TCP/IP网络编程_基于Linux的编程_第18章多线程服务器端的实现

18.1 理解线程的概念
第19章将介绍 Windows 线程, 而本章给出的是关于线程的通用说明, 掌握了本章内容才能学好 Windows 线程.
引入线程的背景
第10章介绍了多进程服务器端的实现方法. 多进程模型与 select 或 epoll 相比的确有自身的优点, 但同时也有问题. 如前所述, 创建进程(复制)的工作本身会给操作系统带来相当承重的负担. 而且, 每个进程具有独立的内存空间, 所以进程间通信的实现难度也会随之提高(参考第11章). 换言之, 多进程模型的缺点可概括如下.

但相当于下面的缺点, 上述 2个缺点不算什么
只有一个 CPU (准确地说是 CPU 的运算设备 CORE) 的系统中不是也可以同时运行多个进程吗? 这是因为系统将 CPU 时间分成多个微小的块后分配给了多个进程. 为了分时 使用 CPU, 需要 “上下文切换” 的过程. 下面了解一下 “上下文切换” 的概念. 运行程序前需要将相应的进程信息读入内存, 如果运行进程A后需要紧接着运行进程B, 就应该将进程A相关信息移出内存, 并读入进程B相关信息. 这就是上下文切换. 但此时进程A的数据将移动到硬盘, 所以上下文切换需要很长时间. 即使通过优化加速速度, 也会存在一定局限.

为了保持多进程的优点, 同时在一定程度上克服其缺点, 人们引入线程(Thread). 这是为了将进程的各种劣势降至最低程度(不是直接消除) 而是设计的一种"轻量级进程". 线程相比于进程具有如下优点.

各位会逐渐体会这些优点, 可以通过接下来的说明和线程相关代码进行准确理解.
线程和进程的差异
线程是为了解决如下困惑登场的:
![]()
每个进程的内存空间都由保存全局变量的 “数据区”, 向malloc 等函数的动态分配提供空间的堆(Heap), 函数运行时使用的栈(Stack)构成. 每个进程都拥有独立空间, 多个进程的内存结构如图18-1 所示.

但如果以获得多个代码执行流为主要目的, 则不应该像图18-1那样完全分离内存结构, 而只需分离栈区域. 通过这种方式可以获得如下优势.

实际上这是线程. 线程为了保持多条代码执行流而隔开了栈空间, 因此具有如图 18-2 所示的内存结构.
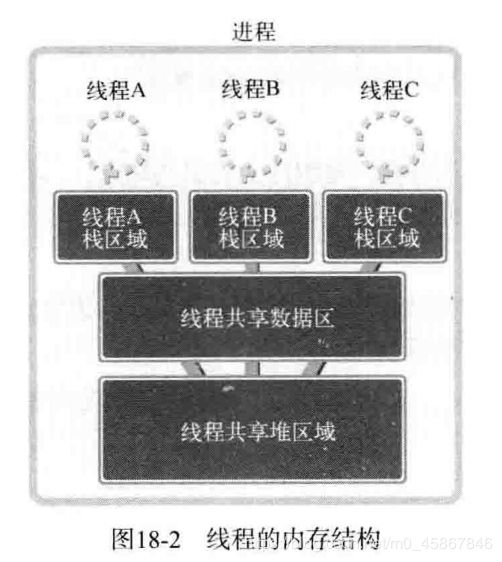
如图 18-2 所示, 多个线程将共享数据区和堆. 为了保持这种结构, 线程将在进程内创建并运行. 也就是说, 进程和线程可以定义如下形式.

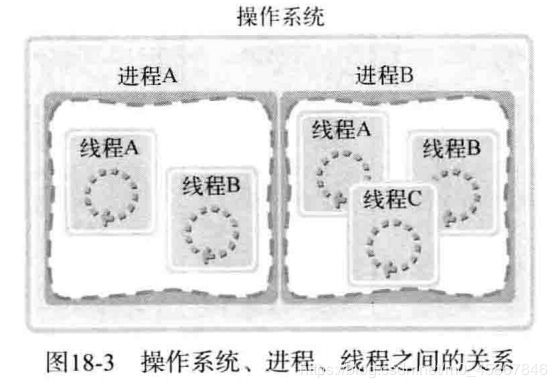
如果说进程在操作系统内部生成多个执行流, 那么线程就在同一进程内部创建多条执行流. 因此, 操作系统, 进程, 线程之间的关系可以通过图18-3表示.
以上就是线程的理论说明. 没有实际编程就很难理解好线程, 希望各位通过学习线程相关代码理解全部内容.
18.2 线程创建及运行
POSIX 是 Portable Operatin System Interface for Computer Environment (适用于计算机环境的可移植操作系统接口) 的简写, 是为了提高 UNIX 系列操作系统间的移植性而制定的API规范. 下面介绍的线程创建方法也是以 POSIX 标准为依据的. 因此, 它不仅适用于 Linux , 也适用于大部分 UNIX 系列的操作系统.
线程的创建和执行流程
线程具有单独的执行流, 因此需要单独定义线程的 main 函数, 还需要请求操作系统在单独的执行流中执行该函数, 完成该功能的函数如下.

要想理解好上述函数的参数, 需要熟练掌握 restrict 关键字和函数指针相关语句. 但如果只关注使用方法(当然以后要掌握 restrict 和函数指针), 那么该函数的使用比想象中要简单. 下面通过简单示例了解函数的功能.

#include 

从上述运行结果中可以看到, 线程相关代码在编译时需要添加 -lpthread 选项声明需要连接线程库, 只有这样才能调用头文件 pthread.h 中声明的函数. 上述程序的执行流程如图 18-4所示.
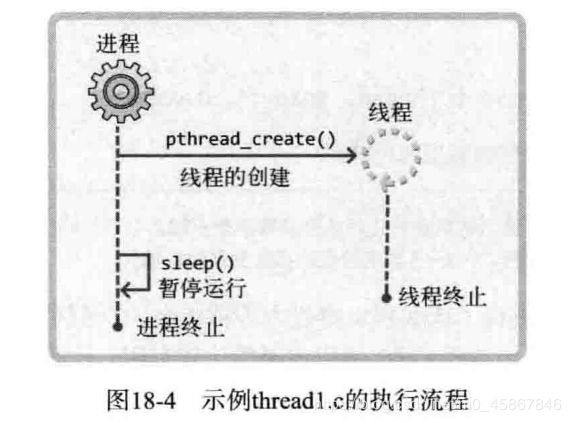
图18-4的虚线代表执行流程, 向下的箭头值的是执行流, 流向箭头是函数调用. 这些都是简单的符合, 可以结合实例理解. 接下来将上述示例的第15行 sleep 函数的调用语句改成如下形式:

各位运行后可以看到, 此时不会像代码中写的那样输出5次 “runnig thread” 字符串. 因为 main 函数返回后整个进程将 被销毁, 如图 18-5 所示.
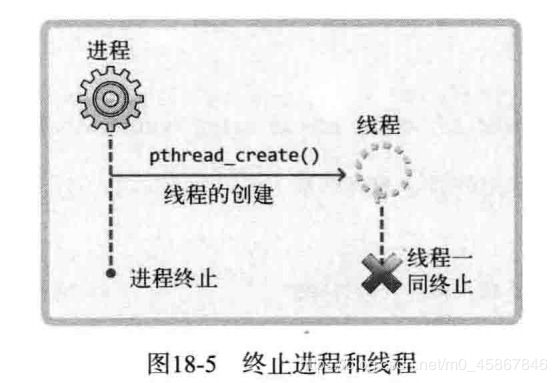
正因如此, 我们在之前的示例中通过调用 sleep 函数向线程提供充足的执行时间.
![]()
并非如此! 通过调用 sleep 函数控制线程的执行相当于预测程序的执行流程, 但实际上这不可能完成的事情. 而且稍有不甚, 很可能干扰程序的正常执行流. 例如, 怎么可能在上述事例中准确预测 thread_main 函数的运行时间, 并让 main 函数恰好等待这么长时间呢? 因此, 我们不用 sleep 函数, 而是通常利用下面的函数控制线程执行流. 通过下列函数可以更有效解决讨论的问题, 还同时了解线程 ID 的用法.

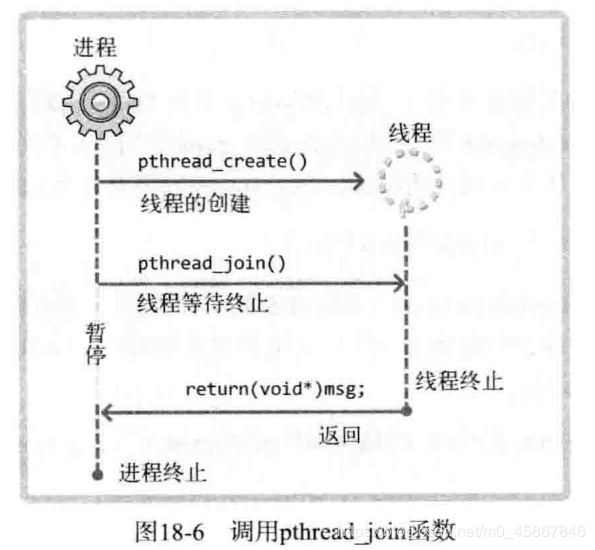
简言之, 调用该函数的进程(或线程) 将进入等待状态, 直到第一个参数为 ID 的线程终止为止. 而且可以得到线程的 main 函数返回值, 所以该函数比较有用. 下面通过实例了解函数的功能.

#include 运行结果:


最后, 为了让大家更好的理解该示例, 给出其执行流程图, 如图18-6 所示. 请注意观察程序暂停后从线程终止时(线程main函数返回时) 重新执行的部分.
可在临界区内调用的函数
之前的示例中只创建了一个线程,接下来的示例将开始创建多个线程. 当然. 无论创建多少线程, 其创建方法没有区别. 但关于线程的运行需要考虑 “多个线程同时调用函数时(执行时可以产生问题)”. 这类函数内部存在临界区(Critiacl Section), 也就是说, 多个线程同时执行这部分代码时, 可以引起问题. 临界区中至少存在1条这类代码 .
稍后将讨论哪些代码可能成为临界区, 多个线程同时执行临界区代码时会产生哪些问题等内容. 现阶段只需理解临界区的概念即可. 根据临界区是否引起问题, 函数可分为以下2类.

线程安全函数被多个线程同时调用时也不会引发问题. 反之, 非线程安全函数被同时调用时会引发问题. 但这并非关于有无临界区的讨论, 线程安全的函数中同样可能存在临界区. 只是在线程安全函数中, 同时被多个线程调用时可通过一些措施避免问题.
幸运的是, 大多数标准函数都是线程安全函数. 更幸运的是, 我们不用自己区分线程安全的函数和非线程安全的函数(在 Windows 程序中同样如此). 因为这些平台的定义非线程安全函数的同时, 提供了具有相同功能的线程安全的函数. 比如, 第8章介绍的如下函数就不是线程安全的函数:
![]()
同时提供线程安全的同一功能的函数.

线程安全函数的名称后缀通常 _r (这与 Windows 平台不同). 既然如此, 多个线程同时访问的代码块中应调用 gethostbyname_r, 而不是 gethostbyname? 当然! 这种方法给程序员带来承重的负担. 幸好可以通过如下方法自动将 gethostbyname 函数调用 改为 gethostbyname_r 函数调用!

gethosbyname 函数和gethostbyname_r 函数的函数名和参数声明都不同, 因此, 这种宏声明方式拥有巨大吸引力. 另外, 无需为了上述宏定义特意添加 #define 语句, 可以在编译时通过添加 -D_REENTRANT 选项定义宏.
下面编译线程相关代码时默认添加 -D_REETRANT 选项.
工作 (Worker) 线程模型
之前示例的主要是介绍线程概念和创建线程的方法, 因此从未涉及1个示例中创建多个线程的情况. 下面给出此类示例.
将要介绍的示例将计算机1到10的和, 但并不是在main 函数中进行累加运算, 而是创建2个线程, 其中一个线程计算1到5的和, 另一个线程计算6~10的和, main 函数只负责输出运算结果. 这种方式的编程模型称为 “工作线程(Worker thread) 模型”. 计算机1到5之和好的线程与计算机6到10之和的线程将成为 main 线程管理的工作(Worker). 最后, 给出示例代码前先给出程序执行流程图, 如图 18-7 所示.

之前也介绍过类似的图, 相信各位很容易看懂图 18-7 的描述的内容(只是单纯说明图, 并未使用特殊的表示方法). 另外, 线程相关代码的执行流程理解起来相对负责一些, 有必要习惯于这类流程图.

#include 之前讲过线程调用函数的参数和返回值类型, 因此不难理解上述示例中创建线程并执行的部分. 但需要注意:
![]()
通过上述示例的第28行可以得出这种结论. 从代码的角度看似乎理所应当, 但之所以可行完全是因为2个线程共享保存全局变量的数据区.
![]()

运行结果是55, 虽然正确, 但示例本身存在问题. 此处存在临界区相关问题, 因此再介绍另一示例. 该示例与上述示例相似, 只是增加了发生临界区相关错误的可能性, 即使在高配置系统环境下也很容易验证产生的错误.

#include 上述示例中共创建了10个线程, 其中一半执行 thread_inc 函数中的代码, 另一半则执行 thread_des 函数中的代码. 全局变量 num 经过增减过程应存有0, 通过运行结果观察是否真能得到.
![]()
运行结果并不是0! 而且每次运行的结果均不同. 虽然其原因尚不得而知, 但可以肯定的是, 这对于线程的应用是大问题.
18.3 线程存在的问题和临界区
我们还不知道示例 thread4.c 中产生的问题的原因, 下面分析该问题并给出解决方案.
多线程访问同一变量是问题
示例 thread4.c 的问题如下:
![]()
此处的 “访问” 是指值的更改. 产生问题的原因可能还有很多, 因此需要准确理解. 虽然示例中访问的对象是全局变量, 但这并非全局变量引发的问题. 任何内存空间-只要被同时访问–都会可能发生问题.
![]()
当然, 此处的 “同时访问” 与各位所想也有一定区别. 下面通过示例解析 “同时访问” 的含义, 并说明为何会引发问题. 假设2个线程要执行将变量值逐次加1 工作, 如图 18-8 所示.
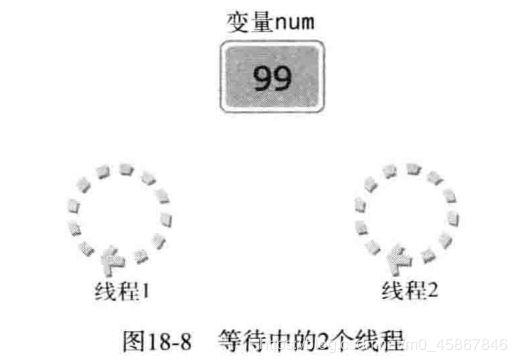
图18-8中描述的是2个线程准备将变量 num 的值加1的情况. 在此情况下, 线程1 将变量num 的值 整到100 后, 线程2再访问 num 时, 变量 num 中按照我们的预想保存101. 图 18-9 是线程1将 变量num 完全增加后的情形.
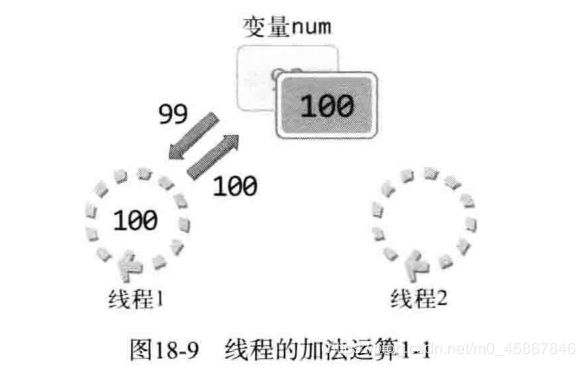
图 18-9 中需要注意值的增加方式, 值的增加需要CPU运算完成, 变量 num 中的值不会自动增加. 线程1首先读取该变量的值并将其传递到 CPU, 获得加1后的结果 100, 最后再把 结构写回变量 num, 这样 num 中就保存100. 接下来给出线程2的执行过程, 如图 18-10 所示.
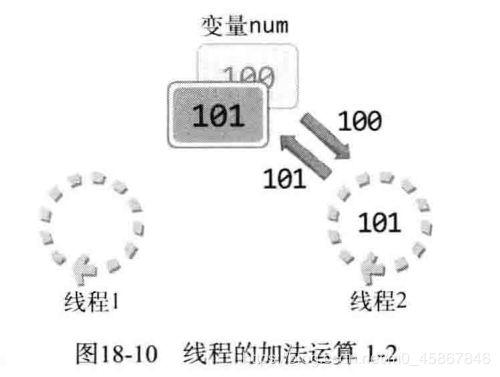
变量 num 中将保存101, 但这是最理想的情况. 线程1完全增加 num 值之前, 线程2完全有可能通过切换得到 CPU 资源. 下面从从头再来. 图18-11 描述的是线程1读取变量 num的值并完成加1运算时的情况, 只是加1后的结果尚未写入变量 num.

接下来就要将 100 保存到变量 num 中, 但执行该操作前, 执行流程跳到了线程2. 幸运的是(能否真正幸运稍后再轮), 线程2完成了加1运算, 并将加1后的结果写入变量 num , 如图 18-12所示.

从图 18-12 中可以看到, 变量 num 的值尚未被线程1加到100, 因此线程2读到的变量num 的值为 99, 结果是线程2将 num 值改成 100. 还剩下线程1将运算后的值写入变量 num 的操作. 接下来给出该过程, 如图18-13所示.
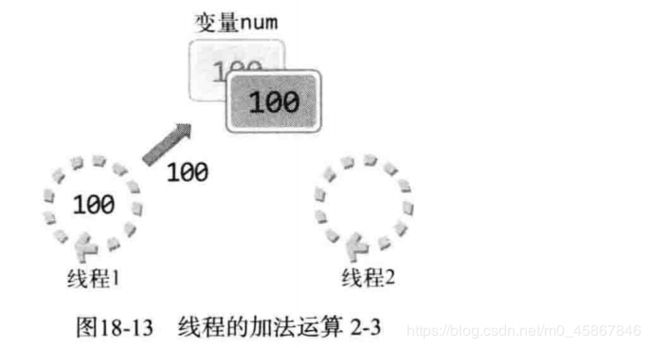
很可惜, 此时线程1将自己的运算结果100再次写入变量 num , 结果变量 num 变成100. 虽然线程1和线程2各做1次运算, 却得到了意想不到的结果. 因此, 线程访问变量 num 时应该阻止其他线程访问, 直到线程1完成运算. 这就是同步(Synchronization). 相信各位也意识到了多线程编程中 “同步” 的必要性, 且能够理解 thread4.c 的运行结果.
临界区位置
划分临界区并不难. 既然临界区定义为如下这种形式, 那就在示例 thread4.c 中寻求.
![]()
全局变量 num 是否应该视为临界区? 不是! 因为它不是引起问题的语句. 该变量并非同时运行的语句, 只是代表内存区域的声明而已. 临界区通常位于由线程运行的函数内部. 下面观察示例 thread4.c 中的两个函数.

由代码注析可知, 临界区并非 num 本身, 而是访问 num的2条语句. 这2条语句可能由多个线程同时运行, 也是引起问题的直接原因. 产生的问题可以整理为如下3种情况.

需要关注最后一点, 它意味着如下情况也会引发问题:

也就是说, 2条不同语句由不同线程同时执行时, 也有可能构成临界区. 前提是这2条语句访问同一内存空间.
18.4 线程同步
前面探讨了线程中存在的问题, 接下来就要讨论解决方法–线程同步.
同步的两面性
线程同步用于解决线程访问顺序访问引发的问题. 需要同步的情况可以从如下两个方面考虑.

之前已解析过前一种情况, 因此重点讨论第二种情况. 这是 "控制(Control)线程执行顺序"的相关内容. 假设有A, B 两个线程, 线程A负责向指定内存空间写入(保存)数据, 线程B负责取走该数据. 这种情况下, 线程A首先应该访问约定的内存空间并保存数据. 万一线程B先访问并取走数据, 将导致错误结果. 想这种需要控制执行顺序的情况也需要使用同步技术.
稍后将介绍 "互斥量(Mutex) 和 “信号量(Semaphore)” 这2种同步技术. 二者概念上十分接近, 只要理解了互斥量就很容易掌握信号量. 而且大部分同步技术的原理都大同小异, 因此, 只要掌握了本章介绍的同步技术, 就很容易掌握并运用 Windows 平台下的同步技术.
互斥量
互斥量是 “Mutual Exclusion” 的简写, 表示不允许多线程同时访问. 互斥量主要用于解决线程同步访问的问题. 为了理解好互斥量, 请观察如下对话过程.

相信各位也猜到了上述对话发生的场景. 现实世界中的灵界区就是洗手间. 洗手间无法同时容纳多人 (比作线程), 因此可以将临界区比喻洗手间. 而且这里发生的所有事情几乎可以全部套用临界区同步过程. 洗手间使用规则如下.

这就是洗手间的使用规则. 同样, 线程中为了保护临界区也需要套用上述规则. 洗手间中存在, 但之前的线程实例中缺少的是什么呢? 就是锁机制. 线程同步同样需要锁, 就像洗手间实例中使用的那样. 互斥量就是一把优秀的锁, 接下来介绍互斥量的创建及销毁函数.


从上述函数声明中也可看出, 为了创建相当于锁系统的互斥量, 需要声明如下 pthread_mutex_t 变量:

该变量的地址传递给 pthread_mutex_init 函数, 用来保存操作系统创建的互斥量(锁系统). 调用 pthread_mutex_destroy 函数时同样需要该信息. 如果不需要配置特殊的互斥量属性, 则向第二个参数传递 NULL 时, 可以利用PTHREAD_MUTEX_INITIALIZER 宏进行如下声明:
![]()
但推荐各位尽可能使用 pthread_mutex_init 函数进行初始化, 因为通过宏进行初始化时很难发现的错误, 接下来介绍利用互斥量锁住或释放临界区时使用的函数.

函数名本身含有lock, unlock 等词汇, 很容易理解其含义. 进入临界区前调用的函数就是 pthread_mutex_lock. 调用该函数时, 发现有其他线程已进入临界区, 则 pthread_mutex_lock 函数不会返回, 直到里面的线程调用 pthread_mutex_unlock 函数退出临界区为止. 也就是说, 其他线程让出临界区之前, 当前线程将一直处于 阻塞状态. 接下来整理一下保护临界区的代码块编写方法. 创建好互斥量的前提下, 可以通过如下结构保护临界区.

简言之, 就是利用 lock 和 unlock 函数围住临界区的两端. 此时互斥量相当于一把锁, 阻止多个线程同时访问. 还有一点需要注意, 线程退出临界区时, 如果忘了调用 pthread_mutex_unlock 函数, 那么其他为进入临界区而调用 pthread_mutex_lock 函数的线程就无法摆脱阻塞状态. 这种情况称为 “死锁(Dead-lock)”, 需要格外注意. 接下来利用互斥解决示例 thread4.c 中遇到的问题.
#include 

从运行结果可以看出, 已解决了示例 thread4.c 中的问题. 但确认运行结果需要等待较长的时间. 因为互斥量lock, unlock 函数调用过程要比想象中花费更长时间. 首先分析一下 thread_inc 函数的同步过程.

以上临界区划分范围较大, 但是考虑到如下优点所做的决定:
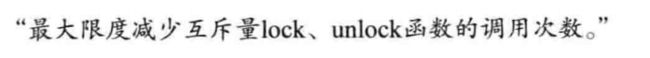
上述示例中, therad_des 函数比 thread_inc函数多调用 49,999,999 次互斥量 lock, unlock 函数, 表现出人感知的速度差别. 如果不太关注线程的等待时间, 可以 适当扩展临界区. 但变量 num 的值增加到 50,000,000 前不允许其他线程访问, 这反而成了缺点. 其实这里没有正确答案, 需要根据不同程序考虑究竟扩大还是缩小临界区. 此处没有公式可言, 各位需要培养自己的判断能力.
信号量
下面介绍信号量. 信号量与互斥量极为相似, 在互斥量的基础上很容易理解信号量. 此处只涉及利用 “二进制信号量”(只用0和1) 完成 “控制线程顺序” 为中心的同步方法. 下面给出信号量创建及销毁方法.

上述函数的 pshared 参数超过了我们关注的范围, 故默认向其传递0. 稍后讲解通过 value 参数初始化的信号量值究竟是多少. 接下来介绍信号量中相当于互斥量 lock , unlock 函数.

调用 sem_init 函数时, 操作系统将创建信号量对象, 此对象中记录着 “信号量值” (SemaphoreValue) 整数. 该值在调用 sem_post 函数时增1, 调用 sem_wait 函数时减一. 但信号量的值不能小于0, 因此, 在信号量为0的情况下调用 sem_wait 函数时, 调用函数的线程将进入阻塞状态(因为函数未返回). 当然, 此时如果有其他线程调用 sem_post 函数, 信号量的值将变为1, 而原本阻塞的线程可以将信号量重新减为0并跳出阻塞状态. 实际上就是通过这种特性完成临界区的同步操作, 可以通过如下形式同步临界区(假设信号量的初始值为1).

上述代码结构中, 调用 sem_wait 函数进入临界区的线程在调用 sem_post 函数前不允许其他线程进入临界区. 信号量的值在0和1之间跳转, 因此, 具有这种特性的机制称为 “二进制信号量”. 接下来给出信号量相关示例. 即将介绍的示例并非关于同时的同步, 而是关于控制访问顺序的同步. 该示例的场景如下:

为了按照上述要求构建程序, 应按照线程A, 线程B的顺序访问变量 num , 且需要线程同步. 接下来给出示例, 分析该示例可能需要花费的一定时间.

#include 
如果各位还不太理解为何需要2个信号量, 可将代码中的注释部分去掉, 再运行程序并观察运行结果. 上述就是线程相关的全部理论知识, 下面在此基础上编写服务器端.
18.5 线程的销毁和多线程并发 服务器端的实现
我们之前只讨论了线程的创建和控制, 而线程的销毁同样重要. 下面先介绍线程的销毁, 再实现多线程服务器端.
销毁线程的 3 种方法
Linux 线程并不是首次调用的线程 main 函数返回时自动销毁, 所以如下2种方法之一加以明确. 否则由线程创建的内存空间一直存在.

之前调用过 pthread_join 函数. 调用该函数时, 不仅会等待线程终止, 还会引导线程销毁. 但该函数的问题是, 线程终止前, 调用该函数的线程将进入阻塞状态. 因此, 通常通过如下函数调用引导线程销毁.

调用上述函数不会引起线程终止或进入阻塞状态, 可以通过该函数引导销毁线程创建的内存空间. 调用该函数后不能再针对相应调用 pthread_join 函数, 这需要格外注意. 虽然还有方法在创建线程是可以指定销毁时机, 但与 pthread_detach 方式相比, 结果上没有太大差异, 故省略其说明. 下面的多线程并发服务器端的实现过程中, 希望各位同样关注线程销毁的部分.
多线程并发服务器端的实现
本节并不打算介绍回声服务器端, 而是介绍多个客户端之间可以交换信息的简单的聊天程序. 希望各位通过本示例复习线程的使用方法及同步的处理方法, 还可以再次思考临界区的处理方式.
无论服务器端还是客户端, 代码都不少, 故省略可以从其他示例中得到或从源代码中下载的头文件声明, 同时最大程度地减少异常处理的代码.

#include \n" , argv[0]);
exit(1);
}
serv_sock = socket(PF_INET, SOCK_STREAM, 0);
memset(&serv_adr, 0, sizeof(serv_adr));
serv_adr.sin_family = AF_INET;
serv_adr.sin_addr.s_addr = htonl(INADDR_ANY);
serv_adr.sin_port = htons(atoi(argv[1]));
if (bind(serv_sock, (struct sockaddr*)&serv_adr, sizeof(serv_adr)) == -1)
{
error_hangling("bind() error");
}
if (listen(serv_sock, 5) == -1)
{
error_hangling("listen() error");
}
while (1)
{
clnt_adr_sz = sizeof(clnt_adr);
clnt_sock = accept(serv_sock, (struct sockaddr*)&clnt_adr, &clnt_adr_sz);
pthread_mutex_lock(&mutx);
clnt_socks[clnt_cnt++] = clnt_sock; /* 55: 每当有新的连接时, 将相关信息写入变量clnt_cnt和clnt_socks. */
pthread_mutex_unlock(&mutx);
pthread_create(&t_id, NULL, handle_clnt, (void*)&clnt_sock); /* 58: 创建线程向新接入的客户端提供服务. 由该线程执行第行定义67行定义的函数. */
pthread_detach(t_id); /* 59: 调用pthread_detach 函数从内存中完全销毁已终止的线程. */
printf("Connected client IP: %s \n", inet_ntoa(clnt_adr.sin_addr));
}
close(serv_sock);
return 0;
}
void *handle_clnt(void *arg)
{
int clnt_sock = *((int*)arg);
int str_len = 0, i;
char msg[BUF_SIZE];
while ((str_len = read(clnt_sock, msg, sizeof(msg))) != 0)
{
send_msg(msg, str_len);
}
pthread_mutex_lock(&mutx);
for (i=0; i<clnt_cnt; i++)
{
if (clnt_sock == clnt_socks[i])
{
while (i++<clnt_cnt-1)
{
clnt_socks[i] = clnt_socks[i+1];
}
break;
}
}
clnt_cnt--;
pthread_mutex_unlock(&mutx);
close(clnt_sock);
return NULL;
}
void send_msg(char *msg, int len) /* 该函数负责向所有连接的客户端发送消息. */
{
int i;
pthread_mutex_lock(&mutx);
for (i=0; i<clnt_cnt; i++)
{
write(clnt_socks[i], msg, len);
}
pthread_mutex_unlock(&mutx);
}
void error_hangling(char *msg)
{
fputs(msg, stderr);
fputc('\n', stderr);
exit(1);
}
从上述示例中, 各位必须掌握的并不是聊天服务器端的实现方式, 而是临界区的构成形式. 上述示例中的临界区具有如下特点:

添加或删除客户端时, 变量 clnt_cnt 和数组 clnt_socks 同时发生变化. 因此, 在如下情形中均会导致数据不一致, 从而引发严重的错误.

因此, 如上示例所示, 访问变量clnt_cnt 和数组 clnt_sock 的代码应组织在一起并构成临界区. 大家现在应该对我之前说过的这句话有同感吧:
![]()
接下来介绍聊天客户端, 客户端示例为了分离输入和输出过程创建的了线程. 代码分析并不难, 故省略代码相关说明.
#include \n" , argv[0]);
exit(1);
}
sprintf(name, "[%s]", argv[3]);
sock = socket(PF_INET, SOCK_STREAM, 0);
memset(&serv_addr, 0, sizeof(serv_addr));
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = inet_addr(argv[1]);
serv_addr.sin_port = htons(atoi(argv[2]));
if (connect(sock, (struct sockaddr*)&serv_addr, sizeof(serv_addr)) == -1)
{
error_handing("connect() error");
}
pthread_create(&snd_thread, NULL, send_msg, (void*)&sock);
pthread_create(&rcv_thread, NULL, recv_msg, (void*)&sock);
pthread_join(snd_thread, &thread_return);
pthread_join(rcv_thread, &thread_return);
close(sock);
return 0;
}
void *send_msg(void *arg)
{
int sock = *((int*)arg);
char name_msg[NAME_SIZE+BUF_SIZE];
while (1)
{
fgets(msg, BUF_SIZE, stdin);
if (!strcmp(msg, "q\n") || !strcmp(msg, "Q\n"))
{
close(sock);
exit(0);
}
sprintf(name_msg, "%s %s", name, msg);
write(sock, name_msg, strlen(name_msg));
}
return NULL;
}
void *recv_msg(void *arg)
{
int sock = *((int*)arg);
char name_msg[NAME_SIZE+BUF_SIZE];
int str_len;
while (1)
{
str_len = read(sock, name_msg, NAME_SIZE+BUF_SIZE-1);
if (str_len == -1)
{
return (void*)-1;
}
name_msg[str_len] = 0;
fputs(name_msg, stdout);
}
return NULL;
}
void error_handing(char *msg)
{
fputs(msg, stderr);
fputc('\n', stderr);
exit(1);
}
下面给出运行结果. 接入服务器的客户端 IP 均为 127.0.0.1, 因为服务器端和客户端均在同一台计算机中运行.


![]()



结语:
你可以下面这个网站下载这本书
https://www.jiumodiary.com/
时间: 2020-06-11