Java程序员学习大数据之HBASE
Java程序员学习大数据之HBASE
- 1 什么是HBase
- 1.1 列式数据库与行式数据库
- 1.2 Hbase对表处理的特点
- 1.3 HBase与RDBMS的区别
- 1.4 HBase的基本结构
- 1.5 HBase的数据模型
- 2 HBase的集群架构
- 2.1 HBase系统架构
- 2.2 WAL机制
- 3 Hbase 的读写流程
- 3.1 数据路由
- 3.2 写过程
- 3.2.1 合并与分裂过程
- 3.2.2 分裂过程meta表变化
- 4 HBase之MVCC
- 4.1 Hbase 有没有并发问题
- 4.2 Hbase 自己的MVCC
1 什么是HBase
Hbase是一个开源、分布式、非关系型列式数据库,数据存储于分布式文件系统HDFS,并且HDFS为其提供了高可靠性的底层存储支持,使用ZooKeeper进行协调服务,MapReduce为其提供了高性能的计算能力。HBase主要是为了处理庞大的表,官方描述单表支持百亿行百万列,由于依赖HDFS的特性,所以主要依靠横向扩展。
1.1 列式数据库与行式数据库
简单来说两者的区别就是对表的组织。行存储法是将各行放入连续的物理位置,这很像传统的记录和文件系统。列存储法是将数据按照列存储到数据库中,与行存储类似。列方式所带来的重要好处之一就是,由于查询中的选择规则是通过列来定义的,因此整个数据库是自动索引化的。
1.2 Hbase对表处理的特点
- 一个表可以有上亿行,上百万列。
- 采用面向列的存储和权限控制。
- 为空的列并不占用存储空间。
1.3 HBase与RDBMS的区别
| 类别 | HBase | RDBMS |
|---|---|---|
| 硬件架构 | 分布式集群、硬件成本低廉 | 传统多核系统、硬件成本高昂 |
| 数据库大小 | PB | GB、TB |
| 数据分布式方法 | 稀疏的、多维的 | 以行和列组织 |
| 数据类型 | 只有简单的字符串类型,所有类型都有用户自定义 | 丰富的数据类型 |
| 储存模式 | 基于列存储 | 基于表格结构的行存储 |
| 数据修改 | 可以保留旧版本数据,插入对应的新版本数据 | 替换修改旧版本数据 |
| 事务支持 | 只支持单个行级别 | 对行和表全面支持 |
| 查询语言 | JAVA API,HIVEQL | SQL |
| 吞吐量 | 百万查询每秒 | 数千查询每秒 |
| 索引 | 只支持行键 ,除非结合其他技术 | 支持 |
1.4 HBase的基本结构

1. 表(table)
在HBase中,数据存储在表中,表名是String类型的字符串,一个表有行和列构成,多维映射。
2. 行(row)
一行由行键(rowkey)和一个或多个列(column)组成,行键总是视为字节数组byte[],行键类似于RDBMS中的主键,在整个HBase表中是唯一的,行键是以字符顺序排列的,而非插入顺序,因此可以用这个特性将相关的数据排列在一起。
3.列族(column family)
纵向切割,一行可以有多个列族,一个列族可以有多个列,表中的每一行都有相同的列族,列族必须在表创建的时候指定,不能轻易修改,一般数目不超过3个,类型为String。
4. 列限定符(qualifier)
列的名称,常见定位格式为 (column family:qualifier)。
5. 单元格(cell)
单元格通过行键、列族和列限定符定位,包括值和时间戳,值没有数据类型,总是视为byte[],之间戳代表当前版本,类型为long,每个单元格根据时间戳有同一份数据的多个版本,降序排序,默认读最新数据。
1.5 HBase的数据模型

2 HBase的集群架构
HBase的集群架构采用主从方式,由HMaster、HRegionServer、ZooKeeper组成。
2.1 HBase系统架构
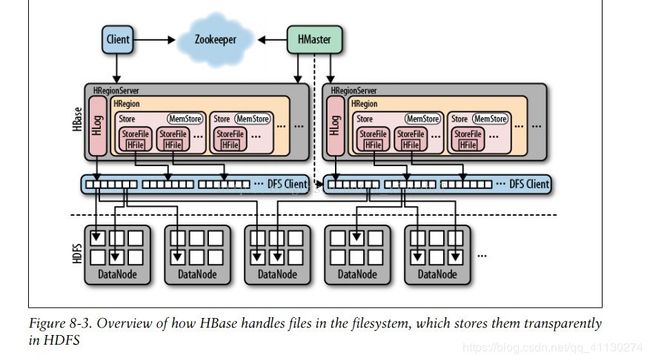
1. HMaster
HMaster用于管理多个HRegionServer,是HBase的管理节点,管理各个HRegionServer之间的状态,并平衡HRegionServer之间的负载,分配Region到HRegionServer,HMaster节点并不只有一个,用户可以启动多个主节点,通过ZK的选举机制同一时刻保持只有一个HMaster活跃,其他用于备用。HMaster还可以管理用户对表的增删改查等操作,以及管理表的元数据。
2. HRegion和HRegionServer
HBase使用rowkey将表水平切分成多个HRegion,所以每个HRegion都由表中的多行数据组成,Region是HBase中分布式存储和负载均衡的最小单位,但不是最小的存储单元。随着HRegion不断增大,当增大到一个阀值的时候,HRegion就会分割成两个HRegion。由HMaster将HRegion分配到不同的HRegionSrver中。
HRegionServer的作用:
维护HMaster分配给它的HRegion,处理对这些HRegion的IO请求
负责切分正在运行过程中变得过大的HRegion
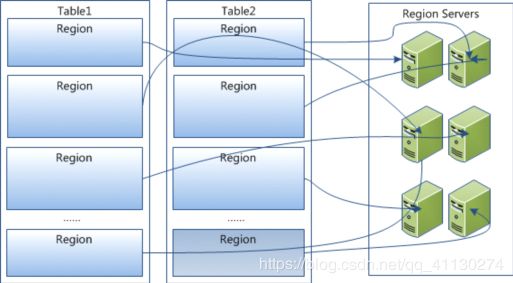
每一个HRegion都记录了rowkey的起始行键和结束行键,第一个HRegion的其实行键为空,最后一个HRegion的结束行键为空。
3. Store
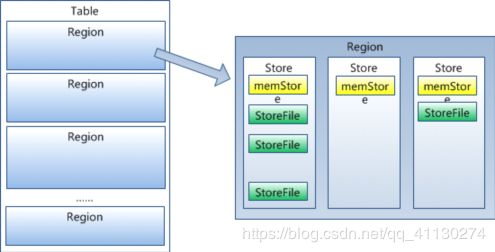
一个Store存储了HBase表中一个列族的数据,因为一个表中可能有多个列族,而表被水平切分成了多个HRegion,所以一个HRegion中就会有一个或多个Store。一个Store包含一个MemStore和若干个StoreFile,数据存入磁盘会先存入MemStore中,当MenStore的大小达到一定值后(默认64MB),就会将MemStore中的数据转移到HFile,StoreFile中包含一个或多个HFile,HFile是HBase底层的数据存储格式,Memstore存放在内存中,StoreFile存放在HDFS上。
4. HFile
HBase中KeyValue数据的存储格式,是Hadoop的二进制格式文件。 首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。
Trailer中有指针指向其他数据块的起始点,FileInfo记录了文件的一些meta信息。Data Block是HBase IO的基本单元,为了提高效率,
HRegionServer中有基于LRU的Block Cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定(默认块大小64KB),
大号的Block有利于顺序Scan,小号的Block利于随机查询。每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成,
Magic内容就是一些随机数字,目的是防止数据损坏,结构如下。

5. HLog
HLog是HBase的日志文件,记录数据的更新操作,HBase在写入数据时会先进行WAL操作,即预写日志,然后才会将数据写入Store中的MemStore,只有两个地方都写入成功后,才会认为是写入成功,若MemStore中的数据丢失,则可以利用Hlog来恢复丢失的数据。
2.2 WAL机制
在一个RegionServer上的所有Region都共享一个HLog,一次数据的提交先写入WAL,写入成功后,再写入menstore之中。当menstore的值达到一定的时候,就会形成一个个StoreFile。
WAL记载了每一个RegionServer对应的HLog。RegionServer或者RegionServer上某一个regiong挂掉了,都会迁移到其它的机器上处理,重新操作,进行恢复。
当RegionServer意外终止的时候,Master会通过Zookeeper感知到,Master首先会处理遗留下来的HLog文件,将其中不同Region的Log数据进行拆分,分别放到相应的Region目录下,然后再将实效的Region重新分配,领取到这些Regio你的RegionMaster发现有历史的HLog需要处理,因此会Replay HLog的数据到Memstore之中,然后flush数据到StoreFiles,完成数据的恢复。
3 Hbase 的读写流程
3.1 数据路由
分布式数据库应该要怎么进行路由呢?
HBase是通过hbase:meta表来完成的,hbase:meta中记录了所有Region的元数据信息,而hbase:meta的位置则记录在ZooKeeper中,在网上较多的文章都会介绍hbase的两个关键表ROOT表与meta表,其实在hbase0.98之后,hbase就废弃了ROOT表,仅保留meta表。meta表是K-V格式,如下图

其中,
table:表名;
region start key:Region 中的第一个 RowKey,如果 region start key 为空,表示该 Region 是第一个 Region;
region id:Region 的 ID,通常是 Region 创建时的 timestamp;
regioninfo:该 Region 的 HRegionInfo 的序列化值;
server:该 Region 所在的 Region Server 的地址;
serverstartcode:该 Region 所在的 Region Server 的启动时间。
3.2 写过程
- 客户端访问ZK得到hbase:meta地址,并缓存。
- 通过访问meta表,获取rowkey所在的HRegionServer地址,并缓存。
- Hbase客户端根据地址请求HRegionServer,进行写操作。
- HRegionServer先将操作和数据写入HLog,再将数据写入MemStore,并保持有序。
- 当MemStore的数据量超过阈值时,将数据溢写磁盘,生成一个StoreFile文件。
当Store中StoreFile的数量超过阈值时,将若干小StoreFile合并(Compact)为一个大StoreFile。
当Region中最大Store的大小超过阈值时,Region分裂(Split),等分成两个子Region。
3.2.1 合并与分裂过程
1. StoreFile合并(Compaction)
目的:减少StoreFile数量,提升数据读取效率。
Compaction分为两种:
major compaction
将Store下面所有StoreFile合并为一个StoreFile,此操作会删除其他版本的数据(不同时间戳的)
minor compaction
选取Store下的部分StoreFile,将它们合并为一个StoreFile,此操作不会删除其他版本数据。
2. Region分裂(Split)
当MemStore的数据超过阈值时,将数据溢写磁盘,生成一个StoreFile文件。当Region中最大Store的大小超过阈值时,Region分裂,等分成两个Region,实现数据访问的负载均衡。新的Region的位置由HMaster来确定在哪个RegionServer中。
主要由配置中的hbase.hregion.max.filesize所决定阈值大小,分裂过程会暂停写操作,分裂在高并发写的情况下,影响非常大,如何减少在写入过程中region的分裂,是利用好HBase的关键所在。
目的:实现数据访问的负载均衡。
流程:
1.region所在regionServer创建splits目录;
2.关闭要分裂的region的读写请求;
3.在splits目录中创建所需要的文件结构;
4.移动两个新region文件目录到目录表中,并更新.META表;
5.异步复制父region中的数据到两个子region中(最主要的消耗时间);
6.复制完成后、打开两个新产生的region,并上线,可以接收新的读写请求;
7.异步任务把定时把原来被分裂的region从.META表中清除掉,并从文件系统中删除该region所占用的空间;
原文链接:https://blog.csdn.net/SmallCatBaby/article/details/90304489
3.2.2 分裂过程meta表变化
当不断向一个table写数据,会触发region spilt,具体过程不再此描述,主要描述meta表的变化:
1)首先是更新meta表中parent region的info:regionfo列的值,然后增加两列info:spiltA和info:splitB(top child的regioninfo,这里约定top为startkey较小的HRegionInfo,bottom则反)。整个过程正常完成后,会删除parent region;
2)更新完meta表中parent region的记录时,需要把child region相关信息插入到meta表中,top child region的startkey和parent key region完全一样,这个时候regionId就发挥作用了,如果没有regionId,当meta表中有top region和parent region时,就不知道选哪个了,因为他们的startkey一样的。而可以通过timestamp作为region的id作区分(top region id取timestamp+1)。这样就可以保证child region总是排在parent region前面;
3)另外,bottom child必须先插入到meta表中,然后,top child才能插入,否则,就会出现在meta表中,bottom region里面key找不到对应region的情况。
原文链接:https://blog.csdn.net/JY_He/article/details/88955793
4 HBase之MVCC
4.1 Hbase 有没有并发问题
首先我们需要了解一下什么是ACID事务性:
原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性(Consistency)
事务前后数据的完整性必须保持一致。
隔离性(Isolation)
事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
如果我们假设没有并发问题的前提下进行两个写入操作
info:name = LiSi, info:age = 5
info:name = ZhangSan, info:age = 6
有可能的情况是
- "LiSi"写入成功
- “6” 写入成功
- "ZhangSan"写入成功
- "5"写入成功
最后得到的数据就是 ”ZhangSan“,“5”, 显然不是我们所需要的,并且也违背了隔离性。所以HBase存在并发问题,所以应该要怎么解决呢?
4.2 Hbase 自己的MVCC
百度:MVCC(MultiVersionConsistencyControl , 多版本控制协议),是一种通过数据的多版本来解决读写一致性问题的解决方案。在隔离性级别中,MVCC可以解决“可重复读”的隔离(即除了最后一级别的幻读无法解决,幻读只能事务串行化解决),基本是同一份数据并发条件下保证读写一致性的一个理想方案了。
一般情况下MVCC的一种实现思路是类似乐观锁(OCC,又叫乐观并发控制) 的实现机制。乐观锁适用于写冲突不大的并发场景,先执行写入,检查是否有冲突,若有冲突则回滚重来,否则提交写请求成功。MVCC获取最新的版本进行写操作,如果失败则回滚,成功则会将当前的版本作为可读点;读操作只能读大于或小于当前版本的数据。这里用版本概念可能会有点混淆,通常可能是timestamp或seqID。
所以简而言之就是在读写的操作时加上版本控制。
而HBase则也是引用了版本这个概念,而它则是用在了写操作的HRegion中:
- 首先获取到行锁后,每个写操作立刻被分配一个write number, HRegion级别的seqID自增加一,并且当前 writeNo 设为 seqID + 1000000000。 这个大数的意义是防止别的写操作提交时把readNo提高了,导致当前writeNo成为一个可读状态的id,后面会将其设回正常的seqID。
- 每个数据cell存储自己的write number;
- 对于实际写操作本身,先写memstore,再写WAL,如果中间失败则回滚,否则则当做成功继续执行。
- 不管失败成功,当前这个seqID都是不可再用的了,写请求提交实际上就是把当前HRegion级别的readNo设为队列中已完成的写请求(包括别的线程的写请求)的seqID最大值,表示seqID以下的写请求都处理完了,可读。
读操作:
每个read point被分配一个最大的大于所有已完成write number的整数;对于read r将会返回数据cell,其满足所有的write number是小于或者等于read point r的最大值。
加上这个博主的图文,更好理解:

引用:https://blog.csdn.net/huanggang028/article/details/46047927?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
下一期:
Hbase 在进行表设计过程中如何进行列族和 RowKey 的设计
Hbase 的数据热点问题发现和解决办法
提高 Hbase 的读写性能的通用做法
HBase 中 RowFilter 和 BloomFilter 的原理
Hbase API 中常见的比较器
Hbase 的预分区
Hbase 的 Compaction
Hbase 集群中 HRegionServer 宕机如何解决