参考了Mask-RCNN实例分割模型的训练教程:
- pytorch官方的Mask-RCNN实例分割模型训练教程:TORCHVISION OBJECT DETECTION FINETUNING TUTORIAL
- 官方Mask-RCNN训练教程的中文翻译:手把手教你训练自己的Mask R-CNN图像实例分割模型(PyTorch官方教程)
在Mask-RCNN实例分割模型训练的基础上稍作修改即可实现Faster-RCNN目标检测模型的训练
相关网页:
- torchvision自带的图像分类、语义分割、目标检测、实例分割、关键点检测、视频分类模型:TORCHVISION.MODELS
- torchvision Github项目地址: https://github.com/pytorch/vision
1. 准备工作
除了需要安装pytorch和torchvision外,还需要安装COCO的API pycocotools
windows系统安装pycocotools的方法:Windows下安装pycocotools
导入相关包和模块:
import torch
import os
import numpy as np
import cv2
import matplotlib.pyplot as plt
from torchvision import datasets, transforms
from PIL import Image
from xml.dom.minidom import parse
%matplotlib inline
2. 定义数据集
我使用的是自己使用labelme进行标注后转为voc格式的目标检测数据集,除了背景外有两种标签(mark_type_1和mark_type_2),即num_classes=3
我的voc数据集的目录结构如下图所示:

Annotations文件夹下的xml标注举例:
172.26.80.5_01_20191128084208520_TIMING.jpg
1536
2048
3
该标注包含了一个类别(mark_type_1)的两个bbox
定义数据集:
class MarkDataset(torch.utils.data.Dataset):
def __init__(self, root, transforms=None):
self.root = root
self.transforms = transforms
# load all image files, sorting them to ensure that they are aligned
self.imgs = list(sorted(os.listdir(os.path.join(root, "JPEGImages"))))
self.bbox_xml = list(sorted(os.listdir(os.path.join(root, "Annotations"))))
def __getitem__(self, idx):
# load images and bbox
img_path = os.path.join(self.root, "JPEGImages", self.imgs[idx])
bbox_xml_path = os.path.join(self.root, "Annotations", self.bbox_xml[idx])
img = Image.open(img_path).convert("RGB")
# 读取文件,VOC格式的数据集的标注是xml格式的文件
dom = parse(bbox_xml_path)
# 获取文档元素对象
data = dom.documentElement
# 获取 objects
objects = data.getElementsByTagName('object')
# get bounding box coordinates
boxes = []
labels = []
for object_ in objects:
# 获取标签中内容
name = object_.getElementsByTagName('name')[0].childNodes[0].nodeValue # 就是label,mark_type_1或mark_type_2
labels.append(np.int(name[-1])) # 背景的label是0,mark_type_1和mark_type_2的label分别是1和2
bndbox = object_.getElementsByTagName('bndbox')[0]
xmin = np.float(bndbox.getElementsByTagName('xmin')[0].childNodes[0].nodeValue)
ymin = np.float(bndbox.getElementsByTagName('ymin')[0].childNodes[0].nodeValue)
xmax = np.float(bndbox.getElementsByTagName('xmax')[0].childNodes[0].nodeValue)
ymax = np.float(bndbox.getElementsByTagName('ymax')[0].childNodes[0].nodeValue)
boxes.append([xmin, ymin, xmax, ymax])
boxes = torch.as_tensor(boxes, dtype=torch.float32)
# there is only one class
labels = torch.as_tensor(labels, dtype=torch.int64)
image_id = torch.tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
# suppose all instances are not crowd
iscrowd = torch.zeros((len(objects),), dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"] = labels
# 由于训练的是目标检测网络,因此没有教程中的target["masks"] = masks
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
if self.transforms is not None:
# 注意这里target(包括bbox)也转换\增强了,和from torchvision import的transforms的不同
# https://github.com/pytorch/vision/tree/master/references/detection 的 transforms.py里就有RandomHorizontalFlip时target变换的示例
img, target = self.transforms(img, target)
return img, target
def __len__(self):
return len(self.imgs)
3. 定义模型
有两种方式来修改torchvision默认的目标检测模型:第一种,采用预训练的模型,在修改网络最后一层后finetuning微调;第二种,根据需要替换掉模型中的骨干网络,如将ResNet替换成MobileNet等。
这两种方法的具体使用可以参考最文章开头的官方教程以及官方教程翻译,在这里我选择了第一种方法。
定义模型可以简单的使用:
torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=False, progress=True, num_classes=3, pretrained_backbone=True)
也可参考教程的写法:
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
def get_object_detection_model(num_classes):
# load an object detection model pre-trained on COCO
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
# replace the classifier with a new one, that has num_classes which is user-defined
num_classes = 3 # 3 class (mark_type_1,mark_type_2) + background
# get the number of input features for the classifier
in_features = model.roi_heads.box_predictor.cls_score.in_features
# replace the pre-trained head with a new one
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
return model
4. 数据增强
在图像输入到网络前,需要对其进行数据增强。这里需要注意的是,由于Faster R-CNN模型本身可以处理归一化(默认使用ImageNet的均值和标准差来归一化)及尺度变化的问题,因而无需在这里进行mean/std normalization或图像缩放的操作。
由于from torchvision import的transforms只能对图片进行数据增强,而无法同时改变图片对应的label标签,因此我们选择使用torchvision Github项目中的一些封装好的用于模型训练和测试的函数:https://github.com/pytorch/vision/tree/master/references/detection

其中的engine.py、utils.py、transforms.py、coco_utils.py、coco_eval.py我们会用到,把这些文件下载下来。我把这些文件放在了正在写的Faster-RCNN目标检测模型训练.ipynb脚本的旁边
查看下载下来的transforms.py,可以看到它里面就有对图像进行水平翻转(RandomHorizontalFlip)时target(bbox)变换的示例:
class RandomHorizontalFlip(object):
def __init__(self, prob):
self.prob = prob
def __call__(self, image, target):
if random.random() < self.prob:
height, width = image.shape[-2:]
image = image.flip(-1)
bbox = target["boxes"]
bbox[:, [0, 2]] = width - bbox[:, [2, 0]]
target["boxes"] = bbox
if "masks" in target:
target["masks"] = target["masks"].flip(-1)
if "keypoints" in target:
keypoints = target["keypoints"]
keypoints = _flip_coco_person_keypoints(keypoints, width)
target["keypoints"] = keypoints
return image, target
由此编写相应的数据增强函数:
import utils
import transforms as T
from engine import train_one_epoch, evaluate
# utils、transforms、engine就是刚才下载下来的utils.py、transforms.py、engine.py
def get_transform(train):
transforms = []
# converts the image, a PIL image, into a PyTorch Tensor
transforms.append(T.ToTensor())
if train:
# during training, randomly flip the training images
# and ground-truth for data augmentation
# 50%的概率水平翻转
transforms.append(T.RandomHorizontalFlip(0.5))
return T.Compose(transforms)
5. 训练模型
至此,数据集、模型、数据增强的部分都已经写好。在模型初始化、优化器及学习率调整策略选定后,就可以开始训练了。在每个epoch训练完成后,我们还要在测试集上对模型的性能进行评价。
from engine import train_one_epoch, evaluate
import utils
root = r'数据集路径'
# train on the GPU or on the CPU, if a GPU is not available
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
# 3 classes, mark_type_1,mark_type_2,background
num_classes = 3
# use our dataset and defined transformations
dataset = MarkDataset(root, get_transform(train=True))
dataset_test = MarkDataset(root, get_transform(train=False))
# split the dataset in train and test set
# 我的数据集一共有492张图,差不多训练验证4:1
indices = torch.randperm(len(dataset)).tolist()
dataset = torch.utils.data.Subset(dataset, indices[:-100])
dataset_test = torch.utils.data.Subset(dataset_test, indices[-100:])
# define training and validation data loaders
# 在jupyter notebook里训练模型时num_workers参数只能为0,不然会报错,这里就把它注释掉了
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=2, shuffle=True, # num_workers=4,
collate_fn=utils.collate_fn)
data_loader_test = torch.utils.data.DataLoader(
dataset_test, batch_size=2, shuffle=False, # num_workers=4,
collate_fn=utils.collate_fn)
# get the model using our helper function
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=False, progress=True, num_classes=num_classes, pretrained_backbone=True) # 或get_object_detection_model(num_classes)
# move model to the right device
model.to(device)
# construct an optimizer
params = [p for p in model.parameters() if p.requires_grad]
# SGD
optimizer = torch.optim.SGD(params, lr=0.0003,
momentum=0.9, weight_decay=0.0005)
# and a learning rate scheduler
# cos学习率
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=1, T_mult=2)
# let's train it for epochs
num_epochs = 31
for epoch in range(num_epochs):
# train for one epoch, printing every 10 iterations
# engine.py的train_one_epoch函数将images和targets都.to(device)了
train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=50)
# update the learning rate
lr_scheduler.step()
# evaluate on the test dataset
evaluate(model, data_loader_test, device=device)
print('')
print('==================================================')
print('')
print("That's it!")
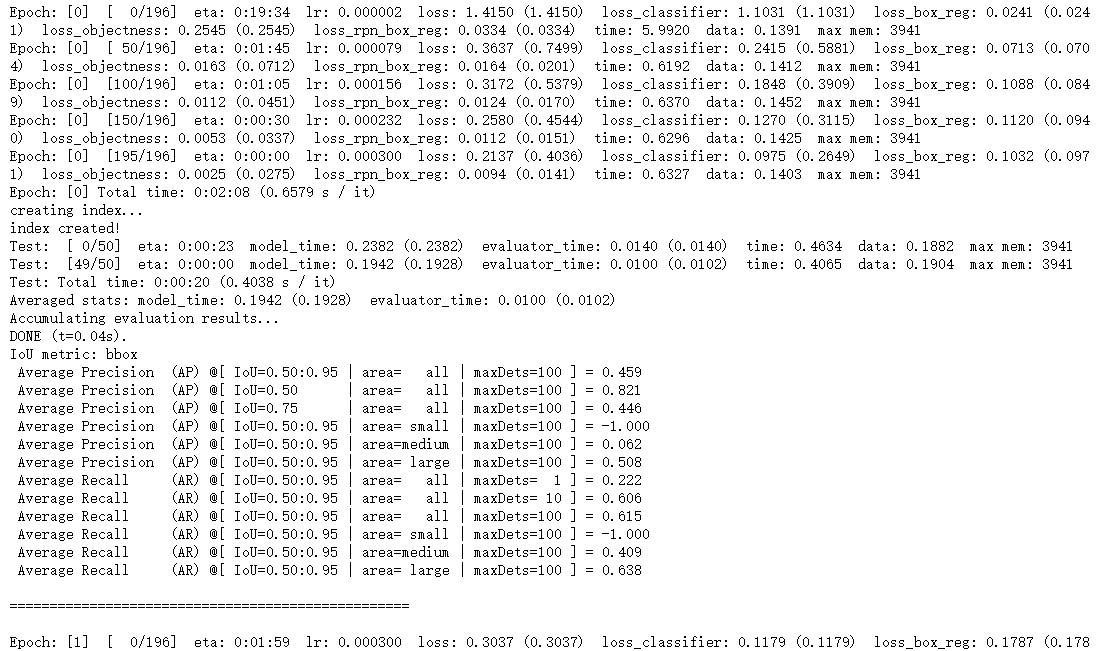
可以看到第一个epoch的学习率并不是设定的0.0003,而是从0开始逐渐增长的,其原因是在engine.py的train_one_epoch函数中,第一个epoch采用了warmup的学习率:
if epoch == 0:
warmup_factor = 1. / 1000
warmup_iters = min(1000, len(data_loader) - 1)
lr_scheduler = utils.warmup_lr_scheduler(optimizer, warmup_iters, warmup_factor)
此外,由于我的数据集中的bbox的面积都比较大,因此area= small时的AP和AR都为-1.000
最后,保存模型:
torch.save(model, r'保存路径\modelname.pkl')
6. 查看效果
用opencv绘制bbox:
def showbbox(model, img):
# 输入的img是0-1范围的tensor
model.eval()
with torch.no_grad():
'''
prediction形如:
[{'boxes': tensor([[1492.6672, 238.4670, 1765.5385, 315.0320],
[ 887.1390, 256.8106, 1154.6687, 330.2953]], device='cuda:0'),
'labels': tensor([1, 1], device='cuda:0'),
'scores': tensor([1.0000, 1.0000], device='cuda:0')}]
'''
prediction = model([img.to(device)])
print(prediction)
img = img.permute(1,2,0) # C,H,W → H,W,C,用来画图
img = (img * 255).byte().data.cpu() # * 255,float转0-255
img = np.array(img) # tensor → ndarray
for i in range(prediction[0]['boxes'].cpu().shape[0]):
xmin = round(prediction[0]['boxes'][i][0].item())
ymin = round(prediction[0]['boxes'][i][1].item())
xmax = round(prediction[0]['boxes'][i][2].item())
ymax = round(prediction[0]['boxes'][i][3].item())
label = prediction[0]['labels'][i].item()
if label == 1:
cv2.rectangle(img, (xmin, ymin), (xmax, ymax), (255, 0, 0), thickness=2)
cv2.putText(img, 'mark_type_1', (xmin, ymin), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 0, 0),
thickness=2)
elif label == 2:
cv2.rectangle(img, (xmin, ymin), (xmax, ymax), (0, 255, 0), thickness=2)
cv2.putText(img, 'mark_type_2', (xmin, ymin), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0),
thickness=2)
plt.figure(figsize=(20,15))
plt.imshow(img)
查看效果:
model = torch.load(r'保存路径\modelname.pkl')
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model.to(device)
img, _ = dataset_test[0]
showbbox(model, img)