redis学习系列(七)--redis-database
对于redis的database来说,我应该是之前就接触过,之前迫于项目拆分需要,我去跟公司运维人员沟通过redis的配置,因为是一个全新项目,那时候接触到了redis的seesion配置,redis的缓存配置,其实就是配置database,基本上公司的项目没有共用的database库,即使有共用的,也在key的设置时,强制性的加了项目名的前缀,用于区分。
本想着去看下redisServer的结构是啥样的,一看吓一跳,辣么多,悲伤辣么大...本着不想看的原则,就贴一下相关的配置项吧
redisServer
struct redisServer {
/* General */
pid_t pid; /* Main process pid. */
redisDb *db;
int dbnum; /* Total number of configured DBs */
};
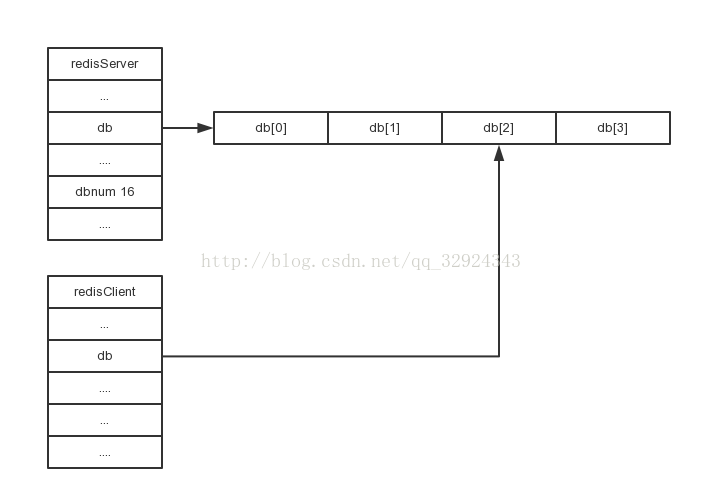
*db就是存储键值对的地方,本质上一个数组,保存着每个数据库存储的键值对。至于dbnum就是redis启动时当前有多少db可供使用,一般是16,这也是配置文件中的默认配置项

我们项目使用的是配置项配置的database是2,因此项目的缓存都会存到db[2]中。而redis的默认配置项是db[0],当然,客户端是可以手动选择数据库的,比如我们项目通过spring配置项的方式选择的是db[2],而redisClient也记录了当前使用的是哪一个库。
redis键空间
/* Redis database representation. There are multiple databases identified
* by integers from 0 (the default database) up to the max configured
* database. The database number is the 'id' field in the structure. */
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP) */
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
struct evictionPoolEntry *eviction_pool; /* Eviction pool of keys */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
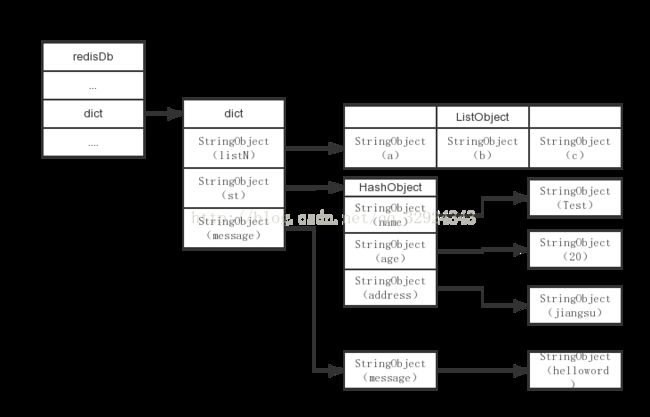
} redisDb;键:键空间的键也就是数据库的键,每个键是一个字符串对象
值:值也即是数据库的值,每个值可以是字符串对象,或者列表对象,或者哈希表对象,集合都可以
例如:
127.0.0.1:6379> set message "hello world"
OK
127.0.0.1:6379> get message
"hello world"
127.0.0.1:6379> lpush listN "a" "b" "c"
(integer) 3
127.0.0.1:6379> hset st name "Test"
(integer) 1
127.0.0.1:6379> hset st age "20"
(integer) 1
127.0.0.1:6379> hset st address "jiangsu"
(integer) 1
127.0.0.1:6379> 上述中有字符串对象,列表对象,和哈希表对象,通过之前的博客分析,大致内部存储其实可以知道是什么样的
其余对字典的操作都是在此基础上进行操作,这里不再叙述,要么增加新节点,要么更新节点的值,要么删除,都是如此,不再记录。
过期时间的设置
redis提供4种不同命令设置过期时间(Time To Live)
EXPIRE: expire
PEXPIRE:pexpire
EXPIREAT:expireat
PEXPIREAT:pexpireat
但是最终都会转成PEXPIREAT来进行时间的设置
typedef struct redisDb {
dict *expires; /* Timeout of keys with a timeout set */
} redisDb;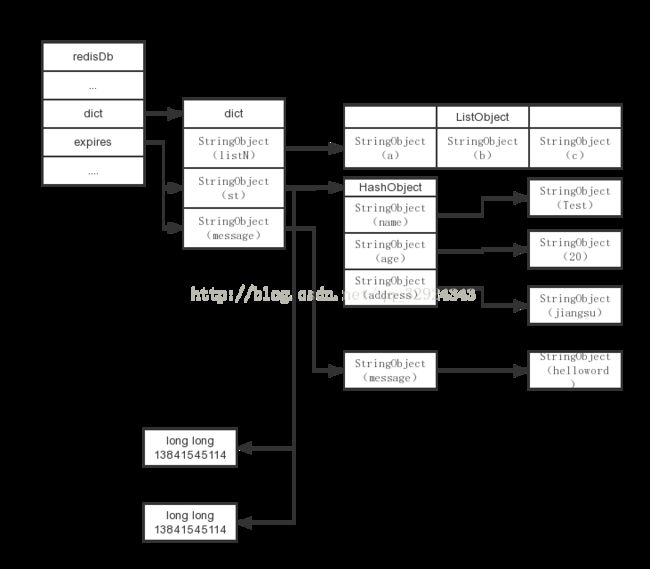
过期键删除策略
定时删除:主动删除,立即执行删除操作
惰性删除:每次从键空间获取键时,会优先检查取得的键是否过期,过期的话执行删除操作,不过期返回。
定期删除:每隔一段时间,程序对数据库进行一次检查,删除里面的过期键。不固定,由删除策略定。
定时删除
定时删除应该说对于内存来说是好事,能够释放键所占用的内存。但是对CPU是不友好的,当过期键比较多时,会过多的占用CPU,而如果此时有大量的命令请求过来时,内存够用,但是redis确在执行删除操作,不去相应命令请求,显然不合理(使用定时器需要用到Redis服务器中的时间事件,无序链表,不清楚这个数据结构,但是它的时间复复杂度是O(n),因此处理不是很高效,对于redis这种O(n)都是不高效的,,,,,)
惰性删除
首先,惰性删除针对的是你获取的键对象,因此你没有获取的是不需要操作的。但是惰性删除对内存不友好,因为数据长期占用了内存,如果没有访问,就一直没法删除。如果有大量的键没有被访问,就一直不会执行删除操作,类似内存泄漏了,这对于redis这种内存数据库来说,是致命的。
定期删除
一般第三种肯定会是一种折中方案了,这里也不例外,定期删除策略每隔一段时间执行一次,并需要限制删除操作的执行时长和频率减少删除操作对CPU的影响
redis的过期删除策略
redis采用的是惰性删除和定期删除两种策略。
惰性删除的实现
db.c/expireIfNeeded实现,大致看了下,过期了才执行删除,没过期或者其他情况,不操作。
int expireIfNeeded(redisDb *db, robj *key) {
mstime_t when = getExpire(db,key);
mstime_t now;
if (when < 0) return 0; /* No expire for this key */
/* Don't expire anything while loading. It will be done later. */
if (server.loading) return 0;
/* If we are in the context of a Lua script, we claim that time is
* blocked to when the Lua script started. This way a key can expire
* only the first time it is accessed and not in the middle of the
* script execution, making propagation to slaves / AOF consistent.
* See issue #1525 on Github for more information. */
now = server.lua_caller ? server.lua_time_start : mstime();
/* If we are running in the context of a slave, return ASAP:
* the slave key expiration is controlled by the master that will
* send us synthesized DEL operations for expired keys.
*
* Still we try to return the right information to the caller,
* that is, 0 if we think the key should be still valid, 1 if
* we think the key is expired at this time. */
if (server.masterhost != NULL) return now > when;
/* Return when this key has not expired */
if (now <= when) return 0;
/* Delete the key */
server.stat_expiredkeys++;
propagateExpire(db,key);
notifyKeyspaceEvent(REDIS_NOTIFY_EXPIRED,
"expired",key,db->id);
return dbDelete(db,key);
}主要思想:在规定的时间内,分多次变量服务器中的各个数据库,从数据库的expires字典中随机检查一部分键的过期时间,并删除其中的过期键。代码就不贴了,短期内也看不懂。
1.函数每次运行时,都从一定数量的数据库中取出一定数量的随机键进行检查,并删除其中过期的键
2.全局变量current_db会记录当前检查的进度,再下一次函数调用时,接着上一次进度进行处理。
3.当所有数据库都被检查一遍之后,current_db会重置为0,进行新一轮的检查。