机器学习中的分类器:感知机、逻辑回归、支持向量机
深度神经网络(Deep Neural Networks,DNN)是深度学习的基础,由于神经网路是基于感知机模型的扩展,因此多层感知机(Multi-Layer perceptron,MLP)就可以看作是深度神经网络。在深度学习中,用于分类的卷积神经网络(Convolutional Neural Networks, CNN),一般都会在全连接层(FC)之后使用softmax分类器,softmax函数可以看作是logistic函数(Sigmoid)的一般形式。当然,也有例如目标检测的经典网络RCNN,是将感兴趣区域提取的CNN特征输入到支持向量机(SVM)进行分类。为了更好地理解深度学习中的内容,以及发现深度学习对机器学习的继承性,我将上面描述的感知机(Perceptron)、逻辑回归(Logistic Regression,LR)、支持向量机(Support Vector Machine, SVM)这三种基础的分类器进行了整理。这是一篇需要数学基础的总结,做好迎接大量公式的准备吧。
目录
- 感知机
- 感知机模型
- 感知机的训练过程
- 感知机的局限性和发展
- 神经网络的反向传播算法
- 总结
- 逻辑回归
- 模型分析
- 损失函数
- softmax多分类
- 逻辑回归与神经网络的关系
- 总结
- 支持向量机
- 线性可分支持向量机
- 软间隔支持向量机
- SVM vs 感知机和逻辑回归
- 总结
感知机
1957年,美国神经学家Frank Rosenblatt提出了可以模拟人类感知能力的机器,并称之为“感知机”,研究成果于1958年发表在《The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain》。感知机是人工神经网络的进一步发展,人工神经网络的概念及人工神经元的数学模型是1943年在《A logical calculus of the ideas immanent in nervous activity》论文中提出。感知机可以被视为一种最简单形式的前馈神经网络(即每个神经元只与前一层的神经元相连,各层间没有反馈),是一种二元线性分类器。二元线性分类器意味着,分类器尝试对于输入的多维数据找到一个超平面(二维数据是找到一条直线),能够把所有的二元类别分隔开。当然,如果数据不是线性可分的时候,感知机的局限性就显现出来了。
感知机模型
为了模拟神经细胞的行为,神经元模型提出了与之对应的基础概念,如权重(突触)、偏置(阈值)及激活函数(细胞体)。感知机由两层神经元组成,输入层接收外界输入信号后传递给输出层。假设输入的m个样本数据可以表示为: ( x 1 ( 1 ) , x 2 ( 1 ) , . . . x n ( 1 ) , y 1 ) (x_1^{(1)}, x_2^{(1)}, ...x_n^{(1)},y_1) (x1(1),x2(1),...xn(1),y1), ( x 1 ( 2 ) , x 2 ( 2 ) , . . . x n ( 2 ) , y 2 ) (x_1^{(2)}, x_2^{(2)}, ...x_n^{(2)}, y_2) (x1(2),x2(2),...xn(2),y2),… ( x 1 ( m ) , x 2 ( m ) , . . . x n ( m ) , y m ) (x_1^{(m)}, x_2^{(m)}, ...x_n^{(m)}, y_m) (x1(m),x2(m),...xn(m),ym),其中向量 x \pmb x xxx有n维特征, y \pmb y yyy每一维限制在两个取值中,代表着样本的类别。那么感知机需要预测的输出为:一类样本 w 1 x 1 + . . . + w n x n + θ > 0 w_{1}x_1 + ... + w_{n}x_{n} + \theta > 0 w1x1+...+wnxn+θ>0,另一类样本 w 1 x 1 + . . . + w n x n + θ < 0 w_{1}x_1 + ... + w_{n}x_{n} + \theta < 0 w1x1+...+wnxn+θ<0。再经过一个神经元激活函数, s i g n ( x ) = { − 1 x < 0 1 x ≥ 0 sign(x)= \begin{cases} -1& {x<0}\\ 1& {x\geq 0} \end{cases} sign(x)={−11x<0x≥0。在 θ \theta θ 处增加一个特征 x 0 = 1 x_0=1 x0=1,这样权重和阈值的学习统一为权重的学习,得到分类结果 y p r e d = s i g n ( w ∙ x ) y_{pred} = sign(\pmb w \bullet \pmb x) ypred=sign(www∙xxx)。上述激活函数可以保证,在预测正确的时候 y p r e d × y ≥ 0 y_{pred}×y \geq 0 ypred×y≥0。感知机结构如下图所示:

感知机的训练过程
感知机的训练过程较为简单,基本思想是:若感知机对训练样本 ( x ( i ) , y i ) (\pmb x^{(i)}, y_i) (xxx(i),yi) 预测正确,则感知机不发生变化,否则将根据错误的程度进行权重调整。感知机的损失函数是 J ( w ) = − ∑ x ( i ) ∈ M y i w ( i ) ∙ x ( i ) J(w) = - \sum\limits_{x^{(i)} \in M}y_i\pmb w^{(i)} \bullet \pmb x^{(i)} J(w)=−x(i)∈M∑yiwww(i)∙xxx(i),其中M是所有误分类的数据的集合,即当预测正确的时候损失函数为0,只有当预测错误的时候损失函数是一组正数的和。由于符号函数的不连续性,这里没有使用标准的均方误差。误差函数的优化问题可以由梯度下降法或者牛顿法来解决,随机梯度下降每次仅仅需要使用一个误分类的数据来更新梯度,用损失函数对样本 i i i 的权重向量求偏导 ∂ ∂ w J ( w ) = − y i x ( i ) \frac{\partial}{\partial w}J(w) = - y_i x^{(i)} ∂w∂J(w)=−yix(i),用该梯度对权重进行更新 w = w + α y i x ( i ) w = w + \alpha y_ix^{(i)} w=w+αyix(i),其中 α \alpha α 为学习率。
感知机的局限性和发展
从上图可以看出,感知机只有输出层神经元进行激活函数处理,即只拥有一层功能神经元,其学习能力非常有限。如果是线性可分的模型,感知机的学习过程一定会收敛,最后求得适当的权向量;否则感知机的学习过程将会发生震荡,权值难以稳定。“与”、“或”、“非”问题感知机都可以解决,但是无法学习比较复杂的非线性模型,像“异或”问题。因此DNN在感知机的基础上做了扩展,主要有以下三点:
- 增加了隐藏层,增强了模型的表达能力和非线性;
- 输出层的神经元数量增多,可以更灵活地处理分类问题;
- 对激活函数做了修改,处理能力有限的符号函数用sigmoid函数进行替换。
参考链接:https://www.cnblogs.com/pinard/p/6418668.html
神经网络的反向传播算法
尽管DNN的学习能力比单层感知机强得多,但是训练多层网络比单层网络也变得困难。反向传播(Backpropagation,BP)算法是一种与最优化方法(如梯度下降法)结合使用的,训练神经网络最有效的算法。1974年哈佛大学的Paul Werbos在论文《Beyond regression: new fools for prediction and analysis in the behavioral sciences》中发明了BP算法,但是由于当时正值神经外网络低潮期,并未受到应有的重视。反向传播算法的几个特点:
- 通常被认为是一种监督学习方法:要求有对每个输入值期望得到的已知输出,来计算损失函数的梯度。然而,它也用在一些无监督网络(如自动编码器)中。
- 用链式法则对每层迭代计算梯度,是多层前馈网络的Delta规则(权值的修正量等于误差乘以输入)的推广。
- 要求人工神经元的激活函数可微。
算法流程:
输入:神经网络结构(各层神经元数量及网络层数L),批量m个样本,损失函数,sigmoid激活函数用 σ \sigma σ表示,迭代步长(学习率) α \alpha α,最大迭代次数MAX,停止迭代阈值为ϵ。
输出:权重矩阵 w \pmb w www和偏置向量 b \pmb b bbb。
(1)初始化网络权值(通常是小的随机值)。
(2)for iter in 1 to Max:
(2-1)for i in 1 to m:
- 输入样本 x ( i ) x^{(i)} x(i);
- for l l l = 2 to L:进行前向传播算法计算隐藏层的输出;
- 通过损失函数计算输出层的误差;
- for l l l = L-1 to 2:进行反向传播算法计算隐藏层的误差;
(2-2)for l l l = 2 to L,更新第 l l l层的权重和偏置。
(2-3)如果所有的 w \pmb w www 和 b \pmb b bbb 的变化值都小于停止迭代阈值ϵ,则跳出迭代循环到步骤(3)。
(3)输出更新后的权重矩阵 w \pmb w www和偏置向量 b \pmb b bbb。
由于网络隐藏层输出的真实值无法求得,所以反向传播算法主要是解决了隐藏层的误差计算,只要根据误差每一层的权重更新便很容易通过求梯度获得,推导过程如下:

- 前向传播计算 l l l 层输出: o u t l = σ ( n e t l ) = σ ( W l o u t l − 1 + b l ) out^l = \sigma(net^l) = \sigma(W^lout^{l-1} + b^l) outl=σ(netl)=σ(Wloutl−1+bl)
- 误差函数使用最常见的均方差来度量损失: J ( W , b , x , y ) = 1 2 ∣ ∣ o u t L − y ∣ ∣ 2 2 J(W,b,x,y) = \frac{1}{2}||out^L-y||_2^2 J(W,b,x,y)=21∣∣outL−y∣∣22
由于输出层可能有多个神经元,如上图所示,则最后一层的损失是多个神经元损失的和: E t o t a l = ∑ 1 2 ( o u t L − y ) 2 = E o 1 + E o 2 E_{total} = \sum \frac{1}{2}(out^L-y)^2=E_{o1}+E_{o2} Etotal=∑21(outL−y)2=Eo1+Eo2 - 计算输出层的权值更新,以 w 5 w_5 w5 为例(链式法则):
∂ E t o t a l ∂ w 5 = ∂ E t o t a l ∂ o u t o 1 ∗ ∂ o u t o 1 ∂ n e t o 1 ∗ ∂ n e t o 1 ∂ w 5 \frac{\partial E_{total}}{\partial w_5}=\frac{\partial E_{total}}{\partial out_{o1}}*\frac{\partial out_{o1}}{\partial net_{o1}}*\frac{\partial net_{o1}}{\partial w_5} ∂w5∂Etotal=∂outo1∂Etotal∗∂neto1∂outo1∗∂w5∂neto1
其中,
由 于 n e t o 1 = o u t h 1 ∗ w 5 + o u t h 2 ∗ w 6 + b 2 , 可 得 ∂ n e t o 1 ∂ w 5 = o u t h 1 ( 前 向 传 播 已 经 求 得 ) 。 由于net_{o1}=out_{h_1}*w_5+out_{h_2}*w_6+b_2 ,可得\frac{\partial net_{o1}}{\partial w_5}=out_{h_1}(前向传播已经求得)。 由于neto1=outh1∗w5+outh2∗w6+b2,可得∂w5∂neto1=outh1(前向传播已经求得)。
由 于 o u t o 1 = σ ( n e t o 1 ) = 1 1 + e − n e t o 1 , 可 得 ∂ o u t o 1 ∂ n e t o 1 = o u t o 1 ∗ ( 1 − o u t o 1 ) 。 ( 利 用 s i g m o i d 函 数 导 数 f ′ ( x ) = f ( x ) ( 1 − f ( x ) ) ) 由于out_{o1}=\sigma (net_{o1})=\frac {1}{1+e^{-net_{o1}}},可得\frac{\partial out_{o1}}{\partial net_{o1}}=out_{o1}*(1-out_{o1})。(利用sigmoid函数导数f^{'}(x)=f(x)(1-f(x))) 由于outo1=σ(neto1)=1+e−neto11,可得∂neto1∂outo1=outo1∗(1−outo1)。(利用sigmoid函数导数f′(x)=f(x)(1−f(x)))
由 于 E t o t a l = 1 2 ( o u t o 1 − t a r g e t o 1 ) 2 + 1 2 ( o u t o 2 − t a r g e t o 2 ) 2 , 可 得 ∂ E t o t a l ∂ o u t o 1 = o u t o 1 − t a r g e t o 1 。 由于E_{total}= \frac{1}{2}(out_{o1}-target_{o1})^2+ \frac{1}{2}(out_{o2}-target_{o2})^2,可得\frac{\partial E_{total}}{\partial out_{o1}}=out_{o1}-target_{o1}。 由于Etotal=21(outo1−targeto1)2+21(outo2−targeto2)2,可得∂outo1∂Etotal=outo1−targeto1。
可以将输出层的误差表示为: δ o 1 = ∂ E t o t a l ∂ o u t o 1 ∗ ∂ o u t o 1 ∂ n e t o 1 , 则 ∂ E t o t a l ∂ w 5 = δ o 1 ∗ o u t h 1 \delta_{o1}=\frac{\partial E_{total}}{\partial out_{o1}}*\frac{\partial out_{o1}}{\partial net_{o1}},则\frac{\partial E_{total}}{\partial w_5}=\delta_{o1}*out_{h_1} δo1=∂outo1∂Etotal∗∂neto1∂outo1,则∂w5∂Etotal=δo1∗outh1
同理对于 w 6 w_6 w6 有 ∂ E t o t a l ∂ w 6 = δ o 1 ∗ o u t h 2 \frac{\partial E_{total}}{\partial w_6}=\delta_{o1}*out_{h_2} ∂w6∂Etotal=δo1∗outh2,对 w 7 w_7 w7 有 ∂ E t o t a l ∂ w 7 = δ o 2 ∗ o u t h 1 \frac{\partial E_{total}}{\partial w_7}=\delta_{o2}*out_{h_1} ∂w7∂Etotal=δo2∗outh1,对 w 8 w_8 w8 有 ∂ E t o t a l ∂ w 8 = δ o 2 ∗ o u t h 2 \frac{\partial E_{total}}{\partial w_8}=\delta_{o2}*out_{h_2} ∂w8∂Etotal=δo2∗outh2。
那么更新 w 5 w_5 w5 的值: w 5 + = w 5 − α ∗ ∂ E t o t a l ∂ w 5 w_5^+=w_5-\alpha *\frac{\partial E_{total}}{\partial w_5} w5+=w5−α∗∂w5∂Etotal - 计算隐藏层的权值更新,以 w 1 w_1 w1 为例(链式法则):
∂ E t o t a l ∂ w 1 = ∂ E t o t a l ∂ o u t h 1 ∗ ∂ o u t h 1 ∂ n e t h 1 ∗ ∂ n e t h 1 ∂ w 1 \frac{\partial E_{total}}{\partial w_1}=\frac{\partial E_{total}}{\partial out_{h_1}}*\frac{\partial out_{h_1}}{\partial net_{h_1}}*\frac{\partial net_{h_1}}{\partial w_1} ∂w1∂Etotal=∂outh1∂Etotal∗∂neth1∂outh1∗∂w1∂neth1
类似上面的推导,可以直接得到 ∂ n e t h 1 ∂ w 1 = i 1 \frac{\partial net_{h_1}}{\partial w_1}=i_1 ∂w1∂neth1=i1, ∂ o u t h 1 ∂ n e t h 1 = o u t h 1 ∗ ( 1 − o u t h 1 ) \frac{\partial out_{h_1}}{\partial net_{h_1}}=out_{h_1}*(1-out_{h_1}) ∂neth1∂outh1=outh1∗(1−outh1)。
但是损失函数是由不同的支路求得的,所以 ∂ E t o t a l ∂ o u t h 1 = ∂ E o 1 ∂ o u t h 1 + ∂ E o 2 ∂ o u t h 1 \frac{\partial E_{total}}{\partial out_{h_1}}=\frac{\partial E_{o1}}{\partial out_{h_1}}+\frac{\partial E_{o2}}{\partial out_{h_1}} ∂outh1∂Etotal=∂outh1∂Eo1+∂outh1∂Eo2
其中, ∂ E o 1 ∂ o u t h 1 = ∂ E o 1 ∂ o u t o 1 ∗ ∂ o u t o 1 ∂ n e t o 1 ∗ ∂ n e t o 1 ∂ o u t h 1 = δ o 1 ∗ w 5 \frac{\partial E_{o1}}{\partial out_{h_1}}=\frac{\partial E_{o1}}{\partial out_{o1}}*\frac{\partial out_{o1}}{\partial net_{o1}}*\frac{\partial net_{o1}}{\partial out_{h_1}}=\delta_{o1}*w_5 ∂outh1∂Eo1=∂outo1∂Eo1∗∂neto1∂outo1∗∂outh1∂neto1=δo1∗w5
同理, ∂ E o 2 ∂ o u t h 1 = δ o 2 ∗ w 6 \frac{\partial E_{o2}}{\partial out_{h_1}}=\delta_{o2}*w_6 ∂outh1∂Eo2=δo2∗w6
∂ E t o t a l ∂ w 1 = ( δ o 1 ∗ w 5 + δ o 2 ∗ w 6 ) ∗ o u t h 1 ∗ ( 1 − o u t h 1 ) ∗ i 1 = δ h 1 ∗ i 1 \frac{\partial E_{total}}{\partial w_1}=(\delta_{o1}*w_5+\delta_{o2}*w_6)*out_{h_1}*(1-out_{h_1})*i_1=\delta_{h1}*i_1 ∂w1∂Etotal=(δo1∗w5+δo2∗w6)∗outh1∗(1−outh1)∗i1=δh1∗i1
接下来的更新方法相同。
参考链接:https://www.cnblogs.com/charlotte77/p/5629865.html
总结
可以看出,如果网络有多个隐藏层的话,隐藏层的误差有一种递归计算的形式,前一层的误差依赖于后一层的误差,再结合本层的输出和输入最后得到梯度值。根据这种规律计算出误差之后,参数的更新就变得简单起来。尽管从感知机到神经网络,增加网络层数使得表达能力更强,但是这样的网络训练仍然会带来梯度消失和梯度爆炸等问题(现在就可以从反向传播的公式清晰地看出来啦),优化过程容易陷入局部极小值,出现过拟合或者欠拟合问题。因此,神经网络逐渐发展了针对此类问题的解决方法。
逻辑回归
逻辑回归(logistic函数)的分类 vs 神经网络的sigmoid激活函数与softmax分类器的分类,这两者在刚接触的时候就一直觉得知识点联系很大,数学原理相似但又是两个不同的分类模型。所以,为了弄清楚这两者之间的联系,再回顾一下机器学习中的逻辑回归。逻辑回归最早由统计学家David Cox在他1958年的论文《The regression analysis of binary sequences》中提出来的。虽然逻辑回归用来处理分类任务,但其实是在回归任务上发展的分类任务,通过回归拟合样本属于某一类别的概率,然后通过限定阈值或其他方式将其贴上标签。
逻辑回归是当前业界比较常用的机器学习方法,它与多元线性回归同属一个家族,即广义线性模型。由于模型的学习方式,Logistic 回归的预测结果也可以用作给定数据实例属于类 0 或类 1 的概率,这对于需要为预测结果提供更多理论依据的问题非常有用。与线性回归类似,当删除与输出变量无关以及彼此之间非常相似或相关的属性后,Logistic 回归的效果更好。该模型学习速度快,对二分类问题十分有效。
像线性回归一样,Logistic回归的目的也是找到每个输入变量的权重系数值。但不同的是,还需找一个单调可微函数将分类任务的真实标记 y 与线性回归模型的预测值联系起来。Logistic回归舍弃了用单位阶跃函数进行二分类标签的映射,而是利用了能在一定程度上近似它的替代函数,所以输出的预测结果是通过logistic非线性函数变换而来的。假设数据服从伯努利分布(0-1分布),通过极大化似然函数的方法,运用梯度下降来求解参数,达到将数据二分类的目的。
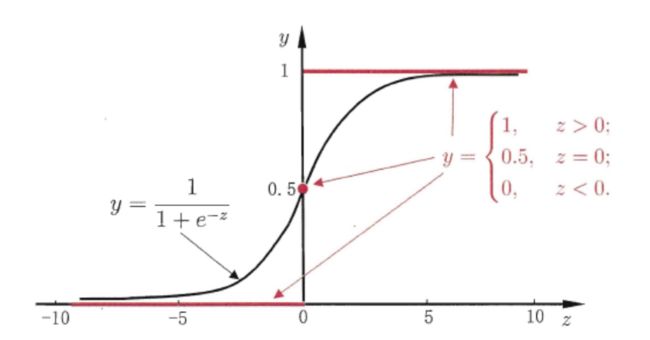
模型分析
线性回归: y = w T x + b y = \pmb w^T\pmb x+b y=wwwTxxx+b
经过对数几率函数变换: y = 1 1 + e − ( w T x + b ) y = \frac {1}{1+e^{-(w^Tx+b)}} y=1+e−(wTx+b)1,对数几率函数是任意阶可导的凸函数,许多数值优化算法都可以求出其最优解。
对数几率: l n y 1 − y = w T x + b ln \frac {y}{1-y} = \pmb w^T\pmb x+b ln1−yy=wwwTxxx+b,y 代表正样本的可能性,1-y 代表负样本的可能性。
如果 y 1 − y ≥ 1 \frac {y}{1-y}\geq 1 1−yy≥1,即 y ≥ 0.5 y\geq 0.5 y≥0.5,则认为输出的为类 1;否则 y 1 − y < 1 \frac {y}{1-y}<1 1−yy<1,则认为输出的为类 0。
决策边界: w T x + b = 0 \pmb w^T\pmb x+b = 0 wwwTxxx+b=0
将 y 视为类后验概率估计 p ( y = 1 ∣ x ) p(y=1|\pmb x) p(y=1∣xxx),则 1-y 可以视为 p ( y = 0 ∣ x ) p(y=0|\pmb x) p(y=0∣xxx),对数几率可写为: l n p ( y = 1 ∣ x ) p ( y = 0 ∣ x ) = w T x + b ln \frac {p(y=1|\pmb x)}{p(y=0|\pmb x)} = \pmb w^T\pmb x+b lnp(y=0∣xxx)p(y=1∣xxx)=wwwTxxx+b
显然有: p ( y = 1 ∣ x ) = e w T x + b 1 + e w T x + b = π ( x ) p(y=1|\pmb x)= \frac {e^{w^Tx+b}}{1+e^{w^Tx+b}}=\pi(x) p(y=1∣xxx)=1+ewTx+bewTx+b=π(x), p ( y = 0 ∣ x ) = 1 1 + e w T x + b = 1 − π ( x ) p(y=0|\pmb x)= \frac {1}{1+e^{w^Tx+b}}=1-\pi(x) p(y=0∣xxx)=1+ewTx+b1=1−π(x)
为了使每个样本属于其真实标记的概率越大越好,使用极大似然法来估计 w \pmb w www 和 b b b。
似然函数: Π i = 1 m [ π ( x ( i ) ) ] y ( i ) [ 1 − π ( x ( i ) ) ] 1 − y ( i ) \Pi_{i=1}^m[\pi(x^{(i)})]^{y^{(i)}} [1-\pi(x^{(i)})]^{1-y^{(i)}} Πi=1m[π(x(i))]y(i)[1−π(x(i))]1−y(i)
对数似然函数:
L ( w ) = log Π i = 1 m [ π ( x ( i ) ) ] y ( i ) [ 1 − π ( x ( i ) ) ] 1 − y ( i ) = ∑ i = 1 m [ y ( i ) log π ( x ( i ) ) + ( 1 − y ( i ) ) log ( 1 − π ( x ( i ) ) ) ] L(w)=\log \Pi_{i=1}^m[\pi(x^{(i)})]^{y^{(i)}} [1-\pi(x^{(i)})]^{1-y^{(i)}} =\sum_{i=1}^m[y^{(i)}\log\pi(x^{(i)})+(1-y^{(i)})\log(1-\pi(x^{(i)}))] L(w)=logΠi=1m[π(x(i))]y(i)[1−π(x(i))]1−y(i)=i=1∑m[y(i)logπ(x(i))+(1−y(i))log(1−π(x(i)))]
损失函数
最大化似然函数等价于求 − L ( w ) -L(w) −L(w)的极小值,即二值交叉熵损失(binary cross entropy):
J ( w ) = − 1 m ∑ i = 1 m ( y ( i ) log π ( x ( i ) ) + ( 1 − y ( i ) ) log ( 1 − π ( x ( i ) ) ) ) J(w)=-{1\over m}\sum_{i=1}^m\big(y^{(i)}\log \pi(x^{(i)})+(1-y^{(i)})\log (1-\pi(x^{(i)}))\big) J(w)=−m1i=1∑m(y(i)logπ(x(i))+(1−y(i))log(1−π(x(i))))
将上述公式对权重求偏导:
∂ ∂ w j J ( w ) = 1 m ∑ i = 1 m ( π ( x ( i ) ) − y ( i ) ) x j ( i ) \frac{\partial}{\partial w_{j}}J(w) ={1\over m}\sum_{i=1}^{m}(\pi(x^{(i)})-y^{(i)})x_j^{(i)} ∂wj∂J(w)=m1i=1∑m(π(x(i))−y(i))xj(i)
梯度下降公式为:
w j + = w j − α 1 m ∑ i = 1 m ( π ( x ( i ) ) − y ( i ) ) x j ( i ) w_j ^+= w_j-\alpha{1\over m}\sum_{i=1}^{m}(\pi(x^{(i)})-y^{(i)})x_j^{(i)} wj+=wj−αm1i=1∑m(π(x(i))−y(i))xj(i)
softmax多分类
二项逻辑回归的参数估计法可以推广到多项逻辑回归,即softmax(或称归一化指数函数,是逻辑函数的一种推广),此时有:
π ( x ) c = e w c T ⋅ x ∑ k = 1 C e w k T ⋅ x \pi(x)_c=\frac{e^{w_c^T\cdot x}}{\sum_{k=1}^C e^{w_k^T \cdot x}} π(x)c=∑k=1CewkT⋅xewcT⋅x
极大似然估计: L ( w ) = ∏ i = 1 n π ( x ( i ) ) y ( i ) L(w)=\prod_{i=1}^n \pi(x^{(i)})^{y^{(i)}} L(w)=∏i=1nπ(x(i))y(i)
第 i 个样本的多类交叉熵损失:
J ( w ) = − ∑ k = 1 C ( y k ( i ) log π ( x ( i ) ) k ) J(w)=-\sum_{k=1}^C\big(y_k^{(i)}\log \pi(x^{(i)})_k) J(w)=−k=1∑C(yk(i)logπ(x(i))k)
逻辑回归与神经网络的关系
- 逻辑回归与感知机都为二元线性分类器,训练方法都是使用梯度下降,但是二者的激活函数分别为sigmoid函数和sign函数,输出类别分别为0/1和-1/1。
- 上述DNN中使用了sigmoid函数,但是损失函数用的是均值平方差损失(Mean Square Error,MSE);而逻辑回归使用的是交叉熵损失(Cross Entropy,CE)。在使用sigmoid激活函数时,MSE Loss求得的梯度包含σ′(x),因此存在反向传播收敛速度慢的问题;而CE Loss的梯度不包含σ′(z)。通常情况下,在使用sigmoid激活函数时,利用CE Loss肯定比MSE Loss效果更好。
- 实际上,可以将Logistic Regression看做是仅含有一个神经元的单层的神经网络。
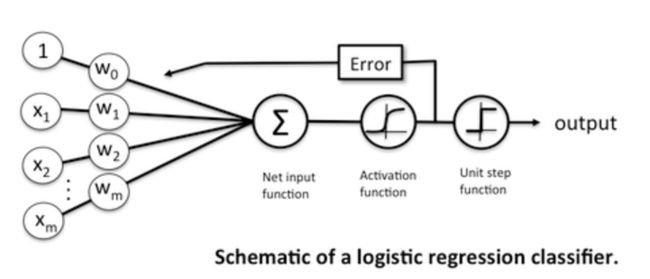
总结
LR不仅预测出类别,还可得到近似概率预测,可以做排序模型。训练快,在使用特征工程后效果更好,并且添加特征简单。容易使用和解释,计算代价低,对时间和内存需求较为高效。但是容易欠拟合(增加特征维度来解决),分类精度不高,而且只能处理两分类问题。过拟合时加入正则化(L1和L2惩罚)。
参考链接:
[1] https://www.cnblogs.com/makefile/p/logistic-regression.html
[2] https://zhuanlan.zhihu.com/p/56900935
支持向量机
支持向量的概念早在二十世纪六十年代就已经出现,而支持向量机是Cortes和Vapnik在1995年的论文《Support vector networks》中正式发表。SVM是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。随着训练数据的复杂,支持向量机学习方法也由简至繁的发展,简单模型是复杂模型的基础,也是复杂模型的特殊情况。当训练数据线性可分时,通过硬间隔最大化,学习一个线性的分类器;当训练数据近似线性可分时,通过软间隔最大化,也学习一个线性的分类器;当训练数据线性不可分时,通过使用核技巧和软间隔最大化,学习非线性支持向量机。
线性可分支持向量机
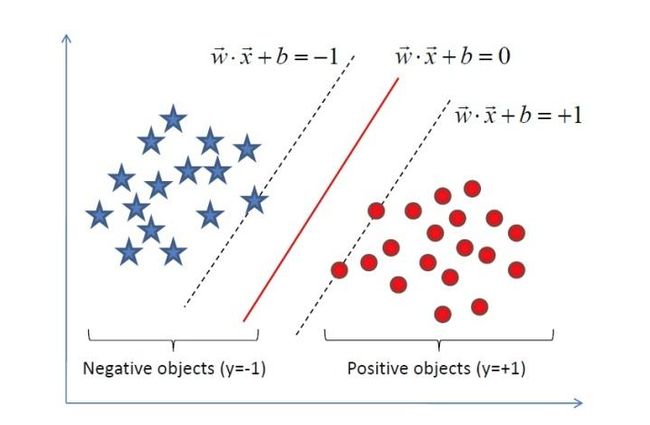
前面提到过,二元线性分类器尝试对于输入的多维数据划分一个超平面,将所有不同类别的样本分隔开。但是,这样的超平面可能有很多个,感知机利用误分类最小的策略,求得分类超平面;而支持向量机利用最大间隔求最优的决策面。显然,这是一个最优化问题,因此我们需要构造目标函数和优化对象。在线性SVM算法中,目标函数是"分类间隔",优化对象是决策面。
- 决策面: w T x + b = 0 \pmb w^T\pmb x+b=0 wwwTxxx+b=0,其中 w = ( w 1 , w 2 , . . . , w n ) \pmb w=(w_1,w_2,...,w_n) www=(w1,w2,...,wn)为超平面的法向量, b b b为截距。
- 几何间隔:给定直线 A x + B y + C = 0 Ax+By+C=0 Ax+By+C=0,由点到直线的距离公式 d = ∣ A x + B y + C A 2 + B 2 ∣ d=|\frac{Ax+By+C}{\sqrt{A^2+B^2}}| d=∣A2+B2Ax+By+C∣,可以得到多维空间中点到决策面的距离为 ∣ w T x + b ∣ ∣ ∣ w ∣ ∣ \frac{|w^Tx+b|}{||w||} ∣∣w∣∣∣wTx+b∣。假设正样本标记为1,负样本标记为-1,那么样本的几何间隔 γ i = y i ( ( w ∣ ∣ w ∣ ∣ ) T x i + b ∣ ∣ w ∣ ∣ ) \gamma_i=y_i((\frac{w}{||w||})^Tx_i+\frac{b}{||w||}) γi=yi((∣∣w∣∣w)Txi+∣∣w∣∣b)。训练集对于超平面的几何间隔为所有样本几何间隔的最小值, γ = min i = 1 , 2 , . . . , m γ i \gamma=\min \limits_{i=1,2,...,m}\gamma_i γ=i=1,2,...,mminγi
- 硬间隔最大化:可以表示为下面的约束最优化问题
max w , b γ , s . t . y i ( ( w ∣ ∣ w ∣ ∣ ) T x i + b ∣ ∣ w ∣ ∣ ) ≥ γ , i = 1 , 2 , . . . , m \max \limits_{w,b}\space\space \gamma\space,\space\space s.t. \space\space y_i((\frac{w}{||w||})^Tx_i+\frac{b}{||w||})\geq \gamma \space,i=1,2,...,m w,bmax γ , s.t. yi((∣∣w∣∣w)Txi+∣∣w∣∣b)≥γ ,i=1,2,...,m
由于函数间隔 γ \gamma γ并不影响最优化问题的解,因此等价于:
max w , b 1 ∣ ∣ w ∣ ∣ , s . t . y i ( w T x i + b ) − 1 ≥ 0 , i = 1 , 2 , . . . , m \max \limits_{w,b}\space\space \frac{1}{||w||}\space,\space\space s.t. \space\space y_i(w^Tx_i+b)-1\geq 0 \space,i=1,2,...,m w,bmax ∣∣w∣∣1 , s.t. yi(wTxi+b)−1≥0 ,i=1,2,...,m
最大化 1 ∣ ∣ w ∣ ∣ \frac{1}{||w||} ∣∣w∣∣1和最小化 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}||w||^2 21∣∣w∣∣2是等价的,最终得到:
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 , s . t . y i ( w T x i + b ) − 1 ≥ 0 , i = 1 , 2 , . . . , m \min \limits_{w,b}\space\space \frac{1}{2}||w||^2\space,\space\space s.t. \space\space y_i(w^Tx_i+b)-1\geq 0 \space,i=1,2,...,m w,bmin 21∣∣w∣∣2 , s.t. yi(wTxi+b)−1≥0 ,i=1,2,...,m
这是一个含有不等式约束的凸二次规划问题,维度较多时,可以对其使用拉格朗日乘子法得到其对偶问题,通过求解对偶问题得到原始问题的最优解,由于上述约束条件是不等式约束,从而还需要用到KKT条件。对比之前无约束的优化问题,是通过求函数对于变量的导数,令其为0,就找到了函数的候选极值点。
- 拉格朗日函数:拉格朗日方程将约束条件放到目标函数中,从而将有约束优化问题转换为无约束优化问题。该函数在可行解区域内与原目标函数完全一致,而在可行解区域外的数值非常大。
L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 − ∑ i = 1 m α i ( y i ( w T x i + b ) − 1 ) L(\pmb w,b,\pmb\alpha)=\frac{1}{2}||w||^2-\sum \limits_{i=1}^m \alpha_i(y_i(w^Tx_i+b)-1) L(www,b,ααα)=21∣∣w∣∣2−i=1∑mαi(yi(wTxi+b)−1)
其中, α i \alpha_i αi是拉格朗日乘子, α i ≥ 0 \alpha_i\geq 0 αi≥0, α = ( α 1 , α 2 , . . . , α m ) \pmb\alpha=(\alpha_1,\alpha_2,...,\alpha_m) ααα=(α1,α2,...,αm)。
由于 max α i ≥ 0 L ( w , b , α ) \max \limits_{\alpha_i\geq 0}L(\pmb w,b,\pmb\alpha) αi≥0maxL(www,b,ααα)在可行域内为 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}||w||^2 21∣∣w∣∣2,在非可行域内为正无穷。所以上述的优化问题可以变为:
min w , b max α i ≥ 0 L ( w , b , α ) \min \limits_{w,b} \max \limits_{\alpha_i\geq 0}L(\pmb w,b,\pmb\alpha) w,bminαi≥0maxL(www,b,ααα) - 对偶算法:上述拉格朗日函数,使用求导的方法求解依然困难。因此使用拉格朗日对偶性,将不易求解的优化问题转化为易求解的优化。
max α i ≥ 0 min w , b L ( w , b , α ) \max \limits_{\alpha_i\geq 0}\min \limits_{w,b} L(\pmb w,b,\pmb\alpha) αi≥0maxw,bminL(www,b,ααα)
该对偶问题的具体形式可以通过以下求解完成:
(1)先求解内侧的最小化:固定 α i \alpha_i αi,对 w , b \pmb w,b www,b分别求偏导数,令偏导数为0
w = ∑ i = 1 m α i y i x i , 0 = ∑ i = 1 m α i y i \pmb w=\sum \limits_{i=1}^m \alpha_iy_ix_i,\space\space0=\sum \limits_{i=1}^m \alpha_iy_i www=i=1∑mαiyixi, 0=i=1∑mαiyi
将 L ( w , b , α ) L(\pmb w,b,\pmb\alpha) L(www,b,ααα)中的 w , b \pmb w,b www,b消去,可得:
L ( w , b , α ) = ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j L(\pmb w,b,\pmb\alpha)=\sum \limits_{i=1}^m \alpha_i-\frac{1}{2}\sum \limits_{i=1}^m \sum \limits_{j=1}^m \alpha_i \alpha_j y_iy_jx_i^Tx_j L(www,b,ααα)=i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxj
(2)求外侧的最大值:
max α ( ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j ) , s . t . ∑ i = 1 m α i y i = 0 , α i ≥ 0 , i = 1 , 2 , . . . , m \max \limits_{\alpha}(\sum \limits_{i=1}^m \alpha_i-\frac{1}{2}\sum \limits_{i=1}^m \sum \limits_{j=1}^m \alpha_i \alpha_j y_iy_jx_i^Tx_j),\space\space s.t.\sum \limits_{i=1}^m \alpha_iy_i=0,\space\space \alpha_i\geq 0,i=1,2,...,m αmax(i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxj), s.t.i=1∑mαiyi=0, αi≥0,i=1,2,...,m
对偶问题和原始问题等价必须要满足(1)求取最小值的目标函数为凸函数的一类优化问题;(2)需要满足KKT条件。
- KKT(Karush-Kuhn-Tucker)条件:
{ α i ≥ 0 y i ( w T x i + b ) − 1 ≥ 0 α i ( y i ( w T x i + b ) − 1 ) = 0 \left\{ \begin{aligned} \alpha_i \geq 0 \\ y_i(w^Tx_i+b)-1 \geq 0 \\ \alpha_i(y_i(w^Tx_i+b)-1) = 0 \end{aligned} \right. ⎩⎪⎨⎪⎧αi≥0yi(wTxi+b)−1≥0αi(yi(wTxi+b)−1)=0
于是,对于任意样本总有 α i = 0 \alpha_i=0 αi=0 或者 y i ( w T x i + b ) − 1 = 0 y_i(w^Tx_i+b)-1= 0 yi(wTxi+b)−1=0。若 α i > 0 \alpha_i>0 αi>0,则必有 y i ( w T x i + b ) − 1 = 0 y_i(w^Tx_i+b)-1=0 yi(wTxi+b)−1=0,此时对应的样本 i i i 位于最大间隔边界上,是一个支持向量。
所以原始最优化问题的解通过求得对偶问题中的最优化解 α i ∗ \alpha_i^* αi∗ ,其中至少有一个 α i ∗ > 0 \alpha_i^*>0 αi∗>0。然后可按下式求得 w ∗ , b ∗ \pmb w^*,b^* www∗,b∗,并且 w ∗ , b ∗ \pmb w^*,b^* www∗,b∗ 只依赖于支持向量:
w ∗ = ∑ i = 1 m α i ∗ y i x i b ∗ = y j − ∑ i = 1 m α i ∗ y i ( x i T x j ) , 存 在 j 使 得 α j ∗ > 0 \pmb w^*=\sum \limits_{i=1}^m \alpha_i^*y_ix_i\\ b^*=y_j-\sum \limits_{i=1}^m \alpha_i^*y_i(x_i^Tx_j),存在\space j\space使得\alpha_j^*>0 www∗=i=1∑mαi∗yixib∗=yj−i=1∑mαi∗yi(xiTxj),存在 j 使得αj∗>0
算法流程:
输入:线性可分训练集m个样本。
输出:分隔超平面和分类决策函数。
(1)构造并求解约束最优化问题
max α ( ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j ) s . t . ∑ i = 1 m α i y i = 0 , α i ≥ 0 , i = 1 , 2 , . . . , m \max \limits_{\alpha}(\sum \limits_{i=1}^m \alpha_i-\frac{1}{2}\sum \limits_{i=1}^m \sum \limits_{j=1}^m \alpha_i \alpha_j y_iy_jx_i^Tx_j)\\ s.t.\sum \limits_{i=1}^m \alpha_iy_i=0,\space\space \alpha_i\geq 0,i=1,2,...,m αmax(i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxj)s.t.i=1∑mαiyi=0, αi≥0,i=1,2,...,m
求得最优解 α ∗ = ( α 1 ∗ , α 2 ∗ , . . . , α m ∗ ) \alpha^*=(\alpha_1^*,\alpha_2^*,...,\alpha_m^*) α∗=(α1∗,α2∗,...,αm∗)。
(2)计算 w ∗ = ∑ i = 1 m α i ∗ y i x i \pmb w^*=\sum \limits_{i=1}^m \alpha_i^*y_ix_i www∗=i=1∑mαi∗yixi,并选择 α ∗ \alpha^* α∗的一个正分量 α j ∗ > 0 \alpha_j^*>0 αj∗>0,计算 b ∗ = y j − ∑ i = 1 m α i ∗ y i ( x i x j ) b^*=y_j-\sum \limits_{i=1}^m \alpha_i^*y_i(x_ix_j) b∗=yj−i=1∑mαi∗yi(xixj)。
(3)求得分隔超平面 ( w ∗ ) T x + b ∗ = 0 (w^*)^Tx+b^*=0 (w∗)Tx+b∗=0 和分类决策函数 f ( x ) = s i g n ( ( w ∗ ) T x + b ∗ ) f(x)=sign((w^*)^Tx+b^*) f(x)=sign((w∗)Tx+b∗)
那么如何求得 α ∗ \alpha^* α∗,1996年Platt提出了SMO(Sequential Minimal Optimizaion)算法用于训练SVM。一旦求出了 α ∗ \alpha^* α∗,就很容易计算出权重向量并得到分隔超平面。
软间隔支持向量机
实际任务中,很难确定训练样本在特征空间中线性可分,也很难断定特征空间线性可分的结果可能是由于过拟合造成的。所以引入了“软间隔”的概念,允许向量机在一些样本上出错,而其余绝大部分样本都是线性可分的。
- 松弛变量 ξ i ≥ 0 \xi_i\geq 0 ξi≥0:约束条件变为 y i ( w T x i + b ) ≥ 1 − ξ i y_i(w^Tx_i+b)\geq 1-\xi_i yi(wTxi+b)≥1−ξi
- 损失函数:对每一个松弛变量添加代价C,C决定了误分类的程度。 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ξ i \frac{1}{2}||w||^2+C\sum \limits_{i=1}^m \xi_i 21∣∣w∣∣2+Ci=1∑mξi,即
1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m max ( 0 , 1 − y i ( w T x i + b ) ) \frac{1}{2}||w||^2+C\sum \limits_{i=1}^m \max (0,1-y_i(w^Tx_i+b)) 21∣∣w∣∣2+Ci=1∑mmax(0,1−yi(wTxi+b))
m a x ( 0 , 1 − z ) max(0,1-z) max(0,1−z) 是hinge loss,因此该损失函数可以看做是加了正则化的hinge loss。 - 原始优化问题:
min w , b , ξ 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ξ i s . t . y i ( w T x i + b ) ≥ 1 − ξ i , i = 1 , 2 , . . . , m ξ i ≥ 0 , i = 1 , 2 , . . . , m \min \limits_{w,b,\xi}\space\space \frac{1}{2}||w||^2+C\sum \limits_{i=1}^m \xi_i\\ s.t. \space\space y_i(w^Tx_i+b)\geq 1-\xi_i \space,i=1,2,...,m\\ \xi_i\geq 0\space,i=1,2,...,m w,b,ξmin 21∣∣w∣∣2+Ci=1∑mξis.t. yi(wTxi+b)≥1−ξi ,i=1,2,...,mξi≥0 ,i=1,2,...,m
后面与线性可分支持向量机的优化方式相同。
- 拉格朗日函数:
L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ξ i − ∑ i = 1 m α i ( y i ( w T x i + b ) − 1 + ξ i ) − ∑ i = 1 m μ i ξ i L(\pmb w,b,\pmb\alpha)=\frac{1}{2}||w||^2+C\sum \limits_{i=1}^m \xi_i-\sum \limits_{i=1}^m \alpha_i(y_i(w^Tx_i+b)-1+\xi_i)-\sum \limits_{i=1}^m \mu_i\xi_i L(www,b,ααα)=21∣∣w∣∣2+Ci=1∑mξi−i=1∑mαi(yi(wTxi+b)−1+ξi)−i=1∑mμiξi - 对偶问题:
max α ( ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j ) s . t . ∑ i = 1 m α i y i = 0 , C − α i − μ i = 0 , α i ≥ 0 , , μ i ≥ 0 , i = 1 , 2 , . . . , m \max \limits_{\alpha}(\sum \limits_{i=1}^m \alpha_i-\frac{1}{2}\sum \limits_{i=1}^m \sum \limits_{j=1}^m \alpha_i \alpha_j y_iy_jx_i^Tx_j)\\ s.t.\sum \limits_{i=1}^m \alpha_iy_i=0,\space\space C-\alpha_i-\mu_i=0,\space\space \alpha_i\geq 0,,\space\space \mu_i\geq 0,i=1,2,...,m αmax(i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxj)s.t.i=1∑mαiyi=0, C−αi−μi=0, αi≥0,, μi≥0,i=1,2,...,m - KKT条件:
{ α i ≥ 0 , μ i ≥ 0 y i ( w T x i + b ) − 1 + ξ i ≥ 0 α i ( y i ( w T x i + b ) − 1 + ξ i ) = 0 ξ i ≥ 0 , μ i ξ i = 0 \left\{ \begin{aligned} \alpha_i \geq 0 ,\mu_i\ge 0\\ y_i(w^Tx_i+b)-1+\xi_i \geq 0 \\ \alpha_i(y_i(w^Tx_i+b)-1+\xi_i) = 0\\ \xi_i \ge 0,\mu_i\xi_i=0\\ \end{aligned} \right. ⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧αi≥0,μi≥0yi(wTxi+b)−1+ξi≥0αi(yi(wTxi+b)−1+ξi)=0ξi≥0,μiξi=0 - 最优解:
w ∗ = ∑ i = 1 m α i ∗ y i x i b ∗ = y j − ∑ i = 1 m α i ∗ y i ( x i T x j ) \pmb w^*=\sum \limits_{i=1}^m \alpha_i^*y_ix_i\\ b^*=y_j-\sum \limits_{i=1}^m \alpha_i^*y_i(x_i^Tx_j) www∗=i=1∑mαi∗yixib∗=yj−i=1∑mαi∗yi(xiTxj)
可以看出,软间隔支持向量的最终模型也只与支持向量有关。
对于非线性分类问题,可以通过非线性变换,将它从原始空间映射到更高维的特征空间中,使得样本在这个特征空间线性可分,因此可以在高维特征空间中学习线性支持向量机。由于在线性支持向量机学习的对偶问题里,目标函数和分类决策函数都只涉及样例之间的内积,所以利用核技巧,用核函数替换其中的内积达到非线性变换。核技巧同样可以用于逻辑回归。
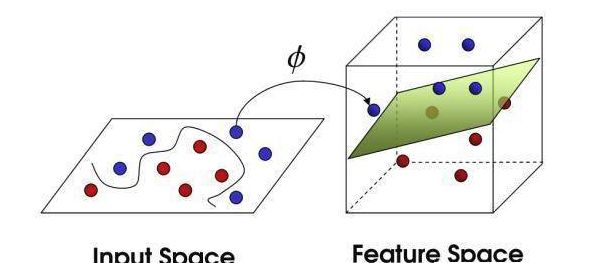
更多关于SMO算法和核函数的内容可以参考下面的文献:
[1]《统计学习方法》 李航著
[2]《机器学习》周志华著
SVM vs 感知机和逻辑回归
这三者都是属于监督学习的一种分类器(决策函数),分类决策面都是线性的(不考虑核函数)。中心思想都是,增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
- 硬间隔SVM与感知机的区别:
SVM分类超平面的解是唯一的,要满足间隔最大化;感知机的分类超平面不唯一,没有间隔最大化的约束条件,容易造成过拟合。 - 软间隔SVM与LR的区别:
(1)LR通过输出预测概率后根据阈值进行判断类别;SVM则直接输出分割超平面,然后使用0/1函数对距离进行分类,不能直接输出概率值。如果需要SVM输出概率值则需要进行特殊处理,可以根据距离的大小进行归一化概率输出。
(2)LR采用交叉熵损失(CE loss),SVM采用合页/铰链损失(hinge loss)。SVM自带了正则化项,是结构风险最小化算法,而LR需要另外在损失函数上添加正则项。
(3)LR对异常值敏感;SVM对异常值不敏感,泛华能力强,分类效果好。
(4)SVM在训练过程只需要支持向量的数据,依赖的训练样本数较小;而LR则是需要全部的训练样本数据,在训练时开销更大。
(5)LR可以使用多阈值然后进行多分类,SVM则需要进行推广。
总结
上述是一些基础的机器学习算法,虽然目前在深度学习中的应用不是很多,但是弄清楚其中的发展脉络和关联也是有必要的。目前,国内工业界应用机器学习较多的领域主要包括:金融、媒体、零售、能源、政府、医疗和算力等。像金融、媒体、零售的用户较多,满足机器学习建模对数据量的要求,而且有大量可以使用机器学习建模的场景。比如,金融领域反欺诈的分类任务使用了GBDT和LR,为用户推荐理财产品等营销场景(类似的,媒体及零售领域推荐浏览过感兴趣的相关内容)都使用推荐算法(协同过滤算法)。而目前工业界最火的机器学习研究方向是AutoML(自动机器学习)技术,这也是未来发展的一个趋势。深度学习主要是应用在CV(计算机视觉)和NLP(自然语言处理),与机器学习的区别在于其特征的可解释性较差、算力开销大。