基于maven的ssm分布式电商项目
最近跟着尚学堂的官网视频在学习了ssm,最后有一个Ego项目,做完这个项目后,对整个项目做个总结,错误之出欢迎指出。
一、项目目录结构介绍
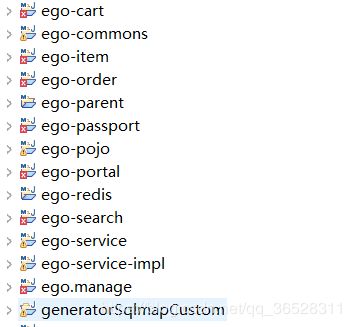
ego-cart:处理购物车业务
ego-commons:存放一些要求复用性很强的内容,比如响应结构EgoResult
ego-item:商品业务处理,比如门户菜单,商品详情
ego-order:商品订单管理
ego-parent:这个项目是通过maven进行构建,利用了maven的项目聚合,这些项目基本上都是这个项目的子项目,达到一种包版本管理目的,既版本仲裁
ego-passport:负责管理用户登陆
ego-pojo:实体类项目,项目中需要的实体类,里面的内容,基本由逆向工程生成
ego-portal:商城门户,这个商城的主页
ego-redis:redis缓存,我们整个项目的,很多地方用到了redis缓存,所以把这个功能抽取出来作为一个项目,其中,则这个redis是个redis集群
ego-search:负责商品的搜索功能
ego-service:提供者接口
ego-service-impl:提供者实现
ego-manage:后台管理,主要处理一些对商品的增删查改业务
generatorSqlmapCustom:逆向工程
二、项目总体介绍
该项目是通过maven进行构建的ssm分布式项目,由13个项目包组成,各自建立依赖,每个大的功能主体模块运行在不同的tomcat服务器上,需多台虚拟机提供服务支持,后期也需全部部署到linux服务器。
三、页面展示





四、主要涉及技术及技术产生背景
1.逆向工程:整个项目的数据库增删查改操作、实体类,均由逆向工程生成
产生背景:
mybatis与spring进行整合之后,mybatis的诸多业务都交给了spring进行管理,但是但是业务所需要的sql语句还是需要我们去编写,而对于一些对于数据库性能要求不是很高的业务,我们只需要一些简单的单表操作,通过业务装配对对象进行注入,而这些代码都是一些比较死板的,多次编写无疑增加了工作负担,影响开发效率
功能:
通过配置好逆向工程的项目配置文件,便可自动生成pojo和mapper
缺点:只能进行简单的单表查询操作,对于复杂业务优势不明显
2.nexus:私服
产生背景:
在各大安全性比较高的公司部门,处于对知识的保护作用,不允许员工上班期间通过外网与外界沟通,但是,如今的大部分项目都需要联网获取依赖资源,并且,一个项目需要有多个模块,每个模块由不同的人进行开发,这个时候就产生了局域性的nexus服务
功能:
1.为项目提供依赖资源,类似于maven中央仓库,首先在内部nexus内部查找资源,如果没有就到maven仓库进行资源获取,将资源存入本地maven参考,与传统maven项目的区别仅在于,将maven项目镜像修改为了nexus私服地址,从nexus中去获取资源
2.资源的获取不只是获取网络上的jar包,同时,同一内部网络的开发人员,可以将自己做好的项目打包放到nexus中,供其他开发人员使用
3.Dubbo:阿里的Rpc服务框架
产生背景:
数据库资源或者其他比较重要的资源,出于安全或者知识性保护考虑,即我们不想让用户直接获取重要资源,所有的资源获取都需要在提供方的同意之下进行。这就出现了一种SOA面向服务架构,我们将我们做好的业务,当成一种服务提供给用户,用户便不知道我们的具体实现,也只能使用我们允许使用的方法,Dubbbo协议便很好的支持了这点
功能:
Dubbo由三个部分组成:
consumer(消费者):用户
provider(服务方):依赖spring容器,为用户提供服务
registry(注册中心):注册中心有很多,较常用的是支持网路集群的zookeeper,在服务方进行功能注册后,将功能的代理对象提供给用户进行调用,即整个服务的稳定性与注册中心密切相关,所以我们在使用的时候,都会建立zookeeper集群,提高系统稳定性和高效性
monitor(管理者):监控消费者对服务者的调用
4.redis:NOSQL型数据库缓存
产生背景:
关系型数据库的操作效率较低,一种基于内存数据存储的高效数据库由此产生,通过关系型数据库和nosql数据库的结合使用,减轻了数据库的压力,为用户提供良好体验
功能:
将数据以字符串键值对的形式存储于内存中,在用户调用时,能够快速响应,并提供了多种持久化方案,提高数据的持久性。在用户发出请求后,系统首先会到redis缓存中查看是否有该信息,如果有便返回,如果没有,就去数据库中查找,查找到后便存储到缓存中,为了redis的存储和查询更加高效,需要建立redis集群。这里需要注意的是,我们每次在更新数据库内容时,需要同步缓存,
5.vsftpd:linux组件,提供ftp服务
产生背景:
随着互联网用户的急剧增加,用户的大量文件需要保存,保存在服务器上,势必增加服务器压力,这个时候就需要把服务器与文件的存储分离。
功能:
用户可以通过ftp协议访问服务器,在java中可以通过FTPclient对linux的文件管理服务器进行文件上传和下载操作
6.nginx:反向代理/负载均衡
产生背景:
大量文件存储在linux文件服务器上,但是文件服务器支持的是ftp协议,网络访问的通过http协议,所以在用户需要访问文件的时候,我们需要对外提供http访问服务,但是,我们又不想用户直接知道我们的资源存储位置,nginx服务器便能解决这有问题,当我们访问资源的时候,我们直接通过http访问nginx就好,由nginx为我们返回数据,这就是反向代理,即,我们不知道为我们真是服务的是谁,只有代理知道,所以我们需要配置好nginx的代理目录,从而得到用户需要的文件,并返回。nginx不仅能代理目录,也能代理访问,随着网站访问量的增加,服务器压力也不断增大,如何为tomcat减压呢?那就是集群,多个tomat为用户提供服务,所以也要求那个服务器上的内容需要一致,也就是用资源换效率,但是,一个服务器只有一个地址,用户访问的时候也只能输入一个地址,那到底如何让访问请求分布到不同的服务器进行处理,那就是,增加一个中间代理,所有请求由代理接收,由代理服务器转发,达到请求分发目的,请求转发的时候我们可以告诉nginx,哪个服务器可以增加承受一定比例的请求,这个通过配置服务器权重来达到。但是相信大家也都感觉到了这个系统的瓶颈在哪,没错,就是ngnix的稳定性决定了这个系统的稳定性,所以ngnix的稳定性架构尤为重要,另外ngnix只接收请求,具体请求是通过被选定的服务器去响应,关于负载均衡的知识还是挺多的,大家有兴趣可以多多了解
功能:
目录代理、代理请求并转发
7.jsonp:ajax跨域通信技术
产生背景:
我们在页面的很多地方都会用到ajax,但是Apache官方处于安全考虑,不允许ajax跨域访问,但是作为一个分布式项目,就必须会要求跨域访问,官方考虑到点,提供了jsonp,ajax请求确实不能跨域,但是,却可以请求js文件,jsonp就利用了这点,通过将请求伪装成js请求,由js将信息携带返回给用户,而spring官方也提供了这一支持
功能:
跨域请求
8.httpclient:由Apache提供的,通过java代码发送请求与接收响应API
产生背景:
前端页面可以通过ajax请求其他服务器的控制器,自然,当我们在编写java代码时,也是需要其他项目提供资源支持,这个时候就需要一个能通过java代码访问其他服务器控制器的功能。
功能:
通过httpclientAPI可以通过java代码,像控制器发送请求,并接收相应
9.SSO单点登陆:基于redis和cookie
产生背景:
在最开始的只有一个服务器的情况下,我们不需要考虑多个服务器之间的数据传递问题,但用户登陆之后,我们只需要把用户信息存储到session中,然后将session的id存储到用户浏览器,用来识别用户,但是如今的互联网时代,网民人数增多,服务器压力巨大,网站为了解决这个问题,建立了服务器集群,也就是分布式项目,这就涉及到各个服务器之间的信息共享问题,我们知道,当用户登陆后,如果跳转到别的项目,如何得到用户的登陆信息?那就是通过sso架构思想,之前的数据都是存储在session中,现在我们把它用redis来替换,并且,把这个登陆功能模块抽取出来作为一个验证用户信息的项目,各个项目,只需要验证通过验证cookie信息,便可以验证用户身份
功能:
多个项目,共享登陆信息
10.solr:搜索框架
产生背景:
在项目中,数据的搜索尤为常见,如果我们通过数据库的like查询语句去查询关键词,那必定是低效的,所以有了solr搜索框架,为了决绝性能问题,我们可以建立solr集群
功能:
提供数据搜索,其实solr就是一个web项目,在将数据录入后,solr会将数据进行关键词拆分,对于中文,我们需要借助IKAnalysiser,建立solr集群也即需要将solr部署到不同的tomcat内,然后通过zookeeper进行统一管理,而为了系统的稳定性更高,我们需要将建立zookeeper集群,我们必须知道,在任何一个集群中,个体的数量最好是奇数,并且有一主一备,这样的系统安全性才更高,所以我们至少建立三个zookeeper,其中一个领导者,其余两个辅助
11.mycat:数据库中间件
产生背景:
tomcat的访问压力问题,有ngnix负载均衡可以解决,那么作为性能瓶颈的元老数据库访问有没有解决方案呢,有的
功能:
我们知道数据库其实也就是底层数据结构的抽象层,而mycat是一个居于程序和数据库之间的一层抽象层,mycat的原理就是让程序访问mycat中间件,然后中间件去分发任务到数据库中执行,那我们程序如何连接到mycat呢,这个时候mycat就有一个逻辑库和逻辑表的概念,逻辑库就是mycat的数据库,逻辑表就是mycat的数据库表,每个逻辑表至少有要三个datanode,这个datanode其实就是我们的实体数据库,只不过在mycat的概念中把这个库抽象成了它的一个表,所以在mycat逻辑库中建了一个库也就是建立一个逻辑表,也就是说由mycat对多个数据库进行管理,分配相应的任务,任务的分配有多种规则,有分库或者分表,分库较为简单,也就是以每个datanode为单位,进行数据库的操作,对数据库的操作又有多种方案,比如,如果需要执行某条sql语句,默认是每个库都执行,还可以选择通过C2C32散列算法散列执行,并且mycat有有读写分离的概念,读写分离依赖的就是mysql数据库本身就具有的主从功能,我们需要开启这个主从功能,并做一定的配置,mysql主从功能的原理就是,从机会通过不断的监听主机的日志,一旦日志更新,从机也会根据日志文件执行相应的操作,从而达到与主机同步的目的,mycat默认,主机执行增删改操作,从机执行查操作。
五、个人感悟与总结
这个项目是刚学完ssm后做的,在学习ssm过程中,总是感觉这么多的配置文件,真的是在简化我们的开发吗?以前总听过,用了框架,我们就可以把我们的经历集中在业务层,但是始终没有一个体会,做完这个项目后,终于体会到了开发的便捷。
项目过程中遇到了很多问题,特别是第一次接触分布式架构,感觉这个分布式架构真的麻烦,不过项目做着做着就感觉,分布式、微服务思想真的很好,增加了代码的复用性,使每个业务更加集中化处理,整个项目开发的思路更加清晰,确实适用于团队开发。
最后感谢视频里的老师,让我学到很多