原来二叉树还可以讲的这么简单,不看看吗?

目录
- 面试三连
- 什么是树
- 二叉树
- 什么是二叉树
- 二叉树的存储结构
- 链表式的二叉树
- 数组形式的二叉树
- 二叉树的遍历
- 二叉查找树
- 概念
- 查找与插入
- 删除节点(链表形式)
- “逻辑删除”
- 如何插入重复数据
- 时间复杂度分析
- 平衡二叉树
- 开篇解答
面试三连
面试官: 知道二叉树吗?
小明: 知道一点…
面试官: 那你说一下什么是二叉树?
小明: 在计算机科学中,二叉树是每个结点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用于实现二叉查找树和二叉堆。
面试官: 哦,还了解二叉查找树啊,二叉树的查找效率并不是特别的高,相对于散列表来说慢很多,为什么还需要二叉树呢?
小明: 不知道。
面试官: 好了,回去等通知吧
就这样,小明失去了这次的工作机会,理由就是没有回答出 有了散列表为什么还要使用二叉树 ,我们一起着这个问题来看看下面讲解的内容:二叉树
什么是树
树状图是一种数据结构,它是由n(n>=0)个有限节点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
每个节点有零个或多个子结点;没有父节点的结点称为根节点;每一个非根节点有且只有一个父节点;除了根节点外,每个子节点可以分为多个不相交的子树(百度百科)。
画张图,一起来理解一下

类似这种结构的就是树结构,a是根节点同时也是b、c的父节点,b是d的父节点同时是a的子节点,d没有子节点,所以它是叶子节点(我们把没有子节点的节点称为叶子节点),c是e、f的父节点同时也是a的子节点,d、f没有子节点,属于叶子节点。
上面是树的基本介绍,其实,树还有三个概念需要我们掌握:高度、深度、层
高度:节点到叶子节点的路径(节点个数),从0开始计数
深度:根节点到某个节点所经历的路径(节点个数),从0开始计数
层:深度+1
概念很抽象,画图很重要,我们使用图形表示一下什么是高度、什么是深度、以及什么是层

解释一下:高度从叶子节点开始计算,叶子结点高度为0;深度从根节点开始计算,根节点深度为0;层从根节点开始计算,根节点为第1层。
二叉树
什么是二叉树
在计算机科学中,二叉树是每个结点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用于实现二叉查找树和二叉堆。
简单点来说就是一个节点只有两个子节点,一个左节点,一个右节点,这样的树我们成为二叉树,虽然定义是这样,但是二叉树并不要求我们每个节点都需要满足两个子节点,有的只有左节点,有的只有右节点,他们也可以被称为二叉树。
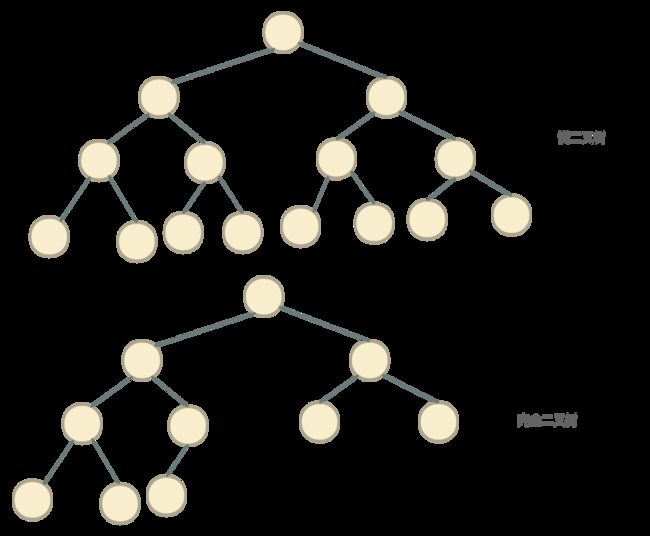
我们来对比一下二叉树和非二叉树

在图中,我们可以很清晰的看出,二叉树中每个节点都只有两个子节点,但是在非二叉树中,我们发现有几个节点都有3个子节点,这种结构只能称为普通树结构。
在二叉树中也有比较特殊的树,主要有两种:满二叉树、完全二叉树。
满二叉树: 一个二叉树,如果每一个层的节点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且每层节点总数是2k-1 ,则它就是满二叉树。
完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K的,有n个节点的二叉树,当且仅当其每一个节点都与深度为K的满二叉树中编号从1至n的节点一一对应时称之为完全二叉树,简单点来说,叶子节点在最底下两层,并且最后一层叶子节点都靠左,除了最后一层,其他节点都要有两个子节点。
二叉树的存储结构
二叉树是怎么存储的呢?其实他有两种数据结构,一种是数组,一种是基于指针的链表,对于二叉树而言使用链表存储相对于数组存储简单的许多。
链表式的二叉树
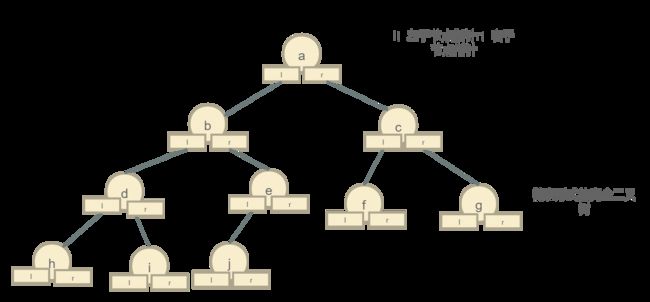
链表式存储需要耗费额外的空间用来存储子节点的指针,用于方便查找,我们只需要知道根节点的指针,就能把整棵树都找出来,不知道你们有没有发现,在叶子节点中也存储了左右节点的指针,但是值为null,当他们有新的子节点的时候就会将子节点的指针存放到对应的位置,这种存储方式是我们经常使用的方式。
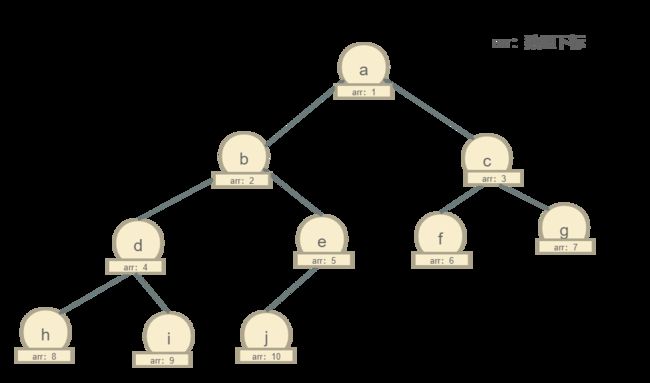
数组形式的二叉树

| 数组下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 数据 | a | b | c | d | e | f | g | h |
我们将根节点存放在数组下标为 i=1的位置,那么他的左子节点(b)所在的下标位置=2 × i=2 ,右子节点(c)= 2 × i- 1= 3,d的下标 = 2 × i(b的下标) = 4,e的下标= 2 × i(b的下标) - 1 = 5,以此类推,所以我们可以得出一个结论:左子节点下标=2 × 当前节点下标,右子节点下标 = 2 × 当前节点下标 - 1 。
仔细看一下上面的表格,数组下标以及数据,我们发现数组长度12,其中只有8个下标中有数据,4个地址中是空的,所以这种存储方式会浪费大量的存储空间,这样一看是不是数组就不适合二叉树呢?
显然不是这样的,数组这种结构也是可以用在二叉树上的,只是有一个条件,当二叉树为完全二叉树的时候使用数组存储相对链表存储更节省存储空间,为什么这么说呢?我们一起看看完全二叉树的数组存储。
| 数组下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 数据 | a | b | c | d | e | f | g | h | i | j |
这是完全二叉树使用数组存储的结果,在表格中,数组长度为11,其中10个地址都被使用了,只有下标为0的地址处于未被使用状态,这样我们的数组得到了充分的使用,仅仅只是浪费了一个地址,相对于链表来说,更省空间,因为链表需要额外的空间存储左右子节点的指针信息,由于数组地址是连续的,它只需要记录自己的地址即可,所以完全二叉树(或者满二叉树)推荐使用数组结构存储。
你可能会疑惑为什么完全二叉树的叶子节点都是靠左而不是靠右,看了上面的分析你应该大致明白了吧,因为靠左不会有数组空间的浪费,如果靠右的话,会导致数组中间至少有一个地址未被使用,所以完全二叉树才要求叶子结点都靠左。
二叉树的遍历
说了这么多都只是对二叉树的介绍,却没有讲到怎么使用二叉树,接下来我们一起来看看二叉树是如何遍历的。
我们需要使用什么方式将存储好的二叉树遍历出来呢?我们常用的方法有三种,分别是:前序遍历、中序遍历、后序遍历。
- 前序遍历:对树结构中的某个节点来说,先打印它自己,再打印他的左子节点,最后打印它的右子节点。
- 中序遍历:对树结构中的某个节点来说,先打印它的左子节点,再打印它本身,最后打印它的右子节点。
- 后序遍历:对树结构中的某个节点来说,先打印它的左子节点,再打印它的右子节点,最后打印它本身。
前序遍历
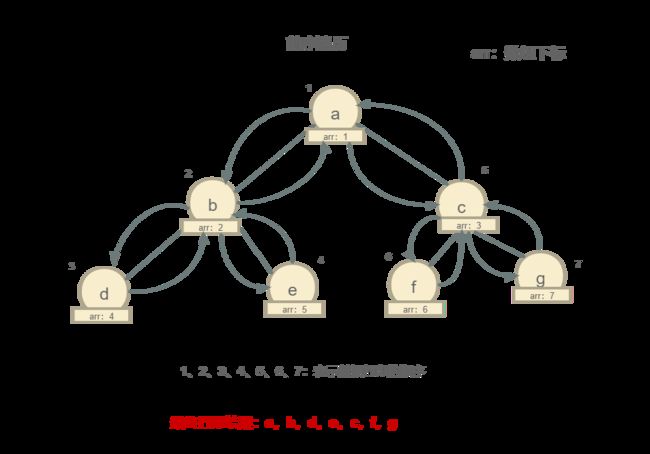
我们从根节点开始打印,找到根节点(a)先打印它本身,然后判断他是否存在左子节点,和明显,b是它的做左子节点,所以再打印b,再通过b查找它的左子节点 —> d,打印d,寻找d的左子节点,没有了,寻找d的右子节点,也没有,往回走,然后查找b的右子节点 —> e,打印e,由于e也没有左右子节点了,往回走,回到根节点,所以这个时候根节点a的左子节点全打印完了,这时候再去查找根节点a的右子节点 —>c,打印c,查找c的左子节点 —>f,打印f,f没有左右子节点了直接往回走,再寻找c的右子节点 —> g,打印g,g没有左右子节点,往回走,回到根节点,遍历完成。
所以前序遍历的最终结果:a, b, d, e, c, f, g
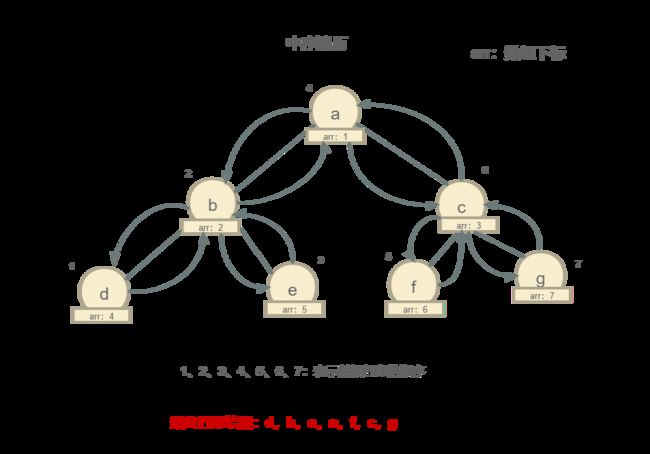
中序遍历
后序遍历
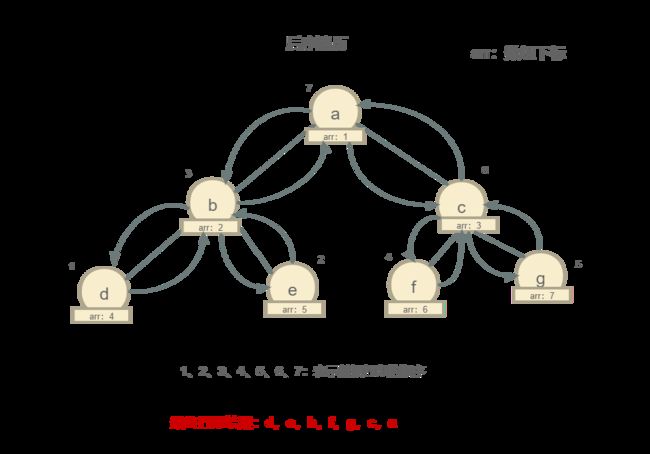
中序遍历和后序遍历的过程我就不写了,可以参考一下前序遍历,自己思考一下,如果不明白,可以在评论中留言,我会将他们补充完成。
这么讲解你有没有对二叉树的遍历有一点点理解了呢?这只是概念,下面我们一起使用代码实现一遍二叉树的前中后序遍历(java代码实现)
NodeTree.java
package binarytree;
public class NodeTree {
/**
* 数据
*/
private Object data;
/**
* 左子节点
*/
private NodeTree leftNodeTree;
/**
* 右子节点
*/
private NodeTree rightNodeTree;
public NodeTree (Object data, NodeTree leftNodeTree,NodeTree rightNodeTree){
this.data = data;
this.leftNodeTree = leftNodeTree;
this.rightNodeTree = rightNodeTree;
}
public Object getData() {
return data;
}
public NodeTree getLeftNodeTree() {
return leftNodeTree;
}
public NodeTree getRightNodeTree() {
return rightNodeTree;
}
}
Test.java
package binarytree;
import java.util.ArrayList;
import java.util.List;
public class Test {
private static NodeTree rootNode = null;
private static List<Object> list = new ArrayList<>();
static {
//数据初始化,方便树结构的打印,初始化的数据结构与上面的前中后序打印的图一样
//b节点的左子节点
NodeTree leftNodeThirdL = new NodeTree("d",null,null);
//b节点的右子节点
NodeTree leftNodeThirdR = new NodeTree("e",null,null);
//根节点的左子节点 b
NodeTree leftNodeSecond = new NodeTree("b",leftNodeThirdL,leftNodeThirdR);
//c节点的左子节点
NodeTree rightNodeThirdL = new NodeTree("f",null,null);
//c节点的右子节点
NodeTree rightNodeThirdR = new NodeTree("g",null,null);
//根节点的右子节点 c
NodeTree rightNodeSecond = new NodeTree("c",rightNodeThirdR,rightNodeThirdL);
//根节点 a
rootNode = new NodeTree("a",leftNodeSecond,rightNodeSecond);
}
/**
* 前序遍历
* @param rootNode
*/
private static void preTraversal(NodeTree rootNode){
if(rootNode != null){
list.add(rootNode.getData());
if(null != rootNode.getLeftNodeTree()){
preTraversal(rootNode.getLeftNodeTree());
}
if(null != rootNode.getRightNodeTree()){
preTraversal(rootNode.getRightNodeTree());
}
}
}
/**
* 中序遍历
* @param rootNode
*/
private static void inorderTraversal(NodeTree rootNode){
if(rootNode != null){
if(null != rootNode.getLeftNodeTree()){
inorderTraversal(rootNode.getLeftNodeTree());
}
list.add(rootNode.getData());
if(null != rootNode.getRightNodeTree()){
inorderTraversal(rootNode.getRightNodeTree());
}
}
}
/**
* 后序遍历
* @param rootNode
*/
private static void afterTraversal(NodeTree rootNode){
if(rootNode != null){
if(null != rootNode.getLeftNodeTree()){
afterTraversal(rootNode.getLeftNodeTree());
}
if(null != rootNode.getRightNodeTree()){
afterTraversal(rootNode.getRightNodeTree());
}
list.add(rootNode.getData());
}
}
/**
* 前中后序遍历
* @param args
*/
public static void main(String[] args) {
preTraversal(rootNode);
System.out.println("前序遍历结果:"+list);
list = new ArrayList<>();
inorderTraversal(rootNode);
System.out.println("中序遍历结果:"+list);
list = new ArrayList<>();
afterTraversal(rootNode);
System.out.println("后序遍历结果:"+list);
}
}
打印结果
前序遍历结果:[a, b, d, e, c, f, g]
中序遍历结果:[d, b, e, a, f, c, g]
后序遍历结果:[d, e, b, f, g, c, a]
Process finished with exit code 0
这个结果与我们画图分析的结果是一致的,并且代码的实现也不是很复杂,不过如果你们仔细看上面的图形的话,你可能就会思考一个问题,二叉树的遍历时间复杂度是多少?
答案是:O(n),原因也很简单,遍历的时间复杂度只会和二叉树中数据的多少(或者高度)有关,在遍历过程中有些节点被访问了两次,按道理来说时间复杂度应该是O(2n),为什么是O(n)? 时间复杂度是随着n的变化而变化,对于2这个常数来说,是可以忽略的,因为他不是影响时间复杂度的关键因素,所以二叉树的遍历时间复杂度为:O(n)。
到现在为止我还是没有讲为什么要使用二叉树,前面都是铺垫,下面的东西才是重点,请拿好笔记本,做好笔记。
二叉查找树
概念
二叉排序树(Binary Sort Tree),又称二叉查找树(Binary Search Tree),亦称二叉搜索树。
特点: 在树的任意一个节点,它的左子节点的值都要小于当前节点,右子节点的值都要大于当前节点,我们将这样的树结构成为二叉查找树。
插入一组从小到大的数据

插入一组从大到小的数据:8,7,6,5,4,3,2,1

插入一组无序的数据:5,3,2,4,1,7,6,8

中序遍历:5,3,2,4,1,7,6,8
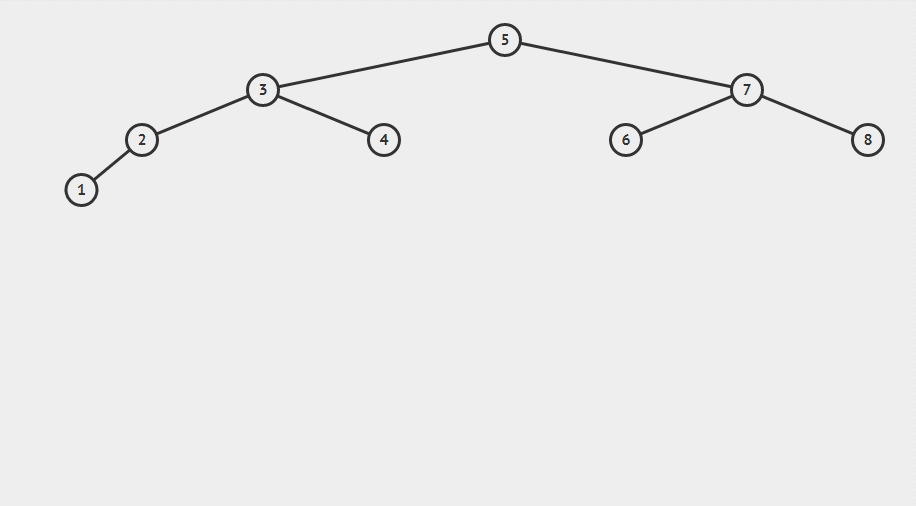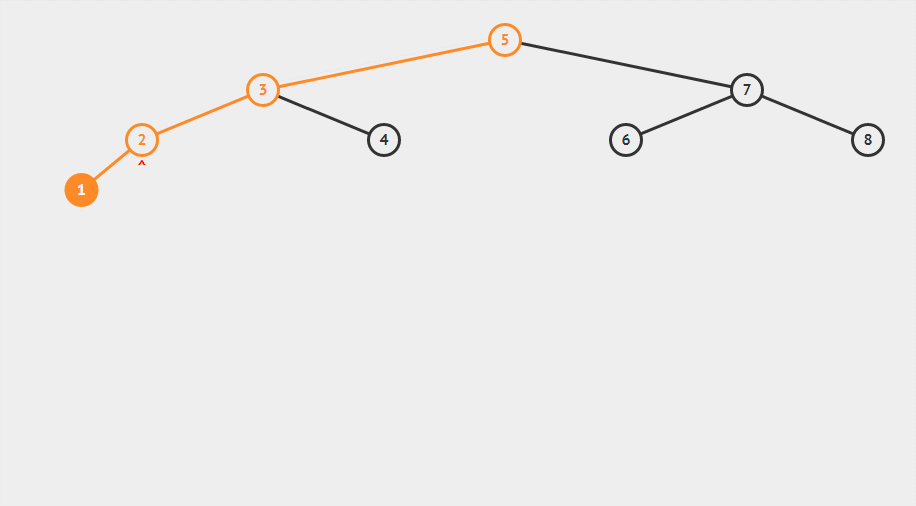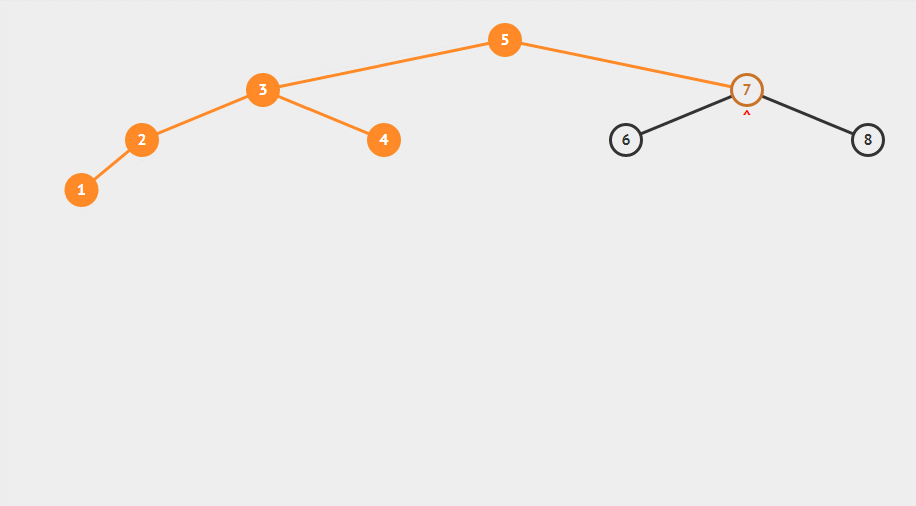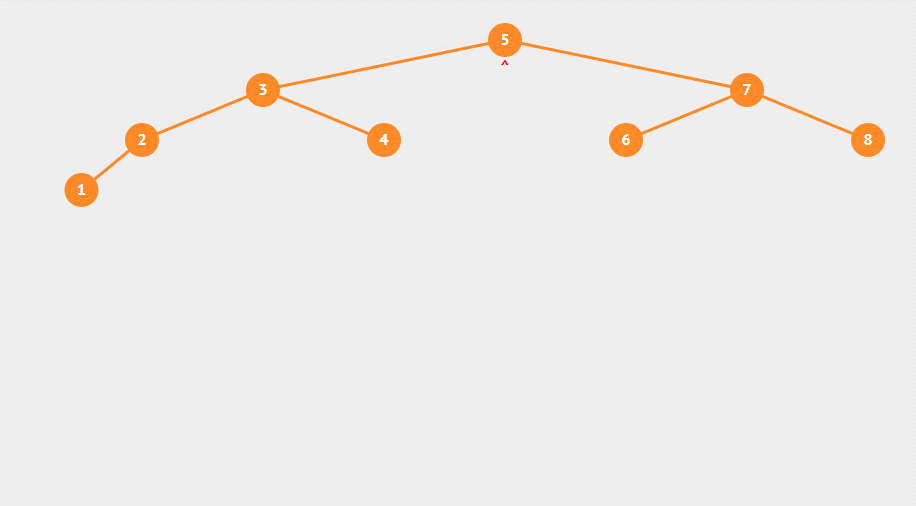
这就是二叉查找树的基本结构,为什么交二叉查找树?就是因为它支持很快的查找能力,同时在删除和插入速度方面也很高效。
查找与插入
如果我们需要在二叉查找树中查找某个元素,我们只需要从根节点开始,首先判断查找的值是否等于根节点的值,如果等于,直接返回,说明找到了,小于根节点的值,那么就往根节点的左子节点中递归查询,知道查到为止,如果查找的值大于根节点的值,那么往根节点的右子节点中递归查找,直到查到为止,是不是有点二分的味道?
我们来看个例子,我们需要在一组数据中查找4这个元素

插入:插入之前也需要查找,它需要查找到自己应该插入的位置,插入时我们将第一个插入的数据作为根节点,之后的插入的数据都会和根节点做对比,如果比根节点数据小,那么就往根节点的左子节点中插入,判断根节点的左子节点是否为空,为空直接插入,否则再次递归查询,直到找到插入的位置位置,反之,如果插入的数据大于根节点数据,那么判断根节点是否存在右子节点,如果不存在,直接插入,如果存在,继续递归查询,找到插入的位置进行插入。
NodeTree.java
package binarytree;
public class NodeTree {
/**
* 数据
*/
private Integer data;
/**
* 左子节点
*/
private NodeTree leftNodeTree;
/**
* 右子节点
*/
private NodeTree rightNodeTree;
public NodeTree (Integer data){
this.data = data;
this.leftNodeTree = null;
this.rightNodeTree = null;
}
public Integer getData() {
return data;
}
public NodeTree getLeftNodeTree() {
return leftNodeTree;
}
public NodeTree getRightNodeTree() {
return rightNodeTree;
}
public void setLeftNodeTree(NodeTree leftNodeTree) {
this.leftNodeTree = leftNodeTree;
}
public void setRightNodeTree(NodeTree rightNodeTree) {
this.rightNodeTree = rightNodeTree;
}
@Override
public String toString() {
return "NodeTree{" +
"data=" + data +
", leftNodeTree=" + leftNodeTree +
", rightNodeTree=" + rightNodeTree +
'}';
}
}
Test.java
package binarytree;
public class Test {
private static NodeTree rootNode = null;
/**
* 搜索次数
*/
private static int seaCount = 0;
/**
* 插入
* @param data
*/
private static void insert(int data) {
if (rootNode == null) {
//插入根节点
rootNode = new NodeTree(5);
return ;
}
NodeTree tree = rootNode;
while (tree != null){
//比较数据和当前节点值的大小
if (data < tree.getData()) {
//小于当前节点的值,判断左子节点是否有数据,没有数据就直接插入到左子节点中
if (tree.getLeftNodeTree() == null) {
tree.setLeftNodeTree(new NodeTree(data));
return ;
}
//否者,获取到当前节点的左子节点,继续递归插入
tree = tree.getLeftNodeTree();
} else {
//插入的值比当前节点值大
//判断当前节点是否存在右子节点,如果不存在,直接将数据插入到当前节点的右子节点中
if (tree.getRightNodeTree() == null) {
tree.setRightNodeTree(new NodeTree(data));
return ;
}
//如果存在,获取到当前节点的右子节点,继续递归插入
tree = tree.getRightNodeTree();
}
}
}
/**
* 搜索
* @param data
* @return
*/
private static NodeTree search(int data){
if(rootNode == null){
seaCount++;
return null;
}
if(rootNode.getData() == data){
seaCount++;
return rootNode;
}
NodeTree tree = rootNode;
while (null != tree ){
seaCount++;
if(data < tree.getData()){
tree = tree.getLeftNodeTree();
}else if(data > tree.getData()){
tree = tree.getRightNodeTree();
}else{
return tree;
}
}
return null;
}
/**
*
*
* @param args
*/
public static void main(String[] args) {
// 5,3,2,4,1,7,6,8
insert(5);
insert(3);
insert(2);
insert(1);
insert(4);
insert(7);
insert(6);
insert(8);
System.out.println("插入完成");
System.out.println("搜索开始-======");
NodeTree search = search(4);
System.out.println(search);
System.out.println("搜索了"+seaCount+" 次");
}
}
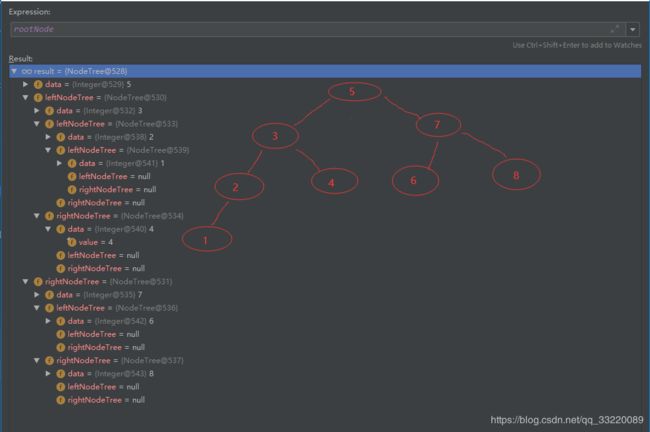
上面的代码主要实现了插入并查找某个元素
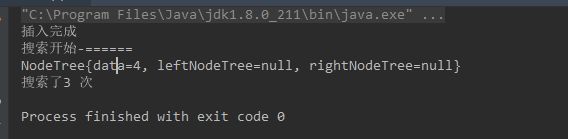
对比一下上面查到的动图,查找了三次就找到了4这个元素,我们使用代码实现也是值搜索了3次就查找到了4,所以代码实现的没有毛病。
删除节点(链表形式)
查找插入我放到了一起讲,为什么要将删除单独分开讲呢?这还不明显吗吗,因为它比较复杂啊。
如果我们现在需要删除二叉树中的某个节点,这个时候不是一个简单的删除就搞定了,而是要视情况而定,大致有以下三种情况。
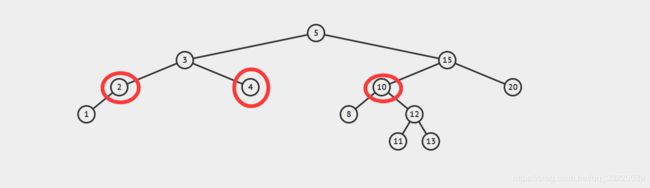
1.删除的节点属于叶子结点:没有子节点,这个时候只需要将他删除即可,C语言只需要删除父节点中指向需要删除子节点指针即可,高级语言(java)只需要将父节点中需要删除子节点的引用即可,删除下图的4 。
2.删除的节点有一个子节点(左子节点或者右子节点都一样,没有特殊要求):我们只需要修改父节点中指向需要删除的指针,让它指向需要删除节点的子节点,删除下图中的2 。
3.删除的节点中含有两个子节点(左子节点 && 右子节点):这种方式稍微麻烦一点,但是也无需过多担心,第一步,我们需要找到需要删除节点右子节点中最小的节点,第二步,将最小的节点替换到为需要删除的节点上,第三步,删除最小的节点,这个最小节点应该是叶子节点,所以只要按照 1 的情况删除即可,删除下图中的10 。
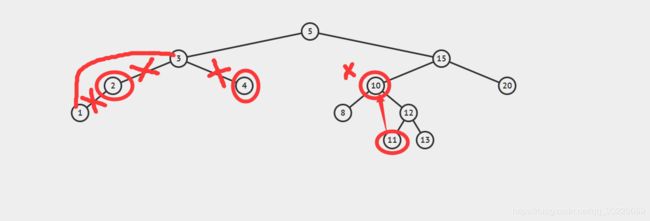
是不是看着有点懵?别担心,我们还有动图

这样看是不是清晰多了,我们在使用代码来实现一下删除。
/**
* 删除节点
* @param data
*/
private static void delete(int data){
NodeTree tree = rootNode;
//tree的父节点
NodeTree treeP = null;
if(null == tree){
return ;
}
//找到需要删除的节点
while (null != tree && tree.getData() != data){
treeP = tree;
if(data < tree.getData()){
tree = tree.getLeftNodeTree();
}else{
tree = tree.getRightNodeTree();
}
}
//判断需要删除的节点是否包含子节点
//如果删除的节点有两个子节点:左子节点与右子节点
if( null != tree.getLeftNodeTree() && null != tree.getRightNodeTree()){
//找到要删除节点右子节点中最小的节点数据
NodeTree minNode = tree.getRightNodeTree();
NodeTree minNodeP = tree;
while(null != minNode.getLeftNodeTree()){
minNodeP = minNode;
minNode = minNode.getLeftNodeTree();
}
//数据交换 将需要删除节点的右子节点中最小节点的值替换到需要删除的节点上
tree.setData(minNode.getData());
tree = minNode;
treeP = minNodeP;
}
//删除的节点没有子节点(叶子结点)或者只有一个子节点
NodeTree childTree = null;
if(null != tree.getLeftNodeTree()){
childTree = tree.getLeftNodeTree();
}else if(null != tree.getRightNodeTree()){
childTree = tree.getRightNodeTree();
}
if(null == treeP){
rootNode = childTree;
}else if(treeP.getLeftNodeTree() == tree){
treeP.setLeftNodeTree(childTree);
}else{
treeP.setRightNodeTree(childTree);
}
}
public static void main(String[] args) {
// 5,3,2,4,1,15,10,20,8,12,13,11
int[] arr = {5,3,2,4,1,15,10,20,8,12,13,11};
for(int i = 0; i<arr.length;++i){
insert(arr[i]);
}
System.out.println("插入完成");
delete(4);
delete(2);
delete(10);
System.out.println(rootNode);
}
删除完成之后的数据
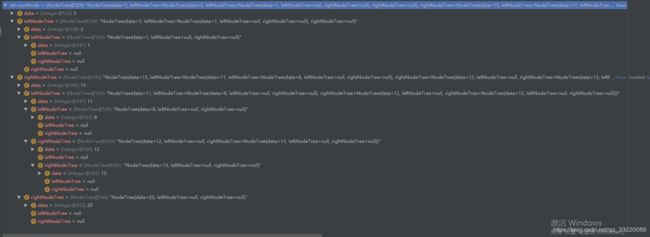
15的左子节点原本应该是10,但是现在变成了11,而11所在的位置已被删除,数据4直接被删除,数据2被删除之后改变了数据3的左子节点的指针,指向数据1,这就是二叉树的三种删除情况,尤其是最后一种删除的节点包含左右子节点,这种不是很好理解,代码看起来也比较抽象,难理解,不过可以多看几遍,然后自己动手走几遍,相信就能理解的。
“逻辑删除”
上面的删除是不是很麻烦?还有一种很简单的方式同样可以以实现删除逻辑,那就是逻辑删除,将需要删除的数据做一下标记,区分开来那些已经被删除,哪些正在被使用,和数据库的逻辑删除性质一样,很简单,就不做代码展示了。
如何插入重复数据
插入一个数据(a1)时,如果查找到一个和插入数据相同的数据(a2),那么我们就将a1存放到a2的右子节点中,右子节点的逻辑处理和之前将的逻辑一致,由于a2的右子节点肯定大于a2,所以我们需要将a1存放到a2的右子节点的左子节点中。

那我们查找的时候需要怎么做呢?和之前的查找一样,只不过在找到第一个数据之后不要停止,需要继续往右子节点查找,理由是可能会存在重复数据,继续往右子节点查找是为了将重复的数据也一起查找出来。
删除操作其实也是之前的逻辑没有什么区别,只是需要多一个步骤,那就是将需要删除的数据先查找出来,然后再执行删除操作。
时间复杂度分析
二叉查找树的时间复杂度应该是和树的高度有关的,为什么这么说呢?你可以仔细看看上面的插入、查找、删除操作就可以得到结论了,所以二叉查找树的时间复杂度=O(h) ,h:树的高度。
那树的高度怎么计算出来呢?之前我一直只知道结论, l o g 2 n log_2n log2n,直到看到了一片很有深度的文章(王争哥写的数据结构算法)之后我终于知道这个高度是怎么算出来的了。
对于满二叉树或者完全二叉树而言,每层的节点数都有着这样的一个规律:m = 2k-1(m:每层的节点数,k:层数)。
那么这棵树最后一层有:2k-1个节点(k为层数),但是呢,我们的树又不可能百分百是满二叉树,所以还有一种情况那就是最后一层只有一个节点,所以最后一层的节点数应该是:1 到 2k-1之间, 我们假设那么总节点数n的范围应该在
n >= 1+2+4+8+…+2(k-2) +1
n <= 1+2+4+8+…+2(k-2) + 2(k-1)
1:第一层节点数;2:第二层节点数;4第三层节点数;2(k-2) 倒数第二层节点数: 2(k-1) :最后一层节点数。
你们发现什么了吗?没错这两个等式都是等比数列,还记得等比数列的求和公式吗?

具体我就不计算了,直接给出最终结果:k的取值范围在[ l o g 2 ( n + 1 ) log_2(n+1) log2(n+1), l o g 2 n log_2n log2n +1],完全二叉树的层数小于等于 l o g 2 n log_2n log2n +1,又因为高度 = 层数-1,所以树的高度小于等于 l o g 2 n log_2n log2n。
我们再将树的高度嵌套回我们开始的公式:最好时间复杂度 = O(h) = O( l o g 2 n log_2n log2n)。
这是最好情况,最坏情况不用我分析大家也知道,肯定是:O(n),所以二叉查找树的时间复杂度在: O( l o g 2 n log_2n log2n) - O(n)之间,极度不稳定。
平衡二叉树
定义很简单:在二叉树中每个节点的左右子节点高度不能相差1。这就是平衡二叉树的概念,我们一起来对比一下平衡二叉树和非平衡二叉树。
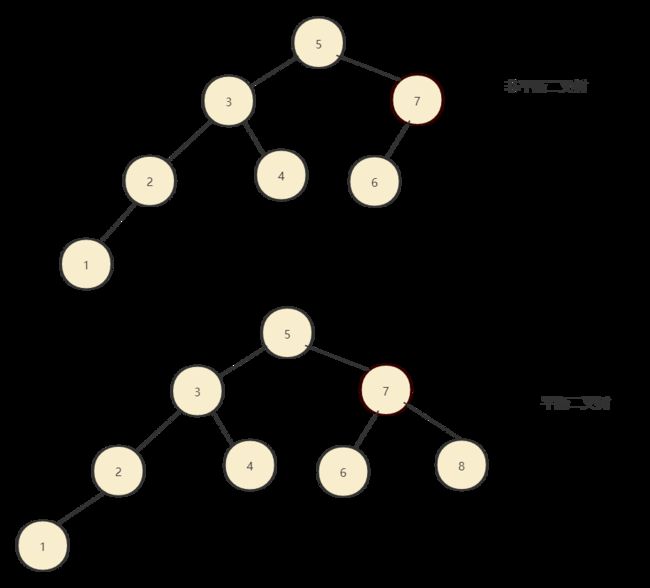
其实我们经常看到的完全二叉树和满二叉树都是平衡二叉树,为什么会定义一个平衡二叉树呢?就是为了让树结构分布的更加均匀,对于某个节点来说,不会出现左右子节点极度不平衡的情况,这样可以尽可能的平衡查找、删除、插入的时间。
开篇解答
有了高效的散列表结构,为什么还要使用二叉树?
如果了解散列表的话都知道,它的删除、查找、新增的时间复杂度能做到:O(1),而我们刚刚讨论的二叉树在最好情况下时间复杂度才是 O( l o g 2 n log_2n log2n),为什么还推荐使用二叉树呢?
1.虽然散列表的查找、删除很快,但是它也存在很慢的时候,什么时候呢?扩容与hash碰撞的时候,扩容会导致数据拷贝,hash碰撞会导致循环计算新的hash值,这个计算可能会让你计算一天都没有计算出新的hash值(虽然不太可能,这里夸张了)。
2.有序性:如果要求我们将数据有序输出,由于散列表是无序的,所以需要将数据先进行排序,在进行输出,而二叉查找树只需要进行一次中序遍历即可。
3.散列表的结构设计要比二叉查找树复杂的多,维护起来更加困难。
所以我们设计一个平衡二叉树,在某些方面确实是比散列表强一点的,比如jdk1.8中 HashMap在hash冲突的时候也是引用了接近平衡二叉查找树的红黑树,也足以说明二叉树的优势。
文章很长,需要细细品味,想当初我学习二叉树的时候也是花了不少功夫呢,冰冻三尺非一日之寒。