一直在思考写一些什么东西作为2017年开篇博客。突然看到一篇《Kafka学习之路》的博文,觉得十分应景,于是决定搬来这“他山之石”。虽然对于Kafka博客我一向坚持原创,不过这篇来自Confluent团队Gwen Shapira女士的博文实在精彩,所以还是翻译给大家,原文参见这里。
~~~~~~~~~~~~
Kafka学习之路
看上去很多工程师都已经把“学习Kafka”加到了2017年的to-do列表中。这没什么惊讶的,毕竟Apache Kafka已经是一个很火的框架了。只需了解一些基本的Kafka技能我们便可以把消息队列应用到实际的业务系统中,集成应用程序和数据存储,构建流式处理系统并且着手搭建高伸缩性高容错性的微服务架构。所有的这些只需要学习Kafka这一个框架就足够了, 听起来还不错吧? 这篇报道中Kafka上榜当选了当前最需要掌握的十大大数据技能之一(译者:好吧, 这么吹我都有点受不了了,这篇报道中提到的技能几乎都是Amazon的,很难让人相信这不是Amazon的软文),所以如果你想在自己的领域内出人头地,Kafka值得一试!

好了,那么该如何开始学习Apache Kafka呢?一言以蔽之:因人而异!这取决于你的职业特点。学习Kafka可能有很多种方式,稍后我会详细向你介绍,不过这些方法都有相通的部分,所以让我们先从这些地方开始吧:
第一步就是要下载Kafka。Confluent提供了免费的Confluent下载(译者:Confluent.io是Kafka团队独立出来成立的一个创业公司,该公司开发的Confluent是一个基于kafka的流式处理平台,提供了一些社区版Kafka没有的功能)。Confluent不仅拥有Apache Kafka提供的所有功能,同时还提供了一些额外的开源插件(比如REST proxy,超多种类的Connector和一个schema registry)
Kafka的安装主要就是解压下载的.tar.gz文件。当然你也可以通过RPM或DEB文件的方式进行安装,教程在这里。
Apache Kafka是一个流式数据处理平台,其本质就是一个发布/订阅模式的消息队列,因此在安装之后你可以尝试创建一些话题(topic),然后往话题中生产一些消息,之后再订阅这些话题进行消费。最好的方式就是参照quick start文档——注意,从第二步开始做就好了,第一步的下载我们已经完成了:)
恭喜你! 你已经成功地对Kafka进行了消息的发布与订阅。不过在继续之前,我建议你花一些时间去读一下Kafka的设计文档——这会极大地帮助你理解很多Kafka的术语与核心概念。
okay,你已经可以简单地往kafka发送和消费消息了,不过真实系统中我们可不会这样用。首先,在quick start中我们只配置了一个Kafka服务器(Kafka broker)——生产环境中我们至少要配置3台以实现高可用;其次,教程中使用了命令行工具进行消息的发布与订阅。而实际线上环境通常都要求在业务系统中来做或者是使用connector实现与外部系统的集成。
下面我们就根据每个人的实际情况具体给出学习Kafka的路线图。
~~~我是软件工程师~~~
软件工程师通常都有一门熟练掌握的编程语言,因此作为软件工程师的你第一步就要根据你掌握的编程语言寻找对应的Kafka客户端。Apache Kafka支持的客户端列表在此,赶紧去找一下吧。
挑选合适自己的客户端本身就是一门技术活,有很多注意事项。不过我推荐大家使用这两种客户端:Java客户端和libkafka。这两个客户端支持绝大多数的Kafka协议,也更加的标准化,同时有很好的性能以及可靠性(毕竟经过了大量的测试)。但是,无论你选择了上述列表中的哪个客户端,我们都推荐你要确认它至少是有活跃社区维护的——Kafka版本迭代速度很快,客户端版本更新太慢会导致很多新功能无法使用的。如何判断客户端更新速度呢? 答案就是查看对应的github上面的commit数和issue数,它们通常都可以帮助识别是否有活跃社区在维护它(译者:KafkaOffsetsMonitor更新速度就很慢,似乎到目前为止还不支持对于Kafka保存offset的监控)
一旦确定了要使用的客户端,马上去它的官网上学习一下代码示例(好吧,如果都没有样例,你要重新思考一下它是否合适了?)——确认你能够正确编译和运行这些样例,这样你就有把握能够驾驭该客户端了。下一步你可以稍微修改一下样例代码尝试去理解并使用其他的API,然后观察结果。
这些都做完之后你可以自己编写一个小项目来进行验证了。第一个项目通常都是一个生产者程序(下称producer),比如它负责发送/生产一些整数到一个话题的某个分区(partition)中,然后再写一个消费者程序(下称consumer)来获取这些整数。作为你的第一个项目,它教会了你大多数Kafka API的使用,你一定会印象深刻的。另外客户端的文档通常都是十分齐全的,但如果你仍有疑问而无处解答,那么给邮件组或StackOverflow发问题吧,会有大神回答你的(译者:做个广告,我在StackOverflow的名字是amethystic,通常都会看到你的问题的)。
做完了这些,下面就是要提升客户端的可靠性与性能了。再去复习一遍Kafka的文档吧,确保你真的理解了不同客户端之间那些影响可靠性和性能的参数,然后去做一些实验来巩固你的理解。举个例子,给producer配置acks=0, 重启服务器然后去看看吞吐率有什么变化? 然后再试试acks=1。另外注意一下在重启的过程中是否出现消息丢失?你是否能说清楚为什么(不)会丢失吗?如果acks=-1的话还会有消息丢失吗?这些配置下的性能都是怎么样的?如果你增加batch.size和linger.ms会发生什么? Kafka提供了很多的参数,如果你觉得应接不暇,那么先从“高重要度”(high importance)的那些开始学起吧。
学完了client及其API的使用,也尝试了一些配置修改和样例运行,下面你就可以真正地开始进行Kafka应用的开发了。
如果你使用Java,只需要继续学习高级流式处理API就可以了。这些API不仅生产/消费消息,还能够执行更为高级的流式处理操作(比如时间窗口聚合以及流连接stream joining等)。文档在这里,例子在这里,不用客气 :-)
~~~我是系统管理员/运维工程师~~~
和开发工程师不同,你的目标是学习如何管理Kafka线上生产环境。因此,从一开始你就需要一个真实的Kafka集群环境,即3节点集群(推荐的线上生产环境配置)。
如果不知道怎么搭建请参考上面quick start中提到的第6步:安装多节点集群。你也可以使用Docker来直接配置出多节点Kafka集群(译者:这是Confluent自己制作的镜像,不是目前STAR数最多的那个)。这些镜像都是我们在生产环境中用到的,所以请放心地作为基础镜像来使用~~
有了这个环境,你可以使用quick-start中提到的bin/kafka-topics.sh脚本创建多个分区多个副本(replica)的topic了,去试试吧。
俗话说的好,做好监控生产环境的部署就成功了一半,所以我推荐你及时地做好对于Kafka的监控。Kafka默认提供了超多的JMX监控指标。我们可以用很多种方式对其进行收集,但是你一定要保证Kafka启动时配置了JMX_PORT环境变量(译者:最简单地方式就是修改bin/kafka-server-start.sh脚本)! 不知道你习惯使用什么监控工具,反正我是用JMXTrans和Graphite进行收集和监控的。如果你也使用Graphite,别客气,我的配置你就拿去用吧:) (译者: 我一直使用JConsole来进行监控,其实也挺好的) 总之使用你习惯的工具就好,另外这里列出了一些常用的监控指标,给你做个参考吧~
作为系统运维管理员,下一步你要观察在一定负载情况下你的Kafka的集群表现。Apache Kafka提供了很多命令行工具用于模拟运行负载:bin/kafka-producer-perf-test和bin/kafka-consumer-perf-test。去学习一下这些工具的使用方法吧,在你的系统中模拟一些负载出来然后观察刚才提到的监控指标。比如producer/consumer能够达到的最大吞吐量是多少? 你是否能够找到整个集群的瓶颈所在?
哦,对了,Kafka的日志也不容忽视。默认情况下它们保存在logs/或/var/log下——取决于你的设置了。你需要仔细地查看server.log,保证没有重大的错误。如果不理解出现错误的含义,发信给邮件组或StackOverflow吧。
我们刚刚所做的都是正常的Kafka操作,去搞些异常出来吧! 比如停掉集群中的一台服务器,然后去查看监控指标——你应该可以发现leader数会下降然后恢复,leader选举数攀升而under-replicated分区数也增加了(译者:under-replicated分区指备份不充分的分区,比如正常情况下我设置该分区有3个副本,但实际中只有2个副本,那么此时该分区就是备份不充分的)。你也可以去查看服务器日志(包括你停掉的那台)——日志应该标明了有新的leader选举发生。
我推荐你在调优producer/consumer性能的时候尝试不断地关闭/启动服务器,甚至直接kill -9也行,然后查看日志和监控指标,搞明白这其中到底发生了什么以及系统是怎么恢复整个过程的。
作为系统管理员的最后一个重要的事情就是学习Kafka的管理工具,比如:
- kafka-topics.sh:修改分区数,副本数以及分配新的分区和副本到指定broker上
- kafka-topics.sh:删除topic
- kafka-config.sh:修改topic配置,比如topic日志留存时间
- kafka-consumer-groups.sh:开发人员通常都要求运维人员帮忙查看consumer消费情况(是否滞后太多),那么使用这个脚本去查看consumer group的消费情况
- kafka-reassign-partitions.sh:重新在各个服务器之间分配分区和副本
- 如果安装的是Confluent Kafka,你可以使用Confluent Rebalancer去检查每个服务器上的负载情况并自动地进行分区再平衡
~~~我是ETL工程师/数据仓库工程师~~~
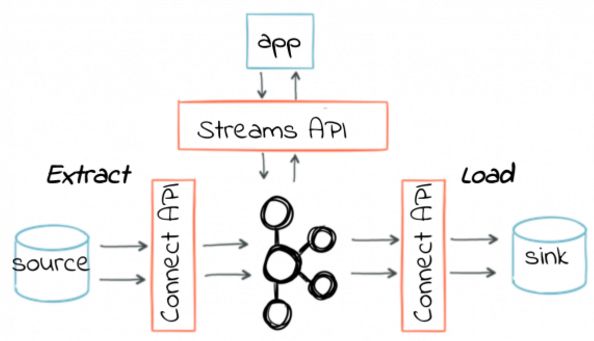
作为一个ETL或数仓工程师,你更在意数据如何在Kafka与外部系统间进行可靠地传输,并且尽量不修改模式信息。不用担心,Kafka提供了Kafka Connect组件用于企业级的数据管理。除此之外,你还可以学习Confluent提供的模式 注册中心的功能。
Kafka Connect是Kafka本身就提供的功能,不需要安装Confluent也能使用。学习Kafka Connect的第一步就是在一个单机环境或分布式环境中运行Connector并且在多个文件的内容导入到Kafka中——具体步骤参见文档中的第7步。
听上去还挺有意思吧,但是导入文件内容其实也没什么大不了的,我们要操作真实的数据存储设备。
首先,我们先安装模式注册中心(下称Schema Registry),因为很多Kafka Connector都需要它的支持。如果你安装的是Apache版的Kafka而不是Confluent,那么很遗憾,你需要下载Confluent Kafka,要么就是拉github代码自己编译。
Schema Registry会假定数据不是文本或JSON格式,而是Avro文件且包含了模式信息。当producer向Kafka发送消息时,数据模式保存在registry中,而后者会对模式进行验证。Consumer使用registry中保存的模式来与不同版本的数据进行交互,从而实现版本兼容性。这样用户很方便识别数据与topic的对应关系。
如果你不想安装Schema Registry也没有问题。Kafka默认提供了大多数的Connector实现,但是你要确保在使用Connector时设置转换器来把数据转成JSON格式,方法如下:
key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter
假设你要导出MySQL数据到ElasticSearch中。Confluent安装包中提供了JDBC Connector以及一个ElasticSearch Connector,你可以直接使用它们,当然也可以从github中编译构建。具体使用方法请参考JDBC Source和ElasticSearch Sink。
最后,你还可以学习Confluent控制中心,它可以让你配置connector以及监控端到端的数据流。
~~~~~~~~~~~~
好了,大部分我认为值得翻译的都在这里了,后面那些关于各种博客和峰会宣传的就不详细列出了。总之,我希望本译文能够对那些想要学习Kafka的人有所帮助~ 2017年,我们再战Kafka!