SSD网络解析之MultiBoxLoss层
SSD网络中的MultiBoxLoss层是根据论文2.2节所提出的损失函数而写的相应caffe实现,也是整个SSD网络很重要的部分。
首先,我们还是先来看一下论文原文对此部分的描述:
①英文部分
Training objective The SSD training objective is derived from the MultiBox objective [7,8] but is extended to handle multiple object categories. Let ![]() be an indicator for matching the
be an indicator for matching the  -th default box to
-th default box to  -th ground truth box of category
-th ground truth box of category  . In the matching strategy above, we can have
. In the matching strategy above, we can have ![]() . The overall objective loss function is a weighted sum of the localization loss (loc) and the confidence loss (conf):
. The overall objective loss function is a weighted sum of the localization loss (loc) and the confidence loss (conf):
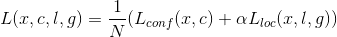
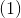
where N is the number of matched default boxes. If N = 0, wet set the loss to 0. The localization loss is a Smooth L1 loss [6] between the predicted box ( ) and the ground truth box (
) and the ground truth box (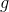 ) parameters. Similar to Faster R-CNN [2], we regress to offsets for the center
) parameters. Similar to Faster R-CNN [2], we regress to offsets for the center ![]() of the default bounding box (
of the default bounding box ( ) and for its width (
) and for its width ( ) and height (
) and height ( ).
).

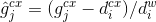
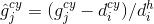

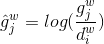
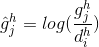
The confidence loss is the softmax loss over multiple classes confidences ( ).
).

![]()

and the weight term  is set to 1 by cross validation.
is set to 1 by cross validation.
Hard negative mining After the matching step, most of the default boxes are nega-tives, especially when the number of possible default boxes is large. This introduces a significant imbalance between the positive and negative training examples. Instead of using all the negative examples, we sort them using the highest confidence loss for each
default box and pick the top ones so that the ratio between the negatives and positives is at most 3:1. We found that this leads to faster optimization and a more stable training.
②我翻译的中文部分
训练目标:SSD训练目标源自MultiBox的目标[7,8],但扩展为处理多个目标类别。使![]() 表示第个默认框与第个地面实况框是否匹配且是否存在类别的指标。根据上述匹配策略,我们得到
表示第个默认框与第个地面实况框是否匹配且是否存在类别的指标。根据上述匹配策略,我们得到![]() 。总体目标损失函数是定位损失(loc)和置信度损失(conf)的加权和:
。总体目标损失函数是定位损失(loc)和置信度损失(conf)的加权和:
其中N为匹配上的默认框数目。如果N=0,我们设置loss为0。定位损失是一个由预测框()和地面实况框()参数产生smooth L1 loss。与Faster R-CNN相似,我们回归默认框()的中心![]() 和它的宽度()、高度()。
和它的宽度()、高度()。
置信度损失是在多类别置信度()上的softmax损失。
![]()
以及权重项由于交叉验证设置为1。
硬负例挖掘(Hard negative mining):在匹配步骤之后,大多数默认框都是负样本,特别是当可能的默认框的数量很大时。这引入了正样本和负样本之间的显着不平衡。我们不是使用所有的负样本,而是使用最高置信度损失对每个默认框进行排序,然后选择顶部的那些,使得负例和正例之间的比值最多为3:1。我们发现这可以带来更快的优化和更稳定的训练。
在了解上面的基础上,我们还需要查看一下MultiBoxLoss层的设置参数,即定义在caffe.proto文件中的MultiBoxLossParameter类,如下(参数较多,大家自行看英文注释即可):
// Message that store parameters used by MultiBoxLossLayer
message MultiBoxLossParameter {
// Localization loss type.
enum LocLossType {
L2 = 0;
SMOOTH_L1 = 1;
}
optional LocLossType loc_loss_type = 1 [default = SMOOTH_L1];
// Confidence loss type.
enum ConfLossType {
SOFTMAX = 0;
LOGISTIC = 1;
}
optional ConfLossType conf_loss_type = 2 [default = SOFTMAX];
// Weight for localization loss.
optional float loc_weight = 3 [default = 1.0];
// Number of classes to be predicted. Required!
optional uint32 num_classes = 4;
// If true, bounding box are shared among different classes.
optional bool share_location = 5 [default = true];
// Matching method during training.
enum MatchType {
BIPARTITE = 0;
PER_PREDICTION = 1;
}
optional MatchType match_type = 6 [default = PER_PREDICTION];
// If match_type is PER_PREDICTION, use overlap_threshold to
// determine the extra matching bboxes.
optional float overlap_threshold = 7 [default = 0.5];
// Use prior for matching.
optional bool use_prior_for_matching = 8 [default = true];
// Background label id.
optional uint32 background_label_id = 9 [default = 0];
// If true, also consider difficult ground truth.
optional bool use_difficult_gt = 10 [default = true];
// If true, perform negative mining.
// DEPRECATED: use mining_type instead.
optional bool do_neg_mining = 11;
// The negative/positive ratio.
optional float neg_pos_ratio = 12 [default = 3.0];
// The negative overlap upperbound for the unmatched predictions.
optional float neg_overlap = 13 [default = 0.5];
// Type of coding method for bbox.
optional PriorBoxParameter.CodeType code_type = 14 [default = CORNER];
// If true, encode the variance of prior box in the loc loss target instead of
// in bbox.
optional bool encode_variance_in_target = 16 [default = false];
// If true, map all object classes to agnostic class. It is useful for learning
// objectness detector.
optional bool map_object_to_agnostic = 17 [default = false];
// If true, ignore cross boundary bbox during matching.
// Cross boundary bbox is a bbox who is outside of the image region.
optional bool ignore_cross_boundary_bbox = 18 [default = false];
// If true, only backpropagate on corners which are inside of the image
// region when encode_type is CORNER or CORNER_SIZE.
optional bool bp_inside = 19 [default = false];
// Mining type during training.
// NONE : use all negatives.
// MAX_NEGATIVE : select negatives based on the score.
// HARD_EXAMPLE : select hard examples based on "Training Region-based Object Detectors with Online Hard Example Mining", Shrivastava et.al.
enum MiningType {
NONE = 0;
MAX_NEGATIVE = 1;
HARD_EXAMPLE = 2;
}
optional MiningType mining_type = 20 [default = MAX_NEGATIVE];
// Parameters used for non maximum suppression durig hard example mining.
optional NonMaximumSuppressionParameter nms_param = 21;
optional int32 sample_size = 22 [default = 64];
optional bool use_prior_for_nms = 23 [default = false];
}在此就解释一下几个参数:
loc_weight:对应于上面公式中的权重项
num_classes:训练集中目标类别数目
share_location:在定位预测中,预测框是否在不同目标类别之间共享(不共享的话会产生num_priors*num_classes个预测框,共享的话产生num_priors个预测框,SSD采用共享的形式,其实一个预测框只能属于一个地面实况框,而一个地面实况框只包含一个目标,采用共享形式就足够了,且能加快执行速度)
use_prior_for_matching:是否使用默认框进行匹配(具体看后面的函数中分析)
do_neg_mining:是否进行负样本挖掘(对应于上面的硬负例挖掘)
看完上面的caffe.proto中的相关设置,我们直接来浏览一下SSD中对该层的调用(摘自SSD300中的train.prototxt):
layer {
name: "mbox_loss"
type: "MultiBoxLoss"
bottom: "mbox_loc"
bottom: "mbox_conf"
bottom: "mbox_priorbox"
bottom: "label"
top: "mbox_loss"
include {
phase: TRAIN
}
propagate_down: true
propagate_down: true
propagate_down: false
propagate_down: false
loss_param {
normalization: VALID
}
multibox_loss_param {
loc_loss_type: SMOOTH_L1
conf_loss_type: SOFTMAX
loc_weight: 1.0
num_classes: 21
share_location: true
match_type: PER_PREDICTION
overlap_threshold: 0.5
use_prior_for_matching: true
background_label_id: 0
use_difficult_gt: true
neg_pos_ratio: 3.0
neg_overlap: 0.5
code_type: CENTER_SIZE
ignore_cross_boundary_bbox: false
mining_type: MAX_NEGATIVE
}
}
可知输入blob有四个,输出blob有一个,而各输入blob的含义如下:
bottom[0]:存储着每个预测框的定位信息,大小为num×(num_priors_*loc_classes_*4),即bottom[0]->num()=num;bottom[0]->channels()=num_priors_*loc_classes_*4(其中num为batch size,即输入图像数目;num_priors_为默认框数目;loc_classes_与share_location_有关,SSD默认loc_classes_为1,即在不同类别间共享预测框;4表示每个预测框左上角和右下角坐标信息)。该blob数据来自于train.prototxt中的mbox_loc层的输出(该层是一个Concat层,将各层的预测框定位数据联结成一个blob)。
bottom[1]:存储着每个预测框中的类别置信度信息,大小为num×(num_priors_*21),即bottom[1]->num()=num;bottom[1]->channels()=num_priors_*21(其中21是针对VOC数据集而言的,共21个类别)。该blob数据来自于train.prototxt中的mbox_conf层的输出(该层同样是一个Concat层)。
bottom[2]:存储着每一个默认框的左上角和右下角坐标及其variance,大小为1×2×(num_priors_*4),即bottom[2]->num()=1,表示所有输入图像共享一组默认框(原因是输入图像大小都是一样的);bottom[2]->channels()=2,第一个通道存储着左上角和右下角坐标信息,第二个通道存储着这些坐标的variance数据。该blob数据来自于train.prototxt中的mbox_priorbox层的输出(该层同样是一个Concat层)
bottom[3]:存储着地面实况信息,具体大小还未知,需要查看SSD的数据层加载方式。
一. multibox_loss_layer.hpp头文件
不做过多解释,完全是按着caffe中定义损失层的形式写的,大家简单浏览即可,具体的还是要看cpp文件中的实现:
#ifndef CAFFE_MULTIBOX_LOSS_LAYER_HPP_
#define CAFFE_MULTIBOX_LOSS_LAYER_HPP_
#include 二. multibox_loss_layer.cpp文件
以下所需要阅读的代码量很大,大家阅读前请做好心理准备(里面所用到的大部分函数均在bbox_util.cpp文件中实现)。
(1)LayerSetUp()函数
template
void MultiBoxLossLayer::LayerSetUp(const vector*>& bottom,
const vector*>& top) {
LossLayer::LayerSetUp(bottom, top); //由于继承于LossLayer,所以需要调用LossLayer中的LayerSetUp函数先进行部分初始化(所有loss类都是这样的操作)
if (this->layer_param_.propagate_down_size() == 0) { //如果没有指定各输入blob是否进行后向传播,则采用默认形式
//即bottom[0]和bottom[1]需要后向传播;bottom[2]和bottom[3]不需要后向传播
this->layer_param_.add_propagate_down(true);
this->layer_param_.add_propagate_down(true);
this->layer_param_.add_propagate_down(false);
this->layer_param_.add_propagate_down(false);
}
//获取设置的该层的参数
const MultiBoxLossParameter& multibox_loss_param =
this->layer_param_.multibox_loss_param();
multibox_loss_param_ = this->layer_param_.multibox_loss_param();
num_ = bottom[0]->num(); //批量数
num_priors_ = bottom[2]->height() / 4; //默认框数目(4表示默认框左上角和右下角左边或这些坐标的variance,详见PriorBox层)
// Get other parameters.
CHECK(multibox_loss_param.has_num_classes()) << "Must provide num_classes."; //必须设置所训练的数据集中的目标有几类
num_classes_ = multibox_loss_param.num_classes();
CHECK_GE(num_classes_, 1) << "num_classes should not be less than 1.";
share_location_ = multibox_loss_param.share_location(); //是否在不同目标类别中共享边界框
loc_classes_ = share_location_ ? 1 : num_classes_; //根据是否共享,设置loc_classes_
background_label_id_ = multibox_loss_param.background_label_id(); //获取背景类的ID
use_difficult_gt_ = multibox_loss_param.use_difficult_gt(); //是否考虑困难的地面实况(difficult ground truth)
mining_type_ = multibox_loss_param.mining_type(); //负样本挖掘方式
if (multibox_loss_param.has_do_neg_mining()) {
LOG(WARNING) << "do_neg_mining is deprecated, use mining_type instead."; //do_neg_mining已弃用,使用mining_type代替
do_neg_mining_ = multibox_loss_param.do_neg_mining();
CHECK_EQ(do_neg_mining_,
mining_type_ != MultiBoxLossParameter_MiningType_NONE);
}
do_neg_mining_ = mining_type_ != MultiBoxLossParameter_MiningType_NONE; //用于判断是否需要做负样本挖掘
if (!this->layer_param_.loss_param().has_normalization() &&
this->layer_param_.loss_param().has_normalize()) {
normalization_ = this->layer_param_.loss_param().normalize() ? //若normalize为真则采用valid模式,否则用batch_size模式
LossParameter_NormalizationMode_VALID : //valid模式表示除以总输出数目(总样本数)但不考虑ignore_label,来进行归一化
LossParameter_NormalizationMode_BATCH_SIZE; //batch_size模式表示除以batch size来进行归一化
} else {
normalization_ = this->layer_param_.loss_param().normalization(); //其余情况下由normalization参数决定(full/valid/batch_size中一种),默认采用valid
}
if (do_neg_mining_) {
CHECK(share_location_)
<< "Currently only support negative mining if share_location is true.";
}
vector loss_shape(1, 1);
// Set up localization loss layer. 建立定位损失层
loc_weight_ = multibox_loss_param.loc_weight(); //定位损失权重,对应于论文2.2节中总体目标损失函数中的参数阿尔法
loc_loss_type_ = multibox_loss_param.loc_loss_type(); //定位损失类型
// fake shape.
vector loc_shape(1, 1); //定义1个int型的向量,且初始化为1
loc_shape.push_back(4);
loc_pred_.Reshape(loc_shape); //存储匹配的定位预测
loc_gt_.Reshape(loc_shape); //存储对应匹配的地面实况
loc_bottom_vec_.push_back(&loc_pred_); //即loc_bottom_vec_包含loc_pred和loc_gt,是输入blob的所有者
loc_bottom_vec_.push_back(&loc_gt_);
loc_loss_.Reshape(loss_shape); //存储定位损失
loc_top_vec_.push_back(&loc_loss_); //loc_top_vec_包含loc_loss,是输出blob的所有者
if (loc_loss_type_ == MultiBoxLossParameter_LocLossType_L2) {//欧式距离损失(L2损失)
LayerParameter layer_param;EncodeLocPrediction
layer_param.set_name(this->layer_param_.name() + "_l2_loc");
layer_param.set_type("EuclideanLoss");
layer_param.add_loss_weight(loc_weight_);
loc_loss_layer_ = LayerRegistry::CreateLayer(layer_param); //根据layer_param创建一个loss层(即注册一个EuclideanLoss层)
loc_loss_layer_->SetUp(loc_bottom_vec_, loc_top_vec_); //调用Layer类的SetUp函数实现EuclideanLoss层的初始化
} else if (loc_loss_type_ == MultiBoxLossParameter_LocLossType_SMOOTH_L1) {//SMOOTH_L1损失(详细参见Fast R-CNN)
LayerParameter layer_param;
layer_param.set_name(this->layer_param_.name() + "_smooth_L1_loc");
layer_param.set_type("SmoothL1Loss");
layer_param.add_loss_weight(loc_weight_);
loc_loss_layer_ = LayerRegistry::CreateLayer(layer_param);
loc_loss_layer_->SetUp(loc_bottom_vec_, loc_top_vec_); //调用Layer类的SetUp函数实现SmoothL1Loss层的初始化
} else {
LOG(FATAL) << "Unknown localization loss type.";
}
// Set up confidence loss layer.建立置信度损失层
conf_loss_type_ = multibox_loss_param.conf_loss_type(); //置信度损失类型
conf_bottom_vec_.push_back(&conf_pred_); //先不对conf_pred_和conf_gt_这两个blob设置大小(之后需要根据不同的损失函数设置大小)
conf_bottom_vec_.push_back(&conf_gt_);
conf_loss_.Reshape(loss_shape);
conf_top_vec_.push_back(&conf_loss_);
if (conf_loss_type_ == MultiBoxLossParameter_ConfLossType_SOFTMAX) {//softmax损失
//先检查背景类是否在所设定的类别中
CHECK_GE(background_label_id_, 0)
<< "background_label_id should be within [0, num_classes) for Softmax.";
CHECK_LT(background_label_id_, num_classes_)
<< "background_label_id should be within [0, num_classes) for Softmax.";
LayerParameter layer_param;
layer_param.set_name(this->layer_param_.name() + "_softmax_conf");
layer_param.set_type("SoftmaxWithLoss");
layer_param.add_loss_weight(Dtype(1.)); //损失权重始终为1,对应论文2.2节中总体损失函数中的前半部分
layer_param.mutable_loss_param()->set_normalization(
LossParameter_NormalizationMode_NONE);
SoftmaxParameter* softmax_param = layer_param.mutable_softmax_param();
softmax_param->set_axis(1);
// Fake reshape.
vector conf_shape(1, 1);
conf_gt_.Reshape(conf_shape);
conf_shape.push_back(num_classes_);
conf_pred_.Reshape(conf_shape);
conf_loss_layer_ = LayerRegistry::CreateLayer(layer_param); //注册一个SoftmaxWithLoss层
conf_loss_layer_->SetUp(conf_bottom_vec_, conf_top_vec_); //调用Layer类的SetUp函数实现SoftmaxWithLoss层的初始化
} else if (conf_loss_type_ == MultiBoxLossParameter_ConfLossType_LOGISTIC) { //logistic损失(采用sigmoid交叉熵损失函数)
LayerParameter layer_param;
layer_param.set_name(this->layer_param_.name() + "_logistic_conf");
layer_param.set_type("SigmoidCrossEntropyLoss");
layer_param.add_loss_weight(Dtype(1.));
// Fake reshape.
vector conf_shape(1, 1);
conf_shape.push_back(num_classes_);
conf_gt_.Reshape(conf_shape);
conf_pred_.Reshape(conf_shape);
conf_loss_layer_ = LayerRegistry::CreateLayer(layer_param);
conf_loss_layer_->SetUp(conf_bottom_vec_, conf_top_vec_); //调用Layer类的SetUp函数实现SigmoidCrossEntropyLoss层的初始化
} else {
LOG(FATAL) << "Unknown confidence loss type.";
}
}
LayerSetUp()函数的目的有两个:
1.初始化该层,加载caffe.proto中定义的一系列参数设置值;
2.创建一个定位损失层和置信度损失层(均采用fake shape形式创建,即采用假定的输入输出bolb大小进行初始化网络),用于后续的前向计算和后向传播。
这里可以分开计算上述公式(1)中的定位损失和置信度损失(两种损失是相加形式,且用到的变量并不相同,求导部分可以分开进行,即使具有相同的变量,也可以分开求导,最后相加),既然可以分开计算,那我们就可以分开利用caffe中的不同损失函数实现相关的前向损失计算和后向梯度传播。而这里代码中的层中层更是让人耳目一新,在MultiBoxLoss这一损失层中加入定位损失层和置信度损失层,我颇有受益。
注:SmoothL1LossLayer参见链接。
(2)Reshape()函数
template
void MultiBoxLossLayer::Reshape(const vector*>& bottom,
const vector*>& top) {
LossLayer::Reshape(bottom, top); //调用LossLayer中的Reshape函数进行部分Reshape
num_ = bottom[0]->num(); //批量数
num_priors_ = bottom[2]->height() / 4; //默认框数目
num_gt_ = bottom[3]->height(); //地面实况数目
CHECK_EQ(bottom[0]->num(), bottom[1]->num());
CHECK_EQ(num_priors_ * loc_classes_ * 4, bottom[0]->channels())
<< "Number of priors must match number of location predictions."; //默认框参数数目必须与定位预测数目匹配
CHECK_EQ(num_priors_ * num_classes_, bottom[1]->channels())
<< "Number of priors must match number of confidence predictions."; //默认框数目必须与置信度预测数目匹配
} 此部分函数比较简单,只是获取了一些参数,并进行了相应的检查。
(3)Forward_cpu()函数
//前向传播
template
void MultiBoxLossLayer::Forward_cpu(const vector*>& bottom,
const vector*>& top) {
const Dtype* loc_data = bottom[0]->cpu_data(); //定位预测数据
const Dtype* conf_data = bottom[1]->cpu_data(); //置信度预测数据
const Dtype* prior_data = bottom[2]->cpu_data(); //默认框数据
const Dtype* gt_data = bottom[3]->cpu_data(); //地面实况数据
// Retrieve all ground truth.恢复地面实况
//注:NormalizedBBox类定义在caffe.proto中
map > all_gt_bboxes;
GetGroundTruth(gt_data, num_gt_, background_label_id_, use_difficult_gt_,
&all_gt_bboxes);
// Retrieve all prior bboxes. It is same within a batch since we assume all
// images in a batch are of same dimension.
//恢复默认框
//注:每一层的所有特征图共享一组默认框
vector prior_bboxes;
vector > prior_variances;
GetPriorBBoxes(prior_data, num_priors_, &prior_bboxes, &prior_variances);
// Retrieve all predictions. 恢复所有定位预测EncodeLocPrediction
vector all_loc_preds;
GetLocPredictions(loc_data, num_, num_priors_, loc_classes_, share_location_,
&all_loc_preds);
// Find matches between source bboxes and ground truth bboxes.
//寻找与地面实况框匹配的预测框
vector > > all_match_overlaps;
FindMatches(all_loc_preds, all_gt_bboxes, prior_bboxes, prior_variances,
multibox_loss_param_, &all_match_overlaps, &all_match_indices_);
num_matches_ = 0;
int num_negs = 0;
// Sample hard negative (and positive) examples based on mining type.
//负样本挖掘(防止副样本数量太多,导致训练不平衡,详见论文2.2节)
MineHardExamples(*bottom[1], all_loc_preds, all_gt_bboxes, prior_bboxes,
prior_variances, all_match_overlaps, multibox_loss_param_,
&num_matches_, &num_negs, &all_match_indices_,
&all_neg_indices_); //all_match_indices_存储所有预测框与地面实况框之间的匹配对;all_neg_indices_存储所有负样本索引
//以下进行定位损失的前向传播
if (num_matches_ >= 1) { //定位损失只对匹配上的预测框进行,其余无匹配对象的不需要计算定位损失,直接为0
// Form data to pass on to loc_loss_layer_.
vector loc_shape(2);
loc_shape[0] = 1;
loc_shape[1] = num_matches_ * 4;
loc_pred_.Reshape(loc_shape);
loc_gt_.Reshape(loc_shape);
Dtype* loc_pred_data = loc_pred_.mutable_cpu_data();
Dtype* loc_gt_data = loc_gt_.mutable_cpu_data();
//得到编码后的预测框和地面实况框匹配对(详见论文2.2节)
EncodeLocPrediction(all_loc_preds, all_gt_bboxes, all_match_indices_,
prior_bboxes, prior_variances, multibox_loss_param_,
loc_pred_data, loc_gt_data);
loc_loss_layer_->Reshape(loc_bottom_vec_, loc_top_vec_); //调用loc_loss_layer_层的Reshape函数重新规划大小
loc_loss_layer_->Forward(loc_bottom_vec_, loc_top_vec_); //loc_loss_layer_层前向传播
} else {
loc_loss_.mutable_cpu_data()[0] = 0;
}
// Form data to pass on to conf_loss_layer_.
//以下进行置信度损失的前向传播(置信度损失对每个预测框均需要计算)
if (do_neg_mining_) {
num_conf_ = num_matches_ + num_negs;
} else {
num_conf_ = num_ * num_priors_;
}
if (num_conf_ >= 1) {
// Reshape the confidence data.
vector conf_shape;
if (conf_loss_type_ == MultiBoxLossParameter_ConfLossType_SOFTMAX) {
conf_shape.push_back(num_conf_);
conf_gt_.Reshape(conf_shape);
conf_shape.push_back(num_classes_);
conf_pred_.Reshape(conf_shape);
} else if (conf_loss_type_ == MultiBoxLossParameter_ConfLossType_LOGISTIC) {
conf_shape.push_back(1);
conf_shape.push_back(num_conf_);
conf_shape.push_back(num_classes_);
conf_gt_.Reshape(conf_shape);
conf_pred_.Reshape(conf_shape);
} else {
LOG(FATAL) << "Unknown confidence loss type.";
}
if (!do_neg_mining_) { //如果不做负样本挖掘
// Consider all scores.
// Share data and diff with bottom[1].
CHECK_EQ(conf_pred_.count(), bottom[1]->count());
conf_pred_.ShareData(*(bottom[1])); //conf_pred_直接使用所有的置信度预测数据
}
Dtype* conf_pred_data = conf_pred_.mutable_cpu_data();
Dtype* conf_gt_data = conf_gt_.mutable_cpu_data();
caffe_set(conf_gt_.count(), Dtype(background_label_id_), conf_gt_data); //调用caffe_set函数完成初始化(用背景类的标签初始化)
//解码所需要的置信度数据和地面实况
EncodeConfPrediction(conf_data, num_, num_priors_, multibox_loss_param_,
all_match_indices_, all_neg_indices_, all_gt_bboxes,
conf_pred_data, conf_gt_data);
conf_loss_layer_->Reshape(conf_bottom_vec_, conf_top_vec_); //调用conf_loss_layer_层的Reshape函数重新规划大小
conf_loss_layer_->Forward(conf_bottom_vec_, conf_top_vec_); //conf_loss_layer_前向传播
} else {
conf_loss_.mutable_cpu_data()[0] = 0;
}
top[0]->mutable_cpu_data()[0] = 0;
if (this->layer_param_.propagate_down(0)) {
//当归一化类型为VALID时,normalizer = num_matches_(SSD采用VALID,对应于论文中的2.2节的参数N)
Dtype normalizer = LossLayer::GetNormalizer(
normalization_, num_, num_priors_, num_matches_);
top[0]->mutable_cpu_data()[0] +=
loc_weight_ * loc_loss_.cpu_data()[0] / normalizer;
}
if (this->layer_param_.propagate_down(1)) {
Dtype normalizer = LossLayer::GetNormalizer(
normalization_, num_, num_priors_, num_matches_);
top[0]->mutable_cpu_data()[0] += conf_loss_.cpu_data()[0] / normalizer;
}
} Forward_cpu()函数中包含的各种在bbox_util.cpp文件中实现的函数请参见此链接。
(4)Backward_cpu()函数
//反向传播
template
void MultiBoxLossLayer::Backward_cpu(const vector*>& top,
const vector& propagate_down,
const vector*>& bottom) {
if (propagate_down[2]) {
LOG(FATAL) << this->type()
<< " Layer cannot backpropagate to prior inputs."; //该层不能对默认框进行反向传播
}
if (propagate_down[3]) {
LOG(FATAL) << this->type()
<< " Layer cannot backpropagate to label inputs."; //该层不能对地面实况(label)进行反向传播
} //由此也可以看出需要在prototxt文档中定义该层的四个propagate_down参数(前两个为true,后两个为false)
// Back propagate on location prediction.
//以下进行定位预测的反向传播
if (propagate_down[0]) {
Dtype* loc_bottom_diff = bottom[0]->mutable_cpu_diff();
caffe_set(bottom[0]->count(), Dtype(0), loc_bottom_diff); //先用0初始化loc_bottom_diff
if (num_matches_ >= 1) {
vector loc_propagate_down;
// Only back propagate on prediction, not ground truth.
//调用loc_loss_layer_层的Backward()函数时需要设置反向传播标志
loc_propagate_down.push_back(true); //定位预测需要反向传播
loc_propagate_down.push_back(false); //地面实况不需要反向传播
loc_loss_layer_->Backward(loc_top_vec_, loc_propagate_down,
loc_bottom_vec_);
// Scale gradient.
//缩放梯度发原因在于,损失函数中也进行此缩放,即损失函数中乘了一个缩放因子sacle,相应求出的梯度中也要乘上此因子
Dtype normalizer = LossLayer::GetNormalizer(
normalization_, num_, num_priors_, num_matches_);
//计算缩放因子,本质就是损失权重/归一化数目(top[0]->cpu_diff()[0]中存的即是损失权重,
//详细可参见:https://blog.csdn.net/qq_21368481/article/details/81950538)
Dtype loss_weight = top[0]->cpu_diff()[0] / normalizer;
caffe_scal(loc_pred_.count(), loss_weight, loc_pred_.mutable_cpu_diff()); //调用caffe_scal进行缩放
// Copy gradient back to bottom[0].
//以下通过匹配对应关系(存放在all_match_indices_中)将梯度拷贝到对应位置
const Dtype* loc_pred_diff = loc_pred_.cpu_diff();
int count = 0;
for (int i = 0; i < num_; ++i) { //循环遍历所有输入图像
for (map >::iterator it =
all_match_indices_[i].begin();
it != all_match_indices_[i].end(); ++it) { //循环遍历所有目标类别
const int label = share_location_ ? 0 : it->first;
const vector& match_index = it->second;
for (int j = 0; j < match_index.size(); ++j) { //循环遍历所有预测框
if (match_index[j] <= -1) { //如果无匹配对象,直接跳过
continue;
}
// Copy the diff to the right place. 拷贝梯度到正确位置
int start_idx = loc_classes_ * 4 * j + label * 4; //计算索引号
caffe_copy(4, loc_pred_diff + count * 4,
loc_bottom_diff + start_idx);//调用caffe_copy进行拷贝
++count;
}
}
loc_bottom_diff += bottom[0]->offset(1); //调用offset更新指针位置
}
}
}
// Back propagate on confidence prediction.
//以下进行置信度预测的反向传播
if (propagate_down[1]) {
Dtype* conf_bottom_diff = bottom[1]->mutable_cpu_diff();
caffe_set(bottom[1]->count(), Dtype(0), conf_bottom_diff); //先用0初始化conf_bottom_diff
if (num_conf_ >= 1) {
vector conf_propagate_down;
// Only back propagate on prediction, not ground truth.
conf_propagate_down.push_back(true);
conf_propagate_down.push_back(false);
conf_loss_layer_->Backward(conf_top_vec_, conf_propagate_down,
conf_bottom_vec_);//调用conf_loss_layer_的反向传播函数
// Scale gradient. 原因参见定位预测反向传播部分
Dtype normalizer = LossLayer::GetNormalizer(
normalization_, num_, num_priors_, num_matches_);
Dtype loss_weight = top[0]->cpu_diff()[0] / normalizer;
caffe_scal(conf_pred_.count(), loss_weight,
conf_pred_.mutable_cpu_diff());
// Copy gradient back to bottom[1].
//以下通过正负样本索引(正样本存放在all_match_indices_;负样本存放在all_neg_indices_中)将梯度拷贝到对应位置
const Dtype* conf_pred_diff = conf_pred_.cpu_diff();
if (do_neg_mining_) {
int count = 0;
for (int i = 0; i < num_; ++i) { //循环遍历所有输入图像
// Copy matched (positive) bboxes scores' diff.
//以下拷贝正样本部分的梯度
const map >& match_indices = all_match_indices_[i];
for (map >::const_iterator it =
match_indices.begin(); it != match_indices.end(); ++it) {//循环遍历所有目标类别
const vector& match_index = it->second;
CHECK_EQ(match_index.size(), num_priors_);
for (int j = 0; j < num_priors_; ++j) { //循环遍历所有预测框
if (match_index[j] <= -1) { //如果无匹配对象,直接跳过
continue;
}
// Copy the diff to the right place.
caffe_copy(num_classes_,
conf_pred_diff + count * num_classes_,
conf_bottom_diff + j * num_classes_); //调用caffe_copy拷贝到对应位置
++count;
}
}
// Copy negative bboxes scores' diff.
//以下拷贝负样本部分的梯度
for (int n = 0; n < all_neg_indices_[i].size(); ++n) {
int j = all_neg_indices_[i][n];
CHECK_LT(j, num_priors_);
caffe_copy(num_classes_,
conf_pred_diff + count * num_classes_,
conf_bottom_diff + j * num_classes_);//调用caffe_copy拷贝到对应位置
++count;
}
conf_bottom_diff += bottom[1]->offset(1); //调用offset更新指针位置
}
} else {
// The diff is already computed and stored.
bottom[1]->ShareDiff(conf_pred_); //如果没有进行负样本挖掘,则直接共享conf_pred_的diff
}
}
}
// After backward, remove match statistics.
//反向传播完毕后,清空本次迭代所用到的一系列索引变量
all_match_indices_.clear();
all_neg_indices_.clear();
}
反向传播实质上是通过调用之前创建的定位损失层和置信度损失层的Backward_cpu()函数实现,也是分别进行的,通过Forward_cpu()中获得的匹配对索引和负样本索引来实现反向传播(即定位损失中只更新匹配上地面实况框的那些预测框的参数信息;置信度损失只更新挑选出的正负样本所对应的置信度参数信息;其余参数均不进行更新,因为这些参数压根没参与损失函数的计算,也就无所谓反向传播(这些参数的反向传播梯度均为0),故每一张输入图像所对应的更新哪些参数都是不一样的,有点类似于dropout)。