Linux系统查看CPU
在linux的系统维护中,可能需要经常查看cpu使用率,分析系统整体的运行情况,以便性能分析优化。而监控CPU的性能一般包括以下3点:运行队列、CPU使用率和上下文切换。
对于每一个CPU来说运行队列最好不要超过3,例如,如果是双核CPU就不要超过6。如果队列长期保持在3以上,说明任何一个进程运行时都不能马上得到cpu的响应,这时可能需要考虑升级cpu。另外满负荷运行cpu的使用率最好是user空间保持在65%~70%,system空间保持在30%,空闲保持在0%~5% 。
Linux系统查看CPU:
1.工具:
SecureCRT
securecrt 32位:http://www.121down.com/soft/softview-906.html
securecrt 64位:http://www.121down.com/soft/softview-53196.html
2.linux命令:
2.1 top
top命令可以看到总体的系统运行状态和cpu的使用率 。
示例:

参数解释:
0.3 us:表示用户空间程序的cpu使用率(没有通过nice调度)
0.4 sy:表示系统空间的cpu使用率,主要是内核程序。
0.0 ni:表示用户空间且通过nice调度过的程序的cpu使用率。
97.2 id:空闲cpu
2.1 wa:cpu运行时在等待io的时间
0.0 hi:cpu处理硬中断的数量
0.0 si:cpu处理软中断的数量
0.0 st:被虚拟机偷走的cpu
2.2 vmstat
可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存 交换情况,IO读写情况。相比top,通过vmstat可以看到整个机器的 CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率。
示例:
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如:

2表示每个两秒采集一次服务器状态,1表示只采集一次。

这表示vmstat每2秒采集数据,一直采集,直到我结束程序。
参数解释:
vmstat命令输出分成六个部分:
(1)进程procs: r:在运行队列中等待的进程数 。 b:在等待io的进程数 。 (2)Linux 内存监控内存memory: swpd:现时可用的交换内存(单位KB)。 free:空闲的内存(单位KB)。 buff: 缓冲去中的内存数(单位:KB)。 cache:被用来做为高速缓存的内存数(单位:KB)。 (3) Linux 内存监控swap交换页面 si: 从磁盘交换到内存的交换页数量,单位:KB/秒。 so: 从内存交换到磁盘的交换页数量,单位:KB/秒。 (4)Linux 内存监控 io块设备: bi: 发送到块设备的块数,单位:块/秒。 bo: 从块设备接收到的块数,单位:块/秒。 (5)Linux 内存监控system系统: in: 每秒的中断数,包括时钟中断。 cs: 每秒的环境(上下文)转换次数。 (6)Linux 内存监控cpu中央处理器: cs:用户进程使用的时间 。以百分比表示。 sy:系统进程使用的时间。 以百分比表示。 id:中央处理器的空闲时间 。以百分比表示。
常见诊断:
1、假如 r 经常大于4 ,且 id 经常小于40,表示中央处理器的负荷很重。
2、假如 bi,bo 长期不等于0,表示物理内存容量太小。
参数详细解释:
r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free 空闲的物理内存的大小。
buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存。
cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用3800多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。
so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte;
bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
in 每秒CPU的中断次数,包括时间中断。
cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的 数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或 者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核 空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的 时间少了,CPU没有充分利用,是不可取的。
us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
id 空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
wt 等待IO CPU时间。
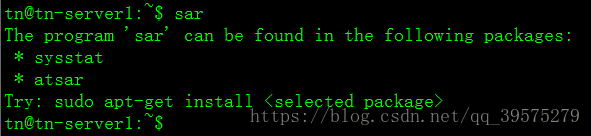
2.3 sar
sar命令语法和vmstat一样。命令不存在时需要安装sysstat包
2.4 mpstat
这个命令也在sysstat包中,语法类似。
cpu使用情况比sar更加详细些,也可以用-P指定某颗cpu 。
2.5 iostat
这个命令主要用来查看io使用情况,也可以来查看cpu,不常用。
2.6 dstat
每秒cpu使用率情况获取 : dstat -c
最占cpu的进程获取 : dstat --top-cpu