对Dilated Convolution理解
“微信公众号”

本文同步更新在我的微信公众号里,地址:https://mp.weixin.qq.com/s/erRlLajvOYmwcfZApNOzIw
本文同步更新在我的知乎专栏里,地址:https://zhuanlan.zhihu.com/p/39542237
本文主要对论文《Multi-Scale Context Aggregation by Dilated Convolutions》进行总结。
论文地址:
https://arxiv.org/abs/1511.07122
源码地址:
https://github.com/fyu/dilation
摘要
针对图像语义分割中像素点级别的密集预测分类,提出了一种新的卷积网络模块。通过扩张(空洞)卷积进行多尺度上下文信息聚合而不降低特征图的大小。扩张卷积支持感受野的指数增长。
1. 前言
(1)什么是图像语义分割?
图像语义分割可以说是图像理解的基石性技术,在自动驾驶系统(具体为街景识别与理解)、无人机应用(着陆点判断)以及穿戴式设备应用中举足轻重。我们都知道,图像是由许多像素(Pixel)组成,而「语义分割」顾名思义就是将像素按照图像中表达语义含义的不同进行分组(Grouping)/分割(Segmentation)。图像的语义分割又属于密集预测(dense prediction)。

图1:图像语义分割
图像语义分割的意思就是机器自动分割并识别出图像中的内容,比如图1中给出一个人骑摩托车的照片,机器判断后应当能够生成右侧图,红色标注为人,绿色是车(黑色表示back ground)。
(2)论文思想
传统的图像分类网络通常通过连续的pooling或其他的下采样层来整合多尺度的上下文信息,这种方式会损失分辨率。而对于稠密预测(dense prediction)任务而言,不仅需要多尺度的上下文信息,同时还要求输出具有足够大的分辨率。
为了解决这个问题,以前的论文做法是:
1) 在图像分割领域,图像输入到FCN中,FCN先像传统的CNN那样对图像做卷积再pooling,降低图像像素的同时增大感受野,但是由于图像分割预测是逐像素的输出,所以要将pooling后较小的图像尺寸上采样(upsampling)到原始的图像尺寸进行预测,上采样一般采用反卷积(deconv)操作。池化(pooling)操作使得每个像素预测都能看到较大的感受野信息。因此图像分割FCN中有两个关键技术,一个是池化(pooling)减少图像尺寸增大感受野,另一个是上采样扩大图像尺寸。那么在先减小再增大尺寸的过程中,肯定有一些信息损失掉了。对于这种方法,作者提出一个疑问:是否真的需要下采样层?
2) 提供图像的多个重新缩放版本(multiple rescaled verions of the image)作为网络的输入。对于这种方法,作者同样提出一个疑问:对多个重新放缩的图像进行分开分析是否必要?
基于这些疑问,在这篇文章,作者提出了一种新的卷积网络模块,它能够整合多尺度的上下文信息,同时不丧失分辨率,也不需要分析重新放缩的图像。这种模块是为稠密预测专门设计的,没有pooling或其它下采样。这个模块是基于空洞卷积,空洞卷积支持感受野指数级的增长,同时还不损失分辨率。
2. Dilated Convolutions
既然网络中加入pooling层会损失信息,降低精度。那么不加pooling层会使感受野变小,学不到全局的特征。如果我们单纯的去掉pooling层、扩大卷积核的话,这样纯粹的扩大卷积核势必导致计算量的增大,此时最好的办法就是Dilated Convolutions(扩张卷积或叫空洞卷积)。
(1)标准卷积
使用卷积核大小为3*3、填充为1,步长为2的卷积操作对输入为5*5的特征图进行卷积生成3*3的特征图,如图2所示。

图2:标准卷积
(2)空洞卷积
使用卷积核大小为3*3、空洞率(dilated rate)为2、卷积步长为1的空洞卷积操作对输入为7*7的特征图进行卷积生成3*3的特征图,如图3所示。

我们从图2、3中可以看出,标准的卷积操作中,卷积核的元素之间都是相邻的。但是,在空洞卷积中,卷积核的元素是间隔的,间隔的大小取决于空洞率。
思考:为什么空洞卷积能够扩大感受野并且保持分辨率呢?
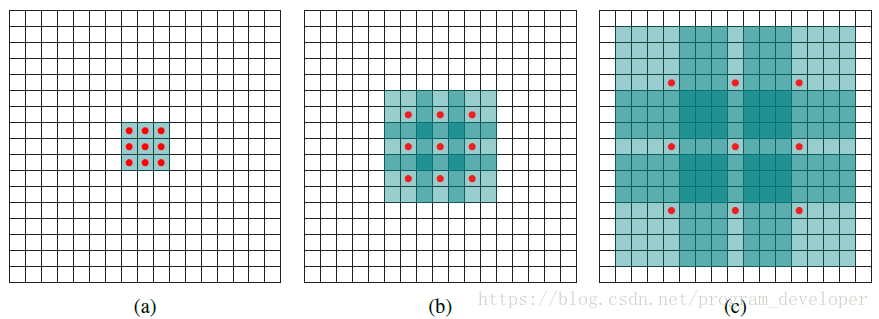
图4:空洞卷积理解
以图4为例,红色圆点为卷积核对应的输入“像素”,绿色为其在原输入中的感受野。
(a) 图对应3x3的扩张率为1的卷积,和普通的卷积操作一样;
(b) 图对应3x3的扩张率为2的卷积,实际的卷积核还是3x3,但是空洞率为2,也就是对于一个7x7的图像块,只有9个红色的点也就是3x3的卷积核发生卷积操作,其余的点略过。也可以理解为卷积核的大小为7x7,但是只有图中的9个点的权重不为0,其余都为0。可以看到虽然卷积核的大小只有3x3,但是这个卷积的感受野已经增大到了7x7。如果考虑到这个2-dilated convolution的前一层有一个1-dilated convolution的话,那么每个红点就是1-dilated的卷积输出,感受野为3x3,所以1-dilated和2-dilated合起来就能达到7x7的卷积;
(c) 图是4-dilated convolution操作,同理跟在1-dilated和2-dilated convolution的后面,能达到15x15的感受野;
对比传统的卷积操作,3层3x3的卷积加起来,stride为1的话,只能达到(kernel-1)*layer+1=7的感受野,也就是和层数layer成线性关系,而dilated conv的感受野是指数级的增长。
补充:dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。在图像需要全局信息或者语音文本需要较长的sequence信息依赖的问题中,都能很好的应用dilated conv,比如图像分割、语音合成WaveNet、机器翻译ByteNet中。
3.Multi-Scale Context Aggregation
在这一部分中,作者提出了自己设计的一种基础的上下文模块(basic context module)。上下文模块旨在通过聚合多尺度上下文信息来提高密集预测网络结构的性能。该模块采用C个通道特征图作为输入,并生成C个通道特征图作为输出。输入和输出具有相同的形式,因此该模块可以插入到现有的密集预测网络结构中。
本文设计的基础上下文模块,有7层,每一层都采用具有不同空洞率的3*3卷积核进行空洞卷积。基础上下文模块根据卷积的通道不同又分为两种形式:basic和large,如图5所示。

图5:上下文网络结构
这一部分另外的一个工作是,作者发现用卷积网络通常的初始化不能提高上下文模块的预测精度。作者采用一个具有明确语义的替代初始化更有效果。这是一种确定初始化的一种形式,最近一直被提倡用于循环神经网络。具体想了解上下文模块如何初始化,可以看一下论文的具体公式,这里我就不贴公式了。
4. Front End
在上一部分中作者提到,在他的实验中为上下文网络提供输入的是前端模块生成的64*64分辨率的特征图。那么到底什么是前端模块呢?
如下图6所示,图中fc-final之前的部分就是前端模块,之后的部分就是上下文模块。前端模块改进了VGG-16网络,将VGG-16最后两个poooling层移除,并且随后的卷积层被空洞卷积代替,pool4和pool5之间的空洞卷积的空洞率为2,在pool5之后的空洞卷积的空洞率为4。实际上,只需要前端而不需要前端之后的部分就能够进行稠密预测。

图6:前端模块+上下文网络结构
作者发现前端模型比其它模型在稠密预测中精度更高,主要是归因于去除了那些对于分类网络来说是有效设计,但对密集预测算作残留成分(vestigial components )的部分。图7是前端模型在VOC-2012数据集上语义分割效果与FCN-8s,DeepLab,DeepLab-Msc方法的比较。图8是作者的前端预测模块比以前的模型更简单、更准确。

图7:通过VGG16分类网络改进产生的语义分割

图8:前端预测模块比以前的模型更简单更准确
图6来源于: https://zhuanlan.zhihu.com/p/37804781
5. Experiment
除了前端网络,这篇文章还提出了前端网络+上下文模块的网络,也就是图6所示的网络结构。当训练的时候,上下文模块接受来自前端网络的特征图作为输入。实验表明,上下文模块和前端模块联合训练精度并没有产生显著的改进,但是还是有提高的。作者又将前端网络+上下文模块与其它网络进行联合,分为三种网络结构,实验定量结果如图9所示,实验定性结果如图10所示。

图9:在语义分割中不同网络结构的精度
实验结果表明,上下文模块提高了三种配置中的每一种的准确性。 基本上下文模块(Front+Basic)提高了每种配置的准确性。 大型上下文模块(Front+Large)以更大的幅度提高准确性。 实验还表明,上下文模块和结构化预测是相互作用的:上下文模块在有或没有后续结构化预测的情况下都能提高准确性。

图10:不同模型产生的语义分割
6. Conclusion
本篇论文作者做了大致两件事情:
(1)证明了扩展卷积适合用于密集预测,因为它能够在不损失分别率的情况下扩大感受野,这一点表现在第四部分提到的前端模块中,因为前端模块是改进VGG16,再加上扩张卷积形成的,可以有效的进行密集预测。作者利用扩张卷积设计了一种新的网络结构,可以在插入现有的语义分割系统时可靠地提高准确性。这一点表现在前端模型+上下文网络结构,从第五部分的实验中也可以看到前端网络+上下文模块与其它网络进行联合预测。
(2)通过实验还证明了,去除图像分类网络中的残余组件(vestigial components)可以提高现有卷积网络对语义分割的准确性。
7. Reference
【1】Yu F, Koltun V. Multi-scale context aggregation by dilated convolutions[J]. arXiv preprint arXiv:1511.07122, 2015.
【2】语义分割之Dilated convolution
https://zhuanlan.zhihu.com/p/37804781
【3】如何理解空洞卷积(dilated convolution)? - 知乎
https://www.zhihu.com/question/54149221
【4】如何理解空洞卷积(dilated convolution)? - 刘诗昆的回答 - 知乎
https://www.zhihu.com/question/54149221/answer/323880412
【5】如何理解空洞卷积(dilated convolution)? - 谭旭的回答 - 知乎
https://www.zhihu.com/question/54149221/answer/192025860
【6】Multi-Scale Context Aggregation by Dilated Convolution 对空洞卷积(扩张卷积)、感受野的理解
https://blog.csdn.net/guvcolie/article/details/77884530?locationNum=10&fps=1
【7】图像语义分析学习(一):图像语义分割的概念与原理以及常用的方法 - 袁国亮 - 博客园
https://www.cnblogs.com/734451909-yuan/p/7060227.html