Java Thread&Concurrency(4): 深入理解Exchanger实现原理
背景(来自注释):
Exchanger的作用是作为一个同步点,线程通过它可以配对交换数据。
每个线程可以通过exchange方法来传递想要传递的数据,并且返回时接受其他线程传递的数据。一个Exchanger可以看做是双向的SynchronousQueue,经常在遗传算法和管道设计中使用。
使用场景:
下面这个FillAndEmpty类的亮点是,使用Exchanger在两个线程之间交换数据,使得填缓存的线程能够在需要时候得到一个新的空缓存,然后挂起自己直到清缓存的线程清空缓存。
算法的核心是通过一个可交换数据的slot,以及一个可以带有数据item的参与者:
for (;;) {
if (slot is empty) { // offer
place item in a Node;
if (can CAS slot from empty to node) {
wait for release;
return matching item in node;
}
}
else if (can CAS slot from node to empty) { // release
get the item in node;
set matching item in node;
release waiting thread;
}
// else retry on CAS failure
}这种方式在原则上是高效的,但实际上,像许多在单个位置上进行原子更新的算法一样,当许多参与者使用同一个Exchanger时,存在严重的伸缩性问题。所以我们的实现通过引入一个消去数组从而安排不同的线程使用不同的slot来降低竞争,并且保证最终会成对交换数据。这意味着我们不能完全地控制线程之间的划分方式,但是我们通过在竞争激烈时增加arena的范围,竞争变少时减少arena的范围来分配线程可用的下标。我们为了达到这个效果,通过ThreadLocals来定义Node,以及在Node中包含了线程下标index以及相应的跟踪状态。(对于每个线程,我们可以重用私有的Node而不是重新创建一个,因为slot只会通过CAS操作交替地变化(Node VS null),从而不会遇到ABA问题。当然,我们在使用时需要重新设置item)。
为了实现一个高效的arena(场地),我们仅在探测到竞争时才开辟空间(当然在单CPU时我们什么都不做),首先我们通过单个slot的slotExchange方法来交换数据,探测到竞争时,我们会通过arena安排不同位置的slot,并且保证没有slot会在同一个缓存行上(cache line)。因为当前没有办法确定缓存行的尺寸,我们使用对任何平台来说都足够大的值。并且我们通过其他手段来避免错误/非意愿的共享来增加局部性,比如对Node使用边距(via sun.misc.Contended),"bound"作为Exchanger的属性,以及使用区别于LockSupport的重新安排park/unpark的版本来工作。
一开始我们只使用一个slot,然后通过记录冲突次数从而扩展arena的尺寸(冲突:CAS在交换数据时失败)。对于以上算法来说,能够表明竞争的碰撞类型是两个线程尝试释放Node的冲突----线程竞争提供Node的情况是可以合理地失败的。当一个线程在当前arena的每个位置上都失败时,会试着去递增arena的尺寸。我们记录冲突的过程中会跟踪"bound”的值,以及会重新计算冲突次数在bound的值被改变时(当然,在冲突次数足够时会改变bound)。
当arena的可用尺寸大于1时,参与者会在等待一会儿之后在退出时递减arena的可用尺寸。这个“一会儿”的时间是经验决定的。我们通过借道使用spin->yield->block的方式来获得合理的等待性能--在一个繁忙的exchanger中,提供数据的线程经常是被立即释放的,相对应的多cpu环境中的上下文切换是非常缓慢/浪费的。arena上的等待去除了阻塞,取而代之的是取消。从经验上看所选择的自旋次数可以避免99%的阻塞时间,在一个极大的持久的交换速率以及一系列的计算机上。自旋以及退让产生了一些随机的特性(使用一种廉价的xorshift)从而避免了严格模式下会引起没必要的增长/收缩环。对于一个参与者来说,它会在slot已经改变的时候知道将要被唤醒,但是直到match被设置之后才能取得进展。在这段时间里它不能取消自己,所以只能通过自旋/退让来代替。注意:可以通过避免第二次检测,通过改变线性化点到对于match属性的CAS操作,当然这样做会增加一点异步性,以及牺牲了碰撞检测的效果和重用一线程一Node的能力。所以现在的方案更好。
检测到碰撞时,下标逆方向循环遍历arena,当bound改变时会以最大下标(这个位置Node是稀少的)重新开始遍历(当退出(取消)时,下标会收缩一半直到变0)。我们这里使用了单步来遍历,原因是我们的操作出现的极快在没有持续竞争的情况下,所以简单/快速的控制策略能够比精确但是缓慢的策略工作地更好。
因为我们使用了退出的方式来控制arena的可用尺寸,所以我们不能直接在限时版本中抛出TimeoutException异常直到arena的尺寸收缩到0(也就是说只要下标为0的位置可用)或者arena没有被激活。这可能对原定时间有延迟,但是还是可以接受的。
本质上来看所有的实现都存于方法slotExchange和arenaExchange中。这两个有相似的整体结构,但是在许多细节上不同。slotExchange方法使用单个"slot"属性相对于使用arena中的元素。同时它也需要极少的冲突检测去激活arena的构造(这里最糟糕的部分是确定中断状态以及InterruptedException异常在其他方法被调用时出现,这里是通过返回null来检查是否被中断.)
在这种类型的代码中,由于方法依赖的大部分逻辑所读取的变量是通过局部量来维持的,所以方法是大片的并且难以分解--这里主要是通过连在一起的 spin->yield->block/cancel 代码)。以及严重依赖于本身具有的Unsafe机制和内联的CAS操作和相关内存读取操作。注意Node.item不是volatile的,尽管它会被释放线程所读取,因为读取操作只会在CAS操作完成之后才发生,以及所有自己的变量都是以能被接受的次序被其他操作所使用。当然这里也可以使用CAS操作来用match,但是这样会减慢速度)。
实现:
@sun.misc.Contended static final class Node {
int index; // Arena index
int bound; // Last recorded value of Exchanger.bound
int collides; // Number of CAS failures at current bound
int hash; // Pseudo-random for spins
Object item; // This thread's current item
volatile Object match; // Item provided by releasing thread
volatile Thread parked; // Set to this thread when parked, else null
}
/** The corresponding thread local class */
static final class Participant extends ThreadLocal {
public Node initialValue() { return new Node(); }
}
/**
* Per-thread state
*/
private final Participant participant;
/**
* Elimination array; null until enabled (within slotExchange).
* Element accesses use emulation of volatile gets and CAS.
*/
private volatile Node[] arena;
/**
* Slot used until contention detected.
*/
private volatile Node slot; - index----------arena中的下标
- bound---------上一次记录的Exchanger.bound
- collides-------在当前bound下失败的CAS次数(这里指的是release失败)
- hash-----------伪随机数用于自旋
- item------------这个线程的当前项(也就是传递的数据)
- match---------做releasing操作的线程传递的项
- parked--------挂起时设置线程值,其他情况下为null
static final int FULL = (NCPU >= (MMASK << 1)) ? MMASK : NCPU >>> 1; arena = new Node[(FULL + 2) << ASHIFT];
这是为何呢?我们再看如何使用arena中的Node。
Node q = (Node)U.getObjectVolatile(a, j = (i << ASHIFT) + ABASE);
这里的ABASE是:
U = sun.misc.Unsafe.getUnsafe();
Class ak = Node[].class;
ABASE = U.arrayBaseOffset(ak) + (1 << ASHIFT);好了,我们发现也是通过<
在当前的4核CPU下,arena可以用如下图来表示:
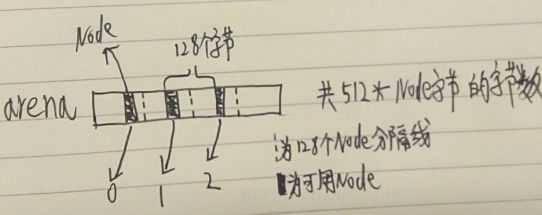
由于最大的缓存行为128个字节,并且Node有sun.misc.Contended来增加padding,所以使得任意两个可用Node不会再同一个缓存行中。
我们接下来看函数调用:
@SuppressWarnings("unchecked")
public V exchange(V x, long timeout, TimeUnit unit)
throws InterruptedException, TimeoutException {
Object v;
Object item = (x == null) ? NULL_ITEM : x;
long ns = unit.toNanos(timeout);
if ((arena != null ||
(v = slotExchange(item, true, ns)) == null) &&
((Thread.interrupted() ||
(v = arenaExchange(item, true, ns)) == null)))
throw new InterruptedException();
if (v == TIMED_OUT)
throw new TimeoutException();
return (v == NULL_ITEM) ? null : (V)v;
}事实上这个限时版本存在一个微妙的bug。注意在slotExchange和arenaExchange中的时间参数ns是同一个,假如一次调用先经过slotExchange,再经过arenaExchange,那么就很可能发生等待时间过长的情况,原因是:U.park(false, ns)这个操作存在莫名其妙返回的可能,根据注释:*
Exchanger
slot:初始以及无竞争状态下使用;
arena[]:竞争状态下使用;
participant:线程独有Node;
/**
* Exchange function used until arenas enabled. See above for explanation.
*
* @param item the item to exchange
* @param timed true if the wait is timed
* @param ns if timed, the maximum wait time, else 0L
* @return the other thread's item; or null if either the arena
* was enabled or the thread was interrupted before completion; or
* TIMED_OUT if timed and timed out
*/
private final Object slotExchange(Object item, boolean timed, long ns) {
Node p = participant.get();
Thread t = Thread.currentThread();
if (t.isInterrupted()) // preserve interrupt status so caller can recheck
return null;
for (Node q;;) {
if ((q = slot) != null) {
if (U.compareAndSwapObject(this, SLOT, q, null)) {
Object v = q.item;
q.match = item;
Thread w = q.parked;
if (w != null)
U.unpark(w);
return v;
}
// create arena on contention, but continue until slot null
if (NCPU > 1 && bound == 0 &&
U.compareAndSwapInt(this, BOUND, 0, SEQ))
arena = new Node[(FULL + 2) << ASHIFT];
}
else if (arena != null)
return null; // caller must reroute to arenaExchange
else {
p.item = item;
if (U.compareAndSwapObject(this, SLOT, null, p))
break;
p.item = null;
}
}
// await release
int h = p.hash;
long end = timed ? System.nanoTime() + ns : 0L;
int spins = (NCPU > 1) ? SPINS : 1;
Object v;
while ((v = p.match) == null) {
if (spins > 0) {
h ^= h << 1; h ^= h >>> 3; h ^= h << 10;
if (h == 0)
h = SPINS | (int)t.getId();
else if (h < 0 && (--spins & ((SPINS >>> 1) - 1)) == 0)
Thread.yield();
}
else if (slot != p)
spins = SPINS;
else if (!t.isInterrupted() && arena == null &&
(!timed || (ns = end - System.nanoTime()) > 0L)) {
U.putObject(t, BLOCKER, this);
p.parked = t;
if (slot == p)
U.park(false, ns);
p.parked = null;
U.putObject(t, BLOCKER, null);
}
else if (U.compareAndSwapObject(this, SLOT, p, null)) {
v = timed && ns <= 0L && !t.isInterrupted() ? TIMED_OUT : null;
break;
}
}
U.putOrderedObject(p, MATCH, null);
p.item = null;
p.hash = h;
return v;
}- 通过participant取得当前线程私有Node。
- 当slot不为空时,尝试消去slot:成功返回数据;失败之后创建arena消去数组,这里的bound从0到256用于第一次改变,然后重试(很可能进入arena逻辑,或者消去最后一次被占领的slot)。
- 假如arena不为空,则返回null,进入arenaExchange的逻辑(受到上一条的影响)。
- 否则,当前q(slot)为空,尝试占领,失败重试,成功之后跳出当前,进入spin+block模式:
- (假若当前是限时版本)取得结束时间和自旋次数,进入自旋+阻塞逻辑:
- 当match为null时候首先尝试spins+随机次自旋(改自旋使用当前节点中的hash,并改变之)和退让。
- 自旋数为0后,假如slot改变则重置自旋数并重试。
- 否则假如:当前未中断&arena为null&(当前不是限时版本或者限时版本+当前时间未结束):阻塞或者限时阻塞。
- 假如:当前中断或者arena不为null或者当前为限时版本+时间已经结束:不限时版本:置v为null;限时版本:如果时间结束以及未中断则TIMED_OUT;否则给出null(原因是探测到arena非空或者当前线程中断)。
- match不为空时跳出循环。
- 返回v(这一步也处理取得结果的情况)。
/**
* Exchange function when arenas enabled. See above for explanation.
*
* @param item the (non-null) item to exchange
* @param timed true if the wait is timed
* @param ns if timed, the maximum wait time, else 0L
* @return the other thread's item; or null if interrupted; or
* TIMED_OUT if timed and timed out
*/
private final Object arenaExchange(Object item, boolean timed, long ns) {
Node[] a = arena;
Node p = participant.get();
for (int i = p.index;;) { // access slot at i
int b, m, c; long j; // j is raw array offset
Node q = (Node)U.getObjectVolatile(a, j = (i << ASHIFT) + ABASE);
if (q != null && U.compareAndSwapObject(a, j, q, null)) {
Object v = q.item; // release
q.match = item;
Thread w = q.parked;
if (w != null)
U.unpark(w);
return v;
}
else if (i <= (m = (b = bound) & MMASK) && q == null) {
p.item = item; // offer
if (U.compareAndSwapObject(a, j, null, p)) {
long end = (timed && m == 0) ? System.nanoTime() + ns : 0L;
Thread t = Thread.currentThread(); // wait
for (int h = p.hash, spins = SPINS;;) {
Object v = p.match;
if (v != null) {
U.putOrderedObject(p, MATCH, null);
p.item = null; // clear for next use
p.hash = h;
return v;
}
else if (spins > 0) {
h ^= h << 1; h ^= h >>> 3; h ^= h << 10; // xorshift
if (h == 0) // initialize hash
h = SPINS | (int)t.getId();
else if (h < 0 && // approx 50% true
(--spins & ((SPINS >>> 1) - 1)) == 0)
Thread.yield(); // two yields per wait
}
else if (U.getObjectVolatile(a, j) != p)
spins = SPINS; // releaser hasn't set match yet
else if (!t.isInterrupted() && m == 0 &&
(!timed ||
(ns = end - System.nanoTime()) > 0L)) {
U.putObject(t, BLOCKER, this); // emulate LockSupport
p.parked = t; // minimize window
if (U.getObjectVolatile(a, j) == p)
U.park(false, ns);
p.parked = null;
U.putObject(t, BLOCKER, null);
}
else if (U.getObjectVolatile(a, j) == p &&
U.compareAndSwapObject(a, j, p, null)) {
if (m != 0) // try to shrink
U.compareAndSwapInt(this, BOUND, b, b + SEQ - 1);
p.item = null;
p.hash = h;
i = p.index >>>= 1; // descend
if (Thread.interrupted())
return null;
if (timed && m == 0 && ns <= 0L)
return TIMED_OUT;
break; // expired; restart
}
}
}
else
p.item = null; // clear offer
}
else {
if (p.bound != b) { // stale; reset
p.bound = b;
p.collides = 0;
i = (i != m || m == 0) ? m : m - 1;
}
else if ((c = p.collides) < m || m == FULL ||
!U.compareAndSwapInt(this, BOUND, b, b + SEQ + 1)) {
p.collides = c + 1;
i = (i == 0) ? m : i - 1; // cyclically traverse
}
else
i = m + 1; // grow
p.index = i;
}
}
}- 取得arena值(必定不为空),取得当前线程的node,根据其中的index(初始为0)去定位arena中的node。
- 如果取得的q不为空并且CAS操作成功,则交换数据,唤醒线程并返回数据。
- 否则假如当前下标i在范围之内(bound & MMASK)并且q为空,则尝试在i上占领node,若成功:则采取与slotExchange中类似的自旋+阻塞方式,区别在于:之前的arena == null探测换成了m=0(只在m为0时允许阻塞,当然只会在index为0的slot上阻塞);以及在 中断/超时/当前m值不为0的情况下的自我消去:假如m不为0则递减bound的值(通过+SEQ-1),shrink节点下标index,假如中断则返回null,假如超时则返回TIMED_OUT,否则break尝试另一个节点。
- 当我们因为下标不在范围内或者由于q不为空但是竞争失败的时候:假如节点bound不为当前的bound则更新i(为m或者m-1,即从最高index开始寻);如果冲突次数不到m或者m已经最大FULL或者修改当前bound的值失败:我们增加一次collides以及循环递减下标i的值;否则更新当前bound的值成功:我们令i为m+1即为此时最大的下标。最后更新当前index的值。
存在的问题: