线性表——Data Structure(C语言描述)
是时候补一补基础了,那么在算法之前,要搞定的就是数据结构。
- 基本概念
- 线性表的顺序存储结构
- 线性表的顺序存储结构的表示和实现
- 初始化一个空的线性表InitList
- 销毁线性表DestroyList
- 清空线性表ClearList
- 判断线性表是否为空isEmpty
- 获取长度getLength
- 根据位置获取元素GetElem
- 比较两个元素是否相等compare
- 查找元素FindElem
- 查找前驱元素PreElem
- 查找后继元素NextElem
- 插入元素InsertElem
- 删除元素并返回其值DeleteElem
- 访问元素visit
- 遍历线性表TraverseList
- 线性表顺序存储结构的优缺点
- 线性表的顺序存储结构的表示和实现
- 线性表的链式存储结构
- 头指针和头结点的异同
- 单链表的表示和实现
- 初始化一个空的线性表InitList
- 销毁线性表DestroyList
- 清空线性表ClearList
- 判断是否为空isEmpty
- 获取长度GetLength
- 根据位置获取元素GetElem
- 比较两个元素是否相等compare
- 查找指定元素的位置FindElem
- 获取前驱元素PreElem
- 获取后继元素NextElem
- 插入元素InsertElem
- 删除元素并返回值DeleteElem
- 访问元素visit
- 遍历线性表TraverseList
- 单链表结构与顺序存储结构的优缺点对比
- 静态链表
- 静态链表的初始化
- 静态链表的插入操作
- 静态链表的删除操作
- 静态链表的优缺点
- 循环链表和双向链表
- 循环链表
- 双向链表
基本概念
首先介绍其中比较重要的几个基本概念
数据(data)是对客观事物的符号表示,在计算机科学中是指所有能输入到计算机中并被计算机程序处理的符号的总称
数据元素(data element)是数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理。
数据对象(data object)是性质相同的数据元素的结合,是数据的一个子集。
数据结构(data structure)是相互之间存在一种或多种特定关系的数据元素的集合。
根据数据元素之间关系的不同特性,通常有下列四类基本结构:
- 集合:结构中的数据元素之间除了“同属于一个集合”的关系外,别无其他关系
- 线性结构:结构中的数据元素之间存在一个对一个的关系
- 树形结构 :结构中的数据元素之间存在一个对多个的关系
- 图状结构或网状结构: 结构中的数据元素之间存在多个对多个的关系
线性表(List):零个或者多个数据严肃的有限序列
线性表的顺序存储结构
线性表的顺序存储结构的表示和实现
线性表的顺序表示指的是用一组地址连续的存储单元一次存储线性表的数据元素
#include 初始化一个空的线性表(InitList)
/*
* 初始化一个空的线性表
*/
Status InitList(SqList *L)
{
L->elem = (Elemtype *) malloc(INIT_SIZE * sizeof(Elemtype));
if (!L->elem)
{
return ERROR;
}
L->length = 0; //空表长度为0
L->size = INIT_SIZE; //初始存储容量
return OK;
}销毁线性表(DestroyList)
/*
* 销毁线性表
*/
Status DestroyList(SqList *L)
{
free(L->elem);
L->length = 0;
L->size = 0;
return OK;
}清空线性表(ClearList)
/*
* 清空线性表
*/
Status ClearList(SqList *L)
{
L->length = 0;
return OK;
}判断线性表是否为空(isEmpty)
/*
* 判断线性表是否为空
*/
Status isEmpty(const SqList L)
{
if (0 == L.length)
{
return TRUE; //这里为什么把0写前边。。。好别扭。。
}
else
{
return FALSE;
}
}获取长度(getLength)
/*
* 获取长度
*/
Status getLength(const SqList L)
{
return L.length; //这个最简单粗暴又多此一举了
}根据位置获取元素(GetElem)
/*
* 根据位置获取元素
*/
Status GetElem(const SqList L, int i, Elemtype *e)
{
if (i < 1 || i > L.length)
{
return ERROR; //判断合法性
}
*e = L.elem[i-1]; //试想一下返回第一个 那么就是第[0]个元素。所以要-1
return OK;
}比较两个元素是否相等(compare)
/*
* 比较两个元素是否相等 前小返回-1 前大返回1 相等返回0
*/
Status compare(Elemtype e1, Elemtype e2)
{
if (e1 == e2)
{
return 0;
}
else if (e1 < e2)
{
return -1;
}
else
{
return 1;
}
}查找元素(FindElem)
/*
* 查找元素
*/
Status FindElem(const SqList L, Elemtype e, Status (*compare)(Elemtype, Elemtype))
{
int i;
for (i = 0; i < L.length; i++)
{
if (!(*compare)(L.elem[i], e))
{
return i + 1;
}
}
if (i >= L.length)
{
return ERROR;
}
}查找前驱元素(PreElem)
/*
* 查找前驱元素
*/
Status PreElem(const SqList L, Elemtype cur_e, Elemtype *pre_e)
{
int i;
for (i = 0; i < L.length; i++)//遍历每个元素
{
if (cur_e == L.elem[i]) //比较当前元素是否与想找的相等
{
if (i != 0) //看看是否是第一个元素
{
*pre_e = L.elem[i - 1]; //如果不是第一个,返回前驱
}
else //如果是第一个元素那么没有前驱
{
return ERROR;
}
}
}
if (i >= L.length)//如果遍历结束后还没有发现这个元素,那么ERROR
//这里注意,没有此元素和此元素只在首位的返回结果是一样的,都是ERROR
{
return ERROR;
}
}查找后继元素(NextElem)
/*
* 查找后继元素
*/
Status NextElem(const SqList L, Elemtype cur_e, Elemtype *next_e)
{
int i;
for (i = 0; i < L.length; i++)
{
if (cur_e == L.elem[i])
{
if (i < L.length - 1)
{
*next_e = L.elem[i + 1];
return OK;
}
else
{
return ERROR;
}
}
}
if (i >= L.length)
{
return ERROR;
}
}插入元素(InsertElem)
/*
* 插入元素
*/
Status InsertElem(SqList *L, int i, Elemtype e)
{
Elemtype *new;
if (i < 1 || i > L->length + 1) //当i不在范围内时
{
return ERROR;
}
if (L->length >= L->size)
{
new = (Elemtype*) realloc(L->elem, (L->size + INCREMENT_SIZE) * sizeof(Elemtype));
if (!new)
{
return ERROR;
}
L->elem = new;
L->size += INCREMENT_SIZE;
}
Elemtype *p = &L->elem[i - 1];
Elemtype *q = &L->elem[L->length - 1];
for (; q >= p; q--)
{
*(q + 1) = *q;
}
*p = e;
++L->length;
return OK;
}删除元素并返回其值(DeleteElem)
/*
* 删除元素并返回其值
*/
Status DeleteElem(SqList *L, int i, Elemtype *e)
{
if (i < 1 || i > L->length)
{
return ERROR;
}
Elemtype *p = &L->elem[i - 1];
*e = *p;
for (; p < &L->elem[L->length]; p++)
{
*(p) = *(p + 1);
}
--L->length;
return OK;
}访问元素(visit)
/*
* 访问元素
*/
void visit(Elemtype e)
{
printf("%d ", e);
}遍历线性表(TraverseList)
/*
* 遍历线性表
*/
Status TraverseList(const SqList L, void (*visit)(Elemtype))
{
int i;
for(i = 0; i < L.length; i++)
{
visit(L.elem[i]);
}
return OK;
}线性表顺序存储结构的优缺点
| 优点 | 缺点 |
|---|---|
| 无须为表示表中元素之间的逻辑关系而增加额外的存储空间 | 插入和删除操作需要移动大量元素 |
| 可以快速地存取表中任意位置的元素 | 当线性表长度变化较大时,难以确定存储空间的容量 |
| 容易造成存储空间的“碎片” |
线性表的链式存储结构
线性表的链式存储结构的特点是用一组任意的存储单元存储线性表的数据元素(这组存储单元可以是连续的,也可以是不连续的)。因此,为了表示每个数据元素ai与其直接后继数据元素ai+1至今啊的逻辑关系,对数据元素ai来说,除了存储其本身的信息之外,还需存储一个只是其直接后继的信息(即直接后继的存储位置)。这两部分信息组成数据元素ai的存储映像,成为结点(node)。它包括两个域:其中存储数据元素信息的域成为数据域;存储直接后继存储位置的域成为指针域。指针域中存储的信息称作指针或链。
我们为了更加方便地对链表进行操作。会在单链表的id一个结点前附设一个结点,成为头结点
我们把链表中第一个结点的存储位置叫做头指针
头指针和头结点的异同
- 头指针
- 头指针是指链表指向第一个结点的指针,若链表有头节点,则是指向头结点的指针
- 投指针具有标识作用,所以常用头指针冠以链表的名字
- 无论链表是否为空,头指针均不为空。头指针是链表的必要元素
- 头结点是为了操作的统一和方便而设立的,放在第一元素的结点之前,其数据域一般无意义(也可以存放链表的长度)
- 有了头结点,对在第一元素结点前插入结点和删除第一结点,其操作与其它结点的操作就统一了
- 头结点不一定是链表必须要素
注:结点由存放数据元素的数据域和存放后继结点地址的指针域组成
单链表的表示和实现
#include 初始化一个空的线性表(InitList)
/*
* 初始化线性表
*/
void InitList(LinkList *L)
{
*L = (LinkList) malloc(sizeof(LNode));
if (!L)
{
exit(OVERFLOW);
}
(*L)->next = NULL;
}销毁线性表(DestroyList)
/*
* 销毁线性表
*/
void DestroyList(LinkList *L)
{
LinkList temp;
while (*L) //这个要一个个销毁
{
temp = (*L)->next;
free(*L);
*L = temp;
}
}清空线性表(ClearList)
/*
* 清空线性表
*/
void ClearList(LinkList L)
{
LinkList p = L->next;
L->next = NULL;
DestroyList(&p); //要用到上面的销毁,
//那么这里有个问题,销毁线性表和清空线性表有啥区别?
}判断是否为空(isEmpty)
/*
* 判断是否为空
*/
Status isEmpty(LinkList L)
{
if (L->next)
{
return FALSE;
}
else
{
return TRUE;
}
}获取长度(GetLength)
/*
* 获取长度
*/
int GetLength(LinkList L)
{
int i = 0;
LinkList p = L->next;
while (p)
{
i++;
p = p->next; //要用到计数器
}
return i;
}根据位置获取元素(GetElem)
/*
* 根据位置获取元素
*/
Status GetElem(LinkList L, int i, ElemType *e)
{
int j = 1;
LinkList p = L->next;
while (p && j < i)
{
j++;
p = p->next;
}
if (!p || j > i)
{
return ERROR;
}
*e = p->data;
return OK;
}比较两个元素是否相等(compare)
/*
* 比较两个元素是否相等
*/
Status compare(ElemType e1, ElemType e2)
{
if (e1 == e2)
{
return 0;
}
else if (e1 < e2) //这个和前面一样
{
return -1;
}
else
{
return 1;
}
}查找指定元素的位置(FindElem)
/*
* 查找指定元素的位置
*/
int FindElem(LinkList L, ElemType e, Status (*compare)(ElemType, ElemType))
{
int i = 0;
LinkList p = L->next;
while (p)
{
i++;
if (!compare(p->data, e)) //遍历到为止
{
return i;
}
p = p->next;
}
return 0;
}获取前驱元素(PreElem)
/*
* 获取前驱元素
*/
Status PreElem(LinkList L, ElemType cur_e, ElemType *pre_e)
{
LinkList q, p = L->next;
while (p->next)
{
q = p->next;
if (q->data == cur_e)
{
*pre_e = p->data;
return OK;
}
p = q;
}
return ERROR;
}获取后继元素(NextElem)
/*
* 获取后继元素
*/
Status NextElem(LinkList L, ElemType cur_e, ElemType *next_e)
{
LinkList p = L->next;
while (p->next)
{
if (p->data == cur_e)
{
*next_e = p->next->data;
return OK;
}
p = p->next;
}
return ERROR;
}插入元素(InsertElem)
/*
* 插入元素
*/
Status InsertElem(LinkList L, int i, ElemType e)
{
int j = 0;
LinkList s, p = L;
while (p && j < i - 1)
{
j++;
p = p->next;
}
if (!p || j > i - 1)
{
return ERROR;
}
s = (LinkList) malloc(sizeof(LNode));
s->data = e;
s->next = p->next;
p->next = s;
return OK;
}删除元素并返回值(DeleteElem)
/*
* 删除元素并返回值
*/
Status DeleteElem(LinkList L, int i, ElemType *e)
{
int j = 0;
LinkList q, p = L;
while (p->next && j < i - 1)
{
j++;
p = p->next;
}
if (!p->next || j > i - 1)
{
return ERROR;
}
q = p->next;
p->next = q->next;
*e = q->data;
free(q);
return OK;
}访问元素(visit)
/*
* 访问元素
*/
void visit(ElemType e)
{
printf("%d ", e);
}遍历线性表(TraverseList)
/*
* 遍历线性表
*/
void TraverseList(LinkList L, void (*visit)(ElemType))
{
LinkList p = L->next;
while (p)
{
visit(p->data);
p = p->next;
}
}
单链表结构与顺序存储结构的优缺点对比
- 存储分配方式
- 顺序存储结构用一段连续的存储单元一次存储线性表的数据元素
- 单链表采用链式存储结构,用一组任意的存储单元存放线性表的元素
- 时间性能
- 查找
- 顺序存储结构O(1)
- 单链表O(n)
- 插入和删除
- 顺序存储结构需要平均移动表长一般的元素,时间为O(n)
- 单链表在线出某位置的指针后,插入和删除时间仅为O(1)
- 查找
- 空间性能
- 顺序存储结构需要预分配存储空间,分大了浪费,分笑了容易发生溢出
- 单链表不需要分配存储空间,只要有就可以分配,元素个数也不受限制。
静态链表
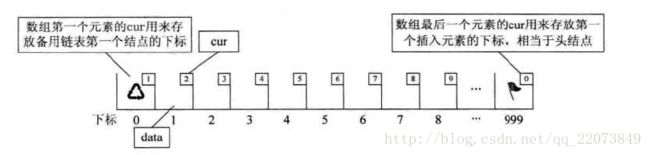
用数组描述的链表叫做静态链表 注:此处参考《大话数据结构 》
(另外在这里吐槽一下csdn的编辑器,注脚总是用不了。。)
我们对数组第一个和最后一个元素作为特殊元素处理,不存数据。我们通常把违背是用的数组元素成为备用链表,而数组第一个元素,即下表为0的元素的cur就存放第一个结点的下表;而数组的最后一个元素的cur则存放第一个有数值的元素的下表,相当于单链表中的头结点的作用。
静态链表的初始化
/*——————————将一维数组space中各分量链成一备用链表——————————*/
/*——————————space[0].cur为头指针,“0”表示空指针——————————*/
Status InitList(StaticLinkList space)
{
int i;
for( i=0; i < MAXSIZE-1; i++ )
space[i].cur = i + 1;
space[MAXSIZE-1].cur = 0; //目前静态链表为空,最后一个元素的cur为0
return OK;
} 

静态链表的插入操作
静态链表中要解决的是:如何用静态模拟动态链表结构的存储空间的分配,需要时申请,无用时释放
我们前面说过,在动态链表中,结点的申请和释放分别借用 malloc() 和 free() 两个函数来实现。在静态链表中,操作的是数组,不存在像动态链表的结点申请和释放问题,所以我们需要自己实现这两个函数,才可以做插入和删除的操作。
为了辨明数组中哪些分量未被使用,解决的办法是将所有未被使用过的以及已被删除的分量用游标链成一个备用的链表,每当进行插入时,便可以从备份链表上取得第一个结点作为待插入的新结点。
//若备用空间链表非空,则返回分配的结点下标,否则返回0
int Malloc_SLL(StaticLinkList space)
{
int i = space[0].cur; //当前数组第一个元素的cur存的值
//就是要返回的第一个备用空闲的下标
if(space[0].cur)
space[0].cur = space[i].cur //由于要拿出一个分量来使用了,
//所以我们就得把它的下一个分量用来做备用
return i ;
}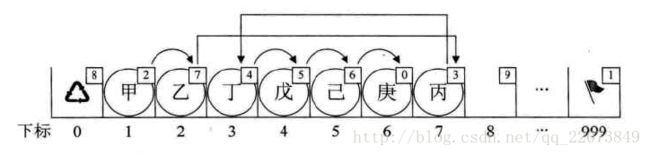
下面举个例子,现在我们如果需要在“乙”和“丁”之间,插入一个值为“丙”的元素,按照以前顺序存储结构的做法,应该要把“丁”“戊”“己”“庚”这些元素都往后移动了以为。但目前不需要,因为我们有了新手段。
新元素“丙”想插队是吧,可以,你先悄悄地在队伍最后一排第7个油表位置待着,我一会就能帮你搞定。我接着找到了“乙”,告诉他,你的 cur 不是游标为3的“丁”了,这点小钱,意思意思,你把你的下一位的游标改为7就可以了。“乙”叹了口气,收了钱把 cur 值改了。此时再回到“丙”那里,说你把你的 cur 改为3.就这样,在绝大多数人都不知道的情况下,整个排队的次序发生了改变。
//在L 中第 i 个元素之前插入新的数据元素e
Status ListInsert(StaticLinkList L, int i, ElemType e)
{
int j, k, l;
k = MAX_SIZE -1 ; //注意K 首先是最后一个元素的下标
if (i<1 || i > ListLength(L) + 1)
return ERROR;
j = Malloc_SSL(L); //获得空闲分量的下标
if (j)
{
L[j].data = e ; // 将数据赋值给此分量的data
for (l=1; l<= i -1 ; l++)//找到第i个元素之前的位置
k = L[k].cur;
L[j].cur = L[k].cur;//把第i个元素之前的cur赋值给新元素的cur
L[k].cur = j; //把新元素的下表赋值给第 i 个元素之前元素的cur
return OK;
}
return ERROR;
}
静态链表的删除操作
以前释放结点要用函数free() 现在也得自己实现
//将下标为k的空闲结点回收到备用链表
void Free_SSL(StaticLinkList space, int k)
{
space[k].cur = space[0].cur//
sapce[0].cur = k;
}
//删除再 L 中第 i 个数据元素 e
Status ListDelete(StaticLinkList L, int i)
{
int j,k;
if(i < 1 || i > ListLength(L))
return ERROR;
k = MAX_SIZE -1 ;
for(j=1; j <= i-1; j++)
k = L[k].cur;
j = L[k].cur;
L[k].cur = L[j].cur;
Free_SSL(L,j);
return OK;
}有了刚才的基础,这段代码就很容易理解了。前面代码都一样,for循环因为i=1而不操作, j=k[999].cur =1 , L[k].cur = L[j].cur 也就是L[999].cur = L[1].cur =2.这其实就是告诉计算机现在“甲”已经离开了,“乙”才是第一个元素。
意思就是“甲”现在要走,这个位置空出来了,也就是,未来如果有新人来,最优先考虑这里,所以原来的第一个空位分量,即下表是8 的分量,它降级了,把8给“甲”所在下表为1 的分量的cur ,也就是space[i].cur = space[0].cur =8,而 space[0].cur=k=1 其实就是让这个删除的位置成为第一个优先空位,把它存入第一个元素的cur中

静态链表的优缺点
| 优点 | 缺点 |
|---|---|
| 在插入和删除操作时,只需要修改游标,不需要移动元素,从而改进了在顺序存储结构中的插入和删除操作需要移动大量元素的缺点 | 1.没有解决连续存储分配带来的表长难以确定的问题, 2.失去了顺序存储结构随机存取的特性 |
循环链表和双向链表
循环链表
将单链表中终端节点的指针端由控制帧改为指向头结点,就使整个单链表形成一个环,这种头尾相接的单链表称为单循环链表,简称循环链表(circular linked list)
循环链表和单链表的主要差异就是在于循环的判断条件上,原来是判断 p->next 是否为空,现在则是 p->next 不等于头结点,则循环未结束。
双向链表
双向链表(double linked list)是在单链表的每个结点中,再设置一个指向其前驱结点的指针域。所以在双向链表中的结点都有两个指针域,一个指向直接后继,林一个指向直接前驱。
双向链表对于单链表来说,更要复杂一些,毕竟它多了prior指针,对于插入和删除时,需要格外小心。另外它由于每个结点都需要记录两份指针,所以在空间上是要占用略多一些。不过它良好的对称性,使得对某个结点的前后结点的操作,带来的方便,可以有效条算法的时间性能。
说白了,就是用空间来换时间