性能网络编程总结
高性能网络编程总结及《TCP/IP Sockets编程(C语言实现) (第2版)》 代码下载(链接以及文件打包)
目录(?)[+]
http://blog.csdn.NET/column/details/high-perf-network.html
http://blog.csdn.net/russell_tao/article/details/9111769
高性能网络编程(一)----accept建立连接




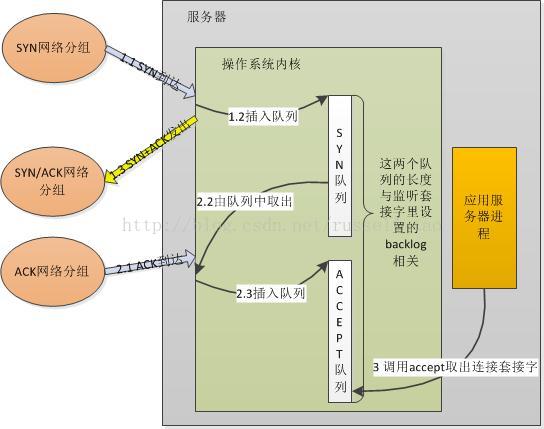



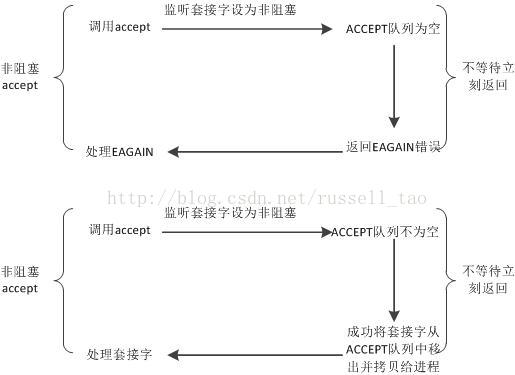

高性能网络编程2----TCP消息的发送
版权声明:本文为博主原创文章,未经博主允许不得转载。
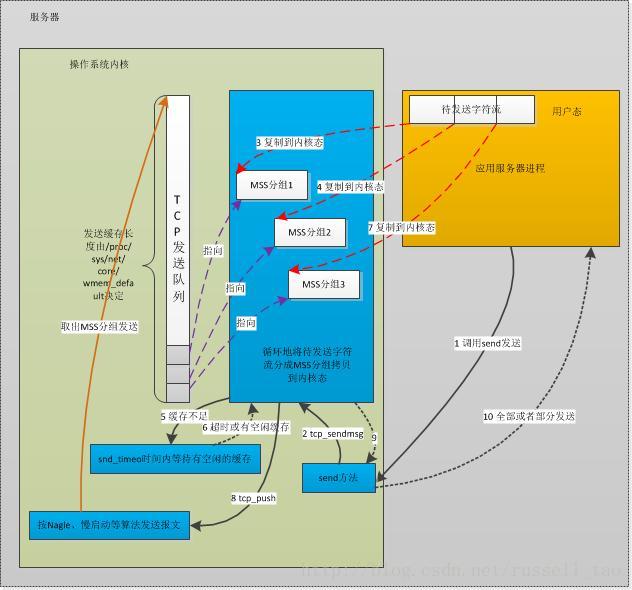


- wait_for_memory:
- if (copied)
- tcp_push(sk, tp, flags & ~MSG_MORE, mss_now, TCP_NAGLE_PUSH);
- if ((err = sk_stream_wait_memory(sk, &timeo)) != 0)
- goto do_error;
这里的 sk_stream_wait_memory方法接受一个参数timeo,就是等待超时的时间。这个时间是tcp_sendmsg方法刚开始就拿到的,如下:
- timeo = sock_sndtimeo(sk, flags & MSG_DONTWAIT);
看看其实现:
- static inline long sock_sndtimeo(const struct sock *sk, int noblock)
- {
- return noblock ? 0 : sk->sk_sndtimeo;
- }
也就是说,当这个套接字是阻塞套接字时,timeo就是SO_SNDTIMEO选项指定的发送超时时间。如果这个套接字是非阻塞套接字, timeo变量就会是0。


- //检查这一次要发送的报文最大序号是否超出了发送滑动窗口大小
- static inline int tcp_snd_wnd_test(struct tcp_sock *tp, struct sk_buff *skb, unsigned int cur_mss)
- {
- //end_seq待发送的最大序号
- u32 end_seq = TCP_SKB_CB(skb)->end_seq;
- if (skb->len > cur_mss)
- end_seq = TCP_SKB_CB(skb)->seq + cur_mss;
- //snd_una是已经发送过的数据中,最小的没被确认的序号;而snd_wnd就是发送窗口的大小
- return !after(end_seq, tp->snd_una + tp->snd_wnd);
- }
- static inline unsigned int tcp_cwnd_test(struct tcp_sock *tp, struct sk_buff *skb)
- {
- u32 in_flight, cwnd;
- /* Don't be strict about the congestion window for the final FIN. */
- if (TCP_SKB_CB(skb)->flags & TCPCB_FLAG_FIN)
- return 1;
- //飞行中的数据,也就是没有ACK的字节总数
- in_flight = tcp_packets_in_flight(tp);
- cwnd = tp->snd_cwnd;
- //如果拥塞窗口允许,需要返回依据拥塞窗口的大小,还能发送多少字节的数据
- if (in_flight < cwnd)
- return (cwnd - in_flight);
- return 0;
- }
再通过tcp_window_allows方法获取拥塞窗口与滑动窗口的最小长度,检查待发送的数据是否超出:
- static unsigned int tcp_window_allows(struct tcp_sock *tp, struct sk_buff *skb, unsigned int mss_now, unsigned int cwnd)
- {
- u32 window, cwnd_len;
- window = (tp->snd_una + tp->snd_wnd - TCP_SKB_CB(skb)->seq);
- cwnd_len = mss_now * cwnd;
- return min(window, cwnd_len);
- }
- static inline int tcp_nagle_test(struct tcp_sock *tp, struct sk_buff *skb,
- unsigned int cur_mss, int nonagle)
- {
- //nonagle标志位设置了,返回1表示允许这个分组发送出去
- if (nonagle & TCP_NAGLE_PUSH)
- return 1;
- //如果这个分组包含了四次握手关闭连接的FIN包,也可以发送出去
- if (tp->urg_mode ||
- (TCP_SKB_CB(skb)->flags & TCPCB_FLAG_FIN))
- return 1;
- //检查Nagle算法
- if (!tcp_nagle_check(tp, skb, cur_mss, nonagle))
- return 1;
- return 0;
- }
再来看看 tcp_nagle_check方法,它与上一个方法不同,返回0表示可以发送,返回非0则不可以,正好相反。
- static inline int tcp_nagle_check(const struct tcp_sock *tp,
- const struct sk_buff *skb,
- unsigned mss_now, int nonagle)
- {
- //先检查是否为小分组,即报文长度是否小于MSS
- return (skb->len < mss_now &&
- ((nonagle&TCP_NAGLE_CORK) ||
- //如果开启了Nagle算法
- (!nonagle &&
- //若已经有小分组发出(packets_out表示“飞行”中的分组)还没有确认
- tp->packets_out &&
- tcp_minshall_check(tp))));
- }
最后看看tcp_minshall_check做了些什么:
- static inline int tcp_minshall_check(const struct tcp_sock *tp)
- {
- //最后一次发送的小分组还没有被确认
- return after(tp->snd_sml,tp->snd_una) &&
- //将要发送的序号是要大于等于上次发送分组对应的序号
- !after(tp->snd_sml, tp->snd_nxt);
- }
想象一种场景,当对请求的时延非常在意且网络环境非常好的时候(例如同一个机房内),Nagle算法可以关闭,这实在也没必要。使用TCP_NODELAY套接字选项就可以关闭Nagle算法。看看setsockopt是怎么与上述方法配合工作的:
- static int do_tcp_setsockopt(struct sock *sk, int level,
- int optname, char __user *optval, int optlen)
- ...
- switch (optname) {
- ...
- case TCP_NODELAY:
- if (val) {
- //如果设置了TCP_NODELAY,则更新nonagle标志
- tp->nonagle |= TCP_NAGLE_OFF|TCP_NAGLE_PUSH;
- tcp_push_pending_frames(sk, tp);
- } else {
- tp->nonagle &= ~TCP_NAGLE_OFF;
- }
- break;
- }
- }
可以看到,nonagle标志位就是这么更改的。
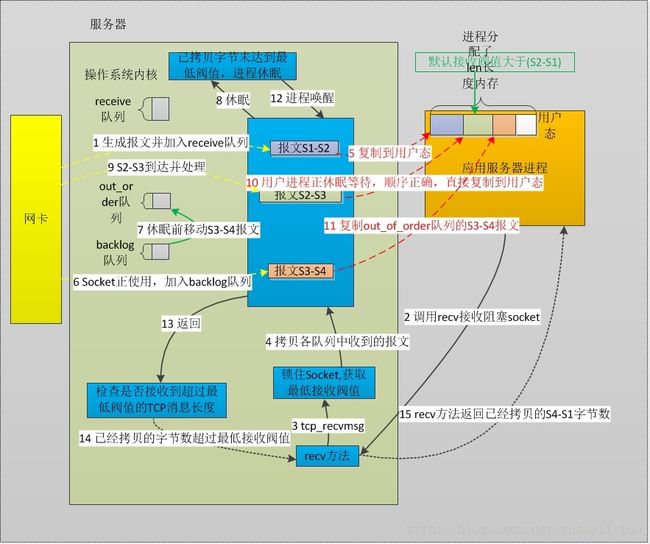
高性能网络编程3----TCP消息的接收
版权声明:本文为博主原创文章,未经博主允许不得转载。

- int tcp_v4_rcv(struct sk_buff *skb)
- {
- ... ...
- //是否有进程正在使用这个套接字,将会对处理流程产生影响
- //或者从代码层面上,只要在tcp_recvmsg里,执行lock_sock后只能进入else,而release_sock后会进入if
- if (!sock_owned_by_user(sk)) {
- {
- //当 tcp_prequeue 返回0时,表示这个函数没有处理该报文
- if (!tcp_prequeue(sk, skb))//如果报文放在prequeue队列,即表示延后处理,不占用软中断过长时间
- ret = tcp_v4_do_rcv(sk, skb);//不使用prequeue或者没有用户进程读socket时(图3进入此分支),立刻开始处理这个报文
- }
- } else
- sk_add_backlog(sk, skb);//如果进程正在操作套接字,就把skb指向的TCP报文插入到backlog队列(图3涉及此分支)
- ... ...
- }
图1第1步里,我们从网络上收到了序号为S1-S2的包。此时,没有用户进程在读取套接字,因此,sock_owned_by_user(sk)会返回0。所以,tcp_prequeue方法将得到执行。简单看看它:
- static inline int tcp_prequeue(struct sock *sk, struct sk_buff *skb)
- {
- struct tcp_sock *tp = tcp_sk(sk);
- //检查tcp_low_latency,默认其为0,表示使用prequeue队列。tp->ucopy.task不为0,表示有进程启动了拷贝TCP消息的流程
- if (!sysctl_tcp_low_latency && tp->ucopy.task) {
- //到这里,通常是用户进程读数据时没读到指定大小的数据,休眠了。直接将报文插入prequeue队列的末尾,延后处理
- __skb_queue_tail(&tp->ucopy.prequeue, skb);
- tp->ucopy.memory += skb->truesize;
- //当然,虽然通常是延后处理,但如果TCP的接收缓冲区不够用了,就会立刻处理prequeue队列里的所有报文
- if (tp->ucopy.memory > sk->sk_rcvbuf) {
- while ((skb1 = __skb_dequeue(&tp->ucopy.prequeue)) != NULL) {
- //sk_backlog_rcv就是下文将要介绍的tcp_v4_do_rcv方法
- sk->sk_backlog_rcv(sk, skb1);
- }
- } else if (skb_queue_len(&tp->ucopy.prequeue) == 1) {
- //prequeue里有报文了,唤醒正在休眠等待数据的进程,让进程在它的上下文中处理这个prequeue队列的报文
- wake_up_interruptible(sk->sk_sleep);
- }
- return 1;
- }
- //prequeue没有处理
- return 0;
- }
由于tp->ucopy.task此时是NULL,所以我们收到的第1个报文在tcp_prequeue函数里直接返回了0,因此,将由 tcp_v4_do_rcv方法处理。
- int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
- {
- if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */
- //当TCP连接已经建立好时,是由tcp_rcv_established方法处理接收报文的
- if (tcp_rcv_established(sk, skb, skb->h.th, skb->len))
- goto reset;
- return 0;
- }
- ... ...
- }
tcp_rcv_established方法在图1里,主要调用tcp_data_queue方法将报文放入队列中,继续看看它又干了些什么事:
- static void tcp_data_queue(struct sock *sk, struct sk_buff *skb)
- {
- struct tcp_sock *tp = tcp_sk(sk);
- //如果这个报文是待接收的报文(看seq),它有两个出路:进入receive队列,正如图1;直接拷贝到用户内存中,如图3
- if (TCP_SKB_CB(skb)->seq == tp->rcv_nxt) {
- //滑动窗口外的包暂不考虑,篇幅有限,下次再细谈
- if (tcp_receive_window(tp) == 0)
- goto out_of_window;
- //如果有一个进程正在读取socket,且正准备要拷贝的序号就是当前报文的seq序号
- if (tp->ucopy.task == current &&
- tp->copied_seq == tp->rcv_nxt && tp->ucopy.len &&
- sock_owned_by_user(sk) && !tp->urg_data) {
- //直接将报文内容拷贝到用户态内存中,参见图3
- if (!skb_copy_datagram_iovec(skb, 0, tp->ucopy.iov, chunk)) {
- tp->ucopy.len -= chunk;
- tp->copied_seq += chunk;
- }
- }
- if (eaten <= 0) {
- queue_and_out:
- //如果没有能够直接拷贝到用户内存中,那么,插入receive队列吧,正如图1中的第1、3步
- __skb_queue_tail(&sk->sk_receive_queue, skb);
- }
- //更新待接收的序号,例如图1第1步中,更新为S2
- tp->rcv_nxt = TCP_SKB_CB(skb)->end_seq;
- //正如图1第4步,这时会检查out_of_order队列,若它不为空,需要处理它
- if (!skb_queue_empty(&tp->out_of_order_queue)) {
- //tcp_ofo_queue方法会检查out_of_order队列中的所有报文
- tcp_ofo_queue(sk);
- }
- }
- ... ...
- //这个包是无序的,又在接收滑动窗口内,那么就如图1第2步,把报文插入到out_of_order队列吧
- if (!skb_peek(&tp->out_of_order_queue)) {
- __skb_queue_head(&tp->out_of_order_queue,skb);
- } else {
- ... ...
- __skb_append(skb1, skb, &tp->out_of_order_queue);
- }
- }
图1第4步时,正是通过tcp_ofo_queue方法把之前乱序的S3-S4报文插入receive队列的。
- static void tcp_ofo_queue(struct sock *sk)
- {
- struct tcp_sock *tp = tcp_sk(sk);
- __u32 dsack_high = tp->rcv_nxt;
- struct sk_buff *skb;
- //遍历out_of_order队列
- while ((skb = skb_peek(&tp->out_of_order_queue)) != NULL) {
- ... ...
- //若这个报文可以按seq插入有序的receive队列中,则将其移出out_of_order队列
- __skb_unlink(skb, &tp->out_of_order_queue);
- //插入receive队列
- __skb_queue_tail(&sk->sk_receive_queue, skb);
- //更新socket上待接收的下一个有序seq
- tp->rcv_nxt = TCP_SKB_CB(skb)->end_seq;
- }
- }
- //参数里的len就是read、recv方法里的内存长度,flags正是方法的flags参数,nonblock则是阻塞、非阻塞标志位
- int tcp_recvmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg,
- size_t len, int nonblock, int flags, int *addr_len)
- {
- //锁住socket,防止多进程并发访问TCP连接,告知软中断目前socket在进程上下文中
- lock_sock(sk);
- //初始化errno这个错误码
- err = -ENOTCONN;
- //如果socket是阻塞套接字,则取出SO_RCVTIMEO作为读超时时间;若为非阻塞,则timeo为0。下面会看到timeo是如何生效的
- timeo = sock_rcvtimeo(sk, nonblock);
- //获取下一个要拷贝的字节序号
- //注意:seq的定义为u32 *seq;,它是32位指针。为何?因为下面每向用户态内存拷贝后,会更新seq的值,这时就会直接更改套接字上的copied_seq
- seq = &tp->copied_seq;
- //当flags参数有MSG_PEEK标志位时,意味着这次拷贝的内容,当再次读取socket时(比如另一个进程)还能再次读到
- if (flags & MSG_PEEK) {
- //所以不会更新copied_seq,当然,下面会看到也不会删除报文,不会从receive队列中移除报文
- peek_seq = tp->copied_seq;
- seq = &peek_seq;
- }
- //获取SO_RCVLOWAT最低接收阀值,当然,target实际上是用户态内存大小len和SO_RCVLOWAT的最小值
- //注意:flags参数中若携带MSG_WAITALL标志位,则意味着必须等到读取到len长度的消息才能返回,此时target只能是len
- target = sock_rcvlowat(sk, flags & MSG_WAITALL, len);
- //以下开始读取消息
- do {
- //从receive队列取出1个报文
- skb = skb_peek(&sk->sk_receive_queue);
- do {
- //没取到退出当前循环
- if (!skb)
- break;
- //offset是待拷贝序号在当前这个报文中的偏移量,在图1、2、3中它都是0,只有因为用户内存不足以接收完1个报文时才为非0
- offset = *seq - TCP_SKB_CB(skb)->seq;
- //有些时候,三次握手的SYN包也会携带消息内容的,此时seq是多出1的(SYN占1个序号),所以offset减1
- if (skb->h.th->syn)
- offset--;
- //若偏移量还有这个报文之内,则认为它需要处理
- if (offset < skb->len)
- goto found_ok_skb;
- skb = skb->next;
- } while (skb != (struct sk_buff *)&sk->sk_receive_queue);
- //如果receive队列为空,则检查已经拷贝的字节数,是否达到了SO_RCVLOWAT或者长度len。满足了,且backlog队列也为空,则可以返回用户态了,正如图1的第11步
- if (copied >= target && !sk->sk_backlog.tail)
- break;
- //在tcp_recvmsg里,copied就是已经拷贝的字节数
- if (copied) {
- ... ...
- } else {
- //一个字节都没拷贝到,但如果shutdown关闭了socket,一样直接返回。当然,本文不涉及关闭连接
- if (sk->sk_shutdown & RCV_SHUTDOWN)
- break;
- //如果使用了非阻塞套接字,此时timeo为0
- if (!timeo) {
- //非阻塞套接字读取不到数据时也会返回,错误码正是EAGAIN
- copied = -EAGAIN;
- break;
- }
- ... ...
- }
- //tcp_low_latency默认是关闭的,图1、图2都是如此,图3则例外,即图3不会走进这个if
- if (!sysctl_tcp_low_latency && tp->ucopy.task == user_recv) {
- //prequeue队列就是为了提高系统整体效率的,即prequeue队列有可能不为空,这是因为进程休眠等待时可能有新报文到达prequeue队列
- if (!skb_queue_empty(&tp->ucopy.prequeue))
- goto do_prequeue;
- }
- //如果已经拷贝了的字节数超过了最低阀值
- if (copied >= target) {
- //release_sock这个方法会遍历、处理backlog队列中的报文
- release_sock(sk);
- lock_sock(sk);
- } else
- sk_wait_data(sk, &timeo);//没有读取到足够长度的消息,因此会进程休眠,如果没有被唤醒,最长睡眠timeo时间
- if (user_recv) {
- if (tp->rcv_nxt == tp->copied_seq &&
- !skb_queue_empty(&tp->ucopy.prequeue)) {
- do_prequeue:
- //接上面代码段,开始处理prequeue队列里的报文
- tcp_prequeue_process(sk);
- }
- }
- //继续处理receive队列的下一个报文
- continue;
- found_ok_skb:
- /* Ok so how much can we use? */
- //receive队列的这个报文从其可以使用的偏移量offset,到总长度len之间,可以拷贝的长度为used
- used = skb->len - offset;
- //len是用户态空闲内存,len更小时,当然只能拷贝len长度消息,总不能导致内存溢出吧
- if (len < used)
- used = len;
- //MSG_TRUNC标志位表示不要管len这个用户态内存有多大,只管拷贝数据吧
- if (!(flags & MSG_TRUNC)) {
- {
- //向用户态拷贝数据
- err = skb_copy_datagram_iovec(skb, offset,
- msg->msg_iov, used);
- }
- }
- //因为是指针,所以同时更新copied_seq--下一个待接收的序号
- *seq += used;
- //更新已经拷贝的长度
- copied += used;
- //更新用户态内存的剩余空闲空间长度
- len -= used;
- ... ...
- } while (len > 0);
- //已经装载了接收器
- if (user_recv) {
- //prequeue队列不为空则处理之
- if (!skb_queue_empty(&tp->ucopy.prequeue)) {
- tcp_prequeue_process(sk);
- }
- //准备返回用户态,socket上不再装载接收任务
- tp->ucopy.task = NULL;
- tp->ucopy.len = 0;
- }
- //释放socket时,还会检查、处理backlog队列中的报文
- release_sock(sk);
- //向用户返回已经拷贝的字节数
- return copied;
- }

- int sk_wait_data(struct sock *sk, long *timeo)
- {
- //注意,它的自动唤醒条件有两个,要么timeo时间到达,要么receive队列不为空
- rc = sk_wait_event(sk, timeo, !skb_queue_empty(&sk->sk_receive_queue));
- }
sk_wait_event也值得我们简单看下:
- #define sk_wait_event(__sk, __timeo, __condition) \
- ({ int rc; \
- release_sock(__sk); \
- rc = __condition; \
- if (!rc) { \
- *(__timeo) = schedule_timeout(*(__timeo)); \
- } \
- lock_sock(__sk); \
- rc = __condition; \
- rc; \
- })
注意,它在睡眠前会调用release_sock,这个方法会释放socket锁,使得下面的第5步中,新到的报文不再只能进入backlog队列。
- void fastcall release_sock(struct sock *sk)
- {
- mutex_release(&sk->sk_lock.dep_map, 1, _RET_IP_);
- spin_lock_bh(&sk->sk_lock.slock);
- //这里会遍历backlog队列中的每一个报文
- if (sk->sk_backlog.tail)
- __release_sock(sk);
- //这里是网络中断执行时,告诉内核,现在socket并不在进程上下文中
- sk->sk_lock.owner = NULL;
- if (waitqueue_active(&sk->sk_lock.wq))
- wake_up(&sk->sk_lock.wq);
- spin_unlock_bh(&sk->sk_lock.slock);
- }
再看看__release_sock方法是如何遍历backlog队列的:
- static void __release_sock(struct sock *sk)
- {
- struct sk_buff *skb = sk->sk_backlog.head;
- //遍历backlog队列
- do {
- sk->sk_backlog.head = sk->sk_backlog.tail = NULL;
- bh_unlock_sock(sk);
- do {
- struct sk_buff *next = skb->next;
- skb->next = NULL;
- //处理报文,其实就是tcp_v4_do_rcv方法,上文介绍过,不再赘述
- sk->sk_backlog_rcv(sk, skb);
- cond_resched_softirq();
- skb = next;
- } while (skb != NULL);
- bh_lock_sock(sk);
- } while((skb = sk->sk_backlog.head) != NULL);
- }
此时遍历到S3-S4报文,但因为它是失序的,所以从backlog队列中移入out_of_order队列中(参见上文说过的tcp_ofo_queue方法)。
高性能网络编程4--TCP连接的关闭
版权声明:本文为博主原创文章,未经博主允许不得转载。
- #define __NR_close 3
- __SYSCALL(__NR_close, sys_close)
- #define __NR_shutdown 48
- __SYSCALL(__NR_shutdown, sys_shutdown)
但sys_close和sys_shutdown这两个系统调用最终是由tcp_close和tcp_shutdown方法来实现的,调用过程如下图所示:


- void fastcall fput(struct file *file)
- {
- if (atomic_dec_and_test(&file->f_count))//检查引用计数,直到为0才会真正去关闭socket
- __fput(file);
- }
当这个socket的引用计数f_count不为0时,是不会触发到真正关闭TCP连接的tcp_close方法的。
- static int copy_files(unsigned long clone_flags, struct task_struct * tsk)
- {
- if (clone_flags & CLONE_FILES) {
- goto out;//创建线程
- }
- newf = dup_fd(oldf, &error);
- out:
- return error;
- }
再看看dup_fd方法:
- static struct files_struct *dup_fd(struct files_struct *oldf, int *errorp)
- {
- for (i = open_files; i != 0; i--) {
- struct file *f = *old_fds++;
- if (f) {
- get_file(f);//创建进程
- }
- }
- }
get_file宏就会加引用计数。
- #define get_file(x) atomic_inc(&(x)->f_count)
所以,子进程会将父进程中已经建立的socket加上引用计数。当进程中close一个socket时,只会减少引用计数,仅当引用计数为0时才会触发tcp_close。
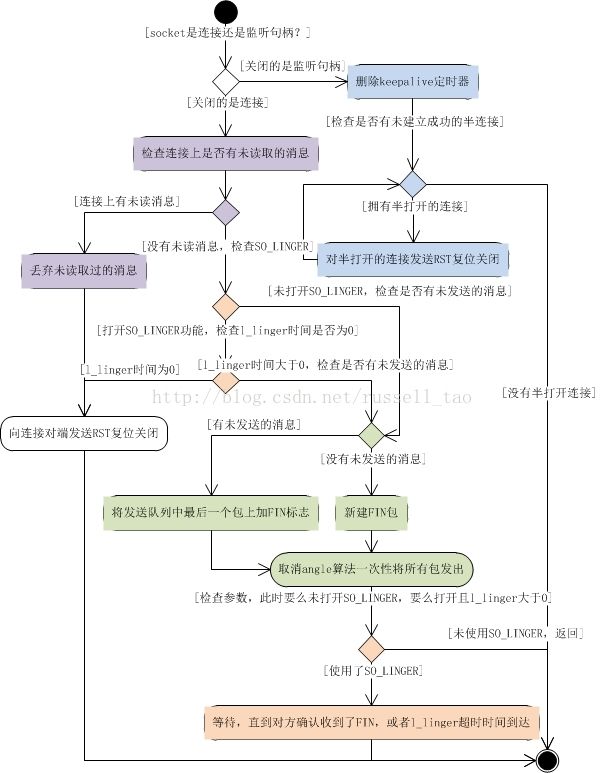
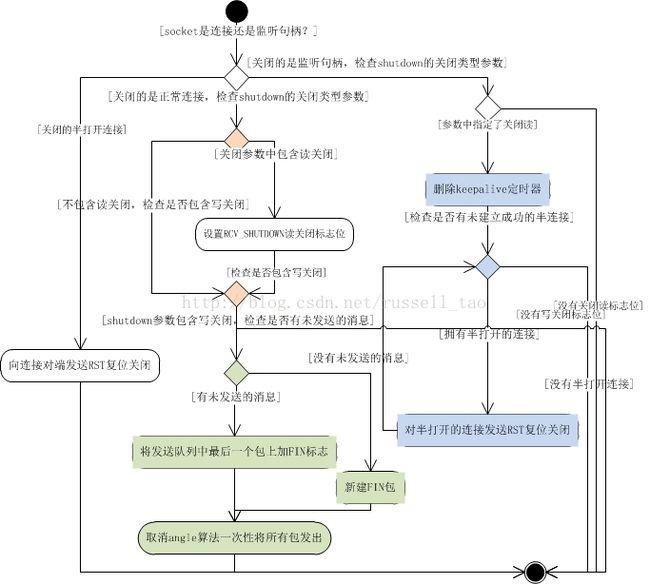

高性能网络编程5--IO复用与并发编程
版权声明:本文为博主原创文章,未经博主允许不得转载。


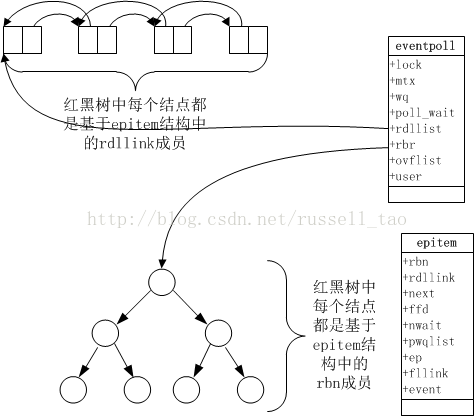

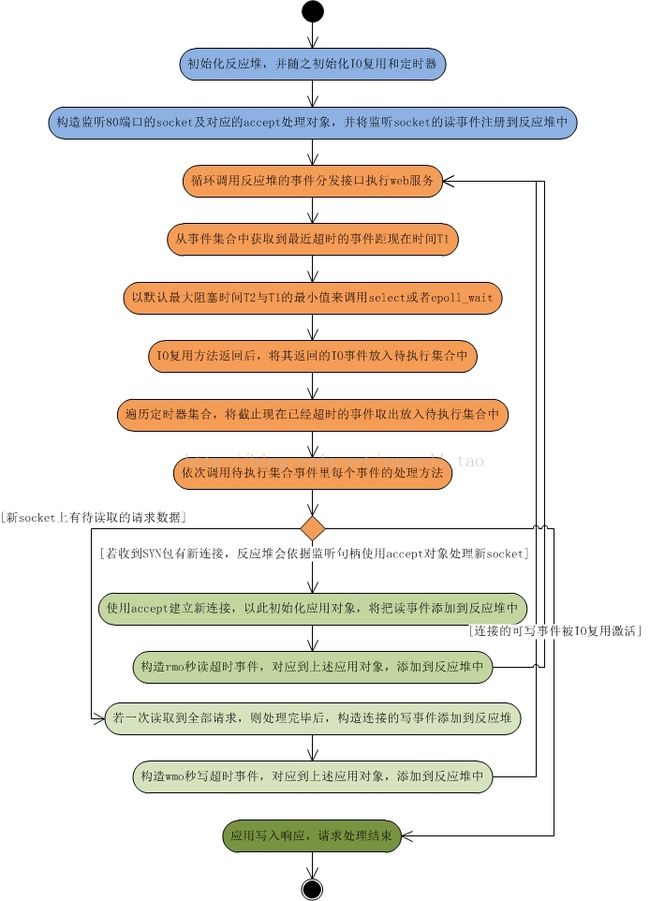
高性能网络编程6--reactor反应堆与定时器管理
版权声明:本文为博主原创文章,未经博主允许不得转载。

 这幅图有5点意思:
这幅图有5点意思:

高性能网络编程7--tcp连接的内存使用
版权声明:本文为博主原创文章,未经博主允许不得转载。
- net.ipv4.tcp_rmem = 8192 87380 16777216
- net.ipv4.tcp_wmem = 8192 65536 16777216
- net.ipv4.tcp_mem = 8388608 12582912 16777216
- net.core.rmem_default = 262144
- net.core.wmem_default = 262144
- net.core.rmem_max = 16777216
- net.core.wmem_max = 16777216
还有一些较少被提及的、也跟TCP内存相关的配置:
- net.ipv4.tcp_moderate_rcvbuf = 1
- net.ipv4.tcp_adv_win_scale = 2
(注:为方便下文讲述,介绍以上系统配置时前缀省略掉,配置值以空格分隔的多个数字以数组来称呼,例如tcp_rmem[2]表示上面第一行最后一列16777216。)
- 14:49:52.421674 IP houyi-vm02.dev.sd.aliyun.com.6400 > r14a02001.dg.tbsite.net.54073: S 2736789705:2736789705(0) ack 1609024383 win 5792
可以看到初始的接收窗口是5792,当然也远小于最大接收缓存(稍后介绍的tcp_rmem[1])。
- int init_cwnd = 4;
- if (mss > 1460*3)
- init_cwnd = 2;
- else if (mss > 1460)
- init_cwnd = 3;
- if (*rcv_wnd > init_cwnd*mss)
- *rcv_wnd = init_cwnd*mss;
大家可能要问,为何上面的抓包上显示窗口其实是5792,并不是1460*4为5840呢?这是因为1460想表达的意义是:将1500字节的MTU去除了20字节的IP头、20字节的TCP头以后,一个最大报文能够承载的有效数据长度。但有些网络中,会在TCP的可选头部里,使用12字节作为时间戳使用,这样,有效数据就是MSS再减去12,初始窗口就是(1460-12)*4=5792,这与窗口想表达的含义是一致的,即:我能够处理的有效数据长度。
- net.ipv4.tcp_adv_win_scale = 2
这里的 tcp_adv_win_scale意味着,将要拿出1/(2^ tcp_adv_win_scale )缓存出来做应用缓存。即,默认 tcp_adv_win_scale配置为2时,就是拿出至少1/4的内存用于应用读缓存,那么,最大的接收滑动窗口的大小只能到达读缓存的3/4。
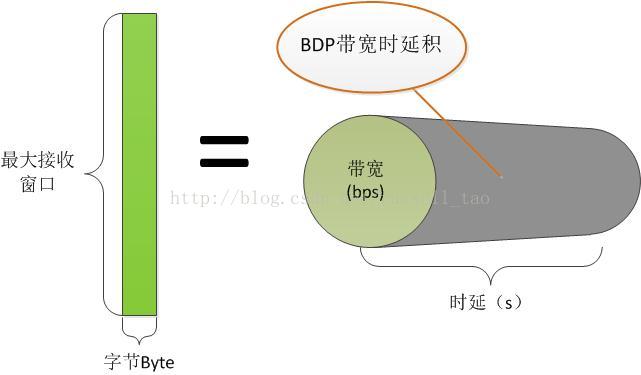

- net.ipv4.tcp_rmem = 8192 87380 16777216
- net.ipv4.tcp_wmem = 8192 65536 16777216
- net.ipv4.tcp_mem = 8388608 12582912 16777216
tcp_rmem[3]数组表示任何一个TCP连接上的读缓存上限,其中 tcp_rmem[0]表示最小上限, tcp_rmem[1]表示初始上限(注意,它会覆盖适用于所有协议的rmem_default配置), tcp_rmem[2]表示最大上限。

作者所属大学Baylor的网站,在相关的页面上提供了下载。
http://cs.ecs.baylor.edu/~donahoo/practical/CSockets2/textcode.html
后来发现这篇日志访问挺高的,干脆自己打个包放上来了。
http://files.cnblogs.com/wuyuegb2312/Sockets%E7%BC%96%E7%A8%8B%E6%BA%90%E7%A0%81.rar
初学Sockets编程(一) 基本的TCP套接字
前段时间刚开始学习《TCP/IP Sockets编程(C语言实现) (第2版)》一书,又被告知建议先去看一下《UNIX网络编程(第一卷)》的部分内容会对理解其理论知识有所帮助,于是稍微停滞了一下。几天前所练习的实例已经有所生疏,因此为了复习这部分内容(前面所提起的第一本书第2章),此文便作为复习笔记(书本关键内容摘录),而以后各章节的学习也希望能做到及时总结和复习。
本章示例的工作方式:客户连接服务器并发送它的数据;服务器简单地把它接收到的任何内容发送回客户并断开连接。
1.典型的TCP客户的通信步骤
⑴使用socket()创建TCP套接字
参数涉及地址族、使用的协议,正确创建返回一个句柄。
⑵使用connect()建立到达服务器的连接
参数涉及套接字句柄、服务器的地址结构中的地址和端口标识,其中地址结构需要强制转换为泛型类型。
⑶使用send()和recv()通信
send()参数涉及套接字句柄、发送内容、发送长度;返回值为发送的字节数,错误返回为-1。
recv()参数涉及套接字句柄、接收缓冲区、缓冲区大小、调用方式;返回值为接受的字节数,返回0表示另一端应用程序关闭了TCP连接,返回-1表示失败。
⑷使用close()关闭连接
示例为之前提供的下载页面的TCPEchoClient4.c。
2.基本的TCP服务器通信的常规步骤
⑴使用socket()创建TCP套接字
⑵利用bind()给套接字分配端口号
参数涉及套接字句柄、服务器的本机地址结构中的地址和端口标识,其中地址结构需要强制转换为泛型类型,如果不是非常关心所在地址可以用inaddr_any。
⑶使用listen()告诉系统允许对该端口建立连接
参数涉及套接字句柄、最大允许连接数。
⑷反复执行以下操作
- 调用accept()为每个客户连接获取新的套接字
参数涉及之前的套接字句柄,创建成功后即将填写的本机地址结构,该地址结构的长度,其中地址结构需要强制转换为泛型类型,返回一个新套接字的句柄。
- 使用send()和recv()通过新的套接字与客户通信
- 使用close()关闭客户连接
示例为之前提供的下载页面的TCPEchoServer4.c以及TCPServerUtility.c中的HandleTCPClient()。
3.指定地址
⑴通用地址
struct sockaddr {
sa_family_t sa_family; //Address family (e.g.,AF_INET)
char sa_data[14];
};
⑵IPv4地址

struct in_addr { uint32_t s_addr; }; struct sockaddr_in { sa_family_t sin_family; //Internet protocol (AF_INET) in_port_t sin_port; //Address port (16bits) struct in_addr sin_addr; //IPv4 address (32bits) char sin_zero[8]; //Not used };
⑶IPv6地址(已按照上一篇文章更改)
struct in_addr { uint8_t s_addr[16];//Internet address(128bits) }; struct sockaddr_in6 { sa_family_t sin6_family; //Internet protocol(AF_INET6) in_port_t sin6_port; //Address port(16bits) uint32_t sin6_flowinfo; //Flow information struct in6_addr sin6_addr;//IPv6 address (128bits) uint32_t sin6_scope_id; //Scope identifier };
⑷地址转换
int inet_pton(int addressFamily, constchar*src , void*dst) //把地址从可打印的字符串(*src)转换为数字(dst引用的地址) constchar*inet_ntop(int addressFamily, constvoid*src, char*dst,socklen_t dstBytes) //把地址从数字转化为可打印的形式
⑸获取套接字的关联地址
int getpeername(int socket, struct sockaddr *remoteAddress, socklen_t (addressLength) int getsockname(int socket, struct sockaddr (localAddress, socklen_t (addressLength)
4.其他
为了便于在同一台计算机的终端上进行调试,需要先在后台执行服务器程序(参数等所有内容的最后面加一个&),再执行客户机程序,发送到127.0.0.1即可。相关调试时用到的进程操作还有ps(查看当前运行进程)、kill(关闭进程)。
初学Sockets编程(二) 关于名称和地址族
这一章的核心内容是getaddrinfo()函数。
int getaddrinfo(constchar*hostStr, constchar* serviceStr, conststruct addrinfo *hints,
struct addrinfo **results)
//需要配合下面函数进行使用
void freeaddrinfo(struct addrinfo *addrList) //释放创建的结果链表
const char *gai_strerror(int errorCode) //如果getaddrinfo返回非0值,可以描述出错的是什么
含义:
hostStr 主机名称或地址,以NULL结尾的字符串
serviceStr 服务名称或端口号,以NULL结尾的字符串
hints 要返回信息的种类,可以实现选择
results 存储一个指向包含结果的链表的指针
对于addrinfo结构,如下所示:
struct addrinfo { int ai_flags;//Flags to control info resolution int ai_family;//Family:AF_INET,AF_INET6,AF_UNSPEC int ai_socktype;//Socket type:SOCK_STREAM,SOCK_DGRAM int ai_protocol;//Protocol: 0(default) or IPPROTO_XXX socklen_t ai_addrlen;//Length of socket address ai_addr struct sockaddr *ai_addr;//Socket address for socket char*ai_canonname;//Canonical name struct addrinfo *ai_next;//Next addrinfo in linked list };
利用getaddrinfo()函数编写出的SetupTCPClientSocket()和SetupTCPServerSocket()可以很方便地隐藏IPv4和IPv6地址的差异,根据它重写的TCPEchoClient.c和TCPEchoServer.c就可以同时处理两种类型的地址了。
本章最后还提到了从Internet地址获取主机名称的getnameinfo()和获取自己主机名称的gethostname(),不再详述。
初学Sockets编程(三) UDP套接字
UDP的过程通信看上去比TCP简单一些,但也有许多细节需要注意。比如,UDP套接字使用前不必连接,TCP类似于电话通信,UDP类似于邮件通信,UDP套接字就像一个邮箱,可以把许多不同来源的信件或包裹放入其中。因此,在示例UDPEchoClient.c中,是需要用SockAddrsEqual()来检测回送的数据包是否是之前所送往的服务器回送的,尽管在示例中不太可能出现这种情况。
程序使用的地址结构、套接字的创建还是与TCP相差无几。由于没有建立连接的步骤,不需要调用listen(),一旦套接字具有地址就准备好接受消息。同时UDP也不需要使用accept()为每个客户获取一个新的套接字,而是利用绑定到想要端口号的相同套接字立即调用recvfrom()。这样,在接收数据报的同时需要获知起来源。以下是发送和接收用到的函数。
ssize_t sendto(int socket, constvoid*msg, size_t msgLength, int flags, conststruct sockaddr *destAddr, socklen_t addrLen)
//前4个参数与send()相同,另外两个指向消息的目的地
ssize_t recvfrom(int socket, void*msg, size_t msgLength, int flags, struct sockaddr *srcAddr,socklen_t *addrLen)
//前4个参数与recv()相同,另外两个告知调用者所接受的数据报的来源
//addrLen是一个输入/输出型的参数,需要传递一个指针
TCP 调用send()时,数据已经复制进缓冲区中以进行传输,可能不会实际的传输;UDP不会重传,这意味着当其调用sendto()时,就已经把消息传递给底层,并且已经(或者很快将要)发送出去。
UDP对不同消息的字节保留边界,recvfrom()不会返回多个数据块。当参数设定小于第一个数据块大小时,剩余字节将会被丢弃而无指示。因此缓冲区应该大于协议允许的最大消息,其最大负载是65507字节。
UDP 套接字上调用connect()可以用于固定通过套接字发送的将来数据报的目的地址。一旦连接,可以用send()代替sendto()、recv()代替recvfrom(),但这不改变UDP的行为方式。
初学Sockets编程(四) 发送和接收数据
放假归来,半个月没看书了,稍微有些生疏。被安排了新的工作,老的自学任务还需继续完成。
这一章内容比较多,按小节整理了一下。
一、编码整数
1.整数型的大小
由通信过程双方交换信息的协议标准引申出了编码的整数,进而探讨了各个整数类型的大小(char、int、long、int8_t、uint8_t等)、获取它们的长度的方法——sizeof()、并且有一个简单的程序示例TestSizes.c来展示。
2.传输顺序
多个字节编码的整数,是从最高有效位(大端、左端)还是从最低有效位(小端、右端)发送,也是传输双方需要协调的。大多数协议使用大端顺序,因此它也被称为网络字节顺序。
3.符号扩展
利用补码进行符号扩展;不同长度的数据类型复制时的补位。
这一小节使用了一个例子BruteForceCoding.c来展示如何进行移位和掩码操作,相当繁琐。
4.在流中包装套接字
使用fdopen、fclose、fflush。
5.结构填充
优化结构成员的排列顺序可以避免一些不必要的填充。或者,安排额外的结构成员使得其成为可控制的填充部分。
这一部分是一个示例。为了便于复习,把各个组件功能注释一下。与前几章不同的是,这里没有用类似receive()这样的函数,而是采用流的方式进行处理。
VoteClientTCP.c 客户端,用于发送请求。请求有两种,投票和质询。
VoteServerTCP.c 服务器端,接收请求,并根据不同请求,修改或仅查询服务器端数据,并回送。
DelimFramer.c 基于界定符成帧,包含了从流复制字节到缓冲区直到遇到界定符的GetNextMsg( )和根据界定符把缓冲区字节复制到流中的PutMsg( )。
LengthFramer.c 基于长度成帧,包含的两个函数与DelimFramer.c提供的两个函数同名,不同的是它们基于长度成帧。此时消息格式有所不同,按照前面的约定,两个字节的前缀中保存了这个消息的长度。
VoteEncodingText.c 基于文本进行消息编码,包含把序列转化为消息结构的Encode( )和把消息结构转化为字节序列的Decode( )。其中用到的strtok( )第一次分割后,每次分割都要利用NULL作为第一个参数;strtoll( )的用法如下:
longlongint strtoll(constchar*nptr, char**endptr, intbase);
//把nptr按照以base为进制进行转换。endptr非空时把第一个无效字符存放至endptr。参考资料
VoteEncodingBin.c 基于二进制消息编码,包含的两个函数与VoteEncodingText.c提供的两个函数同名,不同的是使用固定大小的消息。
这样,把VoteServerTCP.c、两个成帧模块之一、两个编码模块之一以及辅助模块DieWithMessage.c、TCPClientUtility.c、TCPServerUtility.c和AddressUtility.c一起编译即可获得服务器程序。客户端同理,两者需要使用相同的组合。
p.s.第五章程序尚未测试,由于有其它项目需要进行,暂时搁置TCP/IP Socket编程的学习。
高性能网络编程总结及《TCP/IP Sockets编程(C语言实现) (第2版)》 代码下载(链接以及文件打包)
目录(?)[+]
http://blog.csdn.NET/column/details/high-perf-network.html
http://blog.csdn.net/russell_tao/article/details/9111769
高性能网络编程(一)----accept建立连接
高性能网络编程2----TCP消息的发送
版权声明:本文为博主原创文章,未经博主允许不得转载。
- wait_for_memory:
- if (copied)
- tcp_push(sk, tp, flags & ~MSG_MORE, mss_now, TCP_NAGLE_PUSH);
- if ((err = sk_stream_wait_memory(sk, &timeo)) != 0)
- goto do_error;
这里的 sk_stream_wait_memory方法接受一个参数timeo,就是等待超时的时间。这个时间是tcp_sendmsg方法刚开始就拿到的,如下:
- timeo = sock_sndtimeo(sk, flags & MSG_DONTWAIT);
看看其实现:
- static inline long sock_sndtimeo(const struct sock *sk, int noblock)
- {
- return noblock ? 0 : sk->sk_sndtimeo;
- }
也就是说,当这个套接字是阻塞套接字时,timeo就是SO_SNDTIMEO选项指定的发送超时时间。如果这个套接字是非阻塞套接字, timeo变量就会是0。
- //检查这一次要发送的报文最大序号是否超出了发送滑动窗口大小
- static inline int tcp_snd_wnd_test(struct tcp_sock *tp, struct sk_buff *skb, unsigned int cur_mss)
- {
- //end_seq待发送的最大序号
- u32 end_seq = TCP_SKB_CB(skb)->end_seq;
- if (skb->len > cur_mss)
- end_seq = TCP_SKB_CB(skb)->seq + cur_mss;
- //snd_una是已经发送过的数据中,最小的没被确认的序号;而snd_wnd就是发送窗口的大小
- return !after(end_seq, tp->snd_una + tp->snd_wnd);
- }
- static inline unsigned int tcp_cwnd_test(struct tcp_sock *tp, struct sk_buff *skb)
- {
- u32 in_flight, cwnd;
- /* Don't be strict about the congestion window for the final FIN. */
- if (TCP_SKB_CB(skb)->flags & TCPCB_FLAG_FIN)
- return 1;
- //飞行中的数据,也就是没有ACK的字节总数
- in_flight = tcp_packets_in_flight(tp);
- cwnd = tp->snd_cwnd;
- //如果拥塞窗口允许,需要返回依据拥塞窗口的大小,还能发送多少字节的数据
- if (in_flight < cwnd)
- return (cwnd - in_flight);
- return 0;
- }
再通过tcp_window_allows方法获取拥塞窗口与滑动窗口的最小长度,检查待发送的数据是否超出:
- static unsigned int tcp_window_allows(struct tcp_sock *tp, struct sk_buff *skb, unsigned int mss_now, unsigned int cwnd)
- {
- u32 window, cwnd_len;
- window = (tp->snd_una + tp->snd_wnd - TCP_SKB_CB(skb)->seq);
- cwnd_len = mss_now * cwnd;
- return min(window, cwnd_len);
- }
- static inline int tcp_nagle_test(struct tcp_sock *tp, struct sk_buff *skb,
- unsigned int cur_mss, int nonagle)
- {
- //nonagle标志位设置了,返回1表示允许这个分组发送出去
- if (nonagle & TCP_NAGLE_PUSH)
- return 1;
- //如果这个分组包含了四次握手关闭连接的FIN包,也可以发送出去
- if (tp->urg_mode ||
- (TCP_SKB_CB(skb)->flags & TCPCB_FLAG_FIN))
- return 1;
- //检查Nagle算法
- if (!tcp_nagle_check(tp, skb, cur_mss, nonagle))
- return 1;
- return 0;
- }
再来看看 tcp_nagle_check方法,它与上一个方法不同,返回0表示可以发送,返回非0则不可以,正好相反。
- static inline int tcp_nagle_check(const struct tcp_sock *tp,
- const struct sk_buff *skb,
- unsigned mss_now, int nonagle)
- {
- //先检查是否为小分组,即报文长度是否小于MSS
- return (skb->len < mss_now &&
- ((nonagle&TCP_NAGLE_CORK) ||
- //如果开启了Nagle算法
- (!nonagle &&
- //若已经有小分组发出(packets_out表示“飞行”中的分组)还没有确认
- tp->packets_out &&
- tcp_minshall_check(tp))));
- }
最后看看tcp_minshall_check做了些什么:
- static inline int tcp_minshall_check(const struct tcp_sock *tp)
- {
- //最后一次发送的小分组还没有被确认
- return after(tp->snd_sml,tp->snd_una) &&
- //将要发送的序号是要大于等于上次发送分组对应的序号
- !after(tp->snd_sml, tp->snd_nxt);
- }
想象一种场景,当对请求的时延非常在意且网络环境非常好的时候(例如同一个机房内),Nagle算法可以关闭,这实在也没必要。使用TCP_NODELAY套接字选项就可以关闭Nagle算法。看看setsockopt是怎么与上述方法配合工作的:
- static int do_tcp_setsockopt(struct sock *sk, int level,
- int optname, char __user *optval, int optlen)
- ...
- switch (optname) {
- ...
- case TCP_NODELAY:
- if (val) {
- //如果设置了TCP_NODELAY,则更新nonagle标志
- tp->nonagle |= TCP_NAGLE_OFF|TCP_NAGLE_PUSH;
- tcp_push_pending_frames(sk, tp);
- } else {
- tp->nonagle &= ~TCP_NAGLE_OFF;
- }
- break;
- }
- }
可以看到,nonagle标志位就是这么更改的。
高性能网络编程3----TCP消息的接收
版权声明:本文为博主原创文章,未经博主允许不得转载。
- int tcp_v4_rcv(struct sk_buff *skb)
- {
- ... ...
- //是否有进程正在使用这个套接字,将会对处理流程产生影响
- //或者从代码层面上,只要在tcp_recvmsg里,执行lock_sock后只能进入else,而release_sock后会进入if
- if (!sock_owned_by_user(sk)) {
- {
- //当 tcp_prequeue 返回0时,表示这个函数没有处理该报文
- if (!tcp_prequeue(sk, skb))//如果报文放在prequeue队列,即表示延后处理,不占用软中断过长时间
- ret = tcp_v4_do_rcv(sk, skb);//不使用prequeue或者没有用户进程读socket时(图3进入此分支),立刻开始处理这个报文
- }
- } else
- sk_add_backlog(sk, skb);//如果进程正在操作套接字,就把skb指向的TCP报文插入到backlog队列(图3涉及此分支)
- ... ...
- }
图1第1步里,我们从网络上收到了序号为S1-S2的包。此时,没有用户进程在读取套接字,因此,sock_owned_by_user(sk)会返回0。所以,tcp_prequeue方法将得到执行。简单看看它:
- static inline int tcp_prequeue(struct sock *sk, struct sk_buff *skb)
- {
- struct tcp_sock *tp = tcp_sk(sk);
- //检查tcp_low_latency,默认其为0,表示使用prequeue队列。tp->ucopy.task不为0,表示有进程启动了拷贝TCP消息的流程
- if (!sysctl_tcp_low_latency && tp->ucopy.task) {
- //到这里,通常是用户进程读数据时没读到指定大小的数据,休眠了。直接将报文插入prequeue队列的末尾,延后处理
- __skb_queue_tail(&tp->ucopy.prequeue, skb);
- tp->ucopy.memory += skb->truesize;
- //当然,虽然通常是延后处理,但如果TCP的接收缓冲区不够用了,就会立刻处理prequeue队列里的所有报文
- if (tp->ucopy.memory > sk->sk_rcvbuf) {
- while ((skb1 = __skb_dequeue(&tp->ucopy.prequeue)) != NULL) {
- //sk_backlog_rcv就是下文将要介绍的tcp_v4_do_rcv方法
- sk->sk_backlog_rcv(sk, skb1);
- }
- } else if (skb_queue_len(&tp->ucopy.prequeue) == 1) {
- //prequeue里有报文了,唤醒正在休眠等待数据的进程,让进程在它的上下文中处理这个prequeue队列的报文
- wake_up_interruptible(sk->sk_sleep);
- }
- return 1;
- }
- //prequeue没有处理
- return 0;
- }
由于tp->ucopy.task此时是NULL,所以我们收到的第1个报文在tcp_prequeue函数里直接返回了0,因此,将由 tcp_v4_do_rcv方法处理。
- int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
- {
- if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */
- //当TCP连接已经建立好时,是由tcp_rcv_established方法处理接收报文的
- if (tcp_rcv_established(sk, skb, skb->h.th, skb->len))
- goto reset;
- return 0;
- }
- ... ...
- }
tcp_rcv_established方法在图1里,主要调用tcp_data_queue方法将报文放入队列中,继续看看它又干了些什么事:
- static void tcp_data_queue(struct sock *sk, struct sk_buff *skb)
- {
- struct tcp_sock *tp = tcp_sk(sk);
- //如果这个报文是待接收的报文(看seq),它有两个出路:进入receive队列,正如图1;直接拷贝到用户内存中,如图3
- if (TCP_SKB_CB(skb)->seq == tp->rcv_nxt) {
- //滑动窗口外的包暂不考虑,篇幅有限,下次再细谈
- if (tcp_receive_window(tp) == 0)
- goto out_of_window;
- //如果有一个进程正在读取socket,且正准备要拷贝的序号就是当前报文的seq序号
- if (tp->ucopy.task == current &&
- tp->copied_seq == tp->rcv_nxt && tp->ucopy.len &&
- sock_owned_by_user(sk) && !tp->urg_data) {
- //直接将报文内容拷贝到用户态内存中,参见图3
- if (!skb_copy_datagram_iovec(skb, 0, tp->ucopy.iov, chunk)) {
- tp->ucopy.len -= chunk;
- tp->copied_seq += chunk;
- }
- }
- if (eaten <= 0) {
- queue_and_out:
- //如果没有能够直接拷贝到用户内存中,那么,插入receive队列吧,正如图1中的第1、3步
- __skb_queue_tail(&sk->sk_receive_queue, skb);
- }
- //更新待接收的序号,例如图1第1步中,更新为S2
- tp->rcv_nxt = TCP_SKB_CB(skb)->end_seq;
- //正如图1第4步,这时会检查out_of_order队列,若它不为空,需要处理它
- if (!skb_queue_empty(&tp->out_of_order_queue)) {
- //tcp_ofo_queue方法会检查out_of_order队列中的所有报文
- tcp_ofo_queue(sk);
- }
- }
- ... ...
- //这个包是无序的,又在接收滑动窗口内,那么就如图1第2步,把报文插入到out_of_order队列吧
- if (!skb_peek(&tp->out_of_order_queue)) {
- __skb_queue_head(&tp->out_of_order_queue,skb);
- } else {
- ... ...
- __skb_append(skb1, skb, &tp->out_of_order_queue);
- }
- }
图1第4步时,正是通过tcp_ofo_queue方法把之前乱序的S3-S4报文插入receive队列的。
- static void tcp_ofo_queue(struct sock *sk)
- {
- struct tcp_sock *tp = tcp_sk(sk);
- __u32 dsack_high = tp->rcv_nxt;
- struct sk_buff *skb;
- //遍历out_of_order队列
- while ((skb = skb_peek(&tp->out_of_order_queue)) != NULL) {
- ... ...
- //若这个报文可以按seq插入有序的receive队列中,则将其移出out_of_order队列
- __skb_unlink(skb, &tp->out_of_order_queue);
- //插入receive队列
- __skb_queue_tail(&sk->sk_receive_queue, skb);
- //更新socket上待接收的下一个有序seq
- tp->rcv_nxt = TCP_SKB_CB(skb)->end_seq;
- }
- }
- //参数里的len就是read、recv方法里的内存长度,flags正是方法的flags参数,nonblock则是阻塞、非阻塞标志位
- int tcp_recvmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg,
- size_t len, int nonblock, int flags, int *addr_len)
- {
- //锁住socket,防止多进程并发访问TCP连接,告知软中断目前socket在进程上下文中
- lock_sock(sk);
- //初始化errno这个错误码
- err = -ENOTCONN;
- //如果socket是阻塞套接字,则取出SO_RCVTIMEO作为读超时时间;若为非阻塞,则timeo为0。下面会看到timeo是如何生效的
- timeo = sock_rcvtimeo(sk, nonblock);
- //获取下一个要拷贝的字节序号
- //注意:seq的定义为u32 *seq;,它是32位指针。为何?因为下面每向用户态内存拷贝后,会更新seq的值,这时就会直接更改套接字上的copied_seq
- seq = &tp->copied_seq;
- //当flags参数有MSG_PEEK标志位时,意味着这次拷贝的内容,当再次读取socket时(比如另一个进程)还能再次读到
- if (flags & MSG_PEEK) {
- //所以不会更新copied_seq,当然,下面会看到也不会删除报文,不会从receive队列中移除报文
- peek_seq = tp->copied_seq;
- seq = &peek_seq;
- }
- //获取SO_RCVLOWAT最低接收阀值,当然,target实际上是用户态内存大小len和SO_RCVLOWAT的最小值
- //注意:flags参数中若携带MSG_WAITALL标志位,则意味着必须等到读取到len长度的消息才能返回,此时target只能是len
- target = sock_rcvlowat(sk, flags & MSG_WAITALL, len);
- //以下开始读取消息
- do {
- //从receive队列取出1个报文
- skb = skb_peek(&sk->sk_receive_queue);
- do {
- //没取到退出当前循环
- if (!skb)
- break;
- //offset是待拷贝序号在当前这个报文中的偏移量,在图1、2、3中它都是0,只有因为用户内存不足以接收完1个报文时才为非0
- offset = *seq - TCP_SKB_CB(skb)->seq;
- //有些时候,三次握手的SYN包也会携带消息内容的,此时seq是多出1的(SYN占1个序号),所以offset减1
- if (skb->h.th->syn)
- offset--;
- //若偏移量还有这个报文之内,则认为它需要处理
- if (offset < skb->len)
- goto found_ok_skb;
- skb = skb->next;
- } while (skb != (struct sk_buff *)&sk->sk_receive_queue);
- //如果receive队列为空,则检查已经拷贝的字节数,是否达到了SO_RCVLOWAT或者长度len。满足了,且backlog队列也为空,则可以返回用户态了,正如图1的第11步
- if (copied >= target && !sk->sk_backlog.tail)
- break;
- //在tcp_recvmsg里,copied就是已经拷贝的字节数
- if (copied) {
- ... ...
- } else {
- //一个字节都没拷贝到,但如果shutdown关闭了socket,一样直接返回。当然,本文不涉及关闭连接
- if (sk->sk_shutdown & RCV_SHUTDOWN)
- break;
- //如果使用了非阻塞套接字,此时timeo为0
- if (!timeo) {
- //非阻塞套接字读取不到数据时也会返回,错误码正是EAGAIN
- copied = -EAGAIN;
- break;
- }
- ... ...
- }
- //tcp_low_latency默认是关闭的,图1、图2都是如此,图3则例外,即图3不会走进这个if
- if (!sysctl_tcp_low_latency && tp->ucopy.task == user_recv) {
- //prequeue队列就是为了提高系统整体效率的,即prequeue队列有可能不为空,这是因为进程休眠等待时可能有新报文到达prequeue队列
- if (!skb_queue_empty(&tp->ucopy.prequeue))
- goto do_prequeue;
- }
- //如果已经拷贝了的字节数超过了最低阀值
- if (copied >= target) {
- //release_sock这个方法会遍历、处理backlog队列中的报文
- release_sock(sk);
- lock_sock(sk);
- } else
- sk_wait_data(sk, &timeo);//没有读取到足够长度的消息,因此会进程休眠,如果没有被唤醒,最长睡眠timeo时间
- if (user_recv) {
- if (tp->rcv_nxt == tp->copied_seq &&
- !skb_queue_empty(&tp->ucopy.prequeue)) {
- do_prequeue:
- //接上面代码段,开始处理prequeue队列里的报文
- tcp_prequeue_process(sk);
- }
- }
- //继续处理receive队列的下一个报文
- continue;
- found_ok_skb:
- /* Ok so how much can we use? */
- //receive队列的这个报文从其可以使用的偏移量offset,到总长度len之间,可以拷贝的长度为used
- used = skb->len - offset;
- //len是用户态空闲内存,len更小时,当然只能拷贝len长度消息,总不能导致内存溢出吧
- if (len < used)
- used = len;
- //MSG_TRUNC标志位表示不要管len这个用户态内存有多大,只管拷贝数据吧
- if (!(flags & MSG_TRUNC)) {
- {
- //向用户态拷贝数据
- err = skb_copy_datagram_iovec(skb, offset,
- msg->msg_iov, used);
- }
- }
- //因为是指针,所以同时更新copied_seq--下一个待接收的序号
- *seq += used;
- //更新已经拷贝的长度
- copied += used;
- //更新用户态内存的剩余空闲空间长度
- len -= used;
- ... ...
- } while (len > 0);
- //已经装载了接收器
- if (user_recv) {
- //prequeue队列不为空则处理之
- if (!skb_queue_empty(&tp->ucopy.prequeue)) {
- tcp_prequeue_process(sk);
- }
- //准备返回用户态,socket上不再装载接收任务
- tp->ucopy.task = NULL;
- tp->ucopy.len = 0;
- }
- //释放socket时,还会检查、处理backlog队列中的报文
- release_sock(sk);
- //向用户返回已经拷贝的字节数
- return copied;
- }
- int sk_wait_data(struct sock *sk, long *timeo)
- {
- //注意,它的自动唤醒条件有两个,要么timeo时间到达,要么receive队列不为空
- rc = sk_wait_event(sk, timeo, !skb_queue_empty(&sk->sk_receive_queue));
- }
sk_wait_event也值得我们简单看下:
- #define sk_wait_event(__sk, __timeo, __condition) \
- ({ int rc; \
- release_sock(__sk); \
- rc = __condition; \
- if (!rc) { \
- *(__timeo) = schedule_timeout(*(__timeo)); \
- } \
- lock_sock(__sk); \
- rc = __condition; \
- rc; \
- })
注意,它在睡眠前会调用release_sock,这个方法会释放socket锁,使得下面的第5步中,新到的报文不再只能进入backlog队列。
- void fastcall release_sock(struct sock *sk)
- {
- mutex_release(&sk->sk_lock.dep_map, 1, _RET_IP_);
- spin_lock_bh(&sk->sk_lock.slock);
- //这里会遍历backlog队列中的每一个报文
- if (sk->sk_backlog.tail)
- __release_sock(sk);
- //这里是网络中断执行时,告诉内核,现在socket并不在进程上下文中
- sk->sk_lock.owner = NULL;
- if (waitqueue_active(&sk->sk_lock.wq))
- wake_up(&sk->sk_lock.wq);
- spin_unlock_bh(&sk->sk_lock.slock);
- }
再看看__release_sock方法是如何遍历backlog队列的:
- static void __release_sock(struct sock *sk)
- {
- struct sk_buff *skb = sk->sk_backlog.head;
- //遍历backlog队列
- do {
- sk->sk_backlog.head = sk->sk_backlog.tail = NULL;
- bh_unlock_sock(sk);
- do {
- struct sk_buff *next = skb->next;
- skb->next = NULL;
- //处理报文,其实就是tcp_v4_do_rcv方法,上文介绍过,不再赘述
- sk->sk_backlog_rcv(sk, skb);
- cond_resched_softirq();
- skb = next;
- } while (skb != NULL);