SDSoC软硬件协同设计流程系列——3. SDS pragma
前面的章节已经介绍了利用HLS进行开发的流程,分成三步,首先在Vivado HLS工具中将C/C++转换成RTL代码并打包成IP核,然后在Vivado IPI中将HLS IP核与Zynq的PS集成在一起,最后在SDK中编写驱动完成整个设计。在这个流程中开发者需要根据应用特点选择合适的接口,合适的DMA,每一次调整都要先在HLS中调整,然后在Vivado更新IP,操作流程十分繁琐。此外,编写驱动进行调试也要花费大量的精力。
SDSoC替开发者完成后两项工作,使开发者可以专注在最有价值的工作当中。SDSoC完成后两步的工作也需要一些约束条件,这些约束条件以SDS pragma的形式给出。SDS pragma根据是否与数据传输相关可以分成两类,第一类SDS pragma决定了算法加速IP连接到PS的哪个端口,调用哪种类型的Data mover,在DDR中的内存如何分配,包括SDS data copy/zero_copy,data access_pattern,data mem_attribute,data sys_port和data_mover,这些指令可以形成不同的组合,不同的组合最终实现的数据传输性能差距很大。第二类SDS pragma包括SDS async/wait,partition,buffer_depth,resource以及trace,这类指令的功能各异,使用频率也不是很高,本节会着重介绍第一类指令应该如何使用。
SDS指令简介
- access_pattern
语法
#pragma SDS data access_pattern( ArrayName: )
其中:
pattern:SEQUENTIAL或RANDOM,默认为RANDOM。
如果access_pattern是SEQUENTIAL,Array会被综合成一个streaming接口,如ap_fifo;如果是RANDOM,Array会被综合成一个RAM。
例1
#pragma SDS data access_pattern(A:SEQUENTIAL)
void foo(int A[1024], int B[1024])
在这种情况下,数组A会被综合成一个FIFO,只能按照A[0], A[1],…, A[1023]的顺序被访问,而B会被综合成RAM(因为默认是RANDOM),可以按照任意顺序被访问。
例2
#pragma SDS data access_pattern(A:SEQUENTIAL)
void foo(int* A, int B[1024])
类似地,指针变量也可以用data access_pattern指令来规定它的访问次序。
在为硬件加速函数添加SDS指令时,有些指令可以省略,但是access_pattern指令绝对不能省略,除非用到zero_copy指令。zero_copy要求在该接口上数据必须顺序传输,此时data access_pattern强制为SEQUENTIAL,是否添加pragma没有影响。
例3
void mmult_accel(float A[N*N], float B[N*N], float C[N*N], int M)
{
float A_tmp[N][N], B_tmp[N][N];
for(int i=0; i<M; i++) {
for(int j=0; j<M; j++) {
#pragma HLS PIPELINE
A_tmp[i][j] = A[i*M+j];
B_tmp[i][j] = B[i*M+j];
}
}
for (int i = 0; i < M; i++) {
for (int j = 0; j < M; j++) {
float result = 0;
for (int k = 0; k < M; k++) {
#pragma HLS PIPELINE
result += A_tmp[i][k] * B_tmp[k][j];
}
C[i*M+j] = result;
}
}
}
此外,为了提升系统性能,通常算法加速IP需要将运算时用到的数据先加载到PL上再进行计算,如例3代码所示。为了提升性能,将数据从内存搬运到PL的过程访问内存的方式是连续的,因此在本系列文章中所有SDSoC相关实验的assess pattern均设置为SEQUENTIAL。
- #pragma SDS data copy/zero_copy
使用copy指令时SDSoC会综合出一个datamover完成数据传输,而使用zero_copy指令时,SDSoC会将硬件加速器的接口直接连接到PS的S_AXI端口,这部分内容在下一节中会详细分析。
语法:
#pragma SDS data copy|zero_copy(ArrayName[:])
其中:
offset:编译时必须为常量,指定数据存储到数组的第几个元素中,目前offset值必须指定为0。
length:用于告知编译器通过该接口的数据传输量,可以是数学表达式,要确保该函数执行时能够得到确定的结果。
重要!copy指令与zero_copy指令是相互排斥的,绝对不允许在同一个数组/指针上使用。
例1
#pragma SDS data copy(A[0:1024], B[0:1024])
#pragma SDS data zero_copy(A[0:1024], B[0:1024])
void foo(int* A, int* B);
例1的所示情况是不被允许的。
例2
#pragma SDS data copy(A[0:1024])
#pragma SDS data zero_copy(B[0:1024])
void foo(int* A, int* B);
例2的所示情况是被允许的。
例3
#pragma SDS data copy(A[0:size*size], B[0:size*size])
void foo(int *A, int *B, int size)
{
...
}
size作为传入参数虽然在编译时不能确定,但是在执行时可以确定,因此上面的写法是被允许的。
copy与zero_copy的区别会在后面详细介绍。
- pragma SDS data data_mover
默认情况下编译器会分析代码自动选择合适的data_mover,但是开发者可以指定data_mover覆盖掉编译器的默认值。
语法:
#pragma SDS data data_mover(ArrayName:DataMover[:id])
其中:
dataMover:AXIFIFO,AXIDMA_SG或AXIDMA_SIMPLE。
id:可选,必须是一个正整数,如果多个ArrayName指定同一个id,它们会共享同一个data_mover。
例1
#pragma SDS data data_mover(A:AXIDMA_SG:1, B:AXIDMA_SG:1)
void foo(int* A, int* B)
在这种情况下A和B会共享同一个AXIDMA_SG IP
pragma SDS data mem_attribute
对于像支持虚拟内存的操作系统比如Linux,用户空间分配的内存是经过Linux系统虚拟化过的,不能保证在物理上,也就是DDR中是否连续,这可能会影响系统性能。SDSoC提供了API分配物理上连续的内存空间。mem_attribute可用于告诉编译器该参数是否被分配在物理上连续的内存中。
语法:
#pragma SDS data mem_attribute(ArrayName:contiguity)
其中:
Contiguity: PHYSICAL_CONTIGUOUS或NON_PHYSICAL_CONTIGUOUS,默认是后者。
例1
#pragma SDS data mem_attribute(A:PHYSICAL_CONTIGUOUS)
void foo(int* A, int* B)
在上面的例子里,开发者告诉编译器数组A被分配到了物理上连续的内存空间,编译器会强制选择Datamover为AXIDMA_SIMPLE而不是AXIDMA_SG。
- pragma SDS data sys_port
前文介绍过Zynq-7000系列处理器提供了S_AXI_HP,S_AXI_ACP接口用于数据传输。ACP接口全称Accelerator Coherency Port,也叫缓存一致接口,通过该接口PL可以直接访问PS的cache,缓存一致性由SCU保证,延时很低,适合做专用指令加速器模块接口。通过ACP接口传输的数据量有限制,不能超过8MB,如果传输数据量较大只能使用HP接口。
语法:
#pragma SDS data sys_port(ArrayName:port)
其中:
port: ACP,AFI或HPC,AFI对应的是HP接口,ACP对应Zynq-7000系列的缓存一致接口,HPC对应MPSoC系列的缓存一致接口。
例1.
#pragma SDS data sys_port(A:AFI)
void foo(int* A, int* B)
在该例中,A接口连接到S_AXI_HP端口,B接口视情况而定。
- pragma SDS async/wait
ASYNC pragma必须与WAIT pragma搭配使用以手动控制硬件函数同步。在调用硬件函数之前立即指定ASYNC pragma,指示编译器不要根据数据流分析自动生成等待。 WAIT pragma必须插入到程序的适当位置以便CPU等待,直到具有相同ID的关联ASYNC函数调用完成。上面的描述可能比较难以理解,读者可以先看下面的例子。
语法:
#pragma SDS async()
...
#pragma SDS wait(ID)
其中:ID是用户定义的 ID用于匹配ASYNC/WAIT,必须是正整数
例1.
{
#pragma SDS async(1)
mmult(A, B, C);
#pragma SDS async(2)
mmult(D, E, F);
...
#pragma SDS wait(1)
#pragma SDS wait(2)
}
程序运行到mmult(A, B, C)时,先启动数组A和数组B的数据传输,一旦传输完毕立刻返回到主程序中,然后程序开始将数组D和数组E送到mmult硬件加速器中然后立即返回。当程序执行到#pragma SDS wait(1)时,等待输出C就绪,当程序执行到#pragma SDS wait(2)时,等待输出F就绪。使用该指令可以将数组D,E的数据传输时间与数组C的计算时间重叠,提升系统的吞吐率。
SDS Pragma组合
上一小节单独介绍每一个指令,但是在实际开发时要将SDS pragma组合起来,本小节通过一个最基本的数据传输的例子,分析不同的指令组合综合出来的数据传输网络有何区别以及最终数据传输性能的差异。
新建一个Application Project,起名为lab2,将我们提供的代码拷贝到src文件夹。这个工程实现的功能非常简单,首先生成一个随机数数组,然后把这个数组从DDR传到PL中,再从PL中传回DDR,最后验证从PL传回来的数据与最初传到PL的数据是否一致。这个例子并没有涉及如何加速在PL中的计算,只是单纯地分析数据传输。
例1. 以下程序并不完整,为了便于说明摘取了部分片段。
#define N 2048
#pragma SDS data copy(In[0:N],Out[0:N])
#pragma SDS data data_mover(In:AXIDMA_SG, Out:AXIDMA_SG)
#pragma SDS data access_pattern(In:SEQUENTIAL, Out:SEQUENTIAL)
#pragma SDS data sys_port(In:AFI, Out:AFI)
void IO(float* In, float* Out)
{
float Buffer [N];
for(int i=0;i<N;i++) Buffer[i]=In[i];//将数据从DDR读取到PL中
for(int i=0;i<N;i++) Out[i]=Buffer[i];//将数据从PL传输回DDR中
}
int main(int argc, char* argv[])
{
float *A, *B;
A = (float *)malloc(N * sizeof(float));
B = (float *)malloc(N * sizeof(float));
...
IO(A, B);
...
}
在上面这段程序里,我们用到了四个SDS pragma,分别是copy,data_mover,sys_port以及access_pattern。没有使用mem_attribute是因为编译器会自动判断分配的内存连续与否。上面这段程序使用malloc语句分配内存,那么这段内存就是分页的。类似地,我们也可以用数组来初始化一段内存。
float A[N];
float B[N];
这两种方式分配的内存在物理上都是不连续的,想要分配在物理上连续的内存片段必须使用sds_alloc()语句,内存片段在物理上是否连续对数据传输性能影响很大。
这四条指令加上内存分配语句理论上可以产生2(malloc/sds_alloc) * 2(copy/zero_copy) * 3(DMA_SG/DMA_SIMPLE/FIFO) * 2(RANDOM/ SEQUENTIAL) * 2(AFI/ACP)=48种组合方式,但是各个pragma之间是有依赖关系的,比如,zero_copy和DMA_SIMPLE都必须与sds_alloc()同时使用。此外,RANDOM的assess pattern比较罕见(前面有提到),因此实际上并没有那么多组合。下面我们会比较一下各种能够实现的SDS pragma组合的情况(比如paged +AXIDMA_SIMPLE就无法实现),包括各组合的理论性能,实测性能,资源利用等情况。
| 内存 | 端口 | Datamover | copy | Setup | Transfer | 实测 | FF | LUT |
|---|---|---|---|---|---|---|---|---|
| 1 | 连续 | ACP | SIMPLE | zero | 518 | 10890 | 48907 | 1197 |
| 2 | 连续 | AFI | SIMPLE | zero | 11222 | 20675 | 110623 | 1197 |
| 3 | 连续 | ACP | SG | zero | 518 | 10890 | 48891 | 1197 |
| 4 | 连续 | AFI | SG | zero | 11222 | 20675 | 105411 | 1197 |
| 5 | 连续 | ACP | SIMPLE | copy | 1120 | 10337 | 49912 | 130 |
| 6 | 连续 | AFI | SIMPLE | copy | 12454 | 10546 | 80345 | 130 |
| 7 | 连续 | ACP | SG | copy | 5202 | 15370 | 72418 | 130 |
| 8 | 连续 | AFI | SG | copy | 16242 | 15426 | 104536 | 130 |
| 9 | 分页 | ACP | SG | copy | 28524 | 17532 | 321272 | 130 |
| 10 | 分页 | AFI | SG | copy | 26624 | 18636 | 351497 | 130 |
| 11 | 连续 | GP | FIFO | zero | 518 | 10890 | 48941 | 1197 |
| 12 | 连续 | GP | FIFO | copy | 396836 | 18636 | 580754 | 130 |
| 13 | 分页 | GP | FIFO | copy | 396836 | 18636 | 573677 | 130 |
其中,表1的内存,端口,Datamover,copy,Setup,Transfer由Data Motion Network Report给出,实测在板上测试给出,LUT与FF的使用情况由HLS Report给出,这些内容在附件里有提供,此外我们还提供了不同指令组合对应的Block Diagram。

连续+ACP+SIMPLE+zero_copy对应原理图

连续+HP+SIMPLE+zero_copy对应原理图
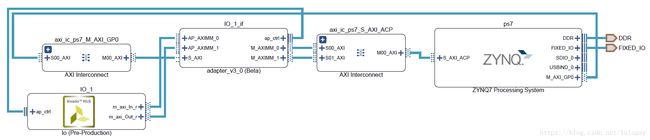
连续+ACP+SG+zero_copy对应原理图
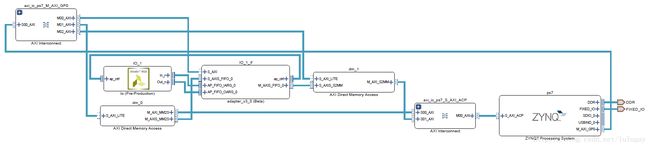
连续+ACP+SIMPLE+copy对应原理图
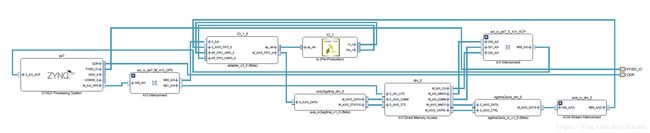
连续+ACP+SG+copy对应原理图

分页+ACP+SG+copy
- 通过分析表1以及各种组合的原理图,我们可以得到如下结论:
- 通过对比7,8和9,10,可知连续内存的性能远强于分页内存性能
- 通过比较1,3,5,7,9和2,4,6,8,10可知ACP端口性能最强,AFI(也就是HP)接口次之,GP接口最差,与前两者性能相差很大。
- 通过对比1,3和2,4,11的Block Diagram(打开Release_sds\p0_vpl\ipi\syn\syn.xpr查看),资源利用情况,Setup时间等,发现zero_copy+SG的zero_copy+SIMPLE的组合完全一致,因此有zero_copy存在的情况下Datamover会强制设置为SIMPLE。
- 通过对比1,2和5,6的Block Diagram,可知使用AXIDMA_SIMPLE时算法加速IP不经过DMA直接连到PS的端口,AXIDMA_SG会生成一个DMA用于数据搬运。二者性能差异不大,但是AXIDMA_SG消耗了更少的FF和LUT。
综上,分配内存时要使用sds_alloc(),数据传输量较小(<8MB)时选择ACP接口,copy与zero_copy性能差距并不大,AXIDMA_SG与AXIDMA_SIMPLE读者可以根据自己需要选择。
欢迎大家关注Xilinx学术合作以及Pynq的官方公众号,里面有许多优质的学习资源等着你哦


希望了解HLS的同学可以关注公众号Xilinx学术合作以及PYNQ中文社区获取最新版《FPGA并行编程-- 以HLS实现信号处理为例》pdf ,关注任一公众号,回复 pp4fpgas 即可获得