3D卷积论文阅读与代码复现:Learning Spatiotemporal Features with 3D Convolutional Networks
文章目录
- 前言
- UCF101动作识别的代码复现
- 补充
- 开始论文!!!!!!!!
- 摘要(copy)
- 1 介绍
- 2 相关工作
- 3 用3D卷积学习特征
- 3.1 3D卷积和池化:
- 3.2 不同时间长度的实验
- 3.3 空间特征的学习
- 4 动作识别
- 5 动作相似性识别
- 6 场景和对象识别
- 7 实时性分析
- 结论
前言
最近由于一些必要的需求,要学习3D卷积网络的相关用法和实现,学习过程中不可避免要阅读相关的论文,其中这篇Learning Spatiotemporal Features with 3D Convolutional Networks是最值得研究的一篇相关论文之一,在学习的时候做好相关笔记并进行代码复现,以便后面遗忘时候快速捡起来。
UCF101动作识别的代码复现
这是我看这篇论文的重点,这里我在colab环境下实现UCF101动作识别。参照代码:
https://github.com/kcct-fujimotolab/3DCNN
经过验证该github代码存在一些逻辑问题,现已经对其进行修改,修改完成之后的复现步骤如下:
- 下载UCF101
首先要去下载ucf101数据集,有的话可以从官网下载,这里我放一个百度云链接::https://pan.baidu.com/s/1KOJy-tfAaHRF4PLXSDynGA 提取码:kgg4。一共6.5G,下载完成后解压。
-
克隆我修改后的github代码:添加链接描述

-
按照下图的方式将解压的数据放入dataset:
4. 安装环境:tensorflow,keras, python-ffmpeg, tqdm,或者用我的yml文件直接生成环境,总之就是缺什么装什么。
conda env create -f freeze.yml
- 运行程序
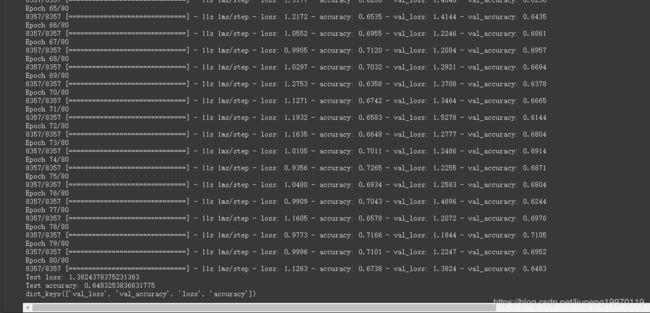
python 3dcnn.py --batch 16 --epoch 80 --videos ./dataset/ --nclass 101 --output 3dcnnresult/ --color True --skip False --depth 15
其中./dataset 是数据路径, depth 是每个视频提取的帧数,这里设置成8, 越多的话精度越高,但是有的视频没有那么多帧,就会报错cv读取了空照片。 nclass 92 是只对./dataset下101文件夹中前92个分类,前期可以设置成3之类快速验证程序是否可运行。

- 调试过程
在运行过程中可能会出现以下几个问题 :
有的视频质量低,导致无法提取足够多的帧: 需要将depth调小,或者将报错视频文件删除,如果觉得麻烦直接整个文件夹删除可以,但是分类–nclass 92中 92 也要对应少1,因为该分类不能多于文件夹的数量。只能少于。
keras 报错没有acc或者accurary: 需要更换keras对应版本下的正确命名,参照https://blog.csdn.net/liupeng19970119/article/details/105963118
环境问题: 环境问题需要自己去尝试解决,因为其他问题我没有遇到。
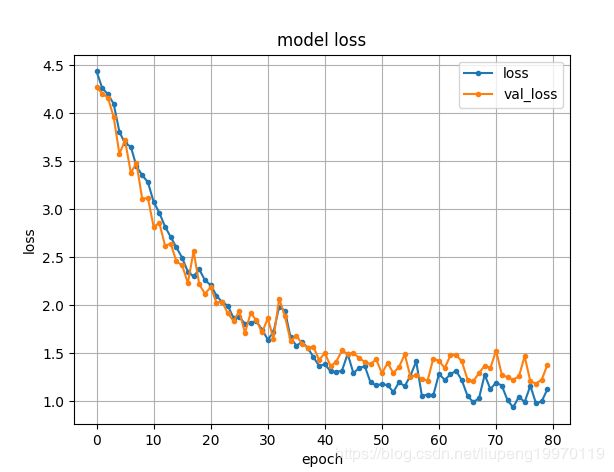
- 训练结果展示
补充
如果您能跑通代码,或者对您有帮助,麻烦帮我给我个star,蟹蟹!!!!
开始论文!!!!!!!!
摘要(copy)
提出了一种基于大尺度监督视频数据集的深度三维卷积网络学习时空特征的方法。结果表明:与二维卷积神经网络相比,三维卷积神经网络更适合时空特征学习;2)在所有层中都有小的3x 3x 3个卷积核的同构结构是3D ConvNets表现最好的结构之一;3)我们学习到的特征,即C3D (Convolutional 3D),它是一个简单的线性分类器,在4个不同的基准上都优于目前最先进的方法,并且可以与另外2个基准上目前最好的方法相媲美。此外,它的特点是紧凑的:在只有10维的UCF101数据集上实现52.8%的准确性,并且由于ConvNets的快速推理,计算效率也非常高。最后它们在概念上非常简单,易于培训和使用。
1 介绍
文章首先介绍随着视频的增长,一些动作识别和行为理解研究也随之发展,但现在仍然需要一种新的同性质方法解决大规模视频处理。一个好的视频描述方法有四个点;1可以很好分类特征 2. 可以紧凑表达每个视频特征,因为视频有很多种,太过疏散表达的类别就少了。3.较高的实时性 4.简单的实施,模型不要太复杂。然而之前的2D图像处理方法并不适合提取视频的特征,所以本文设计了一个3D卷积,尽管之前也有人提出来,但是本文是第一个实现大规模学习的,总的来说本文的工作如下:
- 我们证明了3D卷积的可用性
- 我们发现333是最好的卷积架构
- 通过线性分类器可以验证3D卷积在不同数据上都有很好的特征提取能力。如图所示:

2 相关工作
首先说了很多传统相关工作和深度学习在大规模数据上具有劣势,尽管准确率还可以。引出本文的方法可以将视频帧全部输入并且不依赖任何预处理,因此适用于大规模数据,经过验证3D卷积核,3D池化,加深网络的深度都可以对网络有一定的积极影响。
3 用3D卷积学习特征
3.1 3D卷积和池化:
介绍:从下图中可以看出2D单通道卷积、2Drgb通道卷积、3D卷积的区别是3D卷积输出的还是多个维度,而2D只有单维度,因此丧失了时间维度的信息。具体3D卷积方法可以参照这里
,卷积时候参数变化介绍的非常详细。

**细节:**在这一节中,我们将尝试为3D ConvNets确定一个好的架构。由于在大型视频数据集上训练深度网络非常耗时,因此我们首先使用中等规模的数据集UCF101进行实验,以寻找最佳架构。我们用较少的网络实验在大数据集上验证了这些发现。在2D ConvNet[37]中发现,3×3个卷积核的小感受域与较深的结构可以产生最好的结果。因此,在我们的架构搜索研究中,我们将空间接受域固定为3x 3,只改变3D卷积核的时间深度。
**通知:**卷积大小为c × l × h × w,池化大小为y d×k ×k。d 是时间,c 是通道数量,l 是帧数。
公共网络设置: 在本节中,我们将描述我们所训练的所有网络的公共网络设置。该网络以视频片段为输入,预测属于101个不同动作的类标签。所有的视频帧都被调整为128 x 171。这大概是UCF101帧的一半分辨率。视频被分成不重叠的16帧剪辑,然后作为网络的输入。输入尺寸为3x 16×128×171。我们也使用抖动,在训练中使用大小为3 x 16 x 112 x 112输入剪辑的随机作物。该网络有5个卷积层和5个池化层(每个卷积层紧接着一个池化层),2个全连接层和一个用于预测动作标签的softmax损耗层。1到5个卷积层的滤波器数量分别为64、128、256、256、256。所有的卷积核都有一个d的大小,其中d是内核的时间深度(我们稍后将改变这些层的值d,以搜索一个良好的3D架构)。所有这些卷积层都使用了适当的padding(包括空域和时域)和stride 1,因此从输入到输出的卷积层的大小没有变化。所有的池化层都是最大池化,内核大小为2 x 2 x 2(第一层除外),最大池化步长为1,这意味着输出信号的大小与输入信号相比减少了8倍。第一个池化层的内核大小为1 x 2 x 2,目的是不过早合并时间信号,并满足16帧的剪辑长度(例如,在完全崩溃时间信号之前,我们最多可以用4次因子2进行时间池)。两个完全连接的层有2048个输出。我们使用30个剪辑的小批量训练网络,初始学习率为0.003。每隔4个epoch,学习速率除以10。训练在16个时代之后停止。
**变化的网络结构:**为了本研究的目的,我们主要对如何通过深层网络聚合时间信息感兴趣。为了寻找一个好的三维卷积神经网络结构,我们只改变内核的时间深度d,同时保持所有其他公共设置固定如上所述。我们对两种结构进行了实验:1)均质时间深度:所有卷积层具有相同的核时间深度;2)变化的时间深度:内核的时间深度随着层的变化而变化。对于齐次设置,我们用4个网络进行实验,它们的核时间深度d分别为1、3、5和7。我们称这些网络为深度-d,其中d是它们的均匀时间深度。注意,深度-1网络相当于在单独的帧上应用2D卷积。对于变化的时间深度设置,我们实验了两个时间深度增加的网络:3-3-5-5-7和从第一层到第五层分别减少的75- 5-5-3-3。我们注意到,所有这些网络在最后的池化层具有相同大小的输出信号,因此它们对于完全连接层具有相同数量的参数。由于不同的核时间深度,它们在卷积层上的参数数是不同的。但是与全连接层中的数百万个参数相比,这些差异微不足道。
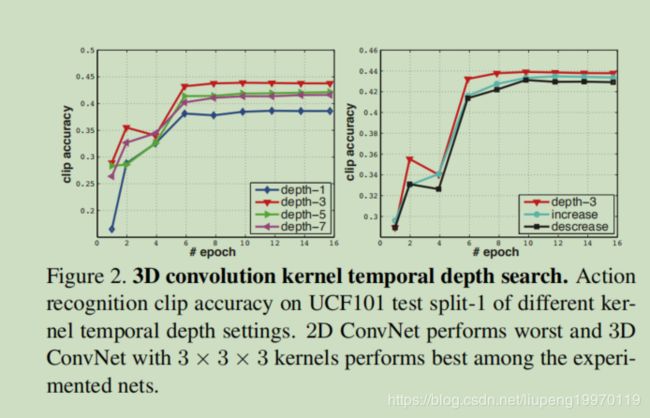
3.2 不同时间长度的实验
我们在UCF101上训练这些网络。图2展示了不同架构的clip accuracy或UCF101 test 。左边的图是时间深度均匀的结果,右边的图是时间深度变化的结果。深度3在同质网中表现最好。注意,深度1明显比其他网差,我们认为这是由于缺乏运动建模。与变化的时间深度网相比,深度3表现最好,但差距较小。我们也用更大的空间接受域(例如5×5)和/或全输入分辨率(240×320帧输入)进行实验,仍然观察到类似的行为。这表明,3x3x3是3D ConvNets的最佳内核选择(根据我们的实验子集),在视频分类方面,3D ConvNets始终优于2D ConvNets。我们还验证了在大规模的内部数据集(即1380K)上,3D ConvNet的性能始终优于2D ConvNet。
3.3 空间特征的学习
作者在前面确定了卷积的大小为333,之后就会根据这里的大小去探索网络的深度对精度的影响,并且在前期使用时间维度较小的池化层来保留时间信息,方便后期的训练。结构如下:

数据集: 为了学习时空特征,我们在Sports-1M数据集[18]上训练我们的C3D,这是目前最大的视频分类基准。数据集包括110万个体育视频。每个视频都属于487个运动类别中的一个。与UCF101相比,Sports1M的类别数量是UCF101的5倍,视频数量是UCF101的100倍。
训练: 因为sport - 1m有很多长视频,所以我们从每个训练视频中随机抽取5个2秒长的视频片段。剪辑的大小被调整为帧大小为128 x 171。在训练中,我们将输入剪辑随机裁剪为16×112×112种作物,以进行空间和时间抖动。我们也以50%的概率水平翻转它们。训练由SGD完成,每批30个样本。初始学习率为0.003,每150K迭代除以2。在1.9M迭代(大约13个epoch)时停止优化。除了从零开始训练的C3D net外,我们还对在1380K上预先训练的模型进行了C3D net微调实验。
分类结果 :表2展示了我们的C3D网络与深度视频[18]和卷积池[29]的结果。可以看出使用120帧输入的话效果非常好。

C3D学习过程我们使用在[46]中解释的反褶积方法来理解C3D内部学习的内容。我们观察到C3D一开始只关注前几帧的外观,然后在接下来的几帧中跟踪突出的运动。图4显示了两个C3D conv5b地形图的反褶积,其中激活度最高的地形图被投影回图像空间。在第一个例子中,该功能将重点放在整个人身上,然后跟踪撑杆跳高的动作表现。类似地,在第二个例子中,它首先关注眼睛,然后在化妆时跟踪眼睛周围发生的动作。因此,C3D不同于标准的2D ConvNets,它有选择地兼顾运动和外观。我们在补充材料中提供了更多的可视化,以便更好地了解所学习的特性。
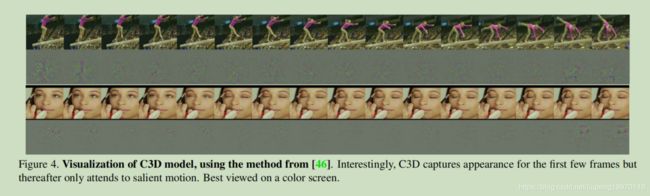
ps:这个点非常关键,以后我可以将这种方法引用到论文中,解释深度学习的过程。
4 动作识别
数据集:我们在UCF101数据集[38]上评估C3D特征。数据集由13320个视频组成,包含101个人类动作类别。我们使用该数据集提供的三个分割设置。
分类模型:提取C3D特征并将其输入到多类线性支持向量机中进行训练。我们使用3种不同的3DCNN网络对进行了实验:3DCNN训练在1380K上,3DCNN训练在Sports-1M上,3DCNN训练在1380K上,3DCNN训练在Sports-1M上。并且添加了L2正则化.
对比实验 使用之前的相关研究例如hog,iDT,hof等。对于图片方法话会对视频帧求平均。
**结果:**表3给出了C3D的动作识别精度,并与两种基线和当前的最佳方法进行了比较。上半部分显示了两个基线的结果。中间部分介绍了只使用RGB帧作为输入的方法。下面的部分使用所有可能的特征组合(如光流,iDT)报告所有当前的最佳方法。

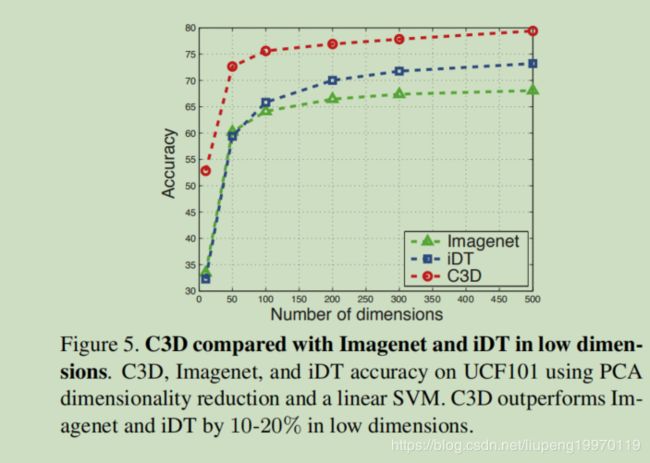
C3D紧凑性判断:为了评估C3D特征的紧凑性,我们使用PCA将特征投影到低维中,并使用线性支持向量机在UCF101[38]上报告投影特征的分类精度。我们对iDT[44]和Imagenet特性[7]应用相同的过程,并比较图5中的结果。在只有10个维度的极端情况下,C3D的精度为52.8%,比Imagenet和iDT的精度(约为32%)提高了20%以上。在50和100 dim时,C3D的准确率分别为72.6%和75.6%,比Imagenet和iDT的准确率高10-12%左右。最后,在500维的情况下,C3D能够达到79.4%的准确率,比iDT高出6%,比Imagenet高出11%。这说明我们的特征是紧凑的,有区别的。这对于存储成本低、检索速度快的大型检索应用非常有帮助。
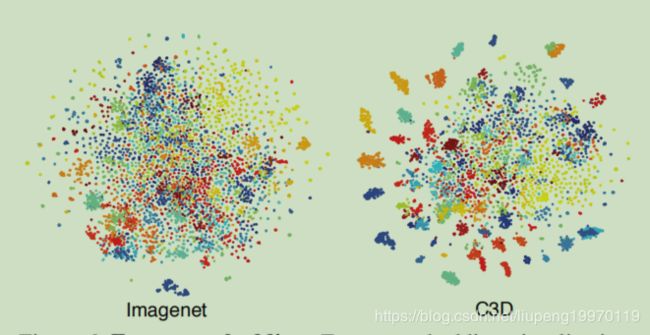
此外我们定性地评估我们学习的C3D特性,通过可视化嵌入到另一个数据集的学习特性来验证它是否是一个好的视频通用特性。我们从UCF101中随机选择100K个剪辑,然后从Imagenet和C3D中提取fc6特征用于这些剪辑的特征。然后使用t-SNE[43]将这些特征投射到二维空间中。图6可视化了来自Imagenet和我们的C3D的特性在UCF101上的嵌入。值得注意的是,我们没有做任何微调,因为我们想要验证的功能是否显示良好的泛化能力跨数据集。我们定量地观察到C3D比Imagenet更好。
5 动作相似性识别
这个工作是将所有的视频进行相似性标记,由于没有标签工作难度更大。在此就不具体说了,因为我也不做这方面的工作。
6 场景和对象识别
这个工作是将所有的视频进行场景和对象识别,工作难度更大。在此就不具体说了,因为我也不做这方面的工作。
7 实时性分析
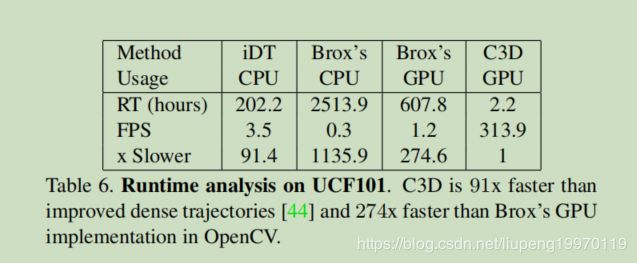
我们比较了C3D和iDT[441和时间流网络[36]的运行时间。对于iDT,我们使用作者[44]提供的代码。对于[36],没有可用的公共模型进行评估。然而,这种方法使用Brox的光流[3]作为输入。我们使用两个不同的版本来评估Brox方法的运行时:由作者[3]提供的CPU实现和OpenCV提供的GPU实现。我们在表6中报告了使用单个CPU或单个K40 Tesla GPU对整个UCF101数据集提取特征(包括1/O)的三种方法的运行时。[36]报告了一对图像的计算时间(没有I/O)为0.06s。在我们的实验中,Brox的GPU实现对于包括I/O在内的每一对图像需要0.85-0.9s的时间。注意,这对iDT来说不是一个公平的比较,因为它只使用CPU。我们找不到任何该方法的GPU实现,这是不平凡的实现该算法的并行版本的GPU。注意,C3D比实时处理快得多,处理速度为313帧/秒,而其他两种方法的处理速度小于4帧/秒。
结论
在这项工作中,我们试图解决的问题,学习时空特征的视频使用三维卷积神经网络训练的大规模视频数据集。为了寻找三维卷积神经网络的最佳时间核长度,我们进行了系统的研究。我们证明了C3D可以同时对外观和运动信息进行建模,并且在各种视频分析任务中都优于2D ConvNet特性。我们证明了C3D特征与线性分类器可以超越或接近目前最好的方法在不同的视频分析基准。最后但并非最不重要的是,提出的C3D功能是有效的,紧凑的,并非常简单的使用。