Hadoop 全分布配置还算蛮详细的步骤整理
Fedora下的Hadoop 全分布配置详细步骤整理
(当前配置环境:虚拟机:vmware workstation 11
系统:fedora (其实fedora和ubuntu操作步骤一模一样,就是在给新建用户分配权限那一步有点不一样之外)
一台从机
fedora中已安装jdk1.8.0_11和hadoop-1.2.1,并已配置环境变量
正式开始前,可以先拍摄快照或者压缩fedora进行备份,本人觉得这是个好习惯)
安装步骤:
1、安装虚拟机系统,本人是将之前安装好的进行了克隆)
2.修改各个虚拟机的hostname和host
3.创建用户组和统一用户
4、配置虚拟机网络,使虚拟机系统之间以及和host主机之间可以通过相互ping通。
5.安装jdk和配置环境变量,检查是否配置成功(此步由于之前已经配置过就不详细赘述了)
6、配置ssh实现节点间的无密码登录 ssh node1指令验证时候成功
7、主机master配置hadoop,再将hadoop文件copy到node1节点
8、配置环境变量,并启动hadoop,检查是否安装成功
接下来的(1)-(6)操作在主机从机都要进行:
(1)修改各个虚拟机的hostname
gedit /etc/hostname
主机 master ;
从机一台 node1 ;
(2)修改各个虚拟机的hosts
gedit /etc/hosts
在gedit编辑器中填入当前ip地址(注意ip地址每断网一次若新连接网络则会变化,若变了则在此处改为相应的最新ip地址。/sbin/Ifconfig-a 查询ip地址),
10.10.31.115 master
10.10.31.126 node1
(3)
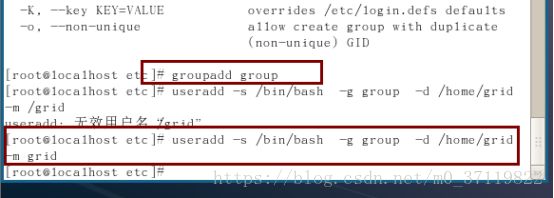
groupadd group
建组 假如名叫group ;
useradd grid
建统一用户 假如名叫grid ;
设置新用户grid 的密码:
passwd grid
【此处我拍摄了快照】
注:删除新建的用户可用
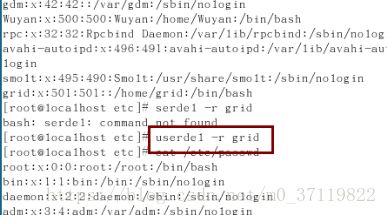
(4)
设置管理权限
sudo gedit /etc/sudoers
按回车键后就会打开/etc/sudoers文件了,给hadoop用户赋予root用户同样的权限
找到root ALL=(ALL:ALL) ALL在其下添加
grid ALL=(ALL:ALL) ALL
(5)
重启虚拟机,并用grid用户登陆
输入命令
/sbin/ifconfig -a
确认ip地址未改变,ping通
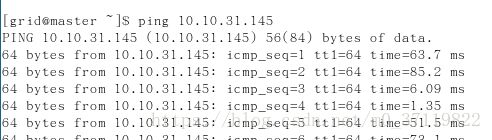
在主机输入
ping node1
或者
ping 当前node1的ip
(6)配置ssh,实现节点间的无密码登录
大部分的linux中都已经安装好ssh,可输入命令查询:
which ssh //查路径

配置可以无密码登陆本机:
首先查看在grid用户根目录下查看是否存在.ssh这个隐藏的文件夹(注意ssh前面有“.”),输入命令:
ls –a /home/grid

接下来,输入命令,生成密钥:(此处rsa有可能是dsa,取决于你的虚拟机系统的算法)
ssh-keygen -t rsa
注:查看算法的命令:(在.ssh文件下)
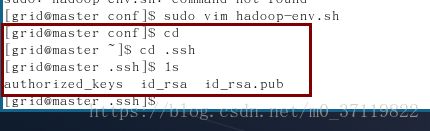
输入之后一直选择enter即可,生成的密钥位于 ~/.ssh文件夹下。可用cd 命令进入查看。
接下来的操作仅在主机master上进行:
(7)在master上,导入authorized_keys
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
(8)远程无密码登录(把master上的.ssh整个文件拷贝到从机node1的相应目录下)
#进入master的.ssh目录,执行复制操作(此步要求先在node1从机上新建一个空的.ssh文件)
scp * grid@node1:~/.ssh/
下一步操作在主机-从机同时进行:
(9)修改各台主机上authorized_keys文件的权限:
所有机器上,均执行命令:
chmod 644 .ssh/authorized_keys
完成之后,在master主机上执行下面操作,检查免密码登录是否成功:
ssh node1

在node1从机上执行下面操作,检查免密码登录是否成功:
ssh master
(10)仅在master主机上
配置hadoop
配置文件:如下图圈出的文件(文件都在/usr/hadoop/conf中)
cd /usr/hadoop/conf
ls

在conf目录下依次操作:
sudo vim core-site.xml

sudo vim mapred-site.xml
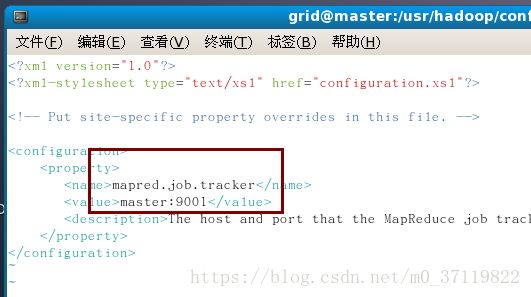
sudo vim hdfs-site.xml
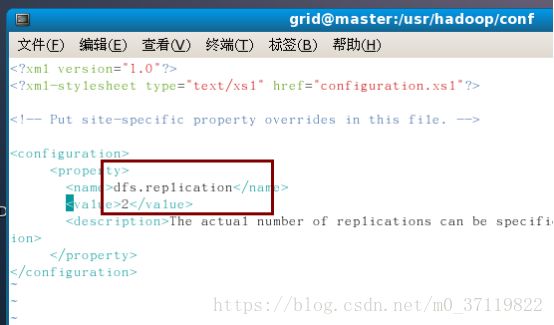
//注意此处的2表示这个机群有两台机器,若有三台则改为3
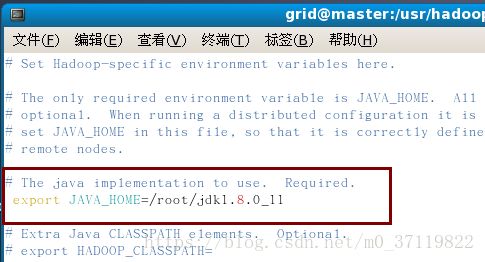
sudo vim hadoop-env.sh
sudo vim masters
在masters里将内容改为 master
sudo vim slaves
在slaves 里将内容改为 node1
(11)在主机上操作:
将配置好的hadoop传输到node1 的根目录
scp -r /usr/hadoop @node1:/
(12)分别在主机master,从机 node1,进入hadoop安装目录
bin/hadoop namenode -format //正式启动前,格式化hadoop
sbin/start-all.sh //全部开始
启动后输入
sudo jps //查看进程
看到下面的结果,则表示成功:
主机:
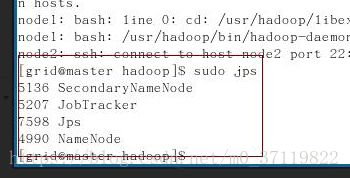
从机:
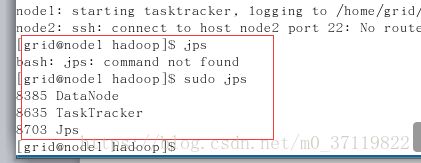
至此,全分布配置完成。
本人属于菜鸟一类,是个非常新的新手,还在入门的边缘,此次配置全分布遇到了无数个问题,基本上是步步出错,还好有班里大神帮助,在此道一声感谢。因此特意在成功之后,将整个步骤详细整理了一遍,并注明了可能容易出的错误,若诸位路过时发现有误之处欢迎指正,谢谢~
吴言
2018/4/26
配置全分布有感......