《数据结构与算法-Python语言描述》读书笔记(3)第3章线性表(关键词:数据结构/算法/Python/线性表/顺序表)
本章的预备知识(读者自己补充的):
(1) 谓词(在本章中,“谓词pred”(即predicate)首次出现在“3.3 链接表 - 3.3.2 单链表 - 扫描、定位和遍历 - 按元素定位”中。)
解释:
离散数学都会讲的一个词语,简单来说就是代入某个论域内的变量就可以产生真或假结果的表达式。比如 x=y+3就是一个谓词,代入(4,1)就是True,代入(0,0)就是False。
参考文献:
如何理解计算机科学相关里出现的“谓词”?
我的理解:
判定某个表达式为True还是False。
金山词霸的释义:
vt.断言,断定; 宣布,宣讲; 使基于;
vi.断言,断定;
n.谓语; 述语;
adj.谓语的; 述语的;
(2)结点(在本章中,“结点”首次出现在“3.3 链接表 - 3.3.2 单链表 - 【P79 - P80】”中,我认为是重点,至少在本章是单链表的基础,理解它很重要!!!这里篇幅有限,建议去阅读原文。)
解释:
单链表(单向链接表)的结点是一个二元组,其表元素域elem保存着作为表元素的数据项(或者数据项的关联信息),链接域next里保存同一个表里的下一个结点的标识(这里我存在一点疑问,“标识”是不是指“链接”、“内存地址”)。

(3)表头变量、表头指针、head(在本章中,“表头变量、表头指针”首次出现在“3.3 链接表 - 3.3.2 单链表 - P80 【也就是说。。。】”中,据我的阅读,至少本章用的是head来代表表头变量。)
我的理解:
表头变量是一个变量,这个变量保存着这个表的首结点的引用(或称为链接)。
(4)rear
金山词霸释义:
n 后部;后面;后尾
第3章 线性表

3.1 线性表的概念和表抽象数据类型
3.1.1 表的概念和性质
3.1.2 表抽象数据类型
(读者笔记:这一节讲了线性表的实现者和使用者需要从各自角度需要考虑的问题、使用者角度考虑一个线性表数据结构应该提供哪些操作。请到书上仔细阅读!)
线性表的操作
表抽象数据类型
(读者笔记:这一小节我就不截图了,书上仔细看,也值得仔细看。)
3.1.3 线性表的实现:基本考虑
(读者笔记:这一小节提到了线性表的两种基本实现模型,详情看书上,值得仔细阅读!!)
3.2 顺序表的实现

3.2.1 基本实现方式
(读者笔记:本小结涉及了“引用”、“链接”、“间接访问”、“索引”、“存储区”等概念,建议仔细阅读,我就不详细截图了。)
3.2.2 顺序表基本操作的实现
创建和访问操作
(读者笔记:这一小节内容有点多,我就不截图了。详细看书上吧。)
创建空表:
简单判断操作:
访问给定下表i的元素:
遍历操作:
查找给定元素d的(第一次出现的)位置:
查找给定元素d在位置k之后的第一次出现的位置:
最后几个操作都需要检查表元素的内容,属于基于内容的检索。数据存储和检索是一切计算和信息处理的基础。
总结一下:不修改表结构的操作只有两种模式,或者是直接访问,或者是基于一个整型变量,按下标循环并检查和处理。
变动操作:加入元素

尾端加入新的数据项:
新数据存入元素存储区的第i个单元:
变动操作:删除元素

尾端删除元素:
删除位置i的数据:
基于条件的删除:
顺序表及其操作的性质
各种访问操作,如果其执行中不需要扫描表内容的全部或一部分,其时间复杂度都是O(1),需要扫描表内容操作时间复杂度都是O(n)。
表的顺序实现(顺序表)的总结:

3.2.3 顺序表的结构
两种基本实现方式
(读者笔记:这一小节仅截图“分离式结构”,详细见书上。)
替换元素存储区
分离式实现的最大优点是带来了一种新的可能:可以在标识不变的情况下,为表对象换一块元素存储区。也就是说,表还是原来的表,其内容可以不变,但是容量改变了。
如果采用分离式技术实现,可以在不改变对象的情况下换一块*更大的元素存储区*,使加入元素操作可以正常完成。操作过程如下:
1)另外申请一块更大的元素存储区。
2)把表中已有的元素复制到新存储区。
3)用新的元素存储区替换原来的元素存储区(改变表对象的元素区链接)。(这里参见图3.6b,读者补充,)
4)实际加入新元素。
后端插入和存储区扩充
(读者补充:这一小节我没有仔细读,感觉不是很重要,但建议下次仔细阅读。)
3.2.4 Python的list
list的基本实现技术
一些主要操作的性质
几个操作

3.2.5 顺序表的简单总结
3.3 链接表
3.3.1 线性表的基本需要和链接表

(读者笔记:我认为的重点在于“在前一结点里用链接的方式显式地记录与下一结点之间的关联”)
3.3.2 单链表(读者笔记:重点来了!!!看的似懂非懂。。后续需要着重看!!!)
单向链接表(简称单链表或者链表)的结点是一个二元组,其表元素域elem保存着作为表元素的数据项(或者数据项的关联信息),链接域next里保存同一个表里的下一个结点的标识。
(读者说明:截图很少,书上讲的很详细,建议后续仔细看书!!!)
(读者笔记:这一段关于表结点类的代码很重要!!!)
class LNode:
def __init__(self, elem, next_=None):
self.elem = elem
self.next = next_基本链表操作

创建空链表:
删除链表:
判断表是否为空:
判断表是否满:
加入元素(读者备注:请注意!!!这一小节我认为很重要!!!)
(读者备注:注意,这里的head是指表头变量,后面会用到,建议彻底搞懂。)
表首端插入:
示例代码段:
q = LNode(13)
q.next = head.next
head = q一般情况的元素插入:(读者补充,这一段说明,我没有看得很懂,下次仔细看!!!)
(读者补充:这一段提到了“next域”,建议回头去看3.3.2 单链表 —— 图3.7,我把前面的图搬过来吧。。)

示例代码段:
q = LNode(13)
q.next = pre.next
pre.next = q删除元素
(读者补充:这一小节我没有看的很明白,下次要仔细阅读。)
删除表首元素:
一般情况的元素删除:
扫描、定位和遍历
按下标定位:(读者补充:这里的代码没有看明白,还提到了“表扫描模式”,建议回头详细看。)
按元素定位:(读者补充:这里提到了“谓词pred”,暂时不懂。
pred的全称是predicate,查词典:
vt 断言,断定
n 谓语)
链表操作的复杂度
(读者笔记:这一小节讲到了链表各种操作的时间复杂度,这一阶段我并不关注这一部分,但阅读这一小节可以加深对各种操作的理解,建议以后仔细阅读。)
求表的长度
在使用链表时,经常需要求表的长度,为此可以定义一个函数:
(读者笔记:以下代码,加入了我的注释)
# 采用遍历单链表的所有结点完成计数,首先访问第一个元素,故传入表头变量head。
def length(head):
p, n = head, 0 # 将表头变量head的赋值给变量p,如果变量p为None,
即表头变量head为None,也就是说,该单链表为空表,将0返回给length。
while p is not None: # 将结点p的next域赋值给变量p(注意,这里的结点与变量是一个意思),
每做这样的一次操作,都将n的值加1,即表示算出的长度加1,这样为一次循环,
如果循环若干次后,到达表的最后结点(表尾结点),而表尾结点的连接域是None
(这里请参阅“3.3.2 单链表 - P80”的“为了表示... 该表是空表”这一两段中,关于空链接的描述。),
则跳出循环,将n值返回给length。
n += 1
p = p.next
return n这个函数采用表扫描模式,遍历表中所有结点完成计数。
实现方式的变化
3.3.3 单链表类的实现
3.3.2节定义了链表的结点类LNode,下面是一段简单使用代码:
(读者备注:以下代码我没有完全看懂,建议后续继续看)
llist1 = LNode(1)
p = llist1
for i in range(2, 11):
p.next = LNode(i)
p = p.next
p = llist1
while p is not None:
print(p.elem)
p = p.next自定义异常
class LinkedListUnderflow(ValueError):
passLList类的定义,初始化函数和简单操作
(读者备注:)
(读者笔记:以下代码,没有看得很明白,下次细看。)
class LList:
# 读者注释: LList将表初始化为空表,故表头变量_head为None。
def __init__(self):
self._head = None
# 读者注释:如果_head为None,就返回True。如果不是None,就返回False。
def is_empty(self):
return self._head is None
# 读者注释:
def prepend(self, elem):
self._head = LNode(elem, self._head)
def pop(self):
if self._head is None: # 无结点,引发异常
raise LinkedListUnderflow("in pop")
e = self._head.elem
self._head = self._head.next
return e(读者笔记:为了方便理解以上的“prepend”方法,这里我把前面“3.3.2 单链表 P80”提到的“简单的表结点类”的代码,复制过来:
class LNode:
def __init__(self, elem, next_=None):
self.elem = elem
self.next = next_)
后端操作
(读者笔记:本小结请着重阅读,一定要理解这里的代码!!)
在链表的最后插入元素,必须先找到链表的最后一个结点。其实现首先是一个扫描循环,找到响应结点后把包含新元素的结点插入在其后。下面是定义:
def append(self, elem):
# 本读书笔记的开头已经提到过,表头变量head保存着这个表的首节点的引用(或称链接)
# 如果类的实例(即一个列表)的表头变量是None,即列表的首节点为空:
if self._head is None:
# 那么,将表结点类的实例(即一个结点)的表元素域elem赋值给表头变量head,即,将表头变量head指向结点LNode的表元素域elem
self._head = LNode(elem)
return
p = self._head
# 如果原表不为空,那么,需要将next域指向新加入的元素elem。
while p.next is not None:
p = p.next
p.next = LNode(elem)现在考虑删除表中最后元素的操作,也就是要删除最后的结点。
def pop_last(self):
if self._head is None: # 空表
raise LinkedListUnderflow("in pop_last")
p = self._head
if p.next is None: # 表中只有一个元素
e = p.elem
self._head = None
return e
while p.next.next is not None: # 直到p.next是最后结点
p = p.next
e = p.next.elem
p.next = None
return e其他操作
def find(self, pred):
p = self._head
while p is not None:
if pred(p.elem):
return p.elem
p = p.nextdef printall(self):
p = self._head
while p is not None:
print(p.elem, end='')
if p.next is not None:
print(', ', end='')
p = p.next
print('')表的遍历
(读者笔记:关于如下代码中的“proc”,应该是伪代码,我的理解是,“proc”应该是指一种能完成某种功能的函数。)
def for_each(each, proc):
p = self._head
while p is not None:
proc(p.elem)
p = p.next为LList类定义对象的一个迭代器
def elements(self):
p = self._head
while p is not None:
yield p.elem
p = p.next筛选生成器
def filter(self, pred):
p = self._head
while p is not None:
if pred(p.elem):
yield p.elem
p = p.next3.4 链表的变形和操作
3.4.1 单链表的简单变形
前面单链表实现有一个缺点:尾端加入元素操作的效率低,因为这时只能从表头开始查找,直至找到表的最后一个结点,而后才能链接新结点。
图3.12给出了一种可行设计,其中的表对象增加一个表尾结点引用域。有了这个域,只需常量时间就能找到尾结点,在表尾加入新结点的操作就可能做到O(1)。
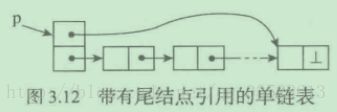
通过继承和扩充定义新链接表类

初始化和变动操作

(读者笔记:以下代码为什么要这么写,请看书上的详细解释。)
def __init__(self):
LList.__init__(self)
self._rear = None # 作为内部作用域,用_rear作为域名,将它也初始化None考虑前段插入操作(读者笔记:暂时不能完全看懂,先抄代码吧)
def prepend(self, elem):
self._head = LNode(elem, self._head)
if self._rear is None: # 空表
self._rear = self._head更合适的代码:
def prepend(self, elem):
if self._head is None:
self._head = LNode(elem, slef._head)
self._rear = self._head
else:
self._head = LNode(elem, self._head)在链表操作定义中,通常都需要区分被修改的是头变量(域)的情况还是一般情况。函数定义:
def append(self, elem):
if self._head is None: # 是空表
self._head = LNode(elem, self._head)
self._rear = self._head
else:
self._rear.next = LNode(elem)
self._rear = self._rear.next 弹出末元素的操作。(读者笔记:详细看书上解释)
def pop_last(self):
if self._head is None: # 是空表
raise LinkedListUnderflow("in pop_last")
p = self._head
if p.next is None: # 表中只有一个元素
e = p.elem
self._head = None
return e
while p.next.next is not None: # 直到p.next是最后结点
p = p.next
e = p.next.elem
p.next = None
self._rear = p
return e类设计的内在一致性
(读者笔记:这一小节是简单讨论类设计中的一个重要原则,值得一读。)
3.4.2 循环单链表
(读者笔记:这一段解释分析,值得一看。)
循环单链表类
(读者笔记:先抄代码吧~~)
class LCList: # 循环单链表类
def __init__(self):
self._rear = None
def is_empty(self):
return self._rear is None
def prepend(self, elem): # 前段插入
p = LNode(elem)
if self._rear is None:
p.next = p # 建立一个结点的环
self._rear = p
else:
p.next = self._rear.next
self._rear.next = p
def append(self, elem): # 尾端插入
self.prepend(elem)
self._rear = self._rear.next
def pop(self): # 前端弹出
if self._rear is None:
raise LinkedListUnderflow("in pop of CLList")
p = self._rear.next
if self._rear is p:
self._rear = None
else:
self._rear.next = p.next
return p.elem
def printall(self): # 输出表元素
if self.is_empty():
return
p = self._rear.next
while True:
print(p.elem)
if p is self._rear:
break
p = p.next3.4.3 双链表
结点操作
(读者笔记:如下的代码非常简单,但是我却没有看懂,而且我很好奇,【p.prev.next】与【p】有什么区别??可能要结合图3.15去理解)
p.next.prev = p.next
p.next.prev = p.prev这两个语句使p所指结点从表中退出,其余结点保持顺序和链接。如果要考虑前后可能无结点的情况,只需增加适当的条件判断。
双链表类
双链表的结点与单链表不同,因为结点里多了一个反向引用域。可以考虑独立定义,或者在LNode类的基础上派生。
class DLNode(LNode): # 双链表结点类
def __init__(self, elem, prev=None, next_=None):
LNode.__init__(self, elem, next_)
self.prev = prev
(读者:抄代码,暂时不求甚解,以后一定要理解!!!)
class DLList(LList1):
def __init__(self):
LList1.__init__(self)
def prepend(self, elem):
p = DLNode(elem, None, self._head)
if self._head is None:
self._rear = p
else:
p.next.prev = p
self._head = p
def append(self, elem):
p = DLNode(elem, self._rear, None)
if self._head is None: #
self._head = p
else:
p.prev.next = p
self._rear = p
def pop(self):
if self._head is None:
raise LinkedListUnderflow("in pop of DLList")
e = self._head.elem
self._head = self._head.next
if self._head is not None: # _head
self._head.prev = None
return e
def pop_last(self):
if self._head is None:
raise LinkedListUnderflow("in pop_last of DLList")
e = self._rear.elem
self._rear = self._rear.prev
if self._rear is None:
self._head = None #
else:
self._rear.next = None
return e循环双链表
(读者:这个看书吧,书上也只有叙述性的文字。)
3.4.4 两个链表操作
链表反转
顺序表中,反转表中元素的算法:
用两个下标,通过逐对交换元素位置并把下标向中间移动的方式工作,直到两个下标碰头时操作完成。
双链表也可以用如上的操作模式,双链表结点有next和prev两个引用,同时支持两个方向的**扫描操作。
单链表不支持从后向前找结点,要找前一结点,只能从头开始做,这就使算法需要O(n²)时间。
顺序表而言,改变其中元素的顺序的方法只有一种,就是在表中搬动元素。
(读者笔记:书上以下这一段,关于反转算法的一种实现方式,我认为非常巧妙,值得仔细阅读!!!)

下面的函数作为LList类的一个方法,最后把反转后的结点链赋给表对象的_head域。链表类LList1继承LList时,必须重新定义这个方法,因为它需要反转操作在完成基本工作后正确设置_rear:
def rev(self):
p = None
while self._head is not None:
q = self._head
self._head = q.next # 摘下原来的首结点
q._next = p
p = q # 将刚摘下的结点加入p引用的结点序列
self._head = p # 反转后的结点序列已经做好,重置表头链接 现实生活中的实例:
如果桌上有一摞书,一本本拿下来放到另一处,叠成另一摞。
链表排序
Python的list类型有一个sort方法,可以完成list的元素排序。如果lst的值是一个list类型的对象,lst.sort()将把lst中元素从小到大进行排序。
标准函数sorted可以对各种序列进行排序,sorted(lst)生成一个新的表(list类型的对象),其中元素是lst的元素排序的结果。
下面讨论单链表的排序问题,以及相关算法和实现。这里只准备考虑一种简单的排序算法,称为插入排序。其基本想法是:

(读者笔记:抄代码)
def list_sort(lst):
for i in range(1, len(lst)): # 开始时片段[0:1]已排序
x = lst[i]
j = i
while j > 0 and lst[j-1] > x:
lst[j] = lst[j-1] # 反序后逐个后移元素至确定插入位置
j -= 1
lst[j] = x单链表的排序算法。注意:由于这里只有next链接,扫描指针只能向下一个方向移动,不能从后向前查找结点(或找元素)。两种可能的完成排序的做法:
移动表中的元素,
调整结点之间的链接关系。
(读者笔记:抄代码)
def sort1(self):
if self._head is None:
return
crt = self._head.next # 从首节点之后开始处理
while crt is not None:
x = crt.elem
p = self._head
while p is not crt and p.elem <= x: # 跳过小元素
p = p.next
while p is not crt: # 倒换大元素,完成元素插入的工作
y = p.elem
p.elem = x
x = y
p = p.next
crt.elem = x # 回填最后一个元素
crt = crt.next考虑通过调整链接的方式实现插入排序。(读者笔记:依然是抄代码。)
def sort(self):
p = self._head
if p is None or p.next is None:
return
rem = p.next
p.next = None
while rem is not None:
p = self._head
q = None
while p is not None and p.elem <= rem.elem:
q = p
p = p.next
if q is None:
self._head = rem
else:
q.next = rem
q = rem
rem = rem.next
q.next = p3.4.5 不同链表的简单总结
3.3节和本节中,讨论时间复杂度时,用的n均指表的长度。
3.5 表的应用
(读者笔记:在这一章消耗的时间太久,先跳过本节,下次仔细阅读!!!)
3.5.1 Josephus问题和基于“数组”概念的解法
3.5.2 基于顺序表的解
3.5.3 基于循环单链表的解
本章总结
顺序表
链接表
讨论
参考文献:
1.《数据结构与算法-Python语言描述》。