在centos7上部署selenium(基于chrome驱动)的爬虫项目
相信大家在写爬虫的时候,经常会遇到爬取的网站是动态渲染的,而且各自反爬加密参数,难以破解,所以不得已采用使用了python+selenium进行模拟人为操作爬取。免去了一些繁琐步骤。但是我们大多数都是在windows或者Mac下进行开发和测试。开发完了之后。最终要部署到服务器上去。那么服务器常用的就有liunx。
至于liunx服务器我们都知道,它并没有一个像windows上的桌面,而是一个纯命令行的界面。所以也就没有所谓的Chrome浏览器之类的。在部署selenium项目的时候,需要开启Chrome的无头模式。也就是没有界面的浏览器。由于我在实际部署上centos7上运行的时候,遇到了很多的问题,各种坑,总是会报各种错误使得selenium项目不能正常运行。通过网上搜集和整理了一些资料动手操作,最终尝试了千百次后成功的部署并正常运行爬取了。这里将我的经验以笔记形式记下来,希望对需要的同仁有所参考:
环境准备
首先我们需要准备好一台centos7的liunx服务器,例如我这里是内核为:3.10.0-862.el7.x86_64 的服务器,如下图所示:
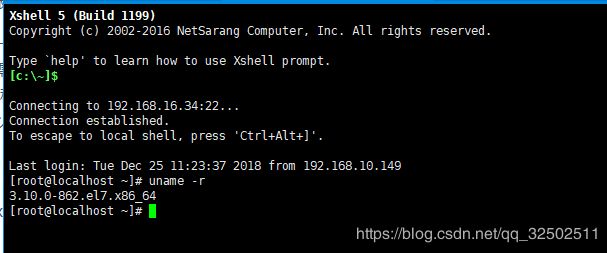
我们可以使用:uname -r 命令查看内核版本,这里建议使用3.10以上的版本。然后我们需要安装Python和项目中用到的一些库。我这里安装的Python版本是3.6.4的,如下图所示:

安装好Python之后,接下来,我们来配置关于selenium的一些环境。相关步骤如下:
步骤1:下载Chrome
wget https://dl.google.com/linux/direct/google-chrome-stable_current_x86_64.rpm步骤2:安装Chrome
yum install ./google-chrome-stable_current_x86_64.rpm步骤3:配置chromedriver
注意chromedriver的版本,要与你安装的chrome版本对应上,这里的版本已经不是最新的。版本列表:http://chromedriver.chromium.org/downloads
步骤4:以我这里为例,下载chromedriver_linux64.zip:
wget https://chromedriver.storage.googleapis.com/2.38/chromedriver_linux64.zip然后解压:解压chromedriver_linux64.zip
unzip chromedriver_linux64.zip步骤5:为chromedriver授权
chmod 755 chromedriver步骤6:Python代码测试
例如使用以下代码:
from selenium import webdriver
def spider(url='http://bing.com'):
option = webdriver.ChromeOptions()
option.add_argument('--no-sandbox')
option.add_argument('--headless')
# 注意path,我这里是chromedriver放在/home/apk/chromedriver
driver = webdriver.Chrome(executable_path='/home/apk/chromedriver', chrome_options=option)
driver.get(url)
print(driver.page_source)
spider()
运行代码,如下图所示表示已经环境配置已经成功:
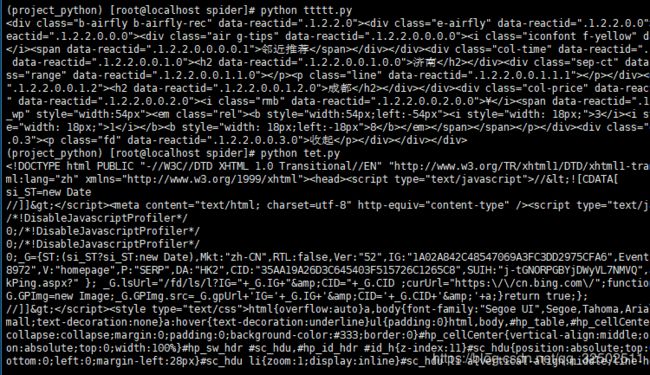
可以看到,它已经成功的返回了许多html代码。
环境配置成功以后,接下来就可以将我们python+selenium写的爬虫代码部署上去啦。最后需要注意两点最关键的代码:
#开启无头模式
options.add_argument('--headless')
#这个命令禁止沙箱模式,否则肯能会报错遇到chrome异常。
options.add_argument('--no-sandbox')这两个参数特别重要,不然运行会报错,因为liunx下是没有界面的。(这里给点建议,在liunx下跑的时候,最好带上header信息的)
这里给出一个示例我自己的爬取同城旅游网机票信息的爬虫:
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from comm.spider_communal import is_same_month,get_day,async,es_save
from selenium.webdriver.chrome.options import Options
import time
import re
from lxml import etree
import platform
import random
import uuid
'''
使用selenium自动化测试工具爬取同城旅游网机票信息
爬取URL:https://www.ly.com
author:liu-yanlin
依赖环境:python3.6.1
pip install selenium==3.13.0
pip install lxml==4.2.1
Chrome驱动下载地址:https://chromedriver.storage.googleapis.com/index.html?path=2.35/
'''
class LySpider():
'''
@:param date_str 查询日期
@:param start_city 查询起始城市
@:param arrive_city 查询抵达城市
'''
def __init__(self,date_str=None,start_city=None,arrive_city=None):
self.date_str=date_str
self.start_city=start_city
self.arrive_city=arrive_city
options = Options()
#开启无头模式
options.add_argument('--headless')
#这个命令禁止沙箱模式,否则肯能会报错遇到chrome异常。
options.add_argument('--no-sandbox')
#建议加上user-agent,因为liunx下有时候会被当成手机版的,所以你会发现代码会报错
num=str(float(random.randint(500,600)))
#此参数最好建议最好带上,不然有些网站会识别liunx系统进行拦截,这里把它伪装成windows下的
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/{} (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/{}".format(num,num))
options.add_argument('Origin=https://www.ly.com')
sys_str = platform.system()
if sys_str=="Linux":
self.driver = webdriver.Chrome(executable_path='/home/chromedriver/chromedriver', chrome_options=options)
else:
self.driver = webdriver.Chrome(chrome_options=options)
'''
通过selenium控制Chrome驱动,完成模拟人工输入查询地址和日期然后点击提交获取查询结果html的流程
'''
def get_query_results(self):
# 隐性等待和显性等待可以同时用,但要注意:等待的最长时间取两者之中的大者
self.driver.implicitly_wait(10)
self.driver.get('https://www.ly.com/FlightQuery.aspx')
locator = (By.ID, 'txtAirplaneCity1')
try:
# 显性等待
WebDriverWait(self.driver, 20, 0.5).until(EC.presence_of_element_located(locator))
# 起始地城市input元素获取并清空值,然后填入城市名称,输入之后模拟按回车键
txtAirplaneCity1 = self.driver.find_element_by_id("txtAirplaneCity1")
# 通过js清空起始地城市值,并填充新的值
js_clear_city1 = ''' document.getElementById('txtAirplaneCity1').value="" '''
self.driver.execute_script(js_clear_city1)
txtAirplaneCity1.send_keys(self.start_city)
txtAirplaneCity1.send_keys(Keys.ENTER)
# 抵达地城市input元素获取并清空值,然后填入城市名称,输入之后模拟按回车键
txtAirplaneCity2 = self.driver.find_element_by_id("txtAirplaneCity2")
txtAirplaneCity2.clear()
# 通过js清空抵达地城市值,并填充新的值
js_clear_city2 = ''' document.getElementById('txtAirplaneCity2').value="" '''
self.driver.execute_script(js_clear_city2)
txtAirplaneCity2.send_keys(self.arrive_city)
txtAirplaneCity2.send_keys(Keys.ENTER)
# 如果所查询的日期在当月范围内,则定位到日历插件中第1个div否则定位到第2个div,div1 表示当月,div2表示下一个月
if is_same_month(self.date_str):
# 定位到日历插件
element_calendar = self.driver.find_elements_by_xpath(
"/html/body/div[17]/div/div[1]/div[1]/div/table/tbody/tr/td/span")
for item in element_calendar:
if item.text == get_day(self.date_str):
item.click()
else:
element_calendar = self.driver.find_elements_by_xpath(
"/html/body/div[17]/div/div[1]/div[2]/div/table/tbody/tr/td/span")
for item in element_calendar:
if item.text == get_day(self.date_str):
item.click()
# 定位搜索按钮并模拟点击提交
airplaneSubmit = self.driver.find_element_by_id("airplaneSubmit")
airplaneSubmit.click()
# 显性等待后,定位到机票查询结果div,然后获取div内的html
locator_content = (By.ID, 'allFlightListDom_1')
WebDriverWait(self.driver, 20, 0.5).until(EC.presence_of_element_located(locator_content))
flight_list_html=self.get_flight_list_dom()
#返回结果
data_list=[]
'''
此处判断返回的flight_list_html里面是否包含有机票信息,如果有直接返回此html代码,否则使用for循环
从新尝试10次,每循环一次暂停一秒(这里为啥要这样写,因为实际情况中可能会存在网络延迟加载慢等原因
导致获取不到内容)
'''
if flight_list_html:
for item in flight_list_html:
data_list.append(item.get_attribute('innerHTML'))
else:
for x in range(10):
flight_list_html = self.get_flight_list_dom()
if flight_list_html:
for item in flight_list_html:
data_list.append(item.get_attribute('innerHTML'))
break
time.sleep(1)
return data_list
except Exception as ex:
print(ex)
finally:
self.driver.close()
'''
定位到机票查询结果div,然后获取div内的html
'''
def get_flight_list_dom(self):
# ---显性等待后,定位到机票查询结果div,然后获取div内的html
#通过观察页面发现这个机票列表数据有三种格式,所以将它们都提取出来拼接成一个List返回
flight_list_html_n=self.driver.find_elements_by_xpath('//div[@class="clearfix flightList"]//div[@class="flist_box"]')
flight_list_html_top=self.driver.find_elements_by_xpath('//div[@class="clearfix flightList"]//div[@class="flist_box f_m_top flist_boxat"]')
flight_list_html_boxbot = self.driver.find_elements_by_xpath('//div[@class="clearfix flightList"]//div[@class="flist_box flist_boxbot"]')
return flight_list_html_n+flight_list_html_top+flight_list_html_boxbot
'''
提取数据
@:param respone get_query_results()方法中返回的结果内容
'''
def extract(self,respone):
try:
data_list=[]
for item in respone:
data = {}
html = etree.HTML(item)
#ID
data["air_id"]=str(uuid.uuid4())
# 航司
airline = html.xpath('/html/body/table/tbody/tr/td[1]/div[1]/text()')
data["airline"] = airline[0] if airline else ""
# 航班号
flight_number = re.findall("[a-zA-Z]{2}\d+", airline[0])+re.findall("\d[a-zA-Z]{1}\d+", airline[0])
data["flight_number"] = flight_number[0] if flight_number else ""
# 出发时间
dep_time = html.xpath('/html/body/table/tbody/tr/td[2]/div[1]/text()')
data["dep_time"] = dep_time[0] if dep_time else ""
# 出发机场
dep_airport = html.xpath('/html/body/table/tbody/tr/td[2]/div[2]/text()')
data["dep_airport"] = dep_airport[0] if dep_airport else ""
# 飞机类型
aircraft_type = html.xpath('/html/body/table/tbody/tr/td[1]/div[2]/a/text()')
data["aircraft_type"] = aircraft_type[0] if aircraft_type else ""
# 抵达时间
arr_time = html.xpath('/html/body/table/tbody/tr/td[4]/div[1]/text()')
data["arr_time"] = arr_time[0] if arr_time else ""
# 抵达机场
arr_airport = html.xpath('/html/body/table/tbody/tr/td[4]/div[2]/text()')
data["arr_airport"] = arr_airport[0] if arr_airport else ""
# 价格
price = html.xpath('/html/body/table/tbody/tr/td[8]/div[1]/span[1]/em[1]/text()')
data["price"] = price[0] if price else ""
#出发日期
data["date_str"]=self.date_str
#采集时间
data["create_time"]=str(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())))
data_list.append(data)
return data_list
except Exception as ex:
print(ex)
return None
'''
保存数据
@:param data 要保存的数据,默认是保存extract()方法所返回的数据
'''
def save(self,data=None):
try:
#以下将数据保存到kafka中
if data:
# with open("ly_data.log","a")as f:
# f.write(str(data))
# f.write("\n")
result=es_save(data)
print("-----返回结果------")
print(result)
except Exception as ex:
pass
if __name__ == "__main__":
@async
def run_spider(date):
print("-------进入 {} ----------爬取".format(date))
ly_spider = LySpider(date,"成都","北京")
res=ly_spider.get_query_results()
data_list=ly_spider.extract(res)
for item in data_list:
print(item)
# ly_spider.save(item)
#-------------------------------
while True:
date_list=["2019-01-14","2019-01-15"]
for x in date_list:
run_spider(x)
time.sleep(600)
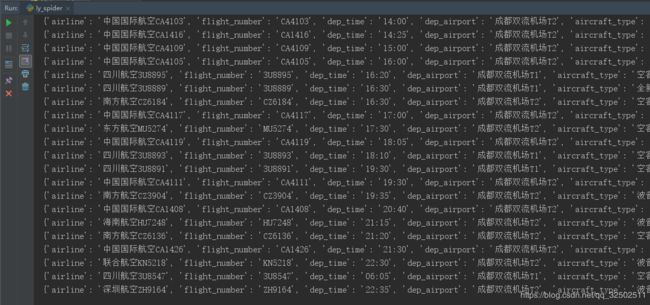
运行结果如图所示: