人脸识别学习笔记
在公司的上个项目,用到了车辆和人脸识别,本人主要负责车辆模块所有的应用服务,只知道调用第三方的接口传入参数rtsp流地址或是一张图片,接口返回一组或一条识别结果,作为一位共产主义的接班人,优秀的少先队员,我带着一脸的懵逼,开始了爬坑。
本文参考了一位日本的大牛Hironsan的一个有趣的项目 BossSensor,有兴趣的同学的试着玩一下
首先梳理下我们需要做的流程:
- rtsp、rtmp视频流中显示出视频并找出头像(二选一)
- 直接用opencv的imshow方法在本地显示
- 用服务推送协议,在web页面显示(因为服务器不在本地,所以本文使用此方法)
- 从视频流中获取我们需要训练的数据(如果以前有数据这一步可以跳过)
- 加载已经保存的图片用于训练
- 训练数据建立数据模型并保存
- 使用之前训练好的模型识别图片
用到主要的模块的版本:
- opencv-python 3.3.0.10
- python 3.6.1
- numpy 1.12.1
- keras 2.0.8
一、从视频流或者摄像头中显示视频并找出头像
该模块主要应用的是opencv模块
import cv2
# rtsp流地址
CAMER_URL = 'rtsp://192.168.1.101:8554/1234'
cap = cv2.VideoCapture(CAMER_URL)
# 加载分类器
classfier = cv2.CascadeClassifier('haarcascade_frontalface_alt2.xml')
# 识别框颜色
color = (0, 255, 0)
while cap.isOpened():
# 获取每一帧图像
ok, frame = cap.read()
if not ok:
break
# 灰度化,降低图片维度
grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 分类对象调用
faceRects = classfier.detectMultiScale(
grey, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
# 判断若未识别到则不进行处理
if len(faceRects) > 0:
for faceRect in faceRects:
# 获取识别信息的坐标信息
x, y, w, h = faceRect
# 绘制方框(这里是给原图上绘制,不是灰度图片)
cv2.rectangle(frame, (x - 10, y - 10),
(x + 10, y + 10), color, 2)
# 展示图片(本地)
cv2.imshow('windowTitle', frame)
# 每隔10ms监听键盘输入,若为q 退出循环
c = cv2.waitkey(10)
if c & 0xFF == orq('q')
break
# 释放摄像头并关闭窗口
cap.release()
cv2.destroyAllWindows()CAMER_URL 是视频来源地址,因为我是台式机而且没有摄像头,所以这次采用的是外部的rtsp实时数据流,如果你有摄像头或者是笔记本的话,只需要将改参数设置为0即可
这里主要解释下classfier.detectMultiScale()参数的具体含义:
- grey :也要检测图片(这里使用的是灰度图片,加快检测速度)
- scaleFactor : 表示前后两次相继的扫描中,搜索窗口的比例系数,默认为1.1即每次搜索窗口扩大10%
- minNeighbors: 表示构成检测目标的相邻矩形的最小个数(默认是3个) ,若果组成检测的目标小于min_neighbors -1都会被排除,如果min_neighbors 为0,则函数不做任何操作就返回所有的被检测候选矩形框,这种设定值一般用在用户自定义对检测结果组合程序上
- minSize限制得到区域的最小范围,当然也有最大范围maxSize,我这里只设置了最小范围
上面是本地窗口显示视频,下面我用web页面显示视频代码,用flask框架搭建了一个简单的web服务,flask框架不是本文的重点,我只贴出用到关键用到的服务推送(multipart/x-mixed-replace)部分代码
from importlib import import_module
import os
from flask import Flask, render_template, Response
from camera_opencv import Camera
app = Flask(__name__)
@app.route('/')
def index():
# 渲染视频主页面
return render_template('index.html')
def gen(camera):
# 视频流生成方法
while True:
frame = camera.get_frame()
yield (b'--frame\r\n'
b'Content-Type: image/jpeg\r\n\r\n' + frame + b'\r\n')
@app.route('/video_feed')
def video_feed():
# 视频流路由,推送到主页面的img标签
return Response(gen(Camera()),
mimetype='multipart/x-mixed-replace; boundary=frame')
if __name__ == '__main__':
app.run(host='0.0.0.0', threaded=True)
get_frame()方法是从上面代码识别的获取frame图片,封装在Camera里,在index.html 里面img标签的路径是vieo_feed路由,建立长连接直接将数据推送web页面
效果如下图:

二、从视频流中获取我们需要训练的数据
如果已经用了训练数据可以跳过直接看后面的
这里的代码是在上面方法基础上只是将识别出来的头像添加保存而已,代码如下:
import cv2,os
# rtsp流地址
CAMER_URL = 'rtsp://192.168.1.101:8554/1234'
cap = cv2.VideoCapture(CAMER_URL)
# 加载分类器
classfier = cv2.CascadeClassifier('haarcascade_frontalface_alt2.xml')
# 识别框颜色
color = (0, 255, 0)
while cap.isOpened():
# 获取每一帧图像
ok, frame = cap.read()
if not ok:
break
# 灰度化,降低图片维度
grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 分类对象调用
faceRects = classfier.detectMultiScale(
grey, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
#定义数量
num = 0
# 判断若未识别到则不进行处理
if len(faceRects) > 0:
for faceRect in faceRects:
# 获取识别信息的坐标信息
x, y, w, h = faceRect
''' ----------图片存储开始----------'''
# 生成图片路径
img_name = '%s/%d.jpg' % (os.getcwd() + './img/me', num)
# 获取识别图片区域
image = frame[y - 10:y + h + 10, x - 10:x + w + 10]
# 保存写入图片
cv2.imwrite(img_name, image)
num += 1
# 如果图片达到1000张时退出
if num > 1000:
break
''' ----------图片存储结束----------'''
# 绘制方框(这里是给原图上绘制,不是灰度图片)
cv2.rectangle(frame, (x - 10, y - 10),
(x + 10, y + 10), color, 2)
# 展示图片(本地)
cv2.imshow('windowTitle', frame)
# 每隔10ms监听键盘输入,若为q 退出循环
c = cv2.waitkey(10)
if c & 0xFF == orq('q')
break
# 释放摄像头并关闭窗口
cap.release()
cv2.destroyAllWindows()这里需要保存两组图片各一千张一个是我自己的照片(保存在me文件夹中),另一个保存别人的照片(other文件夹中,当然名字可以自己命名,但尽量不要用中文)用于训练分类,目录需要提前建好,否则图片保存不进去
三、加载已经保存的图片用于训练
创建一个load_data.py 文件,这个文件主要是加载图指定目录下所有的图图片到缓存中用于后面的数据训练使用
import os
import sys
import numpy as np
import cv2
# 定义加载识别图片尺寸
IMAGE_SIZE = 32
# 重置图片尺寸,将图片修改为以最大边为基准的正方形(不足的地方补黑)方便训练
def resize_image(image, height=IMAGE_SIZE, width=IMAGE_SIZE):
# 初始化高低左右坐标值
top, bottom, left, right = (0, 0, 0, 0)
# 读取图片的高和宽
h, w, _ = image.shape
# 获取高宽中最大的值
longest_edge = max(w, h)
# 判断各边的长短 并补差值
if h < longest_edge:
dh = longest_edge - h
top = dh // 2
bottom = dh - top
elif w < longest_edge:
dw = longest_edge - w
left = dw // 2
right = dw - left
else:
pass
# 定义补充颜色(黑色)
BLACK = [0, 0, 0]
# 补充边界
constant = cv2.copyMakeBorder(
image, top, bottom, left, right, cv2.BORDER_CONSTANT, value=BLACK)
# 重置图片大小
return cv2.resize(constant, (height, width))
# 定义图片集
images = []
# 定义分类名称集
labels = []
# 根据路径加载图片
def read_path(path_name):
# 遍历改路径下所有的目录(我们这里只有me和other目录)
for dir_item in os.listdir(path_name):
# 根据遍历结果拼接子目录的全目录
full_path = os.path.abspath(os.path.join(path_name, dir_item))
# 若子目录不是文件则递归查询文件
if os.path.isdir(full_path):
read_path(full_path)
else:
# 如是文件判断后缀名是否是jpg
if dir_item.endswith('.jpg'):
# 获取该路径图片
image = cv2.imread(full_path)
# 初始化图片
image = resize_image(image, IMAGE_SIZE, IMAGE_SIZE)
# 图片添加到图片集
images.append(image)
# 名称添加的到分类集
labels.append(path_name)
return images, labels
# 调用加载图片
def load_dataset(path_name):
# 获取加载的各个结果集
images, labels = read_path(path_name)
# 将图片集转为四维数组(2000,30,30,3)
# 第一个是数量,第二个高度,第三个宽度,第四个每张图片的颜色数量(rgb三种)
images = np.array(images)
# 将分类集进行分类二维数组(2000,2) 第一个是数量,第二个是每张图片分类值(me是0和other是1)
labels = np.array([0 if label.endswith('me') else 1 for label in labels])
return images, labels四、训练数据建立数据模型并保存
keras 默认的后端引擎是TensorFlow,本文采用的也是默认的后端引擎,当然也可以切换为后端引擎,目前keras支持的有两个一个tensorFlow另一个是Theano,具体的切换方式请查看api, 点击这里
我们训练数据用到的是卷积神经网络(以下简称CNN)
关于CNN的具体的网上教程有很多,基本上都是引用了大量的数据公式,如果想进一步的了解卷积,请戳下面连接:
最形象的卷积神经网络详解:从算法思想到编程实现
如何通俗易懂地解释卷积?
离散卷积
而对于新手或者是非数学科班出身的人来说非常晦涩难懂,本文属于入门文章,没有太多公式基本全是大白话
CNN的工作流程:
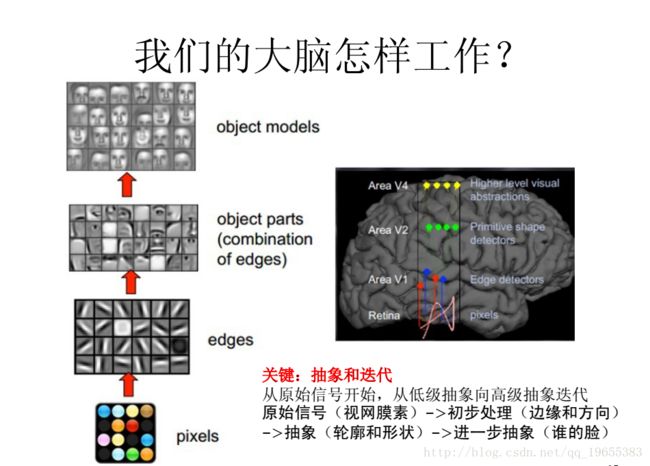
从上图可以看出CNN的工作流程和大脑工作的流程大致相同,是一个不断迭代、不断抽象的过程
比如,我们去看一个场景,首先看到场景中有一个人,然后看到这个人的脸,最后才发觉这个人谁。
神经网络一般包含三种层:输入层、隐含层(多个)、输出层,如下图:
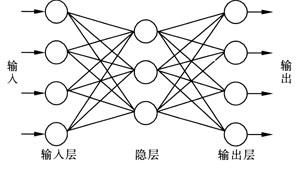
卷积神经网络是一种非全连接的神经网络,包含2中特殊的结构层:卷积层和次抽样层。

每个卷积层都会紧跟1个次抽样层,输入数据经过卷积后,进入高维空间,换句话说,卷积层进行了升维映射。卷积层的每个特征平面都对应了次抽样层的1个平面,次抽样层的神经元对其接受区域中的数据进行抽样(例如,去大、取小,去平均值,等等),因此次抽样层的特征平面上的神经元的个数往往会减半。卷积层的每一个平面都抽去了前一某一个方面的特征,每个卷积层的每个节点作为特征探测器,共同抽泣输入图像的某个特征,如45度角、反色、拉伸、翻转、平移等,图像经过一层卷积,就由原始空间被映射到特征空间,在特征空间中进行重构,卷积层输出,为图像在特征空间中重构坐标,作为下一层也就就是次抽样层的输入。
卷积层由多个特征平面构成,完成抽取特征的任务,每个特征平面有神经元构成, 在同一个特征平面上的所有神经元具有相同的连接权重,对于每个神经元,定义了相应的接受域,值接受从起接受域传输的信号,同一个特征平面的神经元的接受具有相同的大小,故而每个神经元的连接矩阵相同。
卷积层的map个数是在网络初始化指定的,而卷积层的map的大小是由卷积核的上一层输入的map的大小决定的,假设上一次层的大小是n*n、卷积核的大小是k*k,则该层的map大小是(n-k+1)*(n-k+1),比如下图:
![]()
传入map大小是5*5,卷积核的大小是3*3 那么该层的map大小就是(5-3+1)*(5-3+1) = 3*3
采样层是对上一层map的一个采样处理,这里的采样方式是对上一层map的相邻小区域进行聚合统计,区域大小为scale*scale,有些实现是取小区域的最大值,而toolbox里面的实现是采用2*2小区域的平均值。
注意,卷积的计算窗口是有重叠的,而采样的计算窗口没有重叠,toolbox里面计算采用也是用卷积(conv2(A,K,’valid’))来实现的,卷积核是2*2每个元素都是1/4,去掉计算得到的卷积结果中有重叠的部分
cnn的基本结构包括两种特殊的神经元层,其一为卷基层,每个神经元的输入与前一层的局部相连,并提取该局部的特征;
其二是池化层,用来求局部敏感性与二次特征提取的计算层,这两种特征提取结构减少了特征分辨率,减少了需要优化的参数数目
一般地,CNN的基本结构包括两层:
其一,为特征提取层,每个神经元输入与前一层的局部接受域相连,并提取该局部特征。一旦该局部特征被提取后,他与其他特征间的位置关系也随之确定下来;
其二,为特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上每个神经元的权值相等。
特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。
此外,由于一个映射面上的神经元共享权值(如上图),因而减少了网络自由参数的个数,卷积神经网络中的每一个卷积层都紧跟着一个用来求局部平均与二次提取的计算层,这种特有的两层特征提取结构减少了特征分辨率
LeNet-5手写数字识别结构(下图)分析

CNN是一种带有卷积结构的深度神经网络,通常至少有两个非线性可训练的卷积层,两个非线性的固定卷积层(又叫Pooling Layer或降采样层)和一个全连接层,一共至少5个隐含层。
在上图中 训练的样本大小是 32*32
卷积层(Convolutions)C1:
输入大小:32*32
卷积核大小:5*5
卷积核数量:6
输出的特征图大小:(32-5+1)*(32-5+1) = 28*28
输出的特征图数量:6
次抽样层(subsampling)S2:
卷积核大小:2*2
输入大小:28*28*6
卷积核数量:6
输出采样大小:(28/2 )*(28/2) = 14*14
卷积层c3:
输入大小14*14*16
卷积核大小:5*5
输出图片大小:(14-10+1)*(14-10+1) = 10*10
次抽样层S4:
输入图片大小:10*10*16
卷积核大小:2*2
输出图片大小:5*5*16
卷积层C5:
输入图片大小:10*10*16
卷积核大小:5*5
卷积核数:120
输出大小:(5-5+1)*(5-5+1)*120 = 1*1*120
全连接层(full Connection)F6:
输入图片大小:1*1*120
卷积和大小:1*1
卷积核数:84
输出大小:1*1*84
输出层(Out Put):
输入大小:1*1
输出数量:10
知识点可能比较零散,我只是把我平时的笔记拼接在一起了,哈哈哈
接下来看我们的项目,新建一个文件face_train_user_keras.py,先看代码:
import random
from sklearn.model_selection import train_test_split
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import SGD
from keras.utils import np_utils
from keras.models import load_model
from keras import backend as K
import sys
import os
from load_face_dataset import load_dataset, resize_image, IMAGE_SIZE
class Dataset(object):
def __init__(self, path_name):
# 训练集
self.train_images = None
self.train_labels = None
# 验证集
self.valid_images = None
self.valid_labels = None
# 测试集
self.test_images = None
self.test_labels = None
# 数据集加载路径
self.path_name = path_name
# 当前库采用的维度顺序
self.input_shape = None
# 加载数据集并按照交叉验证的原则划分数据并进行相关预处理
'''
1.按照交叉验证的原则将数据集划分三部分:训练集、验证集、测试集
2.按照keras库运行的系统要求改变数据集维度顺序
3.将数据标签one-hot编码,使其向量化
4.归一化图像数据
'''
def load(self, img_rows=IMAGE_SIZE, img_cols=IMAGE_SIZE, img_channels=3, nb_classes=2):
# 加载数据集到内存
images, labels = load_dataset(self.path_name)
''' 这里训练集、验证集、测试集分配数据,我个人建议:
训练集:65%
测试集:25%
验证集:10%
我里我是为了各个集合之间数据不重复,先给验证集分配35%(训练集65%),
再冲验证集分配70%给测试集,剩下的就是验证集了,基本上按照上面的分配法则
'''
train_images, valid_images, train_labels, valid_labels = train_test_split(
images, labels, test_size=0.35, random_state=random.randint(0, 100))
valid_images, test_images, valid_labels, test_labels = train_test_split(
valid_images, valid_labels, test_size=0.7, random_state=random.randint(0, 100))
# 当前维度顺序为'th', 则输入图片数据时顺序为:channels, rows, cols, 否则: rows, cols, channels
# 这部分代码就是根据keras库要求的维度顺序重组训练数据集
if K.image_dim_ordering() == 'th':
train_images = train_images.reshape(
train_images.shape[0], img_channels, img_rows, img_cols)
valid_images = valid_images.reshape(
valid_images.shape[0], img_channels, img_rows, img_cols)
test_images = test_images.reshape(
test_images.shape[0], img_rows, img_cols)
self.input_shape = (img_channels, img_rows, img_cols)
else:
train_images = train_images.reshape(
train_images.shape[0], img_rows, img_cols, img_channels)
valid_images = valid_images.reshape(
valid_images.shape[0], img_rows, img_cols, img_channels)
test_images = test_images.reshape(
test_images.shape[0], img_rows, img_cols, img_channels)
self.input_shape = (img_rows, img_cols, img_channels)
# 输出训练集、验证集、测试集的数据量
print(train_images.shape[0], 'train sample')
print(valid_images.shape[0], 'valid sample')
print(test_images.shape[0], 'test sample')
# 我们的模型使用categorical_crossentropy 作为损失函数,因此需要根据类别数据nb_classes将列表标签进行
# one-hot编码使其向量化,在这里我们类别只有两种,经过转化后标签数据变为二维
train_labels = np_utils.to_categorical(train_labels, nb_classes)
valid_labels = np_utils.to_categorical(valid_labels, nb_classes)
test_labels = np_utils.to_categorical(test_labels, nb_classes)
# 像素数据浮点化以便后面归一化处理
train_images = train_images.astype('float32')
valid_images = valid_images.astype('float32')
test_images = test_images.astype('float32')
# 将像素归一化
train_images /= 255
valid_images /= 255
test_images /= 255
self.train_images = train_images
self.train_labels = train_labels
self.valid_images = valid_images
self.valid_labels = valid_labels
self.test_images = test_images
self.test_labels = test_labels
# CNN网络模型
class Model:
def __init__(self):
self.model = None
# 建立模型
def build_model(self, dataset, nb_classes=2):
self.model = Sequential()
self.model.add(Conv2D(
32, (3, 3), padding='same', input_shape=dataset.input_shape))
self.model.add(Activation('relu'))
self.model.add(Conv2D(32, (3, 3)))
self.model.add(Activation('relu'))
self.model.add(MaxPooling2D(pool_size=(2, 2)))
self.model.add(Dropout(0.25))
self.model.add(Conv2D(64, (3, 3), padding='same'))
self.model.add(Activation('relu'))
self.model.add(Conv2D(64, (3, 3)))
self.model.add(Activation('relu'))
self.model.add(MaxPooling2D(pool_size=(2, 2)))
self.model.add(Dropout(0.25))
self.model.add(Flatten())
self.model.add(Dense(512))
self.model.add(Activation('relu'))
self.model.add(Dropout(0.5))
self.model.add(Dense(nb_classes))
self.model.add(Activation('softmax'))
# 输出模型概况
self.model.summary()
def train(self, dataset, batch_size=20, nb_epoch=10, data_augmentation=True):
# 采用sgd+momentum的优化器进行训练,首先生成一个优化器
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
self.model.compile(loss='categorical_crossentropy',
optimizer=sgd, metrics=['accuracy']) # 完成模型配置
# 不使用数据提升,所谓的听声数据就是从我们提供的数据中利用旋转,反转/加噪声等方法创建新的训练数据
# 有意识的提升训练数据规模,增加训练量
if not data_augmentation:
self.model.fit(dataset.train_images,
dataset.train_labels,
batch_size=batch_size,
epochs=nb_epoch,
validation_data=(
dataset.valid_images, dataset.valid_labels),
shuffle=True)
# 使用数据提升
else:
# 定义数据生成器用于数据提升,其返回一个生成器对象datagen,
# datagen每调用一次其生成一组数据(顺序生成),节省内存,其实就是python的数据生成器
datagen = ImageDataGenerator(
featurewise_center=False, # 布尔值,使输入数据集去中心化(均值为0), 按feature执行
samplewise_center=False, # 布尔值,使输入数据的每个样本均值为0
featurewise_std_normalization=False, # 布尔值,将输入除以数据集的标准差以完成标准化, 按feature执行
samplewise_std_normalization=False, # 布尔值,将输入的每个样本除以其自身的标准差
zca_whitening=False, # 布尔值,对输入数据施加ZCA白化
rotation_range=20, # 整数,数据提升时图片随机转动的角度。随机选择图片的角度,是一个0~180的度数,取值为0~180
width_shift_range=0.2, # 浮点数,图片宽度的某个比例,数据提升时图片随机水平偏移的幅度
height_shift_range=0.2, # 浮点数,图片高度的某个比例,数据提升时图片随机竖直偏移的幅度
# 布尔值,进行随机水平翻转。随机的对图片进行水平翻转,这个参数适用于水平翻转不影响图片语义的时候
horizontal_flip=True,
vertical_flip=True # 布尔值,进行随机竖直翻转
)
# 计算整个训练样本集的数量以用于特征值归一化,ZCA白化等处理
datagen.fit(dataset.train_images)
# 利用生成器开始训练
'''
在新版本keras中
去掉了samples_per_epoch 改为 steps_per_epoch(整数,
当生成器返回steps_per_epoch次数据时计一个epoch结束,执行下一个epoch)
nb_epoch 参数命名该为epochs(整数,数据迭代的轮数)
'''
self.model.fit_generator(
datagen.flow(dataset.train_images,
dataset.train_labels, batch_size=batch_size),
steps_per_epoch=dataset.train_images.shape[0] // batch_size,
epochs=nb_epoch,
validation_data=(dataset.valid_images, dataset.valid_labels))
MODEL_PATH = './me.face.model.h5'
# 保存模型
def save_model(self, file_path=MODEL_PATH):
self.model.save(file_path)
# 加载模型
def load_model(self, file_path=MODEL_PATH):
self.model = load_model(file_path)
# 验证模型
def evaluate(self, dataset):
score = self.model.evaluate(
dataset.test_images, dataset.test_labels, verbose=1)
print('%s: %.2f%%' % (self.model.metrics_names[1], score[1] * 100))
# 识别图片
def face_predict(self, image):
# 依然是根据后端系统确定维度顺序
if K.image_dim_ordering() == 'th' and image.shape != (1, 3, IMAGE_SIZE, IMAGE_SIZE):
image = resize_image(image)
image = image.reshape((1, 3, IMAGE_SIZE, IMAGE_SIZE))
elif K.image_dim_ordering() == 'tf' and image.shape != (1, IMAGE_SIZE, IMAGE_SIZE, 3):
image = resize_image(image)
image = image.reshape((1, IMAGE_SIZE, IMAGE_SIZE, 3))
# 浮点并归一化
image = image.astype('float32')
image /= 255
# 给出输入属于各个类别的概率,我们是二值类别,则该函数会给出输入图像属于0和1的概率各为多少
# resultRat = self.model.predict_proba(image)
# 给出类别预测:0或者1
result = self.model.predict_classes(image)
# 返回类别预测结果
return result
if __name__ == '__main__':
dataset = Dataset(os.getcwd() + '/img/')
dataset.load()
model = Model()
model.build_model(dataset)执行该文件在控制台中可以看见训练模型的概况:

从上图中可以看出我的训练样本数量是817个、验证样本132个、测试样本309个
注意:在keras2.0之后model.summary()方法中去掉了 connected to 列
我们只是展示出了,训练模型并没有开始训练,在程序的后面再添加调用执行训练、验证和保存方法
在执行方法最后面添加下面方法
# 训练模型
model.train(dataset)
# 保存模型文件
# 注意如果存储的文件夹路径不存在,则保存失败
model.save_model(file_path=os.getcwd() +'/model/me.face.model.h5')
# 评估模型
model = Model()
# 加载保存好的模型
model.load_model(file_path=os.getcwd() +'/model/me.face.model.h5')
# 执行验证方法
model.evaluate(dataset)再次执行该文件,打印出训练信息如下图:

从上图可以看出收敛的速度还是挺快的,训练10次,最后的精确度在 99.87%还是挺不错的,最后验证的结果是100%
五. 使用之前训练好的模型识别图片
执行的方法是在我们第一个显示视频流的地方调用model类中定义的face_predict() 方法,如下:
# 判断若未识别到则不进行处理
if len(faceRects) > 0:
for faceRect in faceRects:
# 获取识别信息的坐标信息
x, y, w, h = faceRect
# 绘制方框(这里是给原图上绘制,不是灰度图片)
cv2.rectangle(frame, (x - 10, y - 10),
(x + 10, y + 10), color, 2)
''' --------------识别代码开始-----------------'''
faceID = model.face_predict(img)[0]
if faceID== 0:
self.printText(cv2,img,x,y,w,h,'me',(0,255,0))
else:
self.printText(cv2,img,x,y,w,h,'not me')
''' --------------识别代码结束-----------------'''在数据加载时me 分类的代号是0 所以如果识别的代号是0时就说明检测到了自己,如果是1 的话就是检测到另一个分类集(other文件夹下图片的人)
在图片中,若检测到了自己就会在人脸识别区域图片显示‘me’字样,若不是则会显示‘not me ’字样
结果如下图:

以上是我运用卷积神经网络做人脸识别的学习笔记,识别率并不是很高,后面有时间的话,我会再分享另一个识别率较高的机器学习,这个对于设备的要求比较高,没有GPU的话建议別试,没有检测到人脸还行,检测到会卡死的,别问我怎么知道的,不说了 我重启机器去了……
最后,论显卡的重要性:

如若有错误的地方,还请大神留言指出或加QQ:754395771