使用SSD模型检测教学场景下的“举手”目标
由于项目需求,最近花了约三周的时间,尝试在我们自己的教学场景数据集上,完成SSD目标检测模型的测试,检测目标只有一个类别:举手(Handraising)。实际上,项目中已经存在可以完成举手目标检测的方案R-FCN,所以目的是为了验证SSD是否会有检测效果和检测速度的提升,这里简要记录一下整个流程,尽管之后在测试数据集上,SSD的检全率和准确率并不比R-FCN更好。
一、背景介绍:
SSD(Single Shot MultiBox Detector)是2016出来的一篇目标检测的文章,实际比R-FCN稍早一些。在该文中,作者指出他们提出的新方法比之前的目标检测方法都要好(准确率、检测速度两个方面都有优势),结果统计如下图
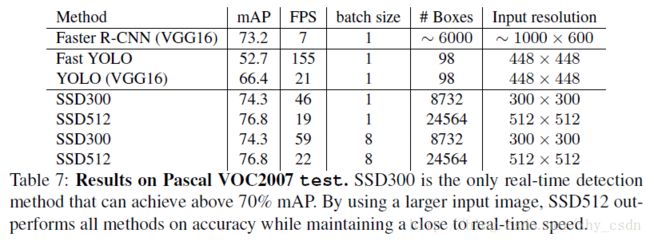
截止到SSD发布,它应该是最优的目标检测算法,之后同年公布的R-FCN也表现出几乎相同的检测准确率,但并未与SSD作比较。到了现在,物体检测方面最优的方法应该要算YOLO v2,下面是近些年出现的一些物体检测算法列表:
PS:总结主要来自博客
http://blog.csdn.net/hx921123/article/details/55804685?locationNum=3&fps=1
DPM(时间 2008)
Adiscriminatively trained, multiscale, deformable part model
OverFeat(时间 2013)
OverFeat:Integrated Recognition, Localization and Detection using Convolutional Networks
SPP-Net(时间 2015)
Spatial PyramidPooling in Deep Convolutional Networks for Visual Recognition
DeepID-Net(时间 2014)
DeepID-Net:Deformable Deep Convolutional Neural Networks for Object Detection
RCNN(时间 2014)
Rich featurehierarchies for accurate object detection and semantic segmentation
Fast RCNN(时间 2015)
Fast R-CNN
Faster RCNN(时间 2015)
Faster R-CNN towards real-time object detection with region proposalnetworks
R-FCN(时间 2016)
R-FCN Object Detection via Region-based Fully Convolutional Networks
Yolo(时间 2016)
You Only Look Once - Unified, Real-Time Object Detection
SSD(时间 2016)
SSD Single Shot MultiBox Detector
Yolo v2(时间 2016)
YOLO9000 - Better, Faster, Stronger
Mask R-CNN(时间 2017)
Mask R-CNN
……
可以看到,物体检测算法层出不穷,让人应接不暇,这里只选取SSD物体检测算法来进行总结,理论分析部分不再讨论,详细记述模型使用过程。
二、SSD配置及调试步骤:
源码网址:https://github.com/weiliu89/caffe/tree/ssd
其实github上已经给出了详细使用步骤,这里再重复一遍,同时就自己遇到的一些问题给出解决办法。
这里按照该网址提供的步骤来记录
1、Installation
2、Preparation
3、Train/Eval
4、Models
1、Installation
1)首先是下载源码并安装,选择将其放在自己的某个文件夹下
git clone https://github.com/weiliu89/caffe.git
cd caffe
git checkout ssd
(出现“分支”则说明copy-check成功...作者caffe目录下有三个分支fcn/master/ssd, 利用git checkout来切换分支,否则只有master目录下的文件)
2)之后需要编译源码
# Modify Makefile.config according to your Caffe installation.
cp Makefile.config.example Makefile.config
#这里需要根据电脑具体的配置修改Makefile.config
make -j8
# Make sure to include $CAFFE_ROOT/python to your PYTHONPATH.
make py
make test -j8
# (Optional)
make runtest -j8
编译过程中,只要配置好了caffe所需要的文件,一般不会出现什么问题
2、Preparation
1)下载已经训练好的VGGNet16模型,fullyconvolutional reduced (atrous) VGGNet,确认将其放在$CAFFE_ROOT/models/VGGNet/ 目录下
网址中提供的链接不可用,这里使用网上搜到的预训练模型
链接:http://pan.baidu.com/s/1miDE9h2
密码:0hf2
可见SSD是基于VGGNet16的物体检测算法,如果该model已经挂了,就自己搜索吧~
2)下载VOC2007、VOC2012数据集,并将其放在 $HOME/data/ 目录下,也可以修改之,但同时记得修改之后的脚本中出现的该目录的引用
# Download the data.
cd $HOME/data
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wgethttp://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
# 下载完毕
# Extract the data.
tar -xvf VOCtrainval_11-May-2012.tar
tar -xvf VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtest_06-Nov-2007.tar
# 解压完毕
3)使用数据集,创建LMDB(Lightning Memory-Mapped Database)文件
cd $CAFFE_ROOT
# Create the trainval.txt, test.txt, and test_name_size.txt indata/VOC0712/
./data/VOC0712/create_list.sh
# 如果修改了数据集的位置,需要修改 create_list.sh 中相应的地址
运行结果:
/home/zhouhuayi/SSD/caffe$ ./data/VOC0712/create_list.sh
Create list for VOC2007 trainval...
Create list for VOC2012 trainval...
Create list for VOC2007 test...
I0122 14:30:12.952246 25110 get_image_size.cpp:61] A total of 4952 images.
I0122 14:30:14.953508 25110 get_image_size.cpp:100] Processed 1000 files.
I0122 14:30:16.875109 25110 get_image_size.cpp:100] Processed 2000 files.
I0122 14:30:18.889964 25110 get_image_size.cpp:100] Processed 3000 files.
I0122 14:30:20.848163 25110 get_image_size.cpp:100] Processed 4000 files.
I0122 14:30:22.774821 25110 get_image_size.cpp:105] Processed 4952 files.
create_list.sh脚本将VOC2007、VOC2012中的图片混合到了一起,得到的trainval.txt,test.txt, test_name_size.txt三个txt文本中,前两个分别是训练集、测试集中图片的名称,test_name_size.txt则是测试集图片名称和对应的长宽
# You can modify the parameters in create_data.sh if needed.
# It will create lmdb files for trainval and test with encoded originalimage:
# -$HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_trainval_lmdb
# -$HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_test_lmdb
# and make soft links at examples/VOC0712/
./data/VOC0712/create_data.sh
create_data.sh才正式生成lmdb文件
这一步总是出现问题,报错如下:
Traceback (most recent call last):
File"/home/zhouhuayi/caffe/scripts/create_annoset.py", line 7, in
from caffe.proto importcaffe_pb2
ImportError: No module named caffe.proto
Traceback (most recent call last):
File"/home/zhouhuayi/caffe/scripts/create_annoset.py", line 7, in
from caffe.proto importcaffe_pb2
ImportError: No module named caffe.proto
上网查找解决方法,发现问题是没有把caffe中的和python相关的内容的路径添加到python的编译路径中。
第一种解决方案是修改 .bashrc 文件,但在我这边实际没有用,出现类似问题的不妨尝试一下
$ cat .bashrc
$ echo "export PYTHONPATH=/home/zhouhuayi/caffe/python">>.bashrc
#在 .bashrc 文件中追加python相关路径
$ source ~/.bashrc
#保存上述修改
之后运行仍旧出现上述bug,该方案不能解决问题
第二种解决方案是,修改出现问题的 .py文件,每一次都明确指定python的相关路径,使用python调用caffe时,在相应的.py文件的最前面加入以下四句:
caffe_root = '/home/zhouhuayi/SSD/caffe/'
import sys
sys.path.insert(0, caffe_root + 'python')
import caffe
问题解决,不过使用该方法,所有调用caffe框架的.py文件中都要包含这四行,略显麻烦。
这里修改的是 /caffe/scripts/create_annoset.py 文件
构建LMDB数据成功后,界面输出的结果:
/home/zhouhuayi/caffe$ ./data/VOC0712/create_data.sh
I0118 13:58:33.651304 18763 convert_annoset.cpp:122] A total of 4952images.
I0118 13:58:33.670905 18763 db_lmdb.cpp:35] Opened lmdb/data/zhouhuayi/VOC/VOCdevkit/VOC0712/lmdb/VOC0712_test_lmdb
I0118 13:58:40.737097 18763 convert_annoset.cpp:195] Processed 1000 files.
I0118 13:58:47.773864 18763 convert_annoset.cpp:195] Processed 2000 files.
I0118 13:58:54.553117 18763 convert_annoset.cpp:195] Processed 3000 files.
I0118 13:59:02.140028 18763 convert_annoset.cpp:195] Processed 4000 files.
I0118 13:59:08.677724 18763 convert_annoset.cpp:201] Processed 4952 files.
/home/zhouhuayi/caffe/build/tools/convert_annoset --anno_type=detection--label_type=xml--label_map_file=/home/zhouhuayi/caffe/data/VOC0712/../../data/VOC0712/labelmap_voc.prototxt--check_label=True --min_dim=0 --max_dim=0 --resize_height=0 --resize_width=0--backend=lmdb --shuffle=False --check_size=False --encode_type=jpg--encoded=True --gray=False /data/zhouhuayi/VOC/VOCdevkit//home/zhouhuayi/caffe/data/VOC0712/../../data/VOC0712/test.txt/data/zhouhuayi/VOC/VOCdevkit/VOC0712/lmdb/VOC0712_test_lmdb
I0118 13:59:09.883656 18802 convert_annoset.cpp:122] A total of 16551images.
I0118 13:59:09.884400 18802 db_lmdb.cpp:35] Opened lmdb/data/zhouhuayi/VOC/VOCdevkit/VOC0712/lmdb/VOC0712_trainval_lmdb
I0118 13:59:31.119462 18802 convert_annoset.cpp:195] Processed 1000 files.
I0118 13:59:52.780809 18802 convert_annoset.cpp:195] Processed 2000 files.
I0118 14:00:13.609648 18802 convert_annoset.cpp:195] Processed 3000 files.
I0118 14:00:34.121955 18802 convert_annoset.cpp:195] Processed 4000 files.
I0118 14:00:54.767715 18802 convert_annoset.cpp:195] Processed 5000 files.
I0118 14:01:15.330397 18802 convert_annoset.cpp:195] Processed 6000 files.
I0118 14:01:36.558912 18802 convert_annoset.cpp:195] Processed 7000 files.
I0118 14:01:57.138043 18802 convert_annoset.cpp:195] Processed 8000 files.
I0118 14:02:18.016297 18802 convert_annoset.cpp:195] Processed 9000 files.
I0118 14:02:39.436408 18802 convert_annoset.cpp:195] Processed 10000files.
I0118 14:03:00.065383 18802 convert_annoset.cpp:195] Processed 11000files.
I0118 14:03:21.318958 18802 convert_annoset.cpp:195] Processed 12000files.
I0118 14:03:41.989552 18802 convert_annoset.cpp:195] Processed 13000files.
I0118 14:04:03.185189 18802 convert_annoset.cpp:195] Processed 14000files.
I0118 14:04:24.233533 18802 convert_annoset.cpp:195] Processed 15000files.
I0118 14:04:45.259112 18802 convert_annoset.cpp:195] Processed 16000files.
I0118 14:04:57.101454 18802 convert_annoset.cpp:201] Processed 16551files.
/home/zhouhuayi/caffe/build/tools/convert_annoset --anno_type=detection--label_type=xml--label_map_file=/home/zhouhuayi/caffe/data/VOC0712/../../data/VOC0712/labelmap_voc.prototxt--check_label=True --min_dim=0 --max_dim=0 --resize_height=0 --resize_width=0--backend=lmdb --shuffle=False --check_size=False --encode_type=jpg--encoded=True --gray=False /data/zhouhuayi/VOC/VOCdevkit//home/zhouhuayi/caffe/data/VOC0712/../../data/VOC0712/trainval.txt/data/zhouhuayi/VOC/VOCdevkit/VOC0712/lmdb/VOC0712_trainval_lmdb
3、Train/Eval
1)开始训练
# It will create model definition files and save snapshot models in:
# -$CAFFE_ROOT/models/VGGNet/VOC0712/SSD_300x300/
# and job file, log file, and the python script in:
# -$CAFFE_ROOT/jobs/VGGNet/VOC0712/SSD_300x300/
# and save temporary evaluation results in:
# -$HOME/data/VOCdevkit/results/VOC2007/SSD_300x300/
# It should reach 77.* mAP at 120k iterations.
python examples/ssd/ssd_pascal_300x300.py
经过120000次的训练之后,我们可以得到所需要的带有超参数的训练model
运行时出现了下面的错误:
Check failed: error == cudaSuccess (10 vs. 0) invalid device ordinal
这是由于GPU数量不匹配造成的,如果训练自己的数据,那么我们只需要将solver.prototxt文件中的device_id项改为自己的GPU块数,一块就是0,两块就是1,以此类推。SSD配置时的例子是将训练语句整合成一个python文件ssd_pascal.py,所以需要改此代码。
解决方法:
将ssd_pascal.py文件中第332行gpus = "0,1,2,3"的GPU选择改为gpus = "0",后面的1,2,3都删掉,再次训练即可。由于我训练时的119服务器上有两块GPU,所以将gpus = "0,1,2,3"修改为gpus ="1"或gpus = "0",问题解决。
这个训练过程十分漫长,我的GPU是K40c,相较作者文中使用的TitanX十分老旧,于是迭代120k次花费了近4~5天的时间,后来验证得到的model确实达到了文中所说的精度。之后才觉得完全没必要这样做,费时又无用,还不如直接准备自己的数据集,上手训练测试,方便快捷。
2)模型测试
# If you would like to test a model you trained, you can do:
python examples/ssd/score_ssd_pascal_300x300.py
这里就是单纯测试model在测试集上的mAP(mean Average Precision),如果训练阶段已经加入了test网络,这一步骤实际已经完成了。
也可以查看单张图片的检测效果,需要修改参数,甚至可以用来测试批量图片
python examples/ssd/ssd_detect.py
4、Models
作者训练好的3个数据集上的模型
PASCAL VOC models
COCO models
ILSVRC models
到这里,完成了SSD的配置和调试工作,在此基础上,可以开始训练自己的数据集。
三、使用SSD训练自己的举手数据集:
遵循上面的步骤,这里可以直接开始准备自己的数据集。
假设已经在某个文件夹下按照VOC数据集的格式放置了自己举手数据集

JPEGImages文件夹下是原始图片帧,这里都是从视频中截取的图片,尺寸均为1080x1920
Annotations-only-handraising文件夹下是xml标签数据,是人工提前将举手对象标记出来的矩形框,也就是GroundTruth,格式模仿VOC数据集
ImageSets中是各类的txt文本,主要包括检测对象的训练集(trainval.txt)、测试集(test.txt),剩下的train,txt、val.txt好像没有单独使用,二者之和就是trainval.txt。由于我只是用SSD检测举手,也就是只有一个类,所以只有这四个txt文本
lmdb文件夹下是之后生成的lmdb文件
准备好数据,开始修改编辑create_list.sh
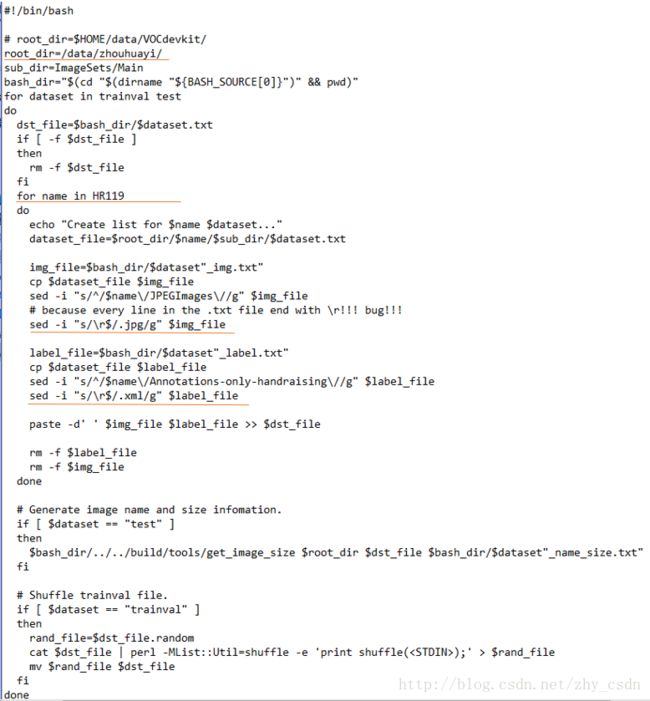
以上画线部分是需要修改的地方。前两个和数据集的位置有关,不再解释,后两个是我有遇到问题的地方。
由于trainval.txt、test.txt文本中,每一行结尾都是回车符’\r’,以致生成的图片名称、标签名称一一对应数据格式出问题,从后缀名开始总是换行,所以需要加上 ’\r’将其替换掉
原语句始:sed -i "s/$/.jpg/g" $img_file
现修改为:sed -i "s/\r$/.jpg/g"$img_file
再顺利执行下列命令
./data/HR119/create_list.sh
接着是生成对应的lmdb数据
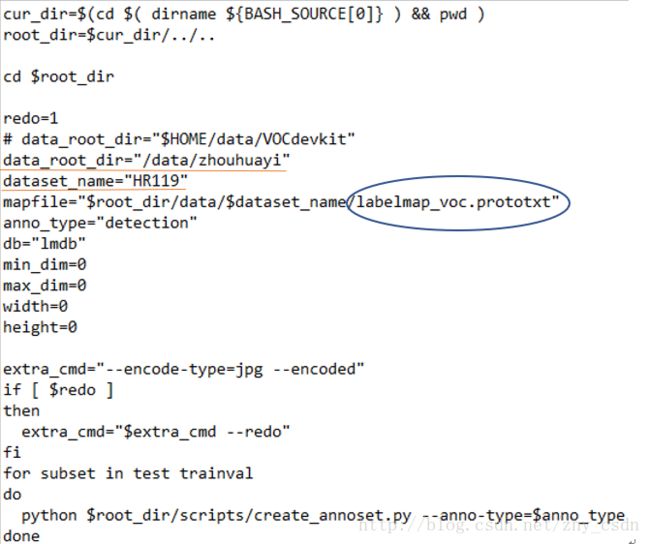
依旧是只需要修改数据集的位置。
值得一提的是,这里还要修改labelmap_voc.prototxt文件,VOC数据集中共有20个类,加上background,num_classes一共是21,而我只有举手一个检测对象,num_classes是2,labelmap_voc.prototxt修改成下列格式

再顺利执行下列命令,就可以完成lmdb数据的制作
./data/HR119/create_data.sh
接着,进入训练阶段,需要修改的是examples/ssd/ssd_pascal.py文件。
主要注意以下几个部分:
1、各种训练集、测试集的位置。VOC0712都要换成自己的数据集名称,记得在对应位置提前新建好文件夹,我的都修改成HR119
2、 resize的尺寸。文中提供的有300x300和512x512两种
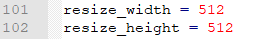
如果是512,还要添加额外添加一层卷积层,如下就是需要多添加的卷积层conv6_1。

如果不确定添加的是否正确,作者提供的训练好的SSD512模型中也有修改好的py脚本,可自行下载
3、检测对象类别数。这里的数量需要+1,因为有个类别是background
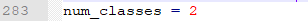
4、 根据GPU的块数和是否空闲,修改参数gpus

5、batchsize、base_lr根据实际调整,一般GPU爆存要调小块大小,loss崩掉(增大为nan)要适当调小学习率
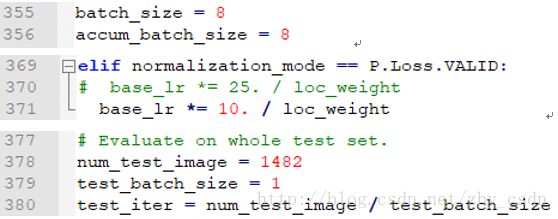
其中,如果训练阶段GPU爆存,可以将测试阶段去掉
6、 修改设置solver.prototxt。这里是在脚本中调整
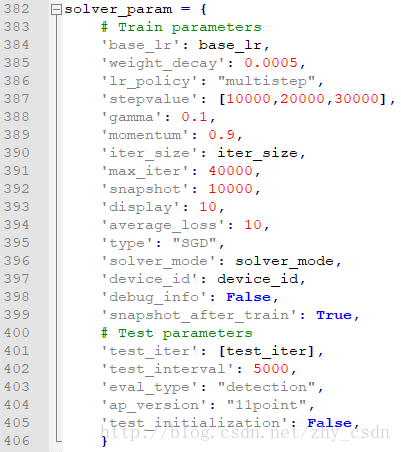
以上,主要就是调整迭代次数’max_iter’、暂时保存节点’snapshot’(可以在意外停止训练时,从保存的最新状态继续恢复训练),其他参数基本不需要修改
终于可以开始训练自己的数据集了,运行以下命令,之后就是耐心的等待了~
python examples/ssd/ssd_HR119_512x512.py
四、问题总结和思考:
一开始,我使用的是SSD300,但是训练之后的效果非常差,举手对象的错检、漏检非常多。
比如下面这张图片391_0041_Student.jpg,人工数的方法GroundTruth是21,使用迭代40000次的SSD300模型检测,并将DetectionBoxing的Threshold设置为0.25,结果正检数量只有5,漏检数达到16。

有尝试过将Threshold调低一些,但是相应的错检率就会上升,说到底还是SSD300模型不能有效区分举手和非举手。
仍旧是图片391_0041_Student.jpg,使用迭代40000次的SSD512模型检测,并将DetectionBoxing的Threshold设置为0.25,结果正检数量是20,漏检数为1,错检数为3。

其中,错检中有一个是老师举手,该干扰不可避免,另外两个误检和一个漏检就是模型自身的缺陷。之后在测试数据集上,发现SSD512的漏检率勉强能接受,但错检率太高,这是致命缺陷,将Threshold设置为0.3,在牺牲检全率的情况下,正检率提升仍旧不明显。
图中,正检数量是17,漏检数为4,错检数为2。

下图是R-FCN的检测结果:

虽然单张的检测结果优势不明显,但全方位统计之后,在我们检测举手的场景下,R-FCN较SSD有很大优势。
总结起来就是,在我们的应用场景下,检测效果SSD300 < SSD512< R-FCN
再将各阶段的尝试总结如下:
第一阶段
没有改变resize的大小,保持默认的300x300,设置迭代次数为40000次,lr经过调整,比原文稍小loss才会收敛,结果训练得到的模型效果十分差劲,这样也就再次浪费了2到3天的时间。经过分析,VOC数据集中的图片,尺寸大都是300x500左右,且清晰度较高,要检测的物体相对整个图片所占比例也较大(大物体检测),而我们自己的数据集图片,是从视频文件中截取的帧,大小均为1080x1920,清晰度较低,举手作为检测对象,符合小物体检测特征,所以猜测是以上的数据集缺陷,导致检测效果不理想。于是修改网络结构,在原始的网络结构上,添加新的卷积层,训练阶段使用较大的resize值。
第二阶段
将resize的调大为512x512,依旧设置迭代次数为40000次,同样lr经过调整比300x300的还要小一些才能正常训练。其中还出现了GPU显存不足的问题,自然是因为resize增大,输入的图片更大,所以需要将batchsize相应调小些,必要时,可以设置成1。期间,在test阶段又出现了GPU爆存的情况,所以test_batch_size也应调小一些,必要时可以设置训练阶段不进行test。这样,又经过2到3天的时间的训练,得到的新模型效果大大改善,和RFCN的检测效果相对比,表现甚至基本接近,但后来统计举手检全率、准确率,效果还是有差距的。
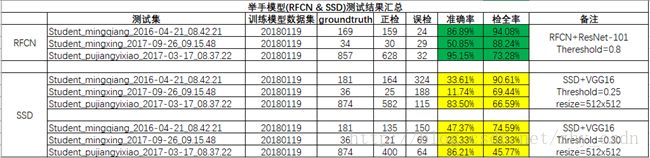
且SSD512情况,依旧存在一些问题:
1、test的准确率(mAP)非常低。可能是因为每个DetectionBounding的置信度偏低,导致计算出的AveragePrecision偏低
2、模型的Threshold需要设置的非常低才能使用。由于每个DetectionBounding的置信度偏低,也可以说举手没有被有效区分出来,所以实际设置中Threshold调整为0.25左右才能有较好效果,这与RFCN中0.8的阈值相去甚远
3、对于拍手、打手势等一些易与举手混淆的对象的剔除不太理想。这个问题也出现在RFCN的模型中,实际上这个问题也是影响检测准确率的关键因素
后来,通过增加迭代次数至80000,检测效果依旧没有得到提升。
第三阶段
继续探索将resize的调大为1024x1024,训练效果是否会进一步提升。由于图片实在过大,此次batchsize必须设置为1,且不能在训练阶段进行测试,为了尽可能准确,迭代次数增大为80000次,lr同样变得更小,训练完成耗费了3到4天的时间。在训练过程中生成的中间结果(40000迭代),可以暂时用来检测效果是否有提升。结果显示,相比512x512的三个问题,有以下改变:
1、test的准确率(mAP)无法测试。尽管将test_batch_size的大小设置成1,GPU却还总是爆存,原因尚不明确
2、模型的Threshold显著提升。这里检测到的降序排名靠前的DetectionBounding的置信度很高,甚至将threshold设置为0.8,仍旧能区分得到大部分举手对象,但结果不比512x512的模型更好,可能是训练次数还不够的原因
3、对于拍手、打手势等一些易与举手混淆的对象,这里表现的也更差劲了,不确定是否也是因为训练次数不够
可惜的是,之后80000次迭代完成后,模型反而更差劲了,可能是发生了过拟合,至此才放弃了SSD替代R-FCN来检测举手的想法。
以上,尽管尝试SSD没有得到更好的结果,但整个过程还是学到了很多,也为之后的实验积累了经验,遂记录之。
2018年2月9日18点03分
PS:不要是用Microsoft Edge浏览器在线编辑博客,尽量使用Google Chorme!!!