对视觉目标检测的整体认知(基于目标检测综述)
计算机视觉领域研究的绝大多数问题均存在诸多不确定性因素,因为图像理解是成像的逆过程。成像是从三维向二维投影的过程,在此过程中不仅会丢失深度信息,而且光照、材料特性、朝向、距离等信息都反映成唯一的测量值,即灰度或色彩,而要从这唯一的测量值中恢复上述一个或几个特征参数是一个病态的过程。不仅如此,大气扰动、镜头因素、传感器噪声,以及量化噪声等的干扰都会造成成像失真,而这些干扰大多具有随机性。
图像或视频中的目标检测,意在基于目标的表观和轮廓区域等信息,准确地对其中感兴趣的目标进行定位,将目标的分类与定位合二为一。复杂环境下可靠的目标检测算法还有待进一步研究,原因在于:(1)一些目标是非刚性、多姿态、多角度的物体,如人体目标;(2)含有目标的图像背景一般都是复杂多变的;(3)目标很容易被其他目标或者物体遮挡;等等。因此,通过运用机器学习与模式识别的相关知识,使计算机能够自动、准确地检测目标,实现鲁棒、快速的目标自动提取和检测显得极为重要。
目标检测是计算机视觉和数字图像处理的一个热门方向,广泛应用于机器人导航、智能视频监控、工业检测、航空航天等诸多领域,通过计算机视觉减少对人力资本的消耗,具有重要的现实意义。因此,目标检测也就成为了近年来理论和应用的研究热点,它是图像处理和计算机视觉学科的重要分支,也是智能监控系统的核心部分,同时目标检测也是泛身份识别领域的一个基础性的算法,对后续的人脸识别、步态识别、人群计数、实例分割等任务起着至关重要的作用。
目录
- 目标检测的发展历程
- 目标检测的算法流程
- 目标检测的主要技术
- 传统目标检测算法
- 深度学习目标检测
- 目标检测评价指标及数据集
- 评价指标
- 通用目标检测数据集
目标检测的发展历程
图像的目标检测(Object Detection)算法大体上可以分为基于传统手工特征的时期(2013年以前)以及基于深度学习的目标检测时期。从技术发展上来讲,目标检测的发展则经历了包围框回归、卷积神经网络的兴起、多参考窗口(anchors)、困难样本挖掘、多尺度多端口检测、特征融合等几个里程碑式的进步。如下图所示,为2019年5月发表的目标检测综述《Object Detection in 20 Years: A Survey》,它除了对目标检测从2001到2009年的里程碑式算法和start-of-art算法进行了总结,帮助我们建立一个完整的知识体系,还对算法流程各个技术模块的演进也进行了说明。
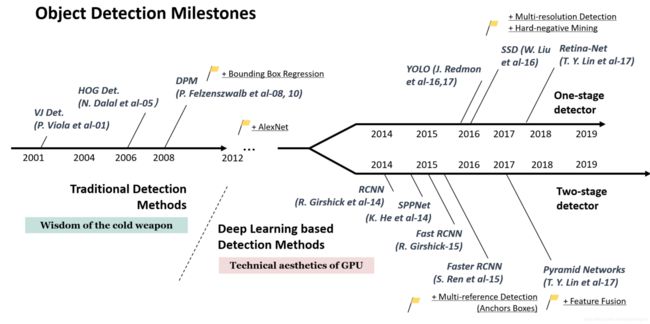
| 传统的里程碑方法 | 基于 CNN 的里程碑方法(two stage) | 基于 CNN 的里程碑方法(one stage) |
|---|---|---|
| VJ Detector | RCNN | You Only Look Once (YOLO) |
| HOG Detector | SPPNet | Single Shot MultiBox Detector (SSD) |
| Deformable Part-based Model (DPM) | Fast RCNN | RetinaNet |
| Faster RCNN | ||
| Feature Pyramid Networks (FPN) |
近年来,CNN在许多计算机视觉任务中发挥了核心作用,因此基于深度学习的检测器的精度在很大程度上取决于其特征提取网络。这些主干网络(backbone)如VGG和ResNet等对应于目标检测的发展阶段如下图所示,该图出自2019年8月发表的《Recent Advances in Deep Learning for Object Detection》。同样,自2012年以来,基于深卷积神经网络的目标检测研究具有重大里程碑意义,而图中红色箭头和绿色箭头分别代表着去年的两个研究趋势,一是基于anchor-free设计目标检测,二是基于AutoML技术的检测器,也是未来两个重要的研究方向。
为了进一步整合各个网络模型的特点,我后续会将主要算法进行归纳。同时,github上面的开源仓库里面https://github.com/hoya012/deep_learning_object_detection,也有2020年最新更新的检测论文,并且持续更新,同时也有数据集论文等。
目标检测的算法流程
目标检测的算法流程如下:

- 候选框:选取感兴趣区域(Region of Interest,ROI),即可能包含物体的区域(在one stage方法中没有候选框的步骤)
- 特征提取:对感兴趣区域进行特征提取,寻找合适的特征表达(尽量对光照、背景、表观等因素的变化不敏感)
- 分类器:对提取的特征进行检测(分类+定位)
- NMS(Non-Maximum Suppression,即非极大值抑制):进行局部搜索,选取邻域里分数最高的极大值,并且抑制那些分数低的检测框,解决检测框存在包含或者大部分交叉的情况
目标检测的主要技术
传统目标检测算法
传统的目标检测算法,即为滑动窗口+传统机器学习算法。
- 滑动窗口法:将一个窗口在待检测图片上从左到右、从上到下的滑动,从而找到目标,这里的滑动窗口所有滑过的位置即为候选框。由于目标的大小不一,因此通常会选择不同尺寸的滑动窗口,但是这样的方法人为经验太多,过程类似于穷举。除此之外,传统检测算法如 VJ 检测器和 HOG 检测器,大多不使用边界框回归(Bounding Box Regression),通常直接将滑动窗口作为检测结果。为了获得精确的目标位置,只能建造非常密集的金字塔(尺度选择较多),并在每个位置上密集地滑动(滑动步长小)检测器。DPM首次将BB回归作为后处理引入目标检测系统,这个过程表示为一个线性最小二乘回归问题 。滑动窗口法如下动图所示:
- 分别对滑动的每个窗口进行特征提取,之后对提取的特征利用机器学习方法(如SVM)进行分类。传统的目标检测算法大多是基于手工设计的特征(handcrafted features),好的特征应该具有可区别性好、可靠性高、独立性好、数量少等特点,因此可以很容易地将目标从特征空间中区分出来。目前的图像特征主要包括:颜色特征、纹理特征、形状特征、深度学习特征等。
颜色特征是最显著、最可靠、最稳定的视觉特征。颜色与图像中所包含的物体和场景的相关性很高,颜色特征对图形对象的大小与方向的变化都不敏感,具有相当强的鲁棒性。颜色直方图是图像中每个亮度值的像素数量分布,能够反映图像颜色的统计分布和基本色调。
纹理特征中最具代表性的是局部二值模式(LBP),该方法通过LBP算子来提取灰度图像中局部相邻区域的纹理特征,LBP算子为固定大小的矩形块(扩展的LBP算子用不同圆心和半径来表示不同尺度),在图像上逐点扫描,对当前中心点的像素灰度值和其邻域点像素灰度值的大小进行比较,根据结果置1或0,然后按逆时针方向读出每个邻域二进制值,该二进制串转化为的十进制数为当前矩阵块的LBP特征值,最后将全部LBP特征值进行统计,以直方图表示区域的纹理特征。
形状特征主要包括Haar-Like特征、SIFT特征、HOG特征。其中,(1)Haar-Like特征由Haar小波演变而来,特征值等于特征提取模板中黑色矩形框中所有像素颜色值之和减去白色矩形框中所有像素颜色值和;(2)尺度不变特征转换(SIFT)特征对尺度的缩放、旋转、亮度变化保持不变性,对视角变化、仿射变换、噪声也保持一定程度的稳定性,SIFT特征提取步骤为:尺度空间极值检测,关键点搜索与定位,方向确定,关键点描述;(3)梯度方向直方图(HOG)特征通过提取局部区域的边缘或梯度的分布来表征局部区域内目标的边缘或梯度结构,进而表征目标的形状,对小的形变和配准误差有较强的鲁棒性。
深度学习特征能解决手工设计特征费时费力、很大程度上依靠经验和运气的问题,思想就是仿照人脑的深层工作机理,堆叠多个特征提取层,实现对输入信息的分层表示。
传统目标检测算法的缺点:(1)识别效果不够好,准确率不高(受限于没有有效的图像表示方法);(2)计算量比较大,运行速度慢。在CNN出现之后,利用卷积层强大的特征提取能力,和神经网络的分类能力,对准确率进行了一定的提升。但是候选框仍是滑动窗口的方法,容易在分类出现大量的假正样本,识别的速度反而有些降低。
深度学习目标检测
通过上述的传统目标检测方法,我们可以看到目标检测过程存在的几个技术难点:(1)候选框/区域建议(proposal)的生成方法;(2)多尺度(Multi-scale)检测对象的 “不同尺寸(scale)” 和 “不同纵横比(ratio)”;(3)包围框回归方式;(4)特征表达的学习;(5)NMS的改进;(6)不平衡问题;(7)加速检测速度;(8)训练和测试策略。下面将一一介绍这些技术的研究情况。
- Proposal Generation
| Methods | Description |
|---|---|
| Sliding-window方法 | 分子块的方法,在整幅图像上穷举。 |
| Selective search方法 | 基于graph的图像分割得到初始区域,再使用贪心算法迭代分组,可以捕捉不同尺度、更具多样性。 |
| Anchor-based方法 | 以Faster RCNN提出的RPN为主,在每个滑窗位置有不同scale和ratio的锚框,后来陆续基于此工作进行改进。 |
| Keypoints-based/Anchor-free方法 | 可以预测一对角点(如CornerNet)或预测特征图上每个位置的中心点对应的宽高(如FSAF),还有两种思路结合的方法(如CenterNet)。 |
- Multi-Scale Detection
该技术与Proposal Generation有很多相似之处,可以说Multi-Scale作为Proposal Generation的其中一个技术研究方向,但是Multi-Scale主要是为了适应不同尺度的目标得到检测框。
| 时间 | Methods | Description |
|---|---|---|
| 2014年前 | 特征金字塔和滑动窗口 | 只需构建特征金字塔,并在其上滑动固定大小检测窗口;但是只考虑了不同的尺度,之后训练多个模型来检测不同纵横比的物体。 |
| 2010-2015年 | 基于目标建议的检测 | 引用一组可能包含任何对象的与类无关的候选框,包括RCNN、SPP、Fast RCNN等。 |
| 2013-2016年 | 深度回归 | 基于深度学习特征直接预测边界框的坐标,比如YOLO。 |
| 2015年后 | 多参考窗口 | 在图像的不同位置预先定义一组不同大小和宽高比的参考框(即锚框),然后根据这些参考框预测检测框,如Faster RCNN。 |
| 2016年后 | 分辨率检测 | 在网络的不同层检测不同尺度的目标。 |

- Bounding Box Regression
边界框(BB)回归的目的是在初始建议(initial proposal)或锚框的基础上细化预测边界框的位置。BB回归经历了三个历史时期:(1)没有BB回归(2008年以前) ,(2)从BB到BB (2008-2013年) ,(3)从feature到BB (2013年后) 。 - Feature Representation Learning
| Methods | Description |
|---|---|
| Multi-scale Feature | 图像金字塔、特征整合、预测金字塔、特征金字塔等一系列方法。 |
| Region Feature Encoding | 对于two stage检测器,区域特征编码是将proposal特征提取到固定长度特征向量的关键步骤,RoI Pooling→RoI Warping→RoI Align→PrROI Pooling→Deformable ROI Pooling。 |
| Context Priming | 常用的方法有三种:局部上下文检测,全局上下文检测,上下文交互。 |
| Deformable Feature | 为了使检测器对非刚性目标变换具有鲁棒性,如可变形卷积。 |


- Non-Maximum Suppression
非最大抑制作为后处理步骤,去除重复的边界框,得到最终的检测结果。
| Methods | Description |
|---|---|
| Greedy Selection | 对于一组重叠检测,选择检测分值最大的边界框,并根据预定义的重叠阈值 ( 如0.5 ) 删除相邻框。上述处理以贪婪的方式迭代执行。缺点:得分最高的框可能不是最合适的;可能会抑制附近的物体;不能抑制假阳性 |
| BB Aggregation | 将多个重叠的边界框组合或聚类成一个最终检测,充分考虑了对象关系及其空间布局。 |
| Learning to NMS | 主要思想是将NMS看作一个过滤器,对所有原始检测进行重新评分,并以端到端方式将NMS训练为网络的一部分,在改善遮挡和密集目标检测方面取得了良好的效果。 |
- Imbalance Problems
TPAMI 2020 的论文《Imbalance Problems in Object Detection: A Review》是一篇关于目标检测中不平衡的综述,这些不平衡会影响最终的检测精度,将这些不平衡问题可以分为四类。具体见下图。
| Methods | Description |
|---|---|
| 类别不平衡(Class) | 主要由输入不同类的边界框数目差异引起的,Foreground-Background 和 Foreground-Foreground不平衡。 |
| 尺度不平衡(Scale) | 主要是输入目标的尺度差异引起的,比如COCO中小物体过多,分配目标到特征金字塔也会不平衡。 |
| 空间不平衡(Spatial) | 不同样本对回归损失的贡献不平衡,正样本边界框的IoU分布,图像中目标的位置分布。 |
| 目标不平衡(Objective) | 不同任务(即分类、回归)对总损失的贡献不平衡。 |
如下图所示,不同颜色的分支代表了四种不平衡问题,论文还给出了每个问题的建议的解决方案列表。

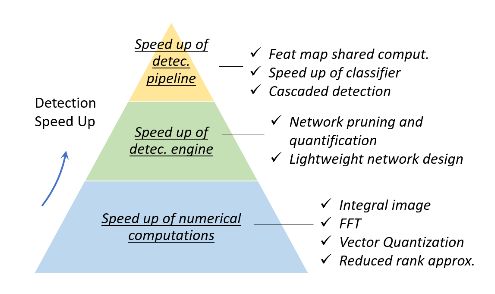
- Speed-up of Detection
| Methods | Description |
|---|---|
| 数值计算提速 | 积分图像快速计算图像子区域的和,频域傅里叶变换加速卷积操作,矢量量化可用于数据压缩和加速目标检测中的内积运算,降秩近似是一种加速矩阵乘法(全连接层)的方法。 |
| 检测引擎(backbone)提速 | (1)在现有网络基础上:网络剪枝(对网络结构或权值进行修剪以减小其大小)、量化(减少激活值或权值的码长)、蒸馏(将大型网络的知识压缩成小型网络)。(2)直接设计轻量级网络:分解卷积 、组卷积、深度可分离卷积、瓶颈设计、 神经结构搜索。 |
| 检测管道(pipeline)提速 | 常用的方法有三种:特征图共享计算,分类器加速,级联检测。 |
- Learning Strategy
| Phase | Methods | Description |
| Training Stage | Data Augmentation | 数据增强策略在检测精度上有显著的提高。 |
| Imbalance Sampling | 类别不均衡采样,或困难样本采样策略;难度不平衡可以使用损失函数。 | |
| Localization Refinemen | 对proposal的位置精修以便获得更准确的bbox。 | |
| Cascade Learning | 将多个分类器放在不同阶段的特征图,进行样本拒绝后送入后面;多级回归Cascade RCNN。 | |
| Others | GAN,网络的对抗样本训练有助于提高网络的鲁棒性;Training from Scratch;Knowledge Distillation。 | |
| Testing Stage | Duplicate Removal | NMS,soft-NMS,还有可学习的Learning NMS。 |
| Model Acceleration | 主要是针对两阶段检测器耗时问题的解决。 | |
| Others | 图像金字塔的多尺度测试;数据增强。 | |
目标检测评价指标及数据集
评价指标
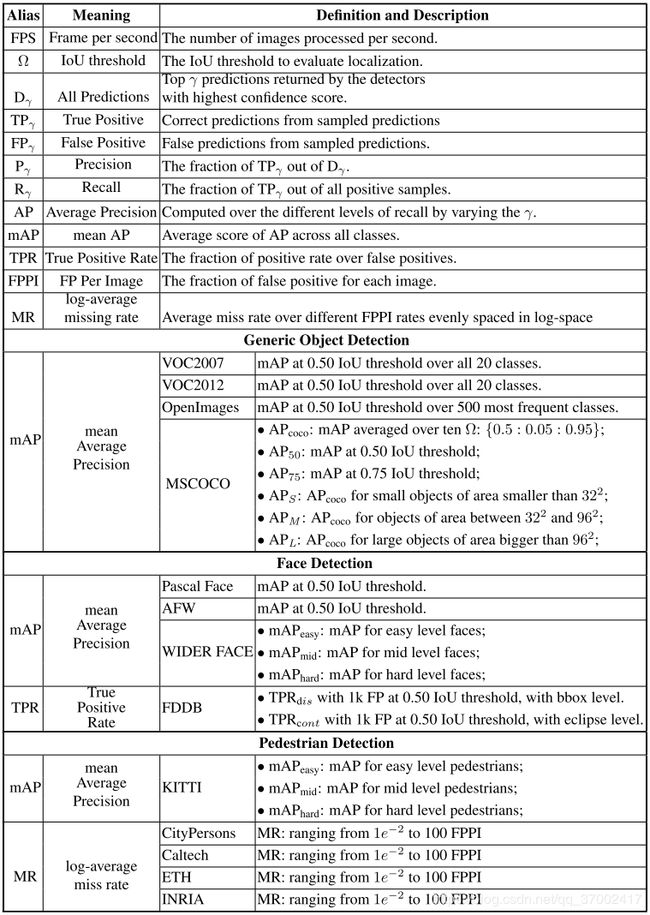
- FPS(Frames per second):代表了模型的检测速度,简单来说就是每秒能够检测多少张图片,像two stage的Faster RCNN可以提高到7FPS,one stage的SSD300可以达到46FPS。
- IOU(Intersection over Union):交并比,意思是检测结果的矩形框和标注(GT)框的交集与并集的比值,一般来说对IOU都会设立一个阈值(如0.5),在这个阈值之上我们才认为检测框成功检测到目标。
- TP,TN,FP,FN:分别代表真正例(true positive)、真反例(true negative)、假正例(false positive)、假反例(false negative),所以样例总数=TP+TN+FP+FN。
- accuracy:准确率就代表被分对的样本数占所有样本的比例=(TP+TN)/(TP+TN+FP+FN),但不意味着准确率越高分类效果越好,因为当不同样本比例非常不平衡时,占比大的类别往往成为影响准确率的主要因素。
- 查准率P(precision):说明了预测为正样本的数据中是真正例的占比=TP/(TP+FP),代表找的好不好。
- 查全率R(recall):说明了在总的正样本中预测正确的正样本数=TP/(TP+FN),代表找的全不全。与TPR(true positive rate)真阳率是一个概念,相对于FPR假阳率(反例中预测为正样本的比率)。
- P-R曲线:为了使得查准率高我们尽量会选择最有把握的正样本,但这样难免会漏掉一些正样本,因此一般来说查准率和查全率是一对矛盾的度量。为了综合评估两方面的表现,评估P-R曲线(precision为纵坐标,recall为横坐标)的整体表现。
- AP(average precision):平均准确率,是对不同召回率点上的准确率进行平均,在P-R曲线上表现为与坐标轴围成的面积。
- mAP(average precision):平均精度均值,对每个检测类别的AP进行平均。一般来说,mAP是目标检测最为重要的指标,在0-1之间越大越好。
其他评价指标:
- F1-score:是精确率和召回率的调和平均数=2TP/(2TP+FP+FN),认为精确率和召回率同等重要,还有F2-score和F0.5-score分别认为召回率的重要性是精度的2倍和0.5倍。
- ROC曲线和AUC值:ROC(receiver operating characteristic)曲线的纵坐标为真阳率,横坐标为假阳率。AUC是ROC曲线下的面积,该值越大说明分类器越可能把真正的正样本排在前面,分类性能越好。
通用目标检测数据集
Generic Detection Benchmarks:
Pascal VOC2007:包含20个类,划分为训练/验证/测试集各2501/2510/5011张图片。
Pascal VOC2012:与VOC2007同样的20类,三个数据集划分为5717/5823/10991张图片。
MSCOCO:包含80个类,划分为训练/验证/测试集各118287/5000/40670张图片。
ImageNet :200类,数据量十分庞大,一般不用于检测而是分类。
参考博文:
[1]2019年最新目标检测算法综述汇总
[2]论文笔记-2019-Object Detection in 20 Years: A Survey