Linux内存空间简介
32位Linux平台下进程虚拟地址空间分布如下图:
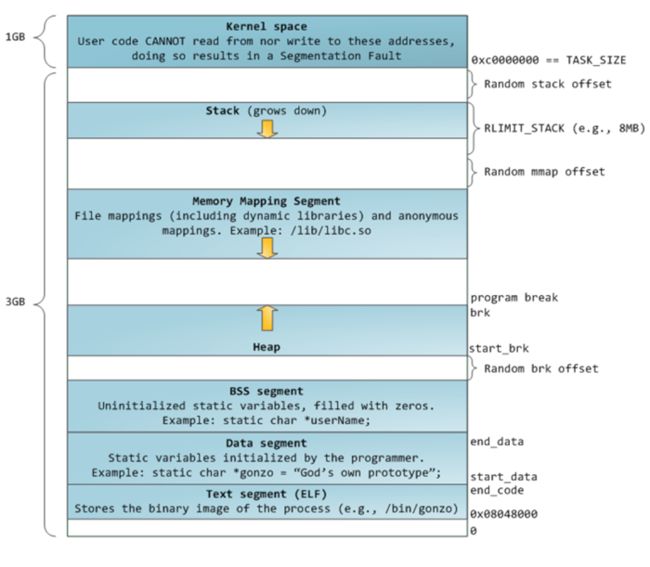
图中,0xC0000000开始的最高1G空间是内核地址空间,剩下3G空间是用户态空间。用户态空间从上到下依次为stack栈(向下增长)、mmap(匿名文件映射区)、Heap堆(向上增长)、bss数据段、数据段、只读代码段。
其中,Heap区是程序的动态内存区,同时也是C++内存泄漏的温床。
malloc、
free均发生在这个区域。本文将简单介绍下glibc在动态内存管理方面的机制,抛砖引玉,希望能和大家多多交流。
Linux提供了如下几个系统调用,用于内存分配:
brk()/sbrk() // 通过移动Heap堆顶指针brk,达到增加内存目的
mmap()/munmap() // 通过文件影射的方式,把文件映射到mmap区
这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。
那么,既然brk、mmap提供了内存分配的功能,直接使用brk、mmap进行内存管理不是更简单吗,为什么需要glibc呢?
我们知道,系统调用本身会产生软中断,导致程序从用户态陷入内核态,比较消耗资源。试想,如果频繁分配回收小块内存区,那么将有很大的性能耗费在系统调用中。因此,为了减少系统调用带来的性能损耗,glibc采用了内存池的设计,增加了一个代理层,每次内存分配,都优先从内存池中寻找,如果内存池中无法提供,再向操作系统申请。
一切计算机的问题都可以通过加层的方式解决。
glibc的内存分配回收策略
glibc中malloc内存分配逻辑如下是:
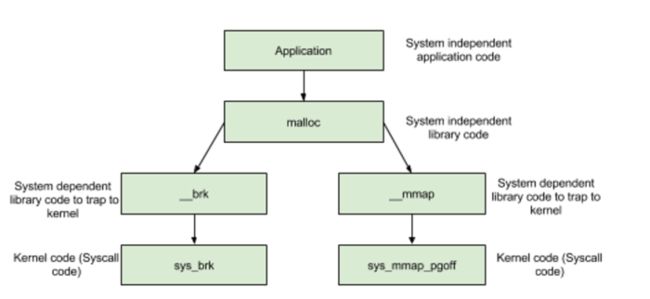
- 分配内存 <
DEFAULT_MMAP_THRESHOLD,走__brk,从内存池获取,失败的话走brk系统调用 - 分配内存 >
DEFAULT_MMAP_THRESHOLD,走__mmap,直接调用mmap系统调用
其中,DEFAULT_MMAP_THRESHOLD默认为128k,可通过mallopt进行设置。
重点看下小块内存(size > DEFAULT_MMAP_THRESHOLD)的分配,glibc使用的内存池如下图示:

内存池保存在bins这个长128的数组中,每个元素都是一双向个链表。其中:
- bins[0]目前没有使用
- bins[1]的链表称为
unsorted_list,用于维护free释放的chunk。 - bins[2,63)的区间称为
small_bins,用于维护<512字节的内存块,其中每个元素对应的链表中的chunk大小相同,均为index*8。 - bins[64,127)称为
large_bins,用于维护>512字节的内存块,每个元素对应的链表中的chunk大小不同,index越大,链表中chunk的内存大小相差越大,例如: 下标为64的chunk大小介于[512, 512+64),下标为95的chunk大小介于[2k+1,2k+512)。同一条链表上的chunk,按照从小到大的顺序排列。
chunk数据结构
 chunk结构
chunk结构
glibc在内存池中查找合适的chunk时,采用了最佳适应的伙伴算法。举例如下:
- 如果分配内存<512字节,则通过内存大小定位到smallbins对应的index上(
floor(size/8))- 如果smallbins[index]为空,进入步骤3
- 如果smallbins[index]非空,直接返回第一个chunk
- 如果分配内存>512字节,则定位到largebins对应的index上
- 如果largebins[index]为空,进入步骤3
- 如果largebins[index]非空,扫描链表,找到第一个大小最合适的chunk,如size=12.5K,则使用chunk B,剩下的0.5k放入unsorted_list中
- 遍历unsorted_list,查找合适size的chunk,如果找到则返回;否则,将这些chunk都归类放到smallbins和largebins里面
- index++从更大的链表中查找,直到找到合适大小的chunk为止,找到后将chunk拆分,并将剩余的加入到unsorted_list中
- 如果还没有找到,那么使用top chunk
- 或者,内存<128k,使用brk;内存>128k,使用mmap获取新内存
top chunk
如下图示:top chunk是堆顶的chunk,堆顶指针brk位于top chunk的顶部。移动brk指针,即可扩充top chunk的大小。当top chunk大小超过128k(可配置)时,会触发malloc_trim操作,调用sbrk(-size)将内存归还操作系统。
 chunk分布图
chunk分布图
free释放内存时,有两种情况:
- chunk和top chunk相邻,则和top chunk合并
- chunk和top chunk不相邻,则直接插入到
unsorted_list中
内存碎片
以上图chunk分布图为例,按照glibc的内存分配策略,我们考虑下如下场景(假设brk其实地址是512k):
- malloc 40k内存,即chunkA,brk = 512k + 40k = 552k
- malloc 50k内存,即chunkB,brk = 552k + 50k = 602k
- malloc 60k内存,即chunkC,brk = 602k + 60k = 662k
- free chunkA。
此时,由于brk = 662k,而释放的内存是位于[512k, 552k]之间,无法通过移动brk指针,将区域内内存交还操作系统,因此,在[512k, 552k]的区域内便形成了一个内存空洞 ---- 内存碎片。
按照glibc的策略,free后的chunkA区域由于不和top chunk相邻,因此,无法和top chunk 合并,应该挂在unsorted_list链表上。
glibc实现的一些重要结构
glibc中用于维护空闲内存的结构体是malloc_state,其主要定义如下:
struct malloc_state {
mutex_t mutex; // 并发编程下锁的竞争
mchunkptr top; // top chunk
unsigned int binmap[BINMAPSIZE]; // bitmap,加快bins中chunk判定
mchunkptr bins[NBINS * 2 - 2]; // bins,上文所述
mfastbinptr fastbinsY[NFASTBINS]; // fastbins,类似bins,维护的chunk更小(80字节的chunk链表)
...
}
static struct malloc_state main_arena; // 主arena
多线程下的竞争抢锁
并发条件下,main_arena引发的竞争将会成为限制程序性能的瓶颈所在,因此glibc采用了多arena机制,线程A分配内存时获取main_arena锁成功,将在main_arena所管理的内存中分配;此时线程B获取main_arena失败,glibc会新建一个arena1,此次内存分配从arena1中进行。
这种策略,一定程度上解决了多线程下竞争的问题;但是随着arena的增多,内存碎片出现的可能性也变大了。例如,main_arena中有10k、20k的空闲内存,线程B要获取20k的空闲内存,但是获取main_arena锁失败,导致留下20k的碎片,降低了内存使用率。
普通arena的内部结构:
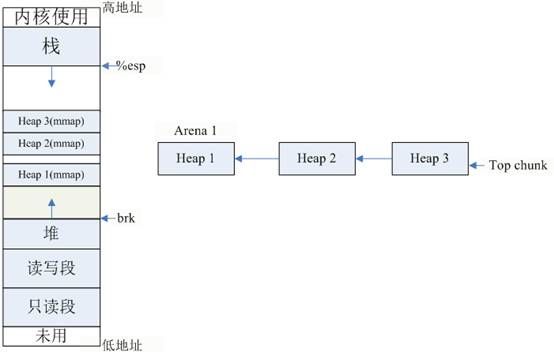
- 一个arena由多个Heap构成
- 每个Heap通过mmap获得,最大为1M,多个Heap间可能不相邻
- Heap之间有prev指针指向前一个Heap
- 最上面的Heap,也有top chunk
每个Heap里面也是由chunk组成,使用和main_arena完全相同的管理方式管理空闲chunk。
多个arena之间是通过链表连接的。如下图:
main arena和普通arena的区别
main_arena是为一个使用brk指针的arena,由于brk是堆顶指针,一个进程中只可能有一个,因此普通arena无法使用brk进行内存分配。普通arena建立在mmap的机制上,内存管理方式和main_arena类似,只有一点区别,普通arena只有在整个arena都空闲时,才会调用munmap把内存还给操作系统。
一些特殊情况的分析
根据上文所述,glibc在调用malloc_trim时,需要满足如下2个条件:
1. size(top chunk) > 128K
2. brk = top chunk->base + size(top chunk)
假设,brk指针上面的空间已经被占用,无法通过移动brk指针获得新的地址空间,此时main_arena就无法扩容了吗?
glibc的设计考虑了这样的特殊情况,此时,glibc会换用mmap操作来获取新空间(每次最少MMAP_AS_MORECORE_SIZE<1M>)。这样,main_arena和普通arena一样,由非连续的Heap块构成,不过这种情况下,glibc并未将这种mmap空间表示为Heap,因此,main_arena多个块之间是没有联系的,这就导致了main_arena从此无法归还给操作系统,永远保留在空闲内存中了。如下图示:
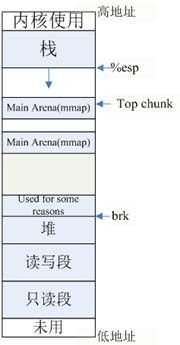
显而易见,此时根本不可能满足调用malloc_trim的条件2,即:
brk !== top chunk->base + size(top chunk),因为此时brk处于堆顶,而
top chunk->base > brk.
#include
#include
#include
#include
#include
#include
#define ARRAY_SIZE 127
char cmd[1024];
void print_info()
{
struct mallinfo mi = mallinfo();
system(cmd);
printf("\theap_malloc_total=%lu heap_free_total=%lu heap_in_use=%lu\n\
\tmmap_total=%lu mmap_count=%lu\n", mi.arena, mi.fordblks, mi.uordblks, mi.hblkhd, mi.hblks);
}
int main(int argc, char** argv)
{
char** ptr_arr[ARRAY_SIZE];
int i;
char* mmap_var;
pid_t pid;
pid = getpid();
sprintf(cmd, "ps aux | grep %lu | grep -v grep", pid);
/* mmap占据堆顶后1M的地址空间 */
mmap_var = mmap((void*)sbrk(0) + 1024*1024, 127*1024, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
printf("before malloc\n");
print_info();
/* 分配内存,总大小超过1M,导致main_arena被拆分 */
for( i = 0; i < ARRAY_SIZE; i++) {
ptr_arr[i] = malloc(i * 1024);
}
printf("\nafter malloc\n");
print_info();
/* 释放所有内存,观察内存使用是否改变 */
for( i = 0; i < ARRAY_SIZE; i++) {
free(ptr_arr[i]);
}
printf("\nafter free\n");
print_info();
munmap(mmap_var, 127*1024);
return 1;
}
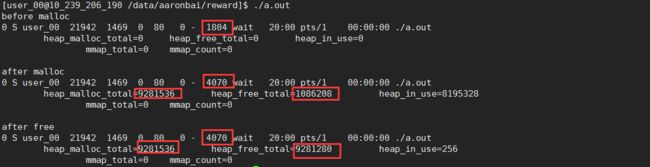
作为对比,去除掉brk上面的mmap区再次运行后结果如下:

可以看出,异常情况下(brk无法扩展),free的内存没有归还操作系统,而是留在了main_arena的unsorted_list了;而正常情况下,由于满足执行malloc_trim的条件,因此,free后,调用了sbrk(-size)把内存归还了操作系统,main_arena内存响应减少。
参考文章
- Linux 堆内存管理深入分析
- 深入剖析glibc内存管理实现及潜在问题
- 十问Linux虚拟内存管理(glibc)