map计算时:从list中取出所有行分别与输入行相乘。
4 推荐算法
4.1 相似度
余玄相似度
二维向量的余玄相似度
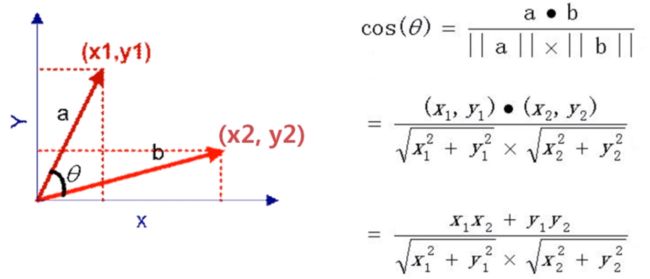
多维向量的余玄相似度

其他相似度

4.2 基于物品的推荐算法(理论)
基于物品的协同过滤推荐算法(ItemCF)
用户行为和权重:点击(1.0分) 搜索(3.0分) 收藏(5.0分) 付款(10.0分)
算法思想:给用户推荐那些和他们之前喜欢的物品相似的物品
实例:


算法步骤:
3个用户、6种商品
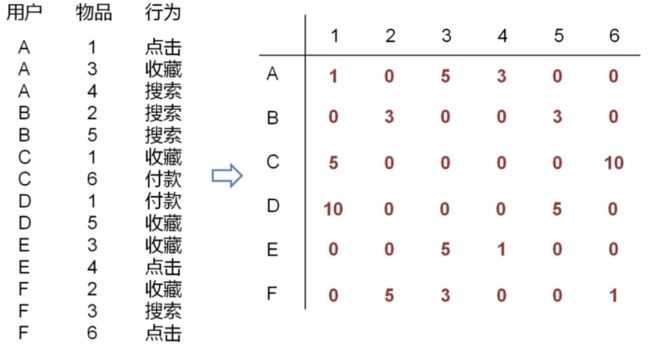
1、根据用户行为列表计算用户、物品的评分矩阵
[图片上传失败...(image-db3bef-1526978905470)]
2、根据用户、物品的评分矩阵计算物品与物品的相似度矩阵
取第一行和第二行的行向量,计算余旋相似度,比如:1号和2号物品的相似度为0.36

评分矩阵两两相乘、然后构建对称矩阵
[图片上传失败...(image-6ceb08-1526978905471)]
3、相似度矩阵*评分矩阵 = 推荐列表
[图片上传失败...(image-3ceb2-1526978905471)]
[图片上传失败...(image-8686f4-1526978905471)]
将推荐矩阵和评分矩阵做一个比较,发现在评分矩阵中,用户已经对一些商品产生过行为,对这些已经产生多的行为, 所以没有必要在为这些用户推荐这些商品,那么我们就可以将之前推荐过的商品置零。
[图片上传失败...(image-455ebe-1526978905471)]
最终的推荐结果,一个用户可能有很多的推荐物品,我们这里去Top1作为最终的推荐结果,取出用户最感兴趣的物品,
[图片上传失败...(image-df6cd3-1526978905471)]
具体实现步骤:
[图片上传失败...(image-94fe70-1526978905471)]
4-3 基于物品的推荐算法(代码)
代码实现的步骤[图片上传失败...(image-bb7222-1526978905471)]
Step1:
计算评分矩阵
输入:用户ID,物品ID,分支
输出:物品ID(行) --- 用户ID(列) --- 分值
Step2:
计算余弦相似度矩阵
输入:步骤1的输出
缓存:步骤1的输出
输出:用户ID(行) --- 物品ID(列) --- 相似度
[图片上传失败...(image-2cf23-1526978905471)]
step3:
将评分矩阵转置
输入:步骤1的输出
输出:用户ID(行) --- 物品ID(列) ---分值
step4:
相似度矩阵*评分矩阵
输入:步骤2的输出
缓存:步骤3的输出
输出:物品ID(行) --- 用户ID(列) --- 分值
step5:
根据评分矩阵,将步骤4的输出中,用户已经有用过行为的商品评分置0
输入:步骤4的输出
缓存:步骤1的输出
输出:用户ID(行) --- 物品ID(列) --- 分值 (最终的推荐列表)
4-4 基于物品的推荐算法(代码)
4-5 基于物品的推荐算法(代码)
4-6 基于用户的推荐算法(理论)
基于用户的协同过滤推荐算法(UserCF)
算法思想:给用户推荐和他兴趣相似的其他用户喜欢的物品
现有如下用户、商品、行为、权重:
用户:A、B、C、D、E、F
商品:1、2、3、4、5、6
行为:点击 1.0分、搜索 3.0分、收藏 5.0分、付款 10.0分

算法步骤:
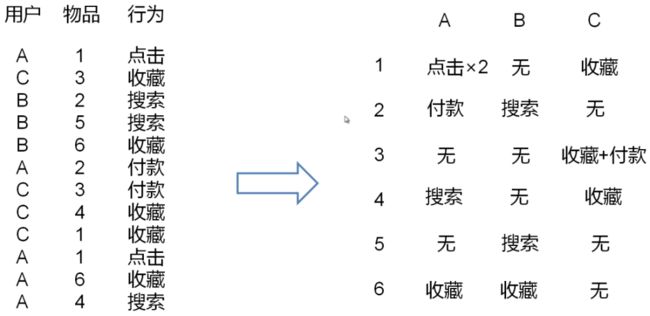
- 根据用户行为为列表计算物品、用户的评分矩阵
行号是用户ID、列号是物品ID
-
根据评分矩阵计算用户与用户的相似度矩阵
将所有的用户两两计算相似度之后,得到相似度矩阵
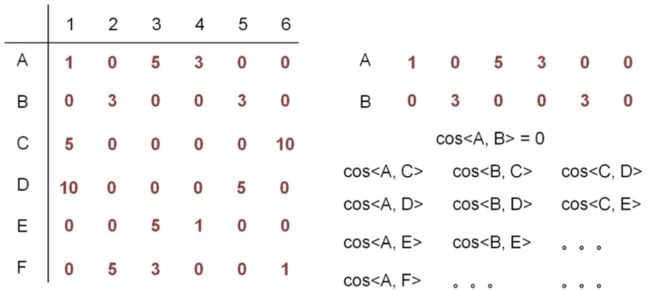 两两计算相似度
两两计算相似度
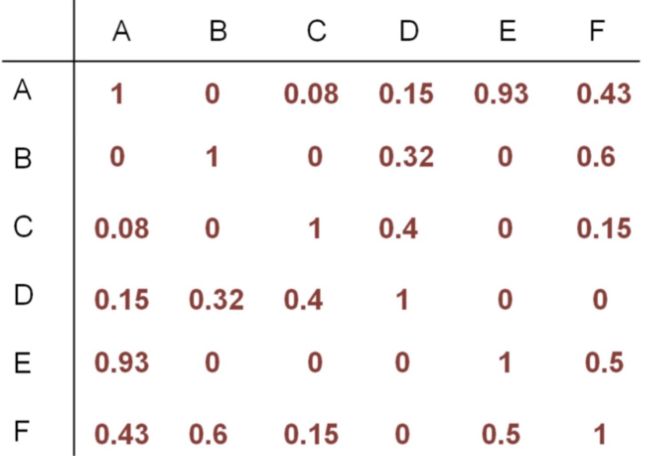 用户与用户的相似度矩阵
用户与用户的相似度矩阵
-
相似度矩阵 * 评分矩阵 = 推荐列表
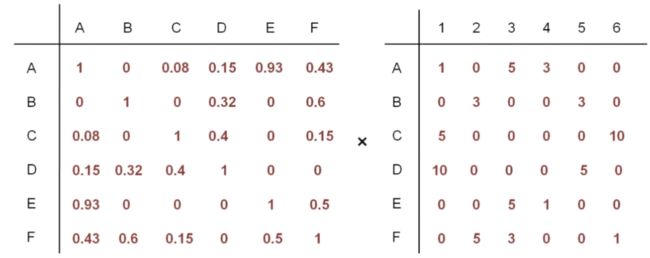 相似度矩阵 * 评分矩阵
相似度矩阵 * 评分矩阵
得到推荐列表,在对照评分矩阵,将相应位置的元素置零
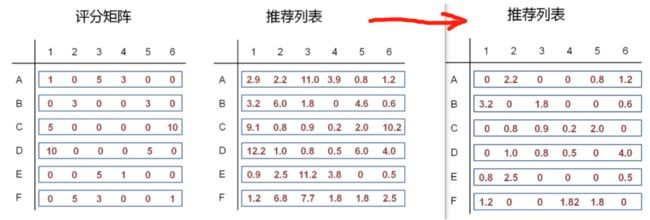
4-7 基于用户的推荐算法(代码)
基于用户的推荐算法MR的步骤:UserCF

与给予物品的推荐算法类似
4-8 基于内容的推荐算法(理论)
基于内容的推荐算法
算法思想:给用户推荐和他们之前喜欢的物品在内容上相似的其他物品
物品特征建模
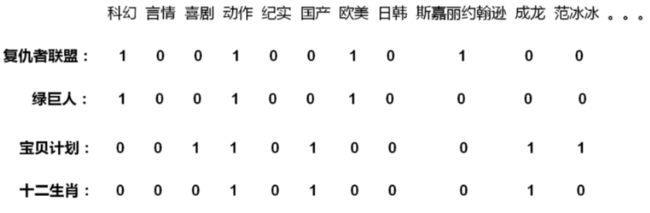
算法步骤:
1 构建Item Profile矩阵
0 1矩阵, 行号是物品ID,列号是标签
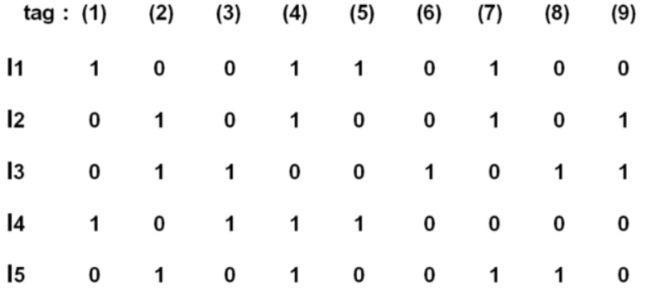
2 构建Item User评分矩阵
行号是用户ID,列号是物品ID

3 Item User * Item Profile = User Profile
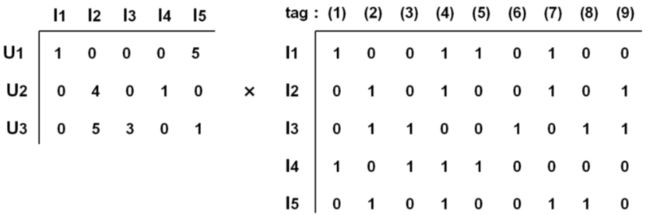
User Profile:用户对所有标签感兴趣的程度
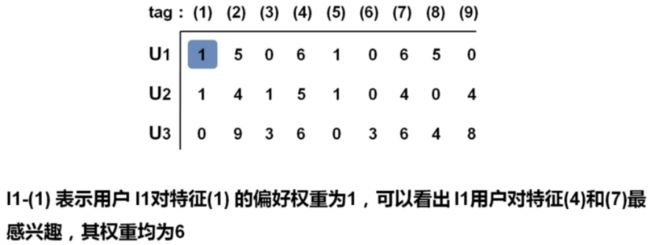
4 对Item Profile 和 User Profile求余弦相似度
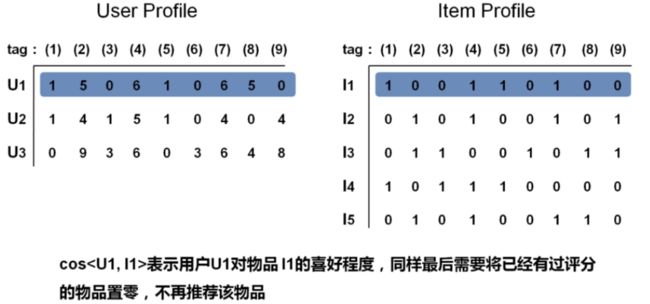
4-9 基于内容的推荐算法(代码)
MR步骤:UserCF

5 第五章 课程总结
