kudu 的基本架构与存储结构
kudu 的基本架构与存储结构
1. 基本架构
TMaster and TServer
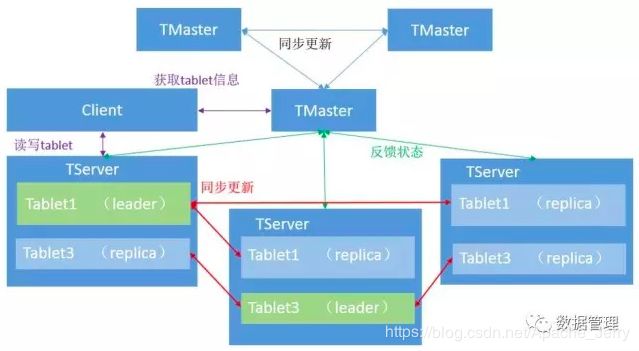
TMaster 主要用来管理元数据,即tablet 和 表的基本信息,监听TServer的状态,TMaster之间通过raft协议进行数据同步
TServer 主要用来管理tablet 。tablet 负责这一张表的某块内容的读写,接受其他tablet leader 传来的同步信息,至于什么是tablet,看下面。
2. 存储结构
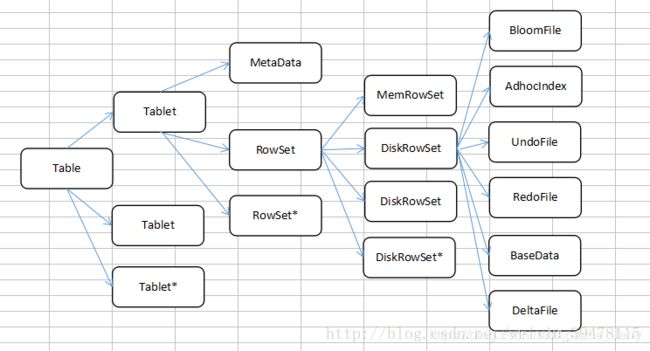
kudu的整个存储架构可以看成这样:
一张table 会分成若干个tablet ,每个tablet中会包含的是 MetaData(元信息)和 若干个RowSet,每个RowSet里面包含的是MemRowSet 和若干个DiskRowSet,其中MemRowSet负责的是存储插入和更新的数据,当MemRowSet 写满后(默认是1G或者两分钟),会刷写到DiskRowSet(磁盘中)。
DiskRowSet用于对老数据的mutation(变化)操作,例如对数据更新,合并,删除历史和无用数据,减少查询过程的IO开销。一个DiskRowSet中,包含一个BoomFile、一个Ad_hoc Index、多个UndoFIle、RedoFile、BaseData和DeltaMem
BloomFile:根据DiskRowSet中key生成一个bloom filter,用于快速模糊的定位某一个key是否在DiskRowSet中
Ad_hoc Index:是主键的索引,用于定位key在DiskRowSet中具体哪个偏移位置
BaseData:基线数据,是MemRowSet flush下来的数据,按照列存储,按照主键有序
UndoFile:增量,是BaseData之前的数据历史数据,简单解释就是,在对基线数据进行修改的时候,kudu 会跟踪所有的更新操作,并将这些操作保存到UndoFile中,超过15分钟这些数据会被删除。
RedoFile:未合并的增量,是BaseData之后的mutation记录,可以获得较新的数据。解释:有些增量修改并不会被执行,因为可能是修改太小,不能为合并 带来好处,便被保留下来等待下一次的合并。
DeltaMem:用于在内存中存储mutation记录,先写到内存中,然后写满后flush到磁盘,形成 DeltaFile
MemRowSet的实现方式是 B+树
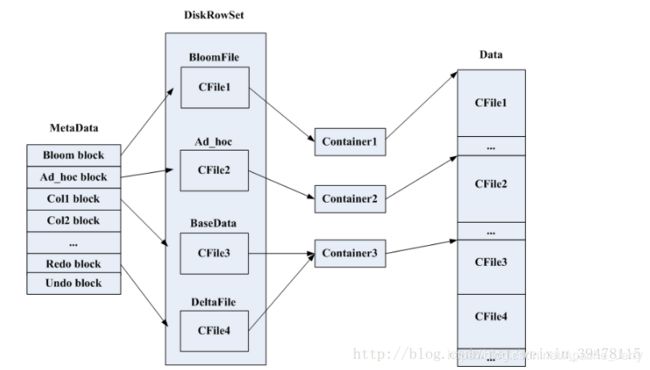
DiskRowSet的实现方式是二叉平衡树,他的内部数据组织是在内存(DeltaMem)中是B+树,在磁盘中存放在CFile文件中。
DiskRowSet的数据在磁盘上的分布情况:
3. KUDU的存储方式
kudu是一个真正的面像列式存储的数据库,表中的每一个列都是单独存放的;
kudu在建表的时候要求制定每一列的类型,为了给每一列设置制定合适的编码格式,实现更高的数据压缩比,降低IO;
kudu在存储的时候也加入timestamp这个字段,只是并不是用来更新或插入数据使用,而是在scan 的时候可以设置timestamp,查看历史数据;
kudu为了提高批量读取的效率,要求设置主键并且唯一,这样的话,kudu在更新数据的时候就不能向HBASE那样,直接插入一条新的数据就可以了,kudu的选择是将插入和更新操作分开进行;
4. KUDU的读写流程
写流程:
a)插入操作:
客户端连接到TMaster获取表的相关信息(分区和tablet信息);
找到负责写请求的tablet 所在的TServer,kudu接受客户端的请求,检查本次写操作是否符合要求;
kudu在 tablet 中所有RowSet 中,查找是否存在与待插入数据相同主键的记录,如果存在,返回错误?否则继续;
写入操作先被提交到tablet 的预写日志(WAL)上,然后根据Raft 一致性算法取得追随节点的同意后,才会被添加到其中一个tablet 的内存中,插入到MenRowSet中。(因为在MemRowSet 中支持了多版本并发控制(mvcc) ,对最近插入的行(未刷新到磁盘上的新的行)的更新和删除操作将被追加到MemRowSet中的原始行之后以生成Redo 记录的列表)。
kudu在MemRowSet 中写入新数据,在MemRowSet 达到一定大小或者时间限制(1G 或者 120s),MemRowSet 会将数据落盘,生成一个DiskRowSet 用于持久化数据 和 一个 MemRowSet 继续接受新数据的请求。
b)更新操作:
客户端连接到TMaster获取表的相关信息(分区和tablet信息);
找到负责写请求的tablet 所在的TServer,kudu接受客户端的请求,检查本次写操作是否符合要求;
因为待更新的数据可能位于MemRowSet ,也可能位于DiskRowSet 中,所以根据待更新的数据所处的位置,kudu有不同的做法:
a) 当待更新的数据位于MemRowSet时,找到它所在的行,然后将跟新操作记录在所在行中的一个mutation的链表中,在MemRowSet 数据落地的时候,kudu会将更新合并到base data,并生成undo records 用于查看历史版本的数据和MVCC, undo records 实际上也是以 DeltaFile 的形式存放;
b)当待跟新的数据位于DiskRowSet时,找到待跟新数据所在的DiskRowSet ,每个DiskRowSet 都会在内存中设置一个DeltaMemStore,将更新操作记录在DeltaMemStore中,在DeltaMemStore达到一定大小时,flush 在磁盘,形成Delta并存放在DeltaFile中。
简单说就是将基线数据BaseData 和 更新合并起来,生成新的基线数据,通过这种方式来更行。
读流程:
客户端连接TMaster 获取表的相关信息,包括分区和表中的tablet 的信息;
客户端找到 tablet 所在的TServer 以后,kudu接受读请求,并记录timestamp(没有显示指定就使用当前时间)信息;
从内存中读取数据,即是从MemRowSet 和 DeltaRowSet中读取数据,根据timestamp来找到对应的mutation链表;
从磁盘中读取数据,从metadata文件中使用boom
filter 快速模糊的判断所有候选的RowSet中是否包含此key,然后从DiskRowSet 中读取数据,实际上是根据B+树,判断key 在这些DiskRowSet 中的range 范围内,然后从metadata文件中,获取index来判断rowID 在Data中的偏移,根据读操作中的timestamp 信息判断是否需要对basedata中的数据进行回滚,从而获取数据。
5. KUDU的设计思想是基于HBASE的,那么KUDU和HBASE有什么区别呢?
这个人讲解的很透彻
https://blog.csdn.net/weixin_39478115/article/details/78470294
https://www.cnblogs.com/163yun/p/9014815.html
总结:
Kudu通过要求完整的表结构设置,主键的设定,以列式存储作为数据在磁盘上的组织方式,更新和数据分开等技巧,使得Kudu能够实现像HBase一样实现数据的随机读写之外,在HBase不太擅长的批量数据扫描(scan)具有较好的性能。而批量读数据正是olap型应用所关注的重点,正如Kudu官网主页上描述的,Kudu实现的是既可以实现数据的快速插入与实时更新,也可以实现数据的快速分析。Kudu的定位不是取代HBase,而是以降低写的性能为代价,提高了批量读的性能,使其能够实现快速在线分析。