MySql数据库优化
数据库优化,是一种综合性的技术,不是通过某一种方式让数据库效率提高很多,而是通过各个方面的优化,来是数据库效率明显的稳步的提高。
主要包括以下:
1、库表的设计优化(三种范式)
2、库表添加合适的索引(普通索引+主键索引+唯一索引+全文索引)
3、分表技术-水平分割与垂直分割
4、读写分离(add/delete/update与select分开)
5、多用存储过程和触发器(模块化编程)
6、优化MqSql配置(配置最大并发数,调整缓存大小,my.ini)
7、SQL优化与慢查询
8、定时清楚垃圾数据,定时进行碎片整理(MyISAM)
除此之外,还有 MqSql服务器硬件升级
以下进行详细描述
题外话:
存储引擎:
MyISAM: 查询速度快,插入速度快,但不支持事务,碎片多;
InnoDB :5.5版本后Mysql的默认数据库,支持事务,支持ACID事务,支持行级锁定;
Memory :所有数据置于内存中,拥有极高的插入,适合频繁的数据更新,更新和查询效率。但是会占用和数据量成正比的内存空间。并且其内容会在Mysql重新启动时丢失,不需要保存滴;
数据库三种模式结构/三级模式
外模式(用户):用户所能看到的数据视图,可通过数据库操纵语言对数据进行操作;
模式(概念):用户视图的最小并集,所有数据的逻辑结构和概念的描述;
内模式(物理):实际存储组合,内部视图,是实际物理存储的抽象;
一、库表设计
良好的数据库设计,能够节省数据库空间,保持数据完整性,方便应用程序的开发;(相反:数据冗余,空间浪费,插入更新繁杂或者异常)
设计数据库
1、充分了解需求:标识实体(具体存在的对象、东西,名词),标识实体属性,标识实体关系
以BBS论坛为例
实体:
用户(属性:昵称,密码,邮箱,生日,性别,登记,备注,积分,注册时间)
主贴(属性:标题,正文,发帖时间,状态,发帖人,回复数量,点击数)
回帖(属性:帖子编号,回帖人,回帖标题,回帖正文,回帖时间,点击数)
板块(属性:板块名称,版主,板块格言,点击数,发帖数)
2、实体关系
一对一,两个表的主键是公共字段
一对多,主键与非主键之间的关系
多对一,非主键与主键之间 的关系
多对多,非主键与非主键之间的关系
3、E-R图,实体-联系图(Entity Relationship Diagram),提供了表示实体类型、属性和联系的方法,用来描述现实世界的概念模型;
*1、创建表时,将实体转化为表,将属性转化为列,唯一标识一行数据的列可为主键,无合适字段做主键就用自动增加列, 将关系转化为主外键展示实体之间的关系;
*2、表结构规范化-三范式(
1、列的原子性。列不可分解,确保每列都不能再分解成更基本的数据单位;
2、记录的唯一标识。给记录增加一个主键,非主键字段依赖主键字段,即表的列中若有重复数据且与主键无关,则可拆分表;
3、字段不存在冗余。不存在传递依赖,即若表的除主键外各个列间有直接关联,即非主键字段一个字段可以推导出另一个字段,则可拆分表
)
范式举例:
山东理工,山东淄博;山大,山东济南;其中山东济南就可以拆分(第一范式)山东理工,山东,淄博;山大,山东,济南;
学号-主,姓名;ID,科目,成绩,学号,姓名;满足第二范式;但不满足第三范式;如果学号非主键,则满足第三范式;
*但注意,也有第五第六等范式,范式越高表越多,查询效率一般就会降低,一般第三范式效率最高列。。
反三范式:学号,语文,数学,英语,总成绩;总成绩字段就是违反第三范式,适当的数据冗余允许,不然就查询效率低了:select sum(yw+sx+yy) from t_score或单独建表 学号,总成绩;
由此可见,数据库的性能效率比规范化更重要;
二、库表添加合适的索引
主键索引,唯一索引见上述链接;
1、主键索引,主键查询时默认使用;
2、组合索引,左边用,右边不用;
3、模糊查询,%或者_写在左边不会用索引,右边会用;
4、条件语句中如果有or,or的两侧均为索引才能使用,否则不会使用;
普通索引与组合索引区别:多个普通索引MySQL只用到认为似乎是最有效率的一个单列索引;组合索引为最左前缀,name-age-city建索引,相当于name,age,age-name,city-name;
主键索引与唯一索引区别:主键执行计划优于唯一,主键索引不能为空,仅一个主键索引列,主键索引更适合自生成不改变的列,主键可被其他列引为外键;
唯一索引,检索到一个直接返回;普通索引,检查是否是全部才返回;
创建索引语法:
create index 索引名称 on 表明 (字段名)
创建全文索引语法:
CREATE fulltext INDEX 索引名称 ON 表明 (字段名)
例子:
- SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('database'); 两个字段的索引:FULLTEXT (title,body)
- SELECT * FROM articles WHERE MATCH (tags) AGAINST ('旅游' IN BOOLEAN MODE);IN BOOLEAN MODE是只有含有关键字就行,不用在乎位置,是不是起启位置.
*仅存储引擎为MyISAM支持全文索引,InnoDB不支持不支持全文索引;
*mysql默认的阀值是50%,当某字段出现次数只有低于50%(停止词)的才会出现在结果集中;(意思是,全文索引用在海量数据中,不存在高于50%的情况)
*fulltext不支持中文,用Sphinx是一个基于SQL的全文检索引擎,结合MySQL,PostgreSQL做全文搜索,他可以提供比数据库本身更专业的搜索功能,使得应用程序更容易实现专业化的全文检索;
三、分表
水平分表:字段不多但是记录行数超级多,达到千万级别,经常检索速度会很慢;按照合理的逻辑去拆分成一个个较小的表,比如按照月份或者类型等待,利于程序简单实现,同时必须考虑到避免union,否则不如不拆分;
垂直分表:记录不多但是字段较多或者较长,占用的空间也比较大,检索需要大量IO,降低性能;拆分时可将较大字段拆分出来,组成一对一的对应关系表;
四、读写分离
数据库服务器压力大时,可以利用主从数据库,对仅仅需要查询,且不特别关注失效性的功能,使用从数据库进行数据的查询;
五、存储过程与触发器
存储过程:可编程的函数,由sql语句和控制结构组成;
sql:需要先编译后执行;存储过程:跨平台和应用使用;速度快,减少网络流量,组件式编程,统一接口参数安全,灵活性差;
| 1 |
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
存储过程内的普通变量
| 1 2 |
|
变量赋值
| 1 2 |
|
存储过程中的用户变量
| 1 2 |
|
参与select/update/where语句
| 1 |
|
判断语句
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
循环语句
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
跳转或者终止符
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
开始结束符
| 1 2 3 |
|
七、SQL优化与慢查询
切入点:一个较大的项目,我们想了解当前mysql的运行状态、是否有耗时较长的sql执行等待
1、数据库的增删改查
一般情况下,增删改总计占数据库的10%,而90%是查询操作;
2、show status的相关常用命令
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
|
3、启动MqSql使用记录慢查询日志(2种)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
重启mysql
停止net stop mysql 启动 net start mysql
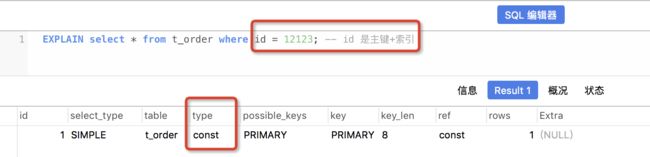
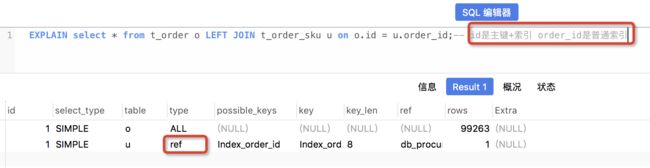
4、explain
explain命令,可以用显示mysql如何使用索引来处理select语句以及连接表;

上述图片中的字段再次描述:
id:查询序号,即执行顺序号,不重要;
select_type:simple 它表示简单的select,没有union和子查询;primary 最外面的select,在有子查询的语句中,最外面的select查询就是primary;union union语句的第二个或者说是后面那一个;
table:显示这一行的数据是关于哪张表的;
possible_keys:可能会使用的索引;
key:实际使用的索引;优化where语句,选择合适的字段或者表字段;
key_len:索引长度,越短越好;
ref:使用某个库表字段 去 匹配表中数据
rows:查询的行数,越小越好;
extra:关于mysql如何解析查询的额外信息
关注当内容显示using temporary,即需要优化sql,因为用到了缓存;--尽力用小表驱动大表
举例:联表排序:驱动表字段排序直接是驱动表排序/非驱动表排序则先合并结果集后排序(指定联接条件时满足查询条件较少数据表为驱动表,不指定联接条件时表数据较少的为驱动表)
type:重要,连接类型:
const 表示:表中最多有一个匹配行,且用到了primary key 或者unique索引;
eq_ref 表示:和前边表查询匹配的值,后边表中最多仅有一个匹配行,且都用到了primary key 或者unique索引,且是最好的表之间的联接类型

ref 表示:和前边表匹配的值,后边表均会取出,且基于的关键字段是索引字段,但不是后边表的primary key 或者unique索引,则为ref,且是较好的表之间的联接类型
八、碎片整理
存储引擎为MyISAM
数据insert会使用其占用空间增加,但delete数据不会是其占用的空间减少,原因:删除数据时,mysql并不会回收被已删除数据的占据的存储空间以及索引位;而是等待新的数据来弥补这个空缺;
语法命令(定期optimize):
| 1 2 |
|