引言:之前大四的时候觉得大数据很火,就尝试搭建了一个单节点的hadoop玩过,最近工作慢慢有点空闲就开始搭建3节点的大数据平台,现在整个大数据的生态圈已经完善了很多了,花了一个星期终于搭建好了,各种组件玩起来简直不要太爽。

一、装虚拟机vm,集群初始配置
1、下载vm和ubuntu镜像,然后复制两份ubuntu,每台ubuntu都创建一个hadoop用户
sudo useradd -m hadoop -s /bin/bash #创建hadoop用户,并使用/bin/bash作为shell
sudo passwd hadoop #为hadoop用户设置密码,之后需要连续输入两次密码
sudo adduser hadoop sudo #为hadoop用户增加管理员权限
su - hadoop #切换当前用户为用户hadoop
sudo apt-get update #更新hadoop用户的apt,方便后面的安装
2、 更改主机名
vim /etc/sysconfig/network
将localhost.localdomain修改为你要更改的名称,主机这里改为master,其他改为slave1,slave2
HOSTNAME=master
注意:重启才生效
3、做主机和IP的关系映射
vim /etc/hosts
添加下面字段
172.16.0.30 master
172.16.0.31 slave1
172.16.0.32 slave2

注意:一定在每一台机器都如此修改,可以在每台机器都用vim修改,也可以在一台机器修改完再用命令传送过去
命令:
scp -r /etc/hosts [email protected]:/etc
4、安装ssh,设置SSH无密码登陆
sudo apt-get install openssh-server #安装SSH server
ssh localhost #登陆SSH,第一次登陆输入yes
exit #退出登录的ssh localhost
cd ~/.ssh/ #如果没法进入该目录,执行一次ssh localhost
ssh-keygen -t rsa
输入完 ssh-keygen -t rsa 需要连续敲击三次回车,如下图:

然后出现下图就成功了
新建authorized_keys文件
touch /root/.ssh/authorized_keys
A、将集群其他机器的rsa文件传送过来
scp ~/.ssh/id_rsa.pub hadoop@master:~/
此命令表示将文件复制到master主机上,命令在其他机器中输入,非master上。
B、在master上将密匙写入到authorized_keys中:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
A和B操作是每一台机器传密匙过来就写入到本机中。
(在slave1上将master和slave2的密匙传过来就写入。)
这第4小节的操作全部在其他机器照样操作。
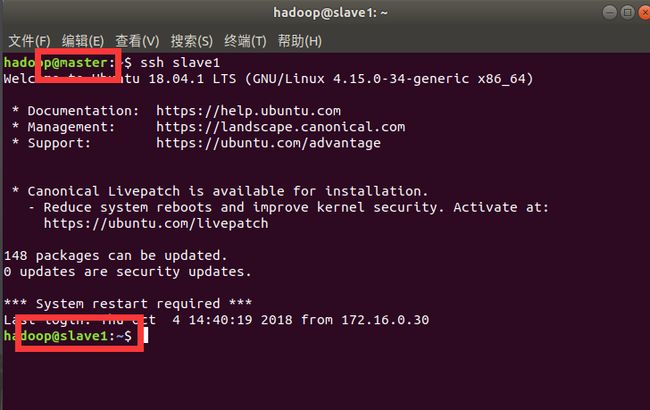
测试:
ssh slave1
5、集群同步时间
时间同步可参照《zookeeper集群同步时间设置》来设置
二、hadoop集群搭建
1、编辑profile文件
sudo vim /etc/profile
source /etc/profile #更新修改
将下列配置加到底部:
export JAVA_HOME=/usr/local/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
export HADOOP_HOME=/usr/local/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:/usr/local/hive/lib
export SCALA_HOME=/usr/local/scala
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:$PATH
export SPARK_HOME=/usr/local/spark
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:$PATH
export ZK_HOME=/usr/local/zookeeper
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${ZK_HOME}/bin:$PATH
export HBASE_HOME=/usr/local/hbase
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:$HBASE_HOME/bin:$PATH
export KYLIN_HOME=/usr/local/kylin
export PATH=$KYLIN_HOME/bin:$PATH
export hive_dependency=/usr/local/hive/conf:/usr/local/hive/lib/*:/usr/local/hive/hcatalog/share/hcatalog/hive-hcatalog-core-2.3.3.jar
export PHOENIX_HOME=/usr/local/phoenix
export PATH=$PATH:$PHOENIX_HOME/bin
export PHOENIX_CLASSPATH=$PHOENIX_HOME
export MAHOUT_HOME=/usr/local/mahout
export MAHOUT_CONF_DIR=$MAHOUT_HOME/conf
export PATH=$PATH:$MAHOUT_HOME/conf:$MAHOUT_HOME/bin
2、java配置
首先卸载ubuntu自带openjdk,再安装oracle官方的jdk
卸载;
sudo apt-get remove openjdk*
去oracle官网下载linux版本的jdk,然后解压、重命名、移动:
tar -xvf jdk-8u144-linux-x64.tar.gz #解压
mv jdk1.8.0_144 java #重命名
mv java /usr/local #移动
每台机器都要配置java
3、hadoop安装配置
3.1、修改 core-site.xml
core-site.xml在/usr/local/hadoop/etc/hadoop文件夹里
fs.defaultFS
hdfs://master:8020
io.file.buffer.size
131072
hadoop.tmp.dir
file:/home/hadoop/tmp
Abase for other temporary directories.
hadoop.proxyuser.hadoop.hosts
*
hadoop.proxyuser.hadoop.groups
*
3.2配置hadoop-env.sh
将export JAVA_HOME=${JAVA_HOME}修改为绝对地址:
export JAVA_HOME=/usr/local/java
3.3 配置 hdfs-site.xml
dfs.namenode.secondary.http-address
master:9001
dfs.namenode.name.dir
file:/home/hadoop/dfs/name
dfs.datanode.data.dir
file:/home/hadoop/dfs/data
dfs.replication
3
dfs.webhdfs.enabled
true
3.4 配置mapred-site.xml
如果没有 mapred-site.xml 该文件,就复制mapred-site.xml.template文件并重命名为mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
3.5 配置yarn-site.xml文件
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.resource-tracker.address
master:8031
yarn.resourcemanager.admin.address
master:8033
yarn.resourcemanager.webapp.address
master:8088
3.6 修改slaves
slave1
slave2
3.7传送hadoop到其他机器
sudo scp -r /usr/local/hadoop hadoop@slave1:~/
sudo scp -r /usr/local/hadoop hadoop@slave2:~/
在每一台机器再用命令移动到各自的 /usr/local/目录下
sudo mv hadoop /usr/local/
3.8 hadoop启动
切换到/opt/hadoop/hadoop2.8/bin目录下输入
格式化namenode
./hdfs namenode -format
初始化成功之后,切换到/opt/hadoop/hadoop2.8/sbin
启动hadoop 的hdfs和yarn
start-dfs.sh
start-yarn.sh
然后可以在浏览器输入: ip+50070或8088 端口查看


4、 配置Hive+Mysql
安装mysql
sudo apt-get install mysql-server
但是ubuntu18安装mysql是不会出现设置 root 帐户密码的
命令:
sudo vim /etc/mysql/debian.cnf

在这个文件里面有着MySQL默认的用户名和用户密码,
最最重要的是:用户名默认的不是root,而是debian-sys-maint
mysql -u debian-sys-maint -p
提示输入密码,输入刚刚那个复杂的密码,进入mysql
版本是5.7,password字段已经被删除,取而代之的是authentication_string字段,我的是5.7,所以要更改密码:
use mysql;
update user set authentication_string=PASSWORD("You'r New Password") where User='root';
update user set plugin="mysql_native_password";
flush privileges;
exit;
重启:
service mysql restart
开启root用户远程登录:
sudo mysql -u root -p
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '密码';
flush privileges;
select user,authentication_string,Host from user; #查看root
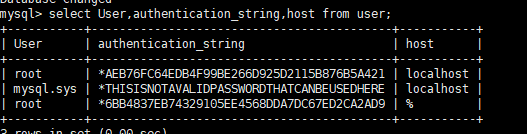
用navicat验证远程登录与否
如果root远程登录不成功:
1. 查看 3306 端口是否正常
root@node1:~# netstat -an | grep 3306
tcp 0 0 127.0.0.1:3306 0.0.0.0:* LISTEN
注意:现在的 3306 端口绑定的 IP 地址是本地的 127.0.0.1
2. 修改 Mysql 配置文件(注意路径,跟之前网上的很多版本位置都不一样)
root@node1:~# vim /etc/mysql/mysql.conf.d/mysqld.cnf
找到
bind-address = 127.0.0.1
前面加 #注释掉
3. 重启 Mysql
service mysql restart
sudo mysql -u root -p #进入mysql
create database hive; #好像不需要创建这个hive数据库
4.1、 配置hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://172.16.0.30:3306/hive?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
mima
hive.metastore.warehouse.dir
/user/hive/warehouse
datanucleus.schema.autoCreateAll
false
4.2、元数据存储初始化
cd /usr/local/hive/bin
schematool -initSchema -dbType mysql
4.3、允许hive连接mysql
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%'IDENTIFIED BY 'mima' WITH GRANT OPTION; 后面的mima是配置hive-site.xml中配置的连接密码
flush privileges 刷新mysql系统权限关系表
4.4、启动验证hive
hive

如果发生slf4j jar包冲突报错,是因为Hadoop的slf4j 与hive的slf4j jar包绑定冲突,移除其中一个即可。
rm -rf /usr/local/hive/lib/log4j-slf4j-impl-2.4.1.jar
三、Zookeeper的环境配置
1、下载zookeeper包后,解压:
tar -xvf zookeeper-3.4.10.tar.gz #解压
mv zookeeper-3.4.10 zookeeper #重命名文件名
mv zookeeper /usr/local #移动
2、修改配置文件
在集群的每台机器上都创建这些目录
mkdir /usr/local/zookeeper/data
mkdir /usr/local/zookeeper/dataLog
在/usr/local/zookeeper/data里创建myid文件
touch myid
修改master的myid文件为1,slave1为2,slave2为3

3、新建zoo.cfg文件
切换到/usr/local/zookeeper/conf 目录下 ,没有zoo.cfg文件就新建一个,并加入以下内容
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/dataLog
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
4、将zookeeper文件夹传送到其他机器
scp -r /usr/local/zookeeper hadoop@slave1:~/
scp -r /usr/local/zookeeper hadoop@slave2:~
再在每个机器将zookeeper文件夹移动到/usr/local/ 目录下
5、启动zookeeper
切换到/usr/local/zookeeper/bin
zkServer.sh start 需要在每台机器都逐一启动
常用命令
启动
zkServer.sh start
查看状态
zkServer.sh status
重启
zkServer.sh restart
关闭
zkServer.sh stop
四、HBase的环境配置
1、解压文件包
tar -xvf hbase-1.2.7-bin.tar.gz #解压
mv hbase-1.2.7 hbase #重命名
mv hbase /usr/local/ #移动
2、查看版本
start-hbase.sh
stop-hbase.sh
hbase version
3、修改hbase-env.sh
切换到 /usr/local/hbase/conf 下,
export JAVA_HOME=/usr/local/java
export HADOOP_HOME=/usr/local/hadoop
export HBASE_HOME=/usr/local/hbase
export HBASE_CLASSPATH=/usr/local/hadoop/etc/hadoop
export HBASE_PID_DIR=/usr/local/hbase/pids
export HBASE_MANAGES_ZK=false
4、修改 hbase-site.xml
hbase.rootdir
hdfs://master:8020/hbase
hbase.master
master
hbase.cluster.distributed
true
hbase.zookeeper.property.clientPort
2181
hbase.zookeeper.quorum
master,slave1,slave2
zookeeper.session.timeout
60000000
dfs.support.append
true
注意:这个8020端口与 core-site.xml里的
说明:hbase.rootdir:这个目录是region server的共享目录,用来持久化Hbase 。hbase.cluster.distributed :Hbase的运行模式。false是单机模式,true是分布式模式。若为false,Hbase和Zookeeper会运行在同一个JVM里面。
5、修改regionservers
指定hbase的主从,和hadoop的slaves文件配置一样
将文件修改为
slave1
slave2
在一台机器上(最好是master)做完这些配置之后,我们使用scp命令将这些配置传输到其他机器上。
命令:
scp -r /usr/local/hbase hadoop@slave1:~/
scp -r /usr/local/hbase hadoop@slave2:~/
在每台机器移动hbase文件夹到 /usr/local/ 目录下
sudo mv hbase /usr/local
启动和停止
start-hbase.sh
stop-hbase.sh
打开网址 http://172.16.0.30:16010

五、Spark的环境配置
1、配置Scala
tar -xvf scala-2.12.2.tgz
mv scala-2.12.2 scala
sudo mv scala /usr/local/
2,配置Spark
tar -xvf spark-1.6.3-bin-hadoop2.4-without-hive.tgz
mv spark-1.6.3-bin-hadoop2.4-without-hive spark
sudo mv spark /usr/local/
3、修改配置文件
切换到conf目录
cd /usr/local/spark/conf
修改 spark-env.sh
在conf目录下,修改spark-env.sh文件,如果没有 spark-env.sh 该文件,就复制spark-env.sh.template文件并重命名为spark-env.sh。
修改这个新建的spark-env.sh文件,加入配置:
export SCALA_HOME=/usr/local/scala
export JAVA_HOME=/usr/local/java
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_HOME=/usr/local/spark
export SPARK_MASTER_HOST=172.16.0.30
export SPARK_MASTER_IP=172.16.0.30
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export SPARK_EXECUTOR_MEMORY=2G
export SPARK_LOCAL_IP=master
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
4、修改slaves
slaves 分布式文件
在conf目录下,修改slaves文件,如果没有 slaves 该文件,就复制slaves .template文件并重命名为slaves 。
修改这个新建的slaves 文件,加入配置:
slave1
slave2
5、传输Scala以及spark到其他机器
scp -r /usr/local/scala hadoop@slave1:~/
scp -r /usr/local/scala hadoop@slave2:~/
scp -r /usr/local/spark hadoop@slave1:~/
scp -r /usr/local/spark hadoop@slave2:~/
然后在各自的机器将其移动到 /usr/local/ 目录下
sudo mv scala /usr/local/
6、spark启动
说明:要先启动Hadoop
切换到Spark目录下,启动spark
cd /usr/local/spark/sbin
start-all.sh
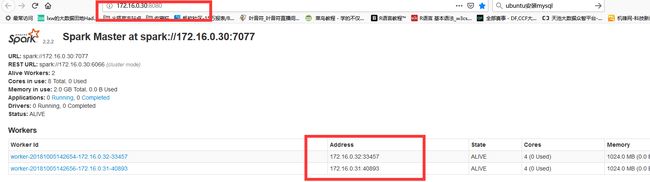
启动成功之后,可以使用jps命令在各个机器上查看是否成功。
可以在浏览器输入: ip+8080 端口查看
六、配置kylin
1、安装
tar -zxvf apache-kylin-2.5.0-bin-hbase1x.tar.gz #解压
mv apache-kylin-2.5.0-bin-hbase1x kylin #重命名
sudo kylin /usr/local/ #移动
2、配置kylin.sh
切换到kylin/bin 目录下
export KYLIN_HOME=/usr/local/kylin
export HBASE_CLASSPATH_PREFIX=${tomcat_root}/bin/bootstrap.jar:${tomcat_root}/bin/tomcat-juli.jar:${tomcat_root}/lib/*:$hive_dependency:$HBASE_CLASSPATH_PREFIX
3、配置kylin.properties
进入conf文件夹,修改kylin各配置文件kylin.properties如下:
kylin.rest.servers=master:7070
kylin.rest.timezone=GMT+8
kylin.job.jar=/usr/local/kylin/lib/kylin-job-2.5.0.jar
kylin.coprocessor.local.jar=/usr/local/kylin/lib/kylin-coprocessor-2.5.0.jar
4、配置kylin_hive_conf.xml和kylin_job_conf.xml
将kylin_hive_conf.xml和kylin_job_conf.xml的副本数设置为2
dfs.replication
2
Block replication
5、启动服务
注意:在启动Kylin之前,先确认以下服务已经启动
启动zookeeper、hadoop、hbase
zkServer.sh start
start-all.sh
start-hbase.sh
启动 hivemetastore 服务
$HIVE_HOME/bin/hive --service metastore
还要启动hadoop的hdfs/yarn/jobhistory服务
mr-jobhistory-daemon.sh start historyserver
最后启动kylin
kylin.sh start
Web访问地址: http://172.16.0.30:7070/kylin/
ADMIN/KYLIN 账户密码登录
七、配置mahout
tar -zxvf apache-mahout-distribution-0.13.0.tar.gz #解压
mv apache-mahout-distribution-0.13.0 mahout #重命名
sudo mahout /usr/local/ #移动
注意:全部的环境变量在前面编辑profile文件已经配置好了
注意:全部的环境变量在前面编辑profile文件已经配置好了
注意:全部的环境变量在前面编辑profile文件已经配置好了