Protocol Buffer介绍
Protocol Buffers是一种独立于语言和平台,可扩展的序列化结构数据格式,主要用于数据存储和RPC数据交换格式。目前google提供了C++、Java、Python 三种语言的 API;包含一个Protocol Buffers编译器和一个Protocol Buffers使用的类库。
(二)Protocol Buffer如何使用它?1.定义结构化消息.proto格式文件
a)指定域的访问属性
required: 非空字段,必须设值
optional: 可选字段,可以没有值
repeated: 可重复字段 (相当于一个动态数组List,会保持元素的顺序)
注:(1).在使用required字段的时候一定要慎重,例如在实际的应用过程中业务发生了改变,如果你把原来的required改为了optional,那么原来使用required读取消息的使用者在收到新改变后的消息后如果没有这个这个字段的话可能会认为该消息不完整而丢弃。Google工程师建议是尽量少使用requried访问属性
(2).可选字段会有默认的值,对于字符串默认值是空串,整型是零,布尔类型是假,枚举类型是枚举体中的第一个元素,除此之外我们也可以为其指定默认值[default = VALUE]
b)指定域类型
c)给每个域指定数字标签(field_number),在一个消息体内,必须唯一(反序列化时,根据数字标签组成的key寻找变量),最好取:1-15(pb的编码格式中1-15只需一个字节)
例:required bool state = 1;
state域的访问属性为:required;域类型为:bool;域数字标签为:1
2.使用PB编译器生成目标语言代码(Java,C++,Python)
protoc —proto_path=$SRC_DIR —java_out=$DST_DIR $SRC_DIR/feed.proto
(1).proto_path 表示.proto文件所在路径
(2). java_out 指定生成java文件所在路径
(3).$SRC_DIR/feed.proto 表示要编译的.proto文件
3.使用PB API来读写消息(反序列化和序列化)
编译后在$DST_DIR目录下生成一个FeedWrap.java类。生成的代码结构可以理解如下(静态内部类):
class FeedWrap {
static class Feed{
static class User {static class Builder{}}
static class Status {
static class GroupName {static class Builder{}}
static class Builder{}
}
static class Advertise{static class Builder{}}
static class Item{static class Builder{}}
static class Ad{static class Builder{}}
static class Builder{}
}
3-1.序列化数据
外部类的成员变量都是private类型的,并且只提供了getter()方法,而没有提供setter方法去为成员变量赋值。
PB对外部类的任何赋值操作都需要通过Builder内部类来进行。当对内部类Builder中的成员赋值完成后,调用Builder的build()方法时,会将Builder类成员的值赋给外部类对象result的对应成员,并返回该外部类对象result。
PB通过这样一种方式保证了数据安全性,一旦数据构建完毕,将无法再对其进行修改。
构建完成,调用writeTo()方法,将数据写入数据流中。
3-2.反序列化数据
使用parseFrom(inputStream或buffer)反序列化
1).根据inputStream或buffer构造一个CodedInputStream。
2).使用生成的代码中的parsePartialFrom方法,解析二进制数据:首先调用CodedInputStream的readTag()获取key值,然后根据key值通过swtich块给key对应对象赋值;将数据解析后,将构建好的对象返回。
PARSER.parseFrom(input);
// PARSER接口变量,PARSER可以直接调用实现类的方法(接口回调),并重写了parsePartialFrom方法,
publicstatic com.google.protobuf.Parser
new com.google.protobuf.AbstractParser
public Feed parsePartialFrom(
com.google.protobuf.CodedInputStream input,
com.google.protobuf.ExtensionRegistryLite extensionRegistry)
throws com.google.protobuf.InvalidProtocolBufferException {
returnnew Feed(input, extensionRegistry); }
};
(三)Protocol Buffer为什么要用它?
PB之所以解析速度快、所占体积小,很大程度上是由它序列化的编码特点来决定的。
Base 128 Varints:整数数值都是由字节表示,其中每个字节为8位,即Base 256。然而在Protocol Buffer的编码中,最高位设成msb(如果该字节后面还有字节,则置1;否则置0),只有后面的7位存储实际的数据,因此我们称其为Base 128。
例:312的Varints 编码为B8 02
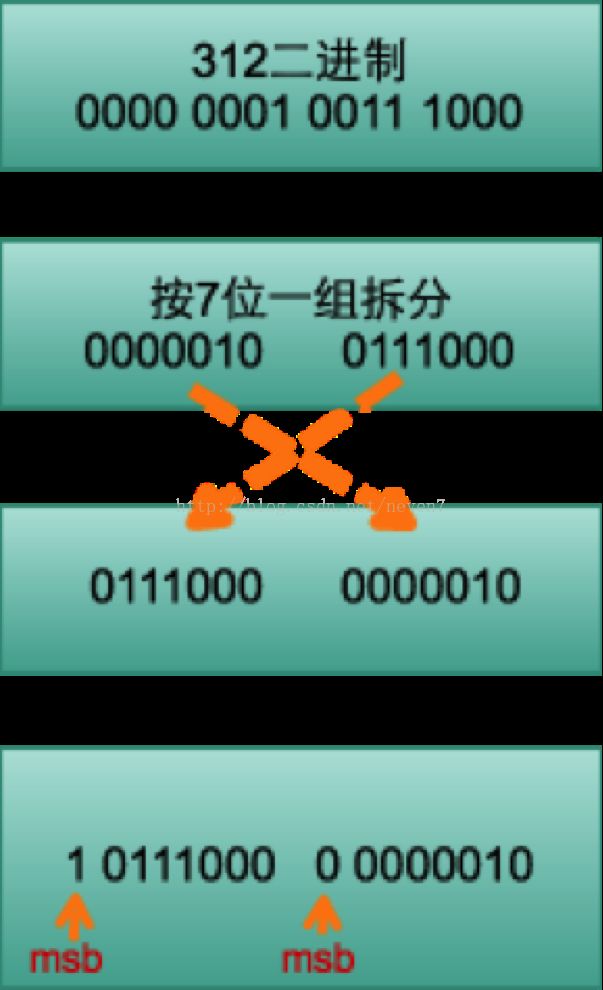
结构化消息经过序列化后会成为一个二进制数据流,该流中的数据类似为一系列的 Key-Value 对。
采用这种 Key-Pair 结构无需使用分隔符来分割不同的 Field。对于可选的 Field,如果消息中不存在该 field,那么在最终的 Message Buffer 中就没有该 field,这些特性都有助于节约消息本身的大小。
Key 用来标识具体的 field,在解包的时候,Protocol Buffer 根据 Key 就可以知道相应的 Value 应该对应于消息中的哪一个 field Key 的定义如下:(field_number << 3) | wire_type 例:optional int32 total_number = 9; 在程序中给total_number 赋值312,序列化后为:0x 48 B8 02。
0x 48 代表key 0 1001 000,最高位(msb)0 表示这key 为一个Byte,中间四位表示total_number的数字标签为9,最后三位表示total_number的属性类型为0 ,0x B8 02代表value
| Wire_type |
Meaning |
Used For |
| 0 |
Varint |
int32,int64,uint64,sint32,sint64,bool,enum |
| 1 |
64bit |
fixed64,sfixed64,double |
| 2 |
Length-delimited |
string,bytes,embedded message,packed repeated fields |
| 5 |
32bit |
fixed32,sfixed32,float |
负数:一个负数一般会被表示为一个很大的整数,因为计算机定义负数的符号位为数字的最高位。如果采用 Varint 表示一个负数,那么一定需要 5 个 Bytes。为此 Google Protocol Buffer 对负数采用 zigzag 编码。
其公式为: (n << 1) ^ (n >> 31) //sint32
(n << 1)^ (n >> 63) //sint64
| Signed Orginal |
Encoded As |
| 0 |
0 |
| -1 |
1 |
| 1 |
2 |
| -2 |
3 |
| … |
… |
| 2147483647 |
4294967294 |
| -2147483648 |
4294967295 |
String类型:
key之后是value部分的字节长度信息length,后面是value实际数据数据。
例:optional string text = 7;
给text赋值为:pbtext
序列化后:0x 3A 06 70 62 74 65 78 74
key 为第一个字节0x3A,通过解码可以得到字段类型2和字段数字标签为7;第二个字节06表示text的长度;后面7个字节则表示pbtext每个字符对应的ASCII十六进制表示。
嵌套消息类型:类似String编码;key信息之后是value部分的字节长度,最后紧随嵌套消息内成员的key-value数据信息。
例:
message Feed {
message Status {
required int64 id = 1;
optional string text = 7;
}
repeated Status statuses = 2;
}
对id赋值150,对text赋值pbtest;
序列化后:0x 12 0B 08 96 01 3A 06 70 62 74 65 78 74
key 为第一个字节0x12,通过解码可以得到字段类型2和字段数字标签为2;第二个字节0B表示嵌套消息Status value部分的长度;后面11个字节表示消息Status内部字段的key-value。
id赋值150 -> 0x 08 96 01
text赋值pbtest -> 0x 3A 06 70 62 74 65 78 74
PB实例( pb接口http连接及反序列化数据代码实现 )HttpClient(提供高效的,最新的,功能丰富的,支持HTTP协议的客户端编程工具包
1)HttpClient client = new HttpClient();
2)GetMethod httpGet = new GetMethod( FEEDURL );
3)client.executeMethod(httpGet);
4)httpGet.getResponseBody() ;
5)对取到的数据处理(反序列化pb);
6)httpGet.releaseConnection();