Linux网络编程:自己动手写高性能HTTP服务器框架(三)
github:https://github.com/froghui/yolanda
buffer对象
buffer,顾名思义,就是一个缓冲区对象,缓存了从套接字接收来的数据以及需要发往套接字的数据。
如果是从套接字接收来的数据,事件处理回调函数在不断地往 buffer 对象增加数据,同时,应用程序需要不断把 buffer 对象中的数据处理掉,这样,buffer 对象才可以空出新的位置容纳更多的数据。
如果是发往套接字的数据,应用程序不断地往 buffer 对象增加数据,同时,事件处理回调函数不断调用套接字上的发送函数将数据发送出去,减少 buffer 对象中的写入数据。
可见,buffer 对象是同时可以作为输入缓冲(input buffer)和输出缓冲(output buffer)两个方向使用的,只不过,在两种情形下,写入和读出的对象是有区别的。
下面展示了 buffer 对象的设计:

//数据缓冲区
struct buffer {
char *data; //实际缓冲
int readIndex; //缓冲读取位置
int writeIndex; //缓冲写入位置
int total_size; //总大小
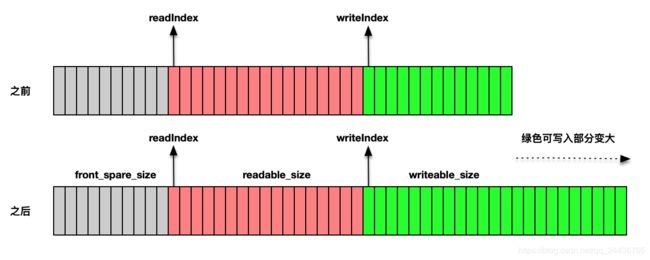
};buffer 对象中的 writeIndex 标识了当前可以写入的位置;readIndex 标识了当前可以读出的数据位置,图中红色部分从 readIndex 到 writeIndex 的区域是需要读出数据的部分,而绿色部分从 writeIndex 到缓存的最尾端则是可以写出的部分。
随着时间的推移,当 readIndex 和 writeIndex 越来越靠近缓冲的尾端时,前面部分的 front_space_size 区域变得会很大,而这个区域的数据已经是旧数据,在这个时候,就需要调整一下整个 buffer 对象的结构,把红色部分往左侧移动,与此同时,绿色部分也会往左侧移动,整个缓冲区的可写部分就会变多了。
make_room 函数就是起这个作用的,如果右边绿色的连续空间不足以容纳新的数据,而最左边灰色部分加上右边绿色部分一起可以容纳下新数据,就会触发这样的移动拷贝,最终红色部分占据了最左边,绿色部分占据了右边,右边绿色的部分成为一个连续的可写入空间,就可以容纳下新的数据。下面的一张图解释了这个过程。

void make_room(struct buffer *buffer, int size) {
if (buffer_writeable_size(buffer) >= size) {
return;
}
//如果front_spare和writeable的大小加起来可以容纳数据,则把可读数据往前面拷贝
if (buffer_front_spare_size(buffer) + buffer_writeable_size(buffer) >= size) {
int readable = buffer_readable_size(buffer);
int i;
for (i = 0; i < readable; i++) {
memcpy(buffer->data + i, buffer->data + buffer->readIndex + i, 1);
}
buffer->readIndex = 0;
buffer->writeIndex = readable;
} else {
//扩大缓冲区
void *tmp = realloc(buffer->data, buffer->total_size + size);
if (tmp == NULL) {
return;
}
buffer->data = tmp;
buffer->total_size += size;
}
}当然,如果红色部分占据过大,可写部分不够,会触发缓冲区的扩大操作。这里我通过调用 realloc 函数来完成缓冲区的扩容。
TCP字节流处理
- 接收数据
套接字接收数据是在 tcp_connection.c 中的 handle_read 来完成的。在这个函数里,通过调用 buffer_socket_read 函数接收来自套接字的数据流,并将其缓冲到 buffer 对象中。之后你可以看到,我们将 buffer 对象和 tcp_connection 对象传递给应用程序真正的处理函数 messageCallBack 来进行报文的解析工作。这部分的样例在 HTTP 报文解析中会展开。
int handle_read(void *data) {
struct tcp_connection *tcpConnection = (struct tcp_connection *) data;
struct buffer *input_buffer = tcpConnection->input_buffer;
struct channel *channel = tcpConnection->channel;
if (buffer_socket_read(input_buffer, channel->fd) > 0) {
//应用程序真正读取Buffer里的数据
if (tcpConnection->messageCallBack != NULL) {
tcpConnection->messageCallBack(input_buffer, tcpConnection);
}
} else {
handle_connection_closed(tcpConnection);
}
}在 buffer_socket_read 函数里,调用 readv 往两个缓冲区写入数据,一个是 buffer 对象,另外一个是这里的 additional_buffer,之所以这样做,是担心 buffer 对象没办法容纳下来自套接字的数据流,而且也没有办法触发 buffer 对象的扩容操作。通过使用额外的缓冲,一旦判断出从套接字读取的数据超过了 buffer 对象里的实际最大可写大小,就可以触发 buffer 对象的扩容操作,这里 buffer_append 函数会调用前面介绍的 make_room 函数,完成 buffer 对象的扩容。
int buffer_socket_read(struct buffer *buffer, int fd) {
char additional_buffer[INIT_BUFFER_SIZE];
struct iovec vec[2];
int max_writable = buffer_writeable_size(buffer);
vec[0].iov_base = buffer->data + buffer->writeIndex;
vec[0].iov_len = max_writable;
vec[1].iov_base = additional_buffer;
vec[1].iov_len = sizeof(additional_buffer);
int result = readv(fd, vec, 2);
if (result < 0) {
return -1;
} else if (result <= max_writable) {
buffer->writeIndex += result;
} else {
buffer->writeIndex = buffer->total_size;
buffer_append(buffer, additional_buffer, result - max_writable);
}
return result;
}- 发送数据
当应用程序需要往套接字发送数据时,即完成了 read-decode-compute-encode 过程后,通过往 buffer 对象里写入 encode 以后的数据,调用 tcp_connection_send_buffer,将 buffer 里的数据通过套接字缓冲区发送出去。
int tcp_connection_send_buffer(struct tcp_connection *tcpConnection, struct buffer *buffer) {
int size = buffer_readable_size(buffer);
int result = tcp_connection_send_data(tcpConnection, buffer->data + buffer->readIndex, size);
buffer->readIndex += size;
return result;
}如果发现当前 channel 没有注册 WRITE 事件,并且当前 tcp_connection 对应的发送缓冲无数据需要发送,就直接调用 write 函数将数据发送出去。如果这一次发送不完,就将剩余需要发送的数据拷贝到当前 tcp_connection 对应的发送缓冲区中,并向 event_loop 注册 WRITE 事件。这样数据就由框架接管,应用程序释放这部分数据。
//应用层调用入口
int tcp_connection_send_data(struct tcp_connection *tcpConnection, void *data, int size) {
size_t nwrited = 0;
size_t nleft = size;
int fault = 0;
struct channel *channel = tcpConnection->channel;
struct buffer *output_buffer = tcpConnection->output_buffer;
//先往套接字尝试发送数据
if (!channel_write_event_registered(channel) && buffer_readable_size(output_buffer) == 0) {
nwrited = write(channel->fd, data, size);
if (nwrited >= 0) {
nleft = nleft - nwrited;
} else {
nwrited = 0;
if (errno != EWOULDBLOCK) {
if (errno == EPIPE || errno == ECONNRESET) {
fault = 1;
}
}
}
}
if (!fault && nleft > 0) {
//拷贝到Buffer中,Buffer的数据由框架接管
buffer_append(output_buffer, data + nwrited, nleft);
if (!channel_write_event_registered(channel)) {
channel_write_event_add(channel);
}
}
return nwrited;
}HTTP 协议实现
为此,我们首先定义了一个 http_server 结构,这个 http_server 本质上就是一个 TCPServer,只不过暴露给应用程序的回调函数更为简单,只需要看到 http_request 和 http_response 结构。
typedef int (*request_callback)(struct http_request *httpRequest, struct http_response *httpResponse);
struct http_server {
struct TCPserver *tcpServer;
request_callback requestCallback;
};在 http_server 里面,重点是需要完成报文的解析,将解析的报文转化为 http_request 对象,这件事情是通过 http_onMessage 回调函数来完成的。在 http_onMessage 函数里,调用的是 parse_http_request 完成报文解析。
// buffer是框架构建好的,并且已经收到部分数据的情况下
// 注意这里可能没有收到全部数据,所以要处理数据不够的情形
int http_onMessage(struct buffer *input, struct tcp_connection *tcpConnection) {
yolanda_msgx("get message from tcp connection %s", tcpConnection->name);
struct http_request *httpRequest = (struct http_request *) tcpConnection->request;
struct http_server *httpServer = (struct http_server *) tcpConnection->data;
if (parse_http_request(input, httpRequest) == 0) {
char *error_response = "HTTP/1.1 400 Bad Request\r\n\r\n";
tcp_connection_send_data(tcpConnection, error_response, sizeof(error_response));
tcp_connection_shutdown(tcpConnection);
}
//处理完了所有的request数据,接下来进行编码和发送
if (http_request_current_state(httpRequest) == REQUEST_DONE) {
struct http_response *httpResponse = http_response_new();
//httpServer暴露的requestCallback回调
if (httpServer->requestCallback != NULL) {
httpServer->requestCallback(httpRequest, httpResponse);
}
//将httpResponse发送到套接字发送缓冲区中
struct buffer *buffer = buffer_new();
http_response_encode_buffer(httpResponse, buffer);
tcp_connection_send_buffer(tcpConnection, buffer);
if (http_request_close_connection(httpRequest)) {
tcp_connection_shutdown(tcpConnection);
http_request_reset(httpRequest);
}
}
}HTTP 通过设置回车符、换行符做为 HTTP 报文协议的边界:

parse_http_request 的思路就是寻找报文的边界,同时记录下当前解析工作所处的状态。根据解析工作的前后顺序,把报文解析的工作分成 REQUEST_STATUS、REQUEST_HEADERS、REQUEST_BODY 和 REQUEST_DONE 四个阶段,每个阶段解析的方法各有不同。
在解析状态行时,先通过定位 CRLF 回车换行符的位置来圈定状态行,进入状态行解析时,再次通过查找空格字符来作为分隔边界。
在解析头部设置时,也是先通过定位 CRLF 回车换行符的位置来圈定一组 key-value 对,再通过查找冒号字符来作为分隔边界。
最后,如果没有找到冒号字符,说明解析头部的工作完成。
parse_http_request 函数完成了 HTTP 报文解析的四个阶段:
int parse_http_request(struct buffer *input, struct http_request *httpRequest) {
int ok = 1;
while (httpRequest->current_state != REQUEST_DONE) {
if (httpRequest->current_state == REQUEST_STATUS) {
char *crlf = buffer_find_CRLF(input);
if (crlf) {
int request_line_size = process_status_line(input->data + input->readIndex, crlf, httpRequest);
if (request_line_size) {
input->readIndex += request_line_size; // request line size
input->readIndex += 2; //CRLF size
httpRequest->current_state = REQUEST_HEADERS;
}
}
} else if (httpRequest->current_state == REQUEST_HEADERS) {
char *crlf = buffer_find_CRLF(input);
if (crlf) {
/**
* -------:-------
*/
char *start = input->data + input->readIndex;
int request_line_size = crlf - start;
char *colon = memmem(start, request_line_size, ": ", 2);
if (colon != NULL) {
char *key = malloc(colon - start + 1);
strncpy(key, start, colon - start);
key[colon - start] = '\0';
char *value = malloc(crlf - colon - 2 + 1);
strncpy(value, colon + 1, crlf - colon - 2);
value[crlf - colon - 2] = '\0';
http_request_add_header(httpRequest, key, value);
input->readIndex += request_line_size; //request line size
input->readIndex += 2; //CRLF size
} else {
//读到这里说明:没找到,就说明这个是最后一行
input->readIndex += 2; //CRLF size
httpRequest->current_state = REQUEST_DONE;
}
}
}
}
return ok;
} 处理完了所有的 request 数据,接下来进行编码和发送的工作。为此,创建了一个 http_response 对象,并调用了应用程序提供的编码函数 requestCallback,接下来,创建了一个 buffer 对象,函数 http_response_encode_buffer 用来将 http_response 中的数据,根据 HTTP 协议转换为对应的字节流。
可以看到,http_response_encode_buffer 设置了如 Content-Length 等 http_response 头部,以及 http_response 的 body 部分数据。
void http_response_encode_buffer(struct http_response *httpResponse, struct buffer *output) {
char buf[32];
snprintf(buf, sizeof buf, "HTTP/1.1 %d ", httpResponse->statusCode);
buffer_append_string(output, buf);
buffer_append_string(output, httpResponse->statusMessage);
buffer_append_string(output, "\r\n");
if (httpResponse->keep_connected) {
buffer_append_string(output, "Connection: close\r\n");
} else {
snprintf(buf, sizeof buf, "Content-Length: %zd\r\n", strlen(httpResponse->body));
buffer_append_string(output, buf);
buffer_append_string(output, "Connection: Keep-Alive\r\n");
}
if (httpResponse->response_headers != NULL && httpResponse->response_headers_number > 0) {
for (int i = 0; i < httpResponse->response_headers_number; i++) {
buffer_append_string(output, httpResponse->response_headers[i].key);
buffer_append_string(output, ": ");
buffer_append_string(output, httpResponse->response_headers[i].value);
buffer_append_string(output, "\r\n");
}
}
buffer_append_string(output, "\r\n");
buffer_append_string(output, httpResponse->body);
}完整的 HTTP 服务器例子
现在,编写一个 HTTP 服务器例子就变得非常简单。在这个例子中,最主要的部分是 onRequest callback 函数,这里,onRequest 方法已经在 parse_http_request 之后,可以根据不同的 http_request 的信息,进行计算和处理。例子程序里的逻辑非常简单,根据 http request 的 URL path,返回了不同的 http_response 类型。比如,当请求为根目录时,返回的是 200 和 HTML 格式。
#include
#include
#include "lib/common.h"
#include "lib/event_loop.h"
//数据读到buffer之后的callback
int onRequest(struct http_request *httpRequest, struct http_response *httpResponse) {
char *url = httpRequest->url;
char *question = memmem(url, strlen(url), "?", 1);
char *path = NULL;
if (question != NULL) {
path = malloc(question - url);
strncpy(path, url, question - url);
} else {
path = malloc(strlen(url));
strncpy(path, url, strlen(url));
}
if (strcmp(path, "/") == 0) {
httpResponse->statusCode = OK;
httpResponse->statusMessage = "OK";
httpResponse->contentType = "text/html";
httpResponse->body = "This is network programming Hello, network programming
";
} else if (strcmp(path, "/network") == 0) {
httpResponse->statusCode = OK;
httpResponse->statusMessage = "OK";
httpResponse->contentType = "text/plain";
httpResponse->body = "hello, network programming";
} else {
httpResponse->statusCode = NotFound;
httpResponse->statusMessage = "Not Found";
httpResponse->keep_connected = 1;
}
return 0;
}
int main(int c, char **v) {
//主线程event_loop
struct event_loop *eventLoop = event_loop_init();
//初始tcp_server,可以指定线程数目,如果线程是0,就是在这个线程里acceptor+i/o;如果是1,有一个I/O线程
//tcp_server自己带一个event_loop
struct http_server *httpServer = http_server_new(eventLoop, SERV_PORT, onRequest, 2);
http_server_start(httpServer);
// main thread for acceptor
event_loop_run(eventLoop);
} 运行这个程序之后,我们可以通过浏览器和 curl 命令来访问它。你可以同时开启多个浏览器和 curl 命令,这也证明了我们的程序是可以满足高并发需求的。
$curl -v http://127.0.0.1:43211/
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to 127.0.0.1 (127.0.0.1) port 43211 (#0)
> GET / HTTP/1.1
> Host: 127.0.0.1:43211
> User-Agent: curl/7.54.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Content-Length: 116
< Connection: Keep-Alive
<
* Connection #0 to host 127.0.0.1 left intact
This is network programming Hello, network programming
% 
这一讲我们主要讲述了整个编程框架的字节流处理能力,引入了 buffer 对象,并在此基础上通过增加 HTTP 的特性,包括 http_server、http_request、http_response,完成了 HTTP 高性能服务器的编写。实例程序利用框架提供的能力,编写了一个简单的 HTTP 服务器程序。
温故而知新 !