C++ string实现原理
C++程序员编码过程中经常会使用string(wstring)类,你是否思考过它的内部实现细节。比如这个类的迭代器是如何实现的?对象占多少字节的内存空间?内部有没有虚函数?内存是如何分配的?构造和析构的成本有多大?笔者综合这两天阅读的源代码及个人理解简要介绍之,错误的地方望读者指出。
首先看看string和wstring类的定义:
typedef basic_string, allocator > string;
typedef basic_string allocator > wstring; 从这个定义可以看出string和wstring分别是模板类basic_string对char和wchar_t的特化。
再看看basic_string类的继承关系(类方法未列出):
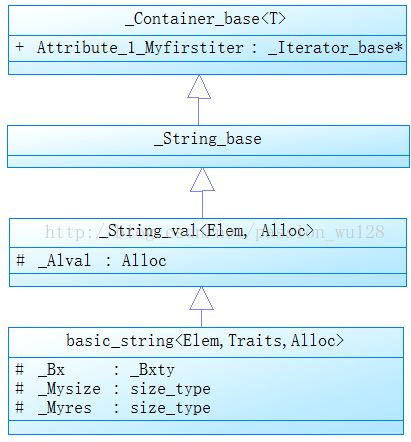
最顶层的类是_Container_base,它也是STL容器的基类,Debug下包含一个_Iterator_base*的成员,指向容器的最开始的元素,这样就能遍历容器了,并定义了了两个函数
void _Orphan_all() const; // orphan all iterators
void _Swap_all(_Container_base_secure&) const; // swaps all iteratorsRelease下_Container_base只是一个空的类。
_String_base类没有数据成员,只定义了异常处理的三个函数:
static void _Xlen(); // report a length_error
static void _Xran(); // report an out_of_range error
static void _Xinvarg();上面三个基类都定义得很简单,而basic_string类的实现非常复杂。不过它的设计和大多数标准库一样,把复杂的功能分成几部分去实现,充分体现了模块的低耦合。
迭代器有关的操作交给_String_iterator类去实现,元素相关的操作交给char_traits类去实现,内存分配交给allocator类去实现。
_String_iterator类的继承关系如下图:

这个类实现了迭代器的通用操作,比如:
reference operator*() const;
pointer operator->() const
_String_iterator & operator++()
_String_iterator operator++(int)
_String_iterator& operator--()
_String_iterator operator--(int)
_String_iterator& operator+=(difference_type _Off)
_String_iterator operator+(difference_type _Off) const
_String_iterator& operator-=(difference_type _Off)
_String_iterator operator-(difference_type _Off) const
difference_type operator-(const _Mybase& _Right) const
reference operator[](difference_type _Off) const有了迭代器的实现,就可以很方便的使用算法库里面的函数了,比如将所有字符转换为小写:
string s("Hello String");
transform(s.begin(), s.end(), s.begin(), tolower); 
这个类定义了字符的赋值,拷贝,比较等操作,如果有特殊需求也可以重新定义这个类。
allocator类图如下:

这个类使用new和delete完成内存的分配与释放等操作。你也可以定义自己的allocator,msdn上有介绍哪些方法是必须定义的。
再看看basic_string类的数据成员:
_Mysize表示实际的元素个数,初始值为0;
_Myres表示当前可以存储的最大元素个数(超过这个大小就要重新分配内存),初始值是_BUF_SIZE-1;
_BUF_SIZE是一个enum类型:
enum
{ // length of internal buffer, [1, 16]
_BUF_SIZE = 16 / sizeof (_Elem) < 1 ? 1: 16 / sizeof(_Elem)
};_Bxty是一个union:
union _Bxty
{ // storage for small buffer or pointer to larger one
_Elem _Buf[_BUF_SIZE];
_Elem *_Ptr;
} _Bx;为什么要那样定义_Bxty呢,看下面这段代码:
_Elem * _Myptr()
{ // determine current pointer to buffer for mutable string
return (_BUF_SIZE <= _Myres ? _Bx._Ptr : _Bx._Buf);
}所以当元素个数小于_BUF_SIZE时不用分配内存,直接使用_Buf数组,_Myptr返回_Buf。否则就要分配内存了,_Myptr返回_Ptr。
不过内存分配策略又是怎样的呢?看下面这段代码:
void _Copy(size_type _Newsize, size_type _Oldlen)
{ // copy _Oldlen elements to newly allocated buffer
size_type _Newres = _Newsize | _ALLOC_MASK;
if (max_size() < _Newres)
_Newres = _Newsize; // undo roundup if too big
else if (_Newres / 3 < _Myres / 2 && _Myres <= max_size() - _Myres / 2)
_Newres = _Myres + _Myres / 2; // grow exponentially if possible
//other code
}针对char和wchar_t,每次分配内存的临界值分别是(超过这些值就要重新分配):
char:15,31,47,70,105,157,235,352,528,792,1188,1782。。。
wchar_t:7, 15, 23, 34, 51, 76, 114, 171, 256, 384, 576, 864, 1296, 1944。。。
重新分配后都会先将旧的元素拷贝到新的内存地址。所以当处理一个长度会不断增长而又大概知道最大大小时可以先调用reserve函数预分配内存以提高效率。
string类占多少字节的内存空间呢?
_Container_base Debug下含有一个指针,4字节,Release下是空类,0字节。_String_val类含有一个allocator对象。string类使用默认的allocator类,这个类没有数据成员,不过按字节对齐的原则,它占4字节。basic_string类的成员加起来是24,所以总共是32字节(Debug)或28字节(Relase)。wstring也是32或28,至于原因文中已经分析。
综上所述:string和wstring类借助_String_iterator实现迭代器操作,都占32(Debug)或28(Release)字节的内存空间,没有虚函数,构造和析构开销较低,内存分配比较灵活。
实际使用string类时也有很多不方便的地方,笔者写了一个扩展类,欢迎提出宝贵意见。
扩展类链接:http://blog.csdn.net/passion_wu128/article/details/38354541