【Linux网络编程二】网络基础2(网络框架)
【Linux网络编程二】网络基础2(网络框架)
- 一.数据如何跨网络传输
-
- 1.源ip和目的ip
- 2.路由器的使命
- 3.Mac地址的使命
- 二.网络通信的本质
- 三.端口号
-
- 1.存在意义
- 2.实现原理
- 四.认识协议
-
- 1.TCP协议
- 2.UDP协议
- 五.网络字节序
- 六.通用网络接口
一.数据如何跨网络传输
在上一篇网络基础中,理解了在局域网下两台主机是如何通信,进行数据的传输的。
在同一个局域网下,两台主机是可以直接通信的,那么如果在不同的局域网下,两台主机该如何通信呢?也就是在跨网络情况下,数据是如何传输的呢?
1.前提知识①:跨网络的主机之间的文件传输,数据从一台计算机到另一台计算机传输的过程中,必须要经过一个或多个路由器!
2.也就是要将数据发送给其他局域网下的一台主机,需要先将数据传输给路由器。再由路由器转发给另一台主机。原因:因为另一台主机的ip地址不是属于当前局域网,是其他子网的,所以必须通过路由器。
3.前提知识②:路由器也是当前局域网下的一台主机,普通机子。
4.所以把数据交给路由器,本质也是在局域网下通信!
因为路由器就是局域网下的一台主机。


网络通信核心就是贯穿协议栈,数据从应用层封装报头到达传输层,再封装到达网络层,在该层,封装的报头里会存储目的本机ip地址和目的ip地址,最后封装报头到达数据链路层,然后通过以太网发送到网络中。在该局域网下的所有主机都会接收到消息,但只有路由器能接收到。
因为在该层会分析报文里的目的ip是否是子网内的,如果不是子网内部的,就需要跨网络。就将数据传给路由器。
因为路由器就是一台主机,它是位于网络层的,所以它底层也具有数据链路层,可以接收其他主机发送的消息。
所以在数据链路层会分离报头,解析报文,根据报文里的目的ip是否需要跨网络,来决定传递的是对端主机还是路由器。如果目的ip是本子网内的那么是发送给对端主机,如果不是本子网的ip那么就是发送给路由器。
路由器在网络层就接收到了报文,并且检测到报头里的目的ip,发现是发送给C局域网里的一台主机,所有它就将报文往下交付,重新封装C域网里的协议报头。
然后属于C局域网的目的主机在数据链路层就会接收到报文。分离报头,解析报文,发现是发送给自己的,就会将有效载荷往上层发送,最后发送给上层应用。
注意,不同局域网中,底层的协议可能是不一样的,比如A局域网在数据链路层使用的是以太网协议,而C局域网在数据链路层使用的是令牌环网。但在跨网络通信中,是不影响的。因为路由器帮它们做了转换。
1.源ip和目的ip

ip地址可以标识一台主机的唯一性,所以通过ip地址就可以定位到主机位置,所以两个ip地址就可以形成一个路径,一个为源ip地址,一个为目的ip地址。
2.路由器的使命

所以路由器可以屏蔽底层网络的差异化,不管底层网络采用的是什么类型的协议都可以实现通信,因为它会帮我们重新封装报头。
3.Mac地址的使命

认识MAC地址
MAC地址用来识别数据链路层中相连的节点;
长度为48位, 及6个字节. 一般用16进制数字加上冒号的形式来表示(例如: 08:00:27:03:fb:19)
在网卡出厂时就确定了, 不能修改. mac地址通常是唯一的(虚拟机中的mac地址不是真实的mac地址, 可
能会冲突; 也有些网卡支持用户配置mac地址).
二.网络通信的本质

网络通信时,到底是谁在通信?是双方的主机在进行通信吗?
并不是!而是双方主机上的应用层的各自应用在通信。
而各自的应用都是由进程控制的,也就是要使用应用层软件,需要先启动这些软件,也就是启动进程。

所以网络通信的本质就是进程间通信!
而进程间通信需要看到同一份资源,这份资源是什么呢?
它就是网络!让不同的主机看到相同的资源。每台主机都可以使用网络。

三.端口号

端口号是标识一台主机应用层上的各种应用的,而每一个应用本质就是进程,所以端口号是用来标识应用层上的各种进程的。
一旦知道端口号后,就知道要将数据发给哪个应用(进程)。
所以在传输层封装报头时,会将发送方进程的端口号和接收方进程的端口号存储,这样在对端主机的传输层就知道要将有效载荷发送给哪个进程。并且对端主机也知道是本主机哪个进程发送给它的。
1.存在意义

网络通信本质就是进程通信,而进程通信,你首先需要知道是哪两个进程在通信,如何找到这两个进程呢?
因为ip地址可以标识唯一的主机,而端口号可以标识一台主机上的唯一应用进程。所以通信进程=ip+port;
所以ip+port这种方式就可以标识全网唯一的一个进程。
这种方式被称为socket(套接字)
所以只有知道进程的ip和端口号。才可以进行通信。
所以在封装报头时,会将对方进程的ip和port和自己的ip和por存储在报头里。这样就可以找到对方的进程。也可以让对方的进程找到我自己。
【存在疑惑】为什么用端口号来唯一标识进程?每一个进程不是有pid吗?它不也是唯一标识进程的吗,为什么不适应pid来标识?

2.实现原理
每一个进程在网络通信之前,都需要绑定一个端口号。
这个端口号是能够唯一标识该进程的。
绑定端口号的本质:就是随机生成一个端口号,或者你设置一个数字,经过哈希运算,放入哈希表里,如果哈希表里存在元素,则绑定失败,需要重新绑定别的端口号。如果哈希表里没有元素,就将该进程的pid存放进去,通过pid就可以找到进程。
所以在我们的应用层,进程想要通信需要先绑定端口号,而进程绑定端口号,就是将进程的pid绑定到哈希表里。

当对端主机的传输层接收到一个报文,就会根据该报文里的目的端口号,进行哈希运算,找到哈希表里的进程,就找到了应用。
补充:


四.认识协议
TCP和UDP都是属于传输层的协议,是将在传输层的数据发送给上层应用。或者接收上层应用发送来的数据。
![]()
1.TCP协议

2.UDP协议

TCP相比较UDP是可靠的,但这不是说UDP传输不可靠,最好不要使用UDP等。可靠是相对的而言的,传输过程中肯定会存在丢失情况。而TCP是花了大代价建立管道,才保证了可靠传输的,所以维护成本要比UDP高的多,而UDP维护成本低,使用简单。

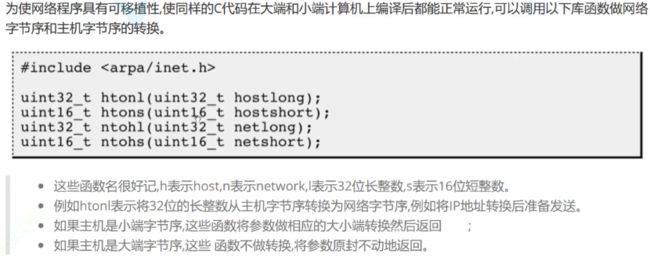
五.网络字节序
因为不同的主机上存在着大端存储和小段存储两种存储序列。网络通信我们要求统一序列,这样才能正常通信,不然一台主机是大端机器,一台主机是小段机器,那么注定一台机器发送的消息,另一台机器是看不懂的或者不准确的。
所以数据在网络中传输时,要求是按照统一的字节序,在传输层TCP/IP协议中就规定,网络数据流全部采用的是大端字节序。
不管主机是大端机还是小端机,都要使用大端字节序来网络传输,如果是大端机那么可以直接传输,如果是小端机,需要先转换成大端字节序才可以进行传输。
在网络中传输的数据都需要按照网络字节序来进行传输。

而系统也为我们提供了一系列便捷的系统调用接口来转换字节序列。
可以让主机序列转换成网络序列,也可以让网络序列转换成主机序列。
六.通用网络接口
网络编程的种类具有多种,分为域间套接字编程,原始套接字编程,网络套接字编程,三种套接字编程。
域间套接字编程是用于同一台机器上的网络通信。
原始套接字编程主要用户网络工具。
网络套接字编程才是用于用户简单网络通信。

系统想让网络接口统一抽象化。这就要求这个网络接口的参数类型必须是统一的。
这几种套接字结构体对开头都是16位地址,这个地址就是代表着你是什么类型的编程,AF_INET就代表是网络通信,AF_UNIX就代表是域间通信,所以我们就可以封装一个统一的结构体对象,这个结构体对象开头也是16位地址,用来判断是什么类型的套接字编程。
所以系统就封装了一个统一的函数接口,该接口需要的是一个统一的结构体对象,通过判断该结构体对象的前16位地址来判断是什么类型的编程。然后直接就使用该类型的套接字编程。


虽然使用的是统一接口,参数都要求是sockaddr结构类型,但是你要使用什么类型套接字,还是定义该类型的结构体对象,在调用接口时,只需要强转成统一接口的指针类型即可。