Elasticsearch全文检索解决方案(上)
ES = 数据库 + 搜索引擎
概念: 它提供了一个分布式、支持多用户的全文搜索引擎,**具有HTTP Web接口和无模式JSON文档。**所有其他语言可以使用 RESTful API 通过端口 *9200* 和 Elasticsearch 进行通信 。
- Elasticsearch是用Java开发的
- Elasticsearch是最受欢迎的企业搜索引擎
- Elasticsearch是属于面向文档的数据库
- Elasticsearch 有2.x、5.x、6.x 三个大版本
问题:为什么ES可以完成全文检索功能而Mysql则不可以
因为Mysql只能对指定行和列进行检索,一次性检索所有的内容
(select … from news where title ‘%python%’ or content like ‘%python%’)
(效率极低,索引因为%也失效,只有python%可以应用索引)
ES搜索原理
倒排索引(反向索引)
它是在文档检索系统中最常用的数据结构。
假设我们有两个文档,每个文档的 content 域包含如下内容:
- The quick brown fox jumped over the , lazy+ dog
- Quick brown foxes leap over lazy dogs in summer
正向索引: 存储每个文档的单词的列表
| Doc | Quick | The | brown | dog | dogs | fox | foxes | in | jumped | lazy | leap | over | quick | summer | the |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Doc1 | X | X | X | X | X | X | X | X | X | ||||||
| Doc2 | X | X | X | X | X | X | X | X | X |
反向索引:
Term Doc_1 Doc_2
-------------------------
Quick | | X
The | X |
brown | X | X
dog | X |
dogs | | X
fox | X |
foxes | | X
in | | X
jumped | X |
lazy | X | X
leap | | X
over | X | X
quick | X |
summer | | X
the | X |
------------------------
如果我们想搜索 quick brown ,我们只需要查找包含每个词条的文档:
Term Doc_1 Doc_2
-------------------------
brown | X | X
quick | X |
------------------------
Total | 2 | 1
两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单 相似性算法 ,那么,我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳。
分析
上面不太合理的地方:
Quick和quick以独立的词条(token)出现,然而用户可能认为它们是相同的词。fox和foxes非常相似, 就像dog和dogs;他们有相同的词根。jumped和leap, 尽管没有相同的词根,但他们的意思很相近。他们是同义词。
进行标准化:
Quick可以小写化为quick。foxes可以 词干提取 --变为词根的格式-- 为fox。类似的,dogs可以为提取为dog。jumped和leap是同义词,可以索引为相同的单词jump。
标准化的反向索引:
Term Doc_1 Doc_2
-------------------------
brown | X | X
dog | X | X
fox | X | X
in | | X
jump | X | X
lazy | X | X
over | X | X
quick | X | X
summer | | X
the | X | X
------------------------
对于查询的字符串必须与词条(token)进行相同的标准化处理,才能保证搜索的正确性。
分词和标准化的过程称为 分析 (analysis) :
- 首先,将一块文本分成适合于倒排索引的独立的 词条 , -> 分词
- 之后,将这些词条统一化为标准格式以提高它们的“可搜索性” -> 标准化
分析工作是由分析器 完成的: analyzer
-
字符过滤器
首先,字符串按顺序通过每个 字符过滤器 。他们的任务是在分词前整理字符串。一个字符过滤器可以用来去掉HTML,或者将
&转化成and。 -
分词器
其次,字符串被 分词器 分为单个的词条。一个简单的分词器遇到空格和标点的时候,可能会将文本拆分成词条。
-
Token 过滤器 (词条过滤器)
最后,词条按顺序通过每个 token 过滤器 。这个过程可能会改变词条(例如,小写化
Quick),删除词条(例如, 像a,and,the等无用词),或者增加词条(例如,像jump和leap这种同义词)。
基本分析过程:
- 句子 ’python @web‘
- 过滤特殊符号 ’python web‘
- 分词 python Web
- 标准化 python web
相关性排序
TF/IDF判断相似程度的算法
检索词频率:出现频率越高,相关性越高(就是python(关键词)在文章中(索引)出现的次数)
反向文档频率:每个检索词在索引中出现频率越高(难理解),相关性越低
举个例子:我们搜索关键词是python web
doc1 doc2 doc3
python x x x
web x
现在python这个词在doc(这个就是索引)中都出现过了,所以它的在计算相关性的时候权重会下降
web关键词的权重会上升
字段长度原则:长度越长,相关性越低。(难理解)
举个例子:
有个长句子和个短句:
python web is xxxxyyyyzzz and uuuiii 文章内容
python web 文章标题
搜索关键词:python web
那么肯定索引长度更短的它的权重更高,相关性也就更高
我们排序的是索引,也就是文档
领悟:倒排索引其实就是倒排文档
ES基础概念
关于数据的概念
Relational DB -> Databases 数据库 -> Tables 表 -> Rows 行 -> Columns 列
Elasticsearch -> Indices 索引库 -> Types 类型 -> Documents 文档 -> Fields 字段/属性
上图展示了es是如何存储和组织数据的,这个前面的搜索原理是不一样的(想象一篇文章被拆了)
节点(node)
- 一个运行中的 Elasticsearch 实例称为一个 节点
- 负责处理客户端发送的增删改的请求
- 主节点并不需要涉及到文档级别的变更和搜索等操作
分片(shard)
细节:索引实际上是指向一个或者多个物理 分片 的 逻辑命名空间
-
一个 分片 是一个底层的 工作单元 ,它仅保存了 全部数据中的一部分
-
文档被存储和索引到分片内,但是应用程序是直接与索引而不是与分片进行交互
(毕竟找到索引就是找到数据)
-
Elasticsearch 是利用分片将数据分发到集群内各处的。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里 。
-
当你的集群规模扩大或者缩小时, Elasticsearch 会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里 。
主分片(primary shard)
索引内任意一个文档都归属于一个主分片,所以主分片的数目决定着索引能够保存的最大数据量。
复制分片(副分片 replica shard)
一个副本分片只是一个主分片的拷贝。 副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。
细节: 在索引建立的时候就已经确定了主分片数,但是副本分片数可以随时修改.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9XV5zA6i-1571994020335)(C:\Users\asus\AppData\Roaming\Typora\typora-user-images\1571910621882.png)]
初始设置索引的分片方法
PUT /blogs
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
-
number_of_shards
每个索引的主分片数,默认值是
5。这个配置在索引创建后不能修改。 -
number_of_replicas
每个主分片的副本数,默认值是
1。对于活动的索引库,这个配置可以随时修改。
2 个节点

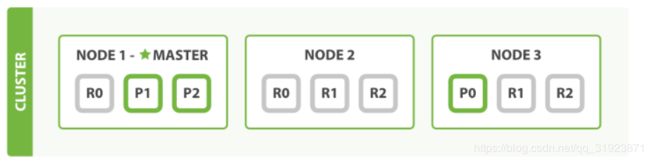
3 个节点
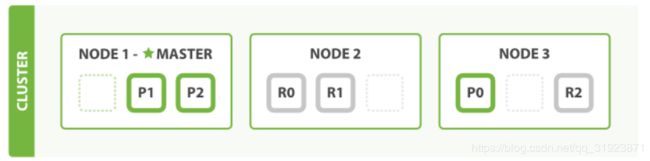
细节:es会自动均匀分配数据到集群中的节点中
拥有越多的副本分片时,也将拥有越高的吞吐量。
这是为什么呢?因为副本分片可以提供搜索和返回文档等读操作提供服务。
查看集群健康状态
GET /_cluster/health
{
"cluster_name": "elasticsearch",
"status": "green",
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0
}
status 字段指示着当前集群在总体上是否工作正常。它的三种颜色含义如下:
-
green所有的主分片和副本分片都正常运行。
-
yellow所有的主分片都正常运行,但不是所有的副本分片都正常运行。
-
red有主分片没能正常运行
curl命令
curl -X http请求方式 请求路径url -H 请求头字段 -d 请求体
curl -X GET 127.0.0.1:9200/articles -H 'Content-Type:application/json' -d {json数据}
IK分词器
需求场景:想向es库中添加一句话我是中国人,如何进行拆分呢?
英文是按照空格切分,那中文呢?语义
解决方案:IK分词器
安装
sudo elasticsearch-plugin install ./elasticsearch-analysis-ik-5.6.16.zip
重新启动
sudo systemctl restart elasticsearch
测试分析器
curl -X GET 127.0.0.1:9200/_analyze?pretty -d '
{
"analyzer": "standard",
"text": "我是&中国人"
}'
curl -X GET 127.0.0.1:9200/_analyze?pretty -d '
{
"analyzer": "ik_max_word",
"text": "我是&中国人"
}'
标准分词器差分为五个汉字,而IK分词器差分为我,是,中国人,中国,国人
索引(库)
增加索引
索引也可以手动创建,通过手动创建,可以控制主分片数目、分析器和类型映射。
PUT /my_index
{
"settings": { ... any settings ... },
"mappings": {
"type_one": { ... any mappings ... },
"type_two": { ... any mappings ... },
...
}
//创建文章索引索引库
curl -X PUT 127.0.0.1:9200/articles -H 'Content-Type: application/json' -d'
{
"settings" : {
"index": {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
}
删除索引
DELETE /index_one,index_two
DELETE /index_*
修改索引
后面才说
类型(表)
类型是在ES中表示一类相似的文档,它由名称和映射组成。(表不就是相同字段的数据的集合吗,类型概念也差不多)
映射, mapping, 就像数据库中的 schema ,描述了文档可能具有的字段或 属性
文档和类型的区别:文档就是指有着下面全部字段的数据,而类型就是多个相似文档的集合
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CUy40GcO-1571994020337)(C:\Users\asus\AppData\Roaming\Typora\typora-user-images\1571969375274.png)]
curl -X PUT 127.0.0.1:9200/articles/_mapping/article -H 'Content-Type: application/json' -d'
{ //下面每一个属性合起来就是一张表,也是字段,不过它们叫做映射,而全部加起来叫做文档
"_all": { //这个all表示下面所有字段的集合,这是整篇文档内容的集合,就是说你不知道python的查 询范围,那么就查询全部
"analyzer": "ik_max_word"
},
"properties": {
"article_id": {
"type": "long",
"include_in_all": "false" //默认放入all这个集合的,如果不需要放入则设置false
},
"user_id": {
"type": "long",
"include_in_all": "false"
},
"title": { //根据这些构建倒排索引
"type": "text",
"analyzer": "ik_max_word", //中文才需要分词
"include_in_all": "true",
"boost": 2 //权重,相关性排序用到,权重越大相关性越大,乘以2(毕竟是标题更重要)
},
"content": {
"type": "text",
"store": "false",
"analyzer": "ik_max_word",
"include_in_all": "true"
},
"status": {
"type": "integer",
"include_in_all": "false"
},
"create_time": {
"type": "date",
"include_in_all": "false"
}
}
}
'
领悟:比如搜索关键词python,那es搜索范围如何确定呢?通过我们发送请求指定的映射就是范围
/article/_search?q=title:python 这样表示我只要查询众多文档中的title字段,这样搜索范围就减小了
查看映射(查看文档的属性)
curl 127.0.0.1:9200/articles/_mapping/article?pretty
映射修改
一个类型映射创建好后,可以为类型增加新的字段映射
curl -X PUT 127.0.0.1:9200/articles/_mapping/article -H 'Content-Type:application/json' -d '
{
"properties": {
"new_tag": {
"type": "text"
}
}
}
**增加新的字段映射可以,但是不能修改已有字段的类型映射**,原因在于elasticsearch已按照原有字段映射生成了反向索引数据,**类型映射改变意味着需要重新构建反向索引数据**,所以并不能再原有基础上修改,只能新建索引库,然后创建类型映射后重新构建反向索引数据。
问题:那么如何进行修改呢?
解决思路:
1.重新创建索引库article_v2
curl -X PUT 127.0.0.1:9200/articles_v2 -H 'Content-Type: application/json' -d'
{
"settings" : {
"index": {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
}
2.创建对应的类型索引
curl -X PUT 127.0.0.1:9200/articles_v2/_mapping/article -H 'Content-Type: application/json' -d' {...}
3.重新索引数据(将原来的索引库的数据导入到新的库中)
curl -X POST 127.0.0.1:9200/_reindex -H 'Content-Type:application/json' -d '
{
"source": {
"index": "articles"
},
"dest": {
"index": "articles_v2"
}
}'
4.为索引起别名
为索引起别名,让新建的索引具有原索引的名字,可以让应用程序零停机。
curl -X DELETE 127.0.0.1:9200/articles 删除原来的
curl -X PUT 127.0.0.1:9200/articles_v2/_alias/articles 取别名(偷天换日)
查询索引别名
# 查看别名指向哪个索引
curl 127.0.0.1:9200/*/_alias/articles
# 查看哪些别名指向这个索引
curl 127.0.0.1:9200/articles_v2/_alias/*
工程实践方法:(不需要删除老库)
1.在创建库的时候就增加版本号,并且有别名
PUT /article_v1 —>alias /articles
2.创建新库,然后将别名/articles指向新库即可
PUT /articles_v2 —> /articles
关于博主
【如果文章有错误,或者想一起学习大数据或者人工智能的朋友可以加下面微信,
在朋友圈不定期直播自己的一些学习心得和面试经历。(请备注CSDN)】
