每天一篇论文 283/376 Deep Virtual Stereo Odometry: Leveraging Deep Depth Prediction for Monocular DSO
原文
TUM Project
本文提出一种基于双目DSO的单目深度估计算法来提高单目DSO的VO能力和重建效果。
摘要
单纯依靠几何线索的单目视觉里程测量方法容易产生尺度漂移,需要在连续帧中有足够的运动视差进行运动估计和三维重建。本文提出利用深度单目深度预测来克服基于几何的单目视觉里程计的局限性。为此,我们将深度预测作为直接的虚拟立体测量纳入到直接稀疏里程计(DSO)中。对于深度预测,我们设计了一个新的深度网络,它在两个阶段的过程中从单个图像中提炼出预测深度。我们以半监督的方式训练我们的网路,以了解立体影像中的光相容性,以及与精确的立体DSO稀疏深度重建的一致性。我们的深度预测优于KITTI基准上单目深度的最新方法。此外,我们的深度虚拟立体里程表在精度上明显超过了以往的单目和基于深度学习的方法。它甚至可以达到与最先进的立体声方法相当的性能,而只需要一个摄像头。
贡献
本文提出了一种新的单目视觉里程表方法,即深度虚拟立体里程表(DVSO),它将深度预测融入到几何单目里程计流程中。在视窗直接束平差的框架内,我们使用深度立体视差作为虚拟直接图像对齐约束。
提出一种深度估计网络方法simplenet,和loss约束提高了深度估计
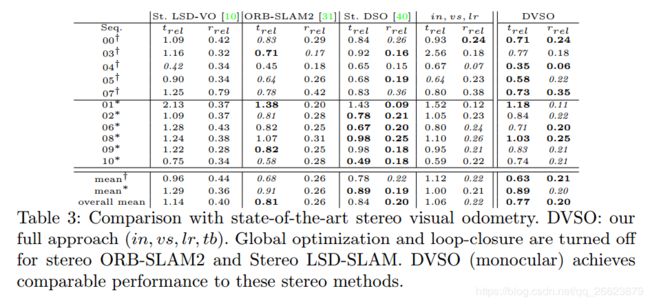
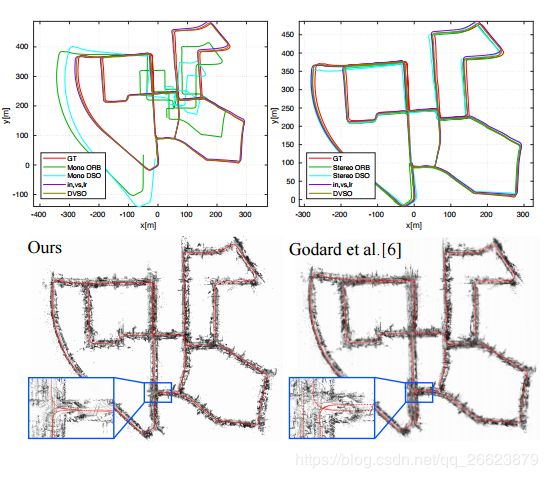
DVSO在KITTI odometry基准上实现了与最先进的立体视觉里程计系统相当的性能。在调整虚拟立体基线等与尺度相关的参数时,它甚至可以优于原始几何VO方法的状态。
方法
本文DSO框架
本文将介绍我们的半监督方法来进行深度单目深度估计。它建立在三个关键要素之上:在类似于的双目立体图像一致性,从光一致性中进行自监督学习,基于监督学习立体DSO的精确稀疏深度重建,以及叠层编解码结构中网络预测的两级细化。
网络方面作者先进行SimpleNet深度估计然后用ResidualNet进行refine
SimpleNet是一种编码器-解码器架构,具有基于ResNet-50的编码器和相应编码器和解码器层之间的跳过连接。解码器将特征映射投影到原始分辨率,生成4对不同分辨率的视差图,分别显示为simple、s和dispright simple,s∈[0,3]。
残差集的目的是进一步细化SimpleNet预测的视差图。ResidualNet学习残差信号dispres,s到视差图dispsimple,s(左、右和所有分辨率)。

LOSS function

用估计的depth优化DSO估计
首先,我们根据差异初始化新关键帧的深度映射。除了这种相当直接的方法外,我们还将虚拟直接图像对齐约束合并到DSO的窗口直接束调整中。我们通过将图像扭曲成束平差估计的深度,并通过我们的网络假设一个虚拟立体设置来预测右视差,从而获得这些约束。

结果
深度估计结果

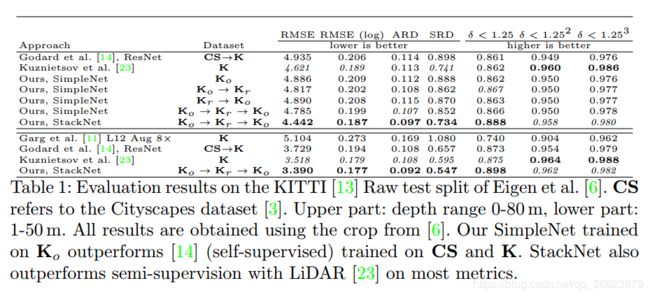
对于细节的估计

里程计的提高