平台搭建---电脑系统---ubuntu16.04下hadoop-2.7.4搭建
Hadoop基本介绍
我准备在同一台电脑上搭建hadoop系统,电脑内存8G,一个物理机的ubuntu系统,一个虚拟机的ubuntu系统。在每台电脑进行如下配置。
准备好ubuntu系统
方法参照我之前的《windows系统下安装ubuntu双系统》及《虚拟机装linux系统》,虚拟机装好的ubuntu系统可能在使用过程中出现莫名其妙的问题,所以最好在安装完一些基础软件后克克隆一个虚拟系统备用。
设置好集群电脑的网络连接
集群包含两个机器,我将物理机命名为master,虚拟机命名为slave1。master同时扮演resourcemanager、namenode、secondarynamenode、datanode、worker;slave1同时扮演nodemanger,datanode和worker;
在不插网线的情况下,配置好网络后物理机与虚拟机之前是可以互传文件的,但是并不能启动集群。
设置物理机的网络连接为静态ip
先查看好物理机的网络连接信息,并将网络连接改为静态IP的形式;并记录下来,方便后面对虚拟机进行网络连接时进行对照。
笔记本无线连接改为静态ip的方法,在屏幕右上角,点网络连接的标志,可以看到当前的网络,点编辑连接,弹出的网络连接界面可以看到无线网和以态网,界面如下:
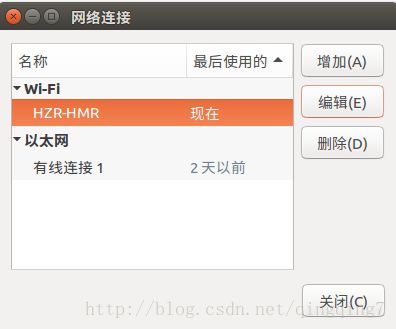
选中对应的无线网并点击编辑按钮,弹出如下界面:
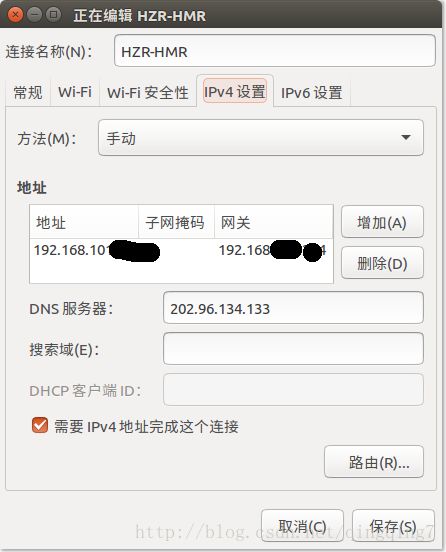
点击ipv4,方法选手动,点击增加,然后再填写ip地址、子网掩码、网关(我是直接将修改前的地址般过来),最后将上图中的“需要IPv4地址完成这个连接”勾选。点出保存。
完成后,重启电脑看看是不是仍然能连接网络,如果能,那就说明修改为静态ip成功。
设置虚拟机的网络连接为静态ip
方法一:
未设置前,可以看到尽管物理机是无线连接的,但虚拟机仍然是有线连接的网络标志。
首先在虚拟机的编辑菜单下找到虚拟网络编辑器,点开后界面如下图左(首次进入的时候这个页面是不能编辑的状态,点击下方的更改设置就可以编辑了),
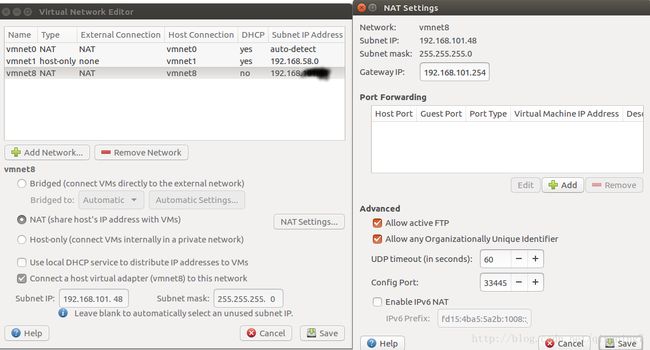
按照图上勾选对vmnet8进行设置,有两个勾选,在最下方设置自己想设的ip地址,和子网掩码;点出NAET Setting会弹出上图右的界面,里面有设置网关的一项。设置成与自己物理机一致的就行。
然后在屏幕右下角,点网络设置的“设置”按钮,弹出下面的界面
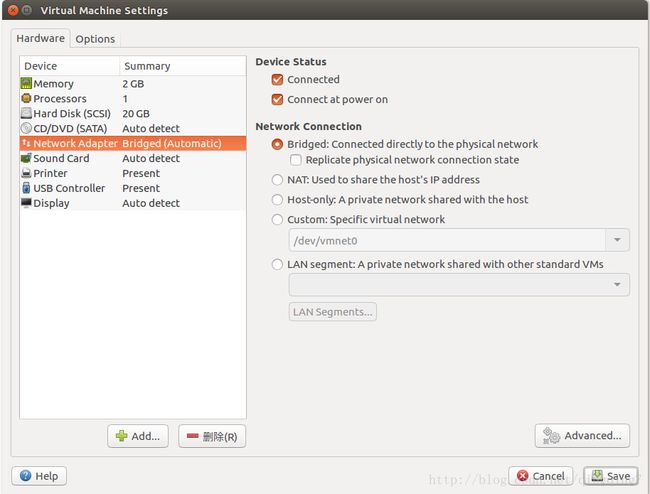
选择"Custom:Specific virtual network",并选择/dev/vmnet8,点击保存。
再点击屏幕右上角的网络连接标志,在弹出的菜单中点击编辑网络连接,弹出如下界面
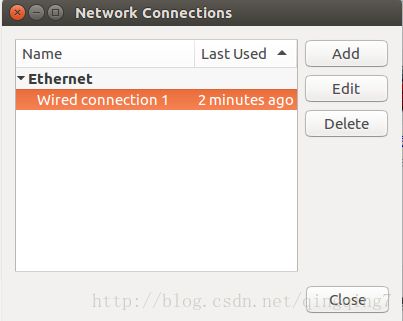
选中现有的以太网络,再点编辑按钮,如果没有以太网,则点击添加,网络类型选以太网;弹出一界面,在此界面进行网络配置,方法同物理机中的配置(点击ipv4,方法选手动,再点添加,接下来就是网络配置了)。
这里我将虚拟机的ip设置为与物理相差一位,如物理机为192.168.0.1,则虚拟机为192.168.0.2,其他一模一样。
我们可以通过电脑之间传输文件来查看网络连接是否正常
sudo scp ~/下载/无标题文档 digger@slave1:~/Downloads
如果文件被对方电脑接收则网络无问题。
方法二:
在虚拟机桌面右下角,点击网络设置,弹出如下界面。
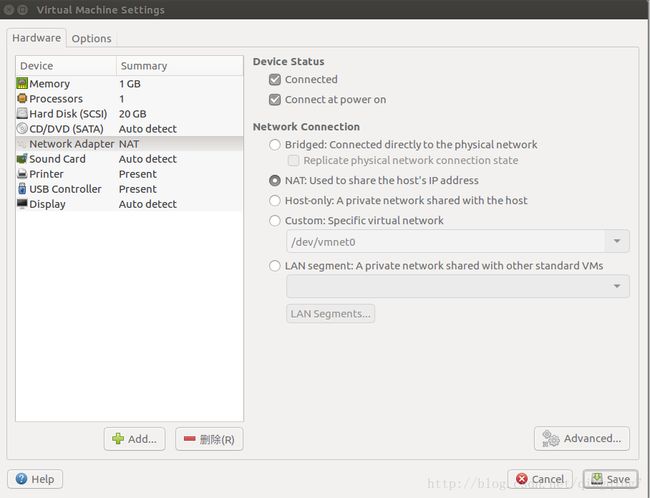
选择NAT模型,似乎虚拟机的IP等设置不是特别重要,就能上网了。不知道这样的网络hadoop 集群能不能工作,还要后面验证一下。
共用IP似乎不同同时上网。
方法三
先介绍一下VMware的网络连接模式,来源《VMware虚拟机设置上网以及与本地计算机通信》。
VMware的网络连接模式有三种:
1、仅主机模式:也就是host_only,这种模式仅仅只让虚拟机与本地物理机通信,不可以上网;
2、NAT模式:这种模式保留仅主机模式的功能下,还能让主机上网;
3、桥接模式:直接让虚拟机使用本地主机的网卡上网。
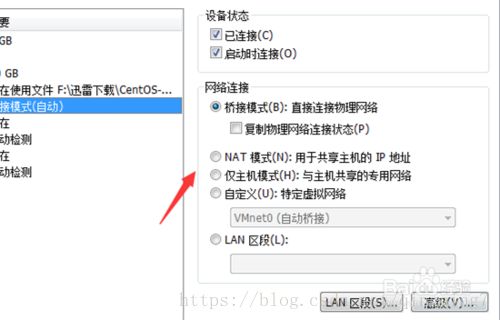
在安装完成VMware之后,软件会在系统中创建两个虚拟的网卡,分别是VMnet1和VMnet8,其中VMnet1是给仅主机模式使用,VMnet8是个NAT模式使用,这一点要分清楚!!!
设置虚拟网卡的方法"win+x-----网络连接------更改适配器选项"或采用后面的方法也可调出界面。
**设置动态ip:**感觉整个设置过程就是设置了虚拟机的ip地址范围,并在“虚拟机-设置-网络适配器”中选择了自动桥接模式。
**设置固定ip:**ubuntu中设置方法参考上面物理机的设置,centos中设置方法参考虚拟机中的CentOS 7设置固定IP连接最理想的配置
主要是利用NAT模式,感觉核心在于取消勾选使用本地DHCP并且子网ip和网关及物理机中虚拟网关的ip地址在同一网段但不同,这里就好像设置的一个大格局一样,然后虚拟机自己的ip设置就要符合这个头,主要是拿了同一网关,同时自己的ip与网关在同一网段。具体如下(直接复制原文):
1.设置虚拟机的网络连接方式:
按照如下图设置,英文版的对照设置即可
2.配置虚拟机的NAT模式具体地址参数:
(1)编辑–虚拟网络编辑器–更改设置
2)选择VMnet8–取消勾选使用本地DHCP–设置子网IP–网关IP设置(记住此处设置,后面要用到),如下图
说明:修改子网IP设置,实现自由设置固定IP,若你想设置固定IP为192.168.2.2-255,比如192.168.2.2,则子网IP为192.168.2.0;若你想设置固定IP为192.168.1.2-255,比如192.168.1.2,则子网IP为192.168.1.0;
(3)网关IP可以参照如下格式修改:192.168.2.1
3.配置笔记本主机具体VMnet8本地地址参数:
4.修改虚拟机中的CentOS 7系统为固定IP的配置文件:
(1)进入centos7命令行界面,修改如下内容:
#cd /etc/sysconfig/network-scripts/
#vi ifcfg-eno16777736#系统版本不同文件后面几位也不同
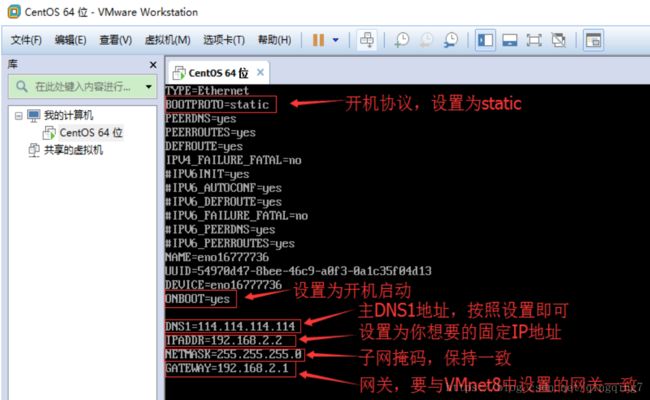
说明:
#将IPV6…..协议都注释;
BOOTPROTO=static #开机协议,有dhcp及static;
ONBOOT=yes #设置为开机启动;
DNS1=114.114.114.114 #这个是国内的DNS地址,是固定的;
IPADDR=192.168.2.2 #你想要设置的固定IP,理论上192.168.2.2-255之间都可以,请自行验证;
NETMASK=255.255.255.0 #子网掩码,不需要修改;
GATEWAY=192.168.2.1 #网关,这里是你在“2.配置虚拟机的NAT模式具体地址参数”中的(2)选择VMnet8--取消勾选使用本地DHCP--设置子网IP--网关IP设置。
使网络设置立即生效的方法:service network restart
ifconfig查看设置是否生效
测试虚拟机是否能连接外网的方法:ping www.baidu.com
测试完后可按ctrl+c退出测试。
快速复制虚拟机
安装各种集群需要多台服务器,一种快速模拟的方式是克隆虚拟机。这样操作系统,网络设置,主机名,ip这些都与之前的一模一样。我们只需要修改主机台、ip地址即只,vi /etc/hostname ; vi /etc/hosts ; vi /etc/sysconfig/network-scripts/ifcfg-ens33;
linux系统设置IP地址
如果有的集群还需要mac地址和UUID唯一,则可进一步修改;克隆的机器一般mac就是不一样的,但UUID是一样,可输入命令uuidgen,将生成的UUID写入ifcfg-ens33
VMware克隆虚拟机后修改UUID、MAC地址、IP和主机名
linux 查看UUID和MAC地址
对集群电脑命名,并配置好dns域名服务器
master 192.168.101.xxx
slave1 192.168.101.yyy
1、设置本机名称
sudo gedit /etc/hostname;将主机名称设置master
同样的操作将虚拟机设置为slave1
2、设置本机dns服务信息
sudo gedit /etc/hosts
添加如下内容:
192.168.101.xxx master
192.168.101.yyy slave1
同样在slave1中进行相同操作。
以上的两步操作就是让网络中的电脑知道谁是谁,哪个ip对应谁。
安装ssh
1、安装ssh
ssh是远程登录协议,ubuntu环境下,自带ssh-client,需要安装ssh-server
为了防止一些软件安装失败可以先sudo apt-get install update,安装其他软件也是一样的。
sudo apt-get install openssh-server
启动ssh-server
/etc/init.d/ssh start
此时会提示输入密码进行授权
可以查看附录是否成功ps -e|grep ssh
2、root用户免官登录本地
由于后面集群之间需要传输文件,交流信息,需要通过ssh设置成免密登录。
为了减少今后运行hadoop和spark及其他各种软件的麻烦,我们可以使root权限来运行集群。
但是root账户默认不允许登录ssh,需要如下设置,
sudo gedit /etc/ssh/sshd_config
找到
找到Authentication,修改PermitRootLogin yes,保存。
为root账户设置密码sudo passwd root
将当前帐户切换为root账户su root
生成密钥
ssh-keygen -t rsa
密钥包括公钥和私钥,默认保存在(/home/digger/.ssh/id_rsa)
进入.ssh文件夹,可以看到两个文件,分别对应着私钥和公钥。复制公钥到授权文件sudo cp id_rsa.pub authorized_keys,刷新后即可以免密登录了
可以用ssh localhost尝试登录。
重新登录,可以用ssh localhost尝试登录。
3、master通过ssh免官登录slave1
在slave1上安装ssh-server,设置root身份能登录ssh,并设置设置slave1的root账户密码,并用root身份登录系统,然后产生密钥。
道理是一样的,在slave1产生密钥和相关文件,让其他电脑能通过ssh密钥来登录slave1。然后将master中root用户下ssh公钥加入到slave1的授权文书中即可。
能联网的电脑之间可通过以下命令来传输文件。
scp /root/.ssh/id_rsa.pub root@slave1:/root/.ssh
此时传输文件是需要密码的。
在slave1中,我们将刚刚传输过去的master的公钥添加到slave1的授权文书中。
cp id_rsa.pub authorized_keys
此时我们就完成了master对slave1的免密登录。下面可以测试一下。
scp /home/digger/下载/无标题文档2 root@slave1:/home/digger/Downloads
可以在slave1相应的文件夹中看到传过去的文件。
到这里我们就完成了hadoop和spark网络环境的准备了。
4、非root用户的免密登录
由于使用root用户有安全隐患,我们安装运行各种软件一般在非root用户进行。但是又可能涉及到写文件的一些操作时,为了避免软件运行出问题,之前是直接用root;但通过将某个文件夹授权用普通用户,使其具有读写权限一样可以避免软件运行出错的问题。
非root用户免密登录的设置过程大体同上。不一样的是需要加上-P ''参数。
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa -P '' # 会有提示,都按回车就可以
cat id_rsa.pub >> authorized_keys # 加入授权
特殊情况:
重装虚拟机后,物理机无法连接虚拟机,提示类似下面的错误:
Add correct host key in /home/hadoop/.ssh/known_hosts to get rid of this message.
Offending key in /home/hadoop/.ssh/known_hosts:5
RSA host key for slave has changed and you have requested strict checking.
Host key verification failed
OpenSSH在4.0p1引入了 Hash Known Hosts功能,在known_hosts中把访问过的计算机名称或IP地址以hash方式存放,令入侵都不能直接知道你到访过那些计算机。这项新项功能缺省是关闭的,要你手动地在ssh_config加上"HashKnownHosts yes"才会被开启。不过Ubuntu就缺省开启了个功能。
然而,偶然一些计算机的ssh公钥是合理地被更动。虽然遇到这些情况OpenSSH会发出惊告并禁止你进入该计算机。以往当我们确定该次 ssh公钥被更动没有可疑时,我们用文字编辑器开启known_hosts,把相关的公钥记录删掉就可以了。但现在因为所有计算机名称或IP地址都被 hash了,我们很难知道那行是相关计算机的公钥。当然我们可以把整个known_hosts删除,但我们会同时失去其他正常计算机的ssh公钥。 事实上OpenSSH在工具ssh-keygen加了三个选项,协助你管理hash了的known_hosts。你可以用"ssh-keygen -F 计算机名称"找出相关的公钥,使用如下命令找出slave所对应的公钥
ssh-keygen -F slave
得到类似下面的结果:
# Host slave found: line 5 type RSA
|1|hMbmluXaSJKOv4bZydZ75Ye3OUc=|rcfbiV7hrXoaDt02BrVb9UxJSqI= ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEA0d8quvKVdc0b620eAY46ucB87dK/Q1EqEsPOdUltfEpr7/r9hCG+yJqjM6l3roOzkkc9Fi/iZEx0pvIgDdtD+n5YEQrQu81/mj1cWXmkN9xuXvqv9BZxOTeETRF5g1cL0yr4T91CmvXIMewUzv1fE1pWOzZvMKj8SqMOn7PpTjQhpDoS8SkTuNO81k41DkyrDe3DIRL0yC6aUGTF3YOTAe4DbpF8jMHD3+wDm4JT//ULRNKSwRQPOb57XWHy9GLHm89oOm2e8wrjrz84nCRJ5hgJdsjaPt3qJEEGeb8OAMj2fevyu+e1KDF3KExSE0jGBegEWpJilxaD8AV4+1CHsw==
上述给出了slave的公钥,以及在所在的行数。我们去known_hosts中找到对应的公钥将其删除。
sudo gedit known_hosts
如果提示无法连接该文件可能是已经了ssh,文件被ssh占用。关闭终端重新打开即可。
准备好java环境
ubuntu16.04系统没有安装java JDK,直接官网下载,选择Linux x64版本(根据自己电脑选择);解压至目标位置,我的一些软件基本安装至/usr目录。
sudo mv ~/下载/jdk1.8.0_151 /usr
并设置好环境变量。
sudo gedit /etc/profile
打开系统配置文件后,添加如下内容:
export JAVA_HOME=/usr/jdk1.8.0_151
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
使配置立即生效
source /etc/profile
查看java是否安装成功
java -version
也可以通过echo $PATH查看系统环境变量是否发生变化。
安装hadoop-2.7.4
到官网下载相应的hadoop版本
解压缩hadoop-2.7.4.tar.gz
将解压后的文件移到安装目录
sudo mv ~/下载/hadoop-2.7.4 /usr
设置环境变量
sudo gedit /etc/profile
添加如下内容:
export HADOOP_HOME=/usr/hadoop-2.7.4
export PATH=$PATH:$HADOOP_HOME/bin
使配置生效
source /etc/profille
要使hadoop作为一个分布式集群运行,最关键的是hadoop的系统配置。
集群配置
配置
配置4大xml文件
主要包括:
core-site.xml,集群整体配置的文件,如集群的访问地址和临时文件存放位置;hdfs-site.xml,文件存储和访问等配置的文件,如namenode和datanode地址,文件的备份数,namenode备用地址等;mapred-site.xml,声明集群的管理模式,以及任务运行日志的访问地址等;yarn-site.xml,对于yarn模式,对yarn进行配置。
安装Hadoop后以上4个配置文件默认是空的,不同的集群管理模式,配置方法是不一样的。哪些配置能生效,对于新手很难搞清楚,网上的一些教程可能又不完全或因版本问题不能直接使用。可以用两种方法去搞清楚如何对这些配置进行修改:
1、在hadoop的安装目录中搜索core-default.xml,hdfs-default.xml,mapred-default.xml,yarn-default.xml,这四个文件是集群的参考配置,参考该文档的参数和解释来配置自己的集群。
2、访问官网http://hadoop.apache.org/common/docs/current,在该网站上可以看到4个配置文件的详细说明,可以好好研究该文档。
常用的端口配置
HDFS端口:
| 参数 | 描述 | 默认 | 配置文件 | 例子值 |
|---|---|---|---|---|
| fs.default.name | namenode RPC交互端口 | 8020 | core-site.xml | hdfs://master:8020/ |
| dfs.http.address | NameNode web管理端口 | 50070 | hdfs- site.xml | 0.0.0.0:50070 |
| dfs.namenode.secondary.http-address | secondary NameNode web管理端口 | 50090 | hdfs-site.xml | 0.0.0.0:50090 |
| dfs.datanode.address | datanode 控制端口 | 50010 | hdfs -site.xml | 0.0.0.0:50010 |
| dfs.datanode.ipc.address | datanode的RPC服务器地址和端口 | 50020 | hdfs-site.xml | 0.0.0.0:50020 |
| dfs.datanode.http.address | datanode的HTTP服务器和端口 | 50075 | hdfs-site.xml | 0.0.0.0:50075 |
MR端口:
| 参数 | 描述 | 默认 | 配置文件 | 例子值 |
|---|---|---|---|---|
| mapred.job.tracker | job-tracker交互端口 | 8021 | mapred-site.xml | hdfs://master:8021/ |
| job | tracker的web管理端口 | 50030 | mapred- site.xml | 0.0.0.0:50030 |
| mapred.task.tracker.http.address | task-tracker的HTTP端口 | 50060 | mapred-site.xml | 0.0.0.0:50060 |
| mapreduce.jobhistory.address | MapReduce JobHistory Server IPC host:port | 10020 | mapred-site.xml | 0.0.0.0:10020 |
| mapreduce.jobhistory.webapp.address | MapReduce JobHistory Server Web UI host:port | 19888 | mapred-site.xml | 0.0.0.0:19888 |
下面是yarn模式下的配置方法举例,没有跟上面的默认参数一样。
在core-site.xml文件中添加如下内容:
fs.default.name
hdfs://master:9000
HDFS的URI,文件系统://namenode标识:端口号
hadoop.tmp.dir
file:/usr/data/hadoop/tmp
namenode上本地的hadoop临时文件夹
在hdfs-site.xml文件中添加如下内容:
dfs.name.dir
file:/usr/data/hadoop/hdfs/name
namenode上存储hdfs名字空间元数据
dfs.data.dir
file:/usr/data/hadoop/hdfs/data
datanode上数据块的物理存储位置,是集群上的位置,存储数据时可能每一个节点都会在对应目录中产生数据文件
dfs.replication
1
副本个数,配置默认是3,应小于datanode机器数量
dfs.namenode.secondary.http-address
master:9001
在mapred-site.xml文件中添加如下内容:
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
在yarn-site.xml文件中添加如下内容:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.resource-tracker.address
master:8031
yarn.resourcemanager.admin.address
master:8033
yarn.resourcemanager.webapp.address
master:8088
让hadoop知道Java路径
把hadoop-env.sh、mapred-env.sh、yarn-env.sh中的JAVA_HOME改为我们自己安装的JAVA_HOME
添加slave节点
在slaves文件中添加slave节点(电脑网址),这里只有两台电脑master和slave1,我同时将两台电脑设置为slave,即两台电脑都为datanode和worker。
检查Hadoop集群是否正常工作
启动hadoop集群
因为权限等原因,暂时先在root用户下运行hadoop,su - root;
首先启动ssh,/etc/init.d/ssh start;
然后启动hadoop集群,cd $HADOOP_HOME;sbin/start-all.sh。或者使用
sbin/start-hdfs.sh
sbin/start-yarn.sh
系统推荐后面的启动方法
利用jps查看
在各节点命令行输入jps可以看到启动的进程。
master上可以看到:Jps、NameNode、 NodeManager、 DataNode、 ResourceManager.
slave1上可以看到:Jps、NodeManager、DataNode
利用网页查看
在配置文件中有http之类字眼的都能在web端查看,如
查看HDFS的情况
http://master:50070
查看yarn的情况
http://master:8088/
往集群上传数据,到相应文件夹下查看数据是否存在
查看数据
在hdfs-site.xml文件的dfs.data.dir字段里的,在每个datanode的这个文件夹里存着该节点上存储的所有数据块block,以blk_打头。数据都是以block形式存在的,大的数据还由好多个block组成,而且每个block还有副本。
dfs.name.dir指定的文件夹在namenode中,则存储着元数据。
也可以利用shell命令:
这个方法是最基本的,能进行所有文件操作。
hadoop fs -ls /user/data/hdfs/data#查看指定目录下的文件和文件夹。/user/data/hdfs/data是HDFS上的目录,不是本地目录
hadoop fs -cat /user/data/hdfs/data#查看文件内容
故障诊断
如果出现如下的提示
Exception in thread "main" java.net.ConnectException: Call From hyj-PC/10.10.99.202 to master:8020 failed on connection exception: java.net.ConnectException: Connection refused: no further information; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
这个属于通信问题,可以尝试下面的操作:
检查集群是否开启等
通过jps查看是否有namenode等进程;
如果namenode没有启动,可以尝试如下操作:
重新格式化一下namenode,hadoop namenode -format
然后启动hadoopstart-all.sh,执行下JPS命令就可以看到NameNode了。
检查网络
通过netstat -nltp|grep 9000查看9000端口是否处于监听状态;
如果用netstat -tpnl则可以看到一系列的监听断口,监听表示该商品已经被占用;
通过telnet 远程的主机名 9000查看是否连接成功,如果提示Connection refused则进行下一步;
检查防火墙
sudo service iptables status查看防火墙是否开启,如果开启则通过sudo service iptables stop(此命令立即生效,但机器重启后又会恢复,如果想永久关闭(开启)防火墙,可以通过sudo chkconfig iptables off(on)命令),将其关闭(大部分是由于开启了防火墙导致的)。